
How Perplexity Built an AI Google

Warp: The Coding Partner You Can Trust (Sponsored)

Too often, agents write code that almost works, leaving developers debugging instead of shipping. Warp changes that.
With Warp you get:
#1 coding agent: Tops benchmarks, delivering more accurate code out of the box.
Tight feedback loop: Built-in code review and editing lets devs quickly spot issues, hand-edit, or reprompt.
1-2 hours saved per day with Warp: All thanks to Warp’s 97% diff acceptance rate.
See why Warp is trusted by over 700k developers.
Disclaimer: The details in this post have been derived from the details shared online by the Perplexity Engineering Team, Vespa Engineering Team, AWS, and NVIDIA. All credit for the technical details goes to the Perplexity Engineering Team, Vespa Engineering Team, NVIDIA, and AWS. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
At its core, Perplexity AI was built on a simple but powerful idea: to change online search from a list of a few blue links into a direct “answer engine”.
The goal was to create a tool that could read through web pages for you, pull out the most important information, and give you a single, clear answer.
Think of it as a combination of a traditional search engine and a smart AI chatbot. When you ask a question, Perplexity first scours the live internet for the most current and relevant information. Then, it uses a powerful AI to read and synthesize what it found into a straightforward summary. This approach is very different from AI models that rely only on the data they were trained on, which can be months or even years out of date.
This design directly tackles two of the biggest challenges with AI chatbots:
Their inability to access current events.
Their tendency to “hallucinate” or make up facts.
By basing every answer on real, verifiable web pages and providing citations for its sources, Perplexity aims to be a more trustworthy and reliable source of information.
Interestingly, the company didn’t start with this grand vision. Their initial project was a much more technical tool for translating plain English into database queries.
However, the launch of ChatGPT in late 2022 was a turning point. The team noticed that one of the main criticisms of ChatGPT was its lack of sources. They realized their own internal prototype already solved this problem. In a decisive move, they abandoned four months of work on their original project to focus entirely on the challenge of building a true answer engine for the web. This single decision shaped the entire technical direction of the company.
Perplexity’s RAG Pipeline
The backbone of Perplexity’s service is a meticulously implemented Retrieval-Augmented Generation (RAG) pipeline. Here’s what RAG looks like on a high-level.
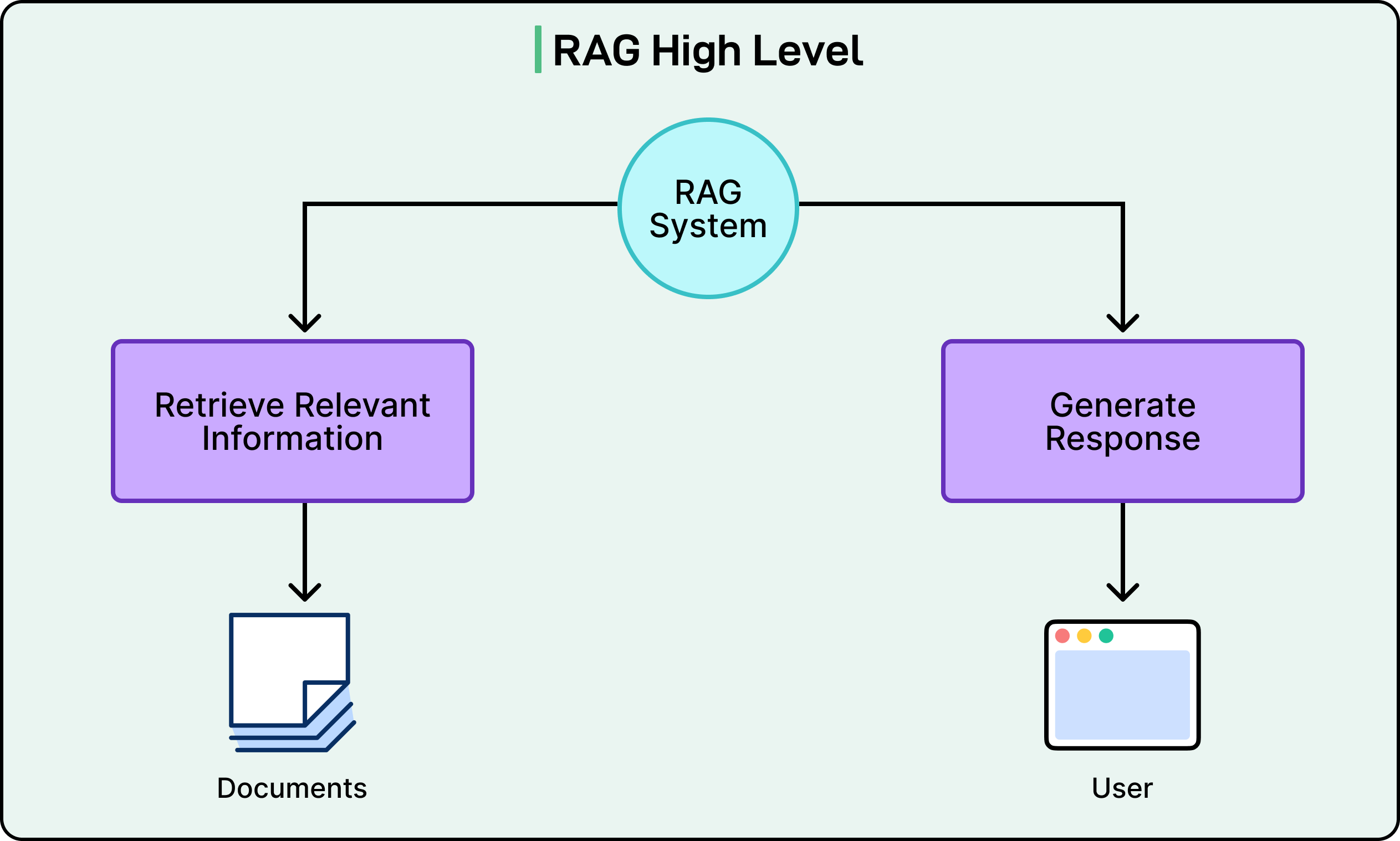
Behind the scenes of RAG at Perplexity is a multi-step process, which is executed for nearly every query to ensure that the generated answers are both relevant and factually grounded in current information.
The pipeline can be deconstructed into five distinct stages:
Query Intent Parsing: The process begins when a user submits a query. Instead of relying on simple keyword matching, the system first employs an LLM (which could be one of Perplexity’s own fine-tuned models or a third-party model such as GPT-4) to parse the user’s intent. This initial step moves beyond the lexical level to achieve a deeper semantic understanding of what the user is truly asking, interpreting context, nuance, and the underlying goal of the query.
Live Web Retrieval: Once the user’s intent is understood, the parsed query is dispatched to a powerful, real-time search index. This retrieval system scours the web for a set of relevant pages and documents that are likely to contain the answer. This live retrieval is a non-negotiable step in the process, ensuring that the information used for answer generation is always as fresh and up-to-date as possible.
Snippet Extraction and Contextualization: The system does not pass the full text of the retrieved web pages to the generative model. Instead, it utilizes algorithms to extract the most relevant snippets, paragraphs, or chunks of text from these sources. These concise snippets, which directly pertain to the user’s query, are then aggregated to form the “context” that will be provided to the LLM.
Synthesized Answer Generation with Citations: The curated context is then passed to the chosen generative LLM. The model’s task is to generate a natural-language, conversational response based only on the information contained within that provided context. This is a strict and defining principle of the architecture: “you are not supposed to say anything that you didn’t retrieve”. To enforce this principle and provide transparency, a crucial feature is the attachment of inline citations to the generated text. These citations link back to the source documents, allowing users to verify every piece of information and delve deeper into the source material if they choose.
Conversational Refinement: The Perplexity system is designed for dialogue, not single-shot queries. It maintains the context of the ongoing conversation, allowing users to ask follow-up questions. When a follow-up is asked, the system refines its answers through a combination of the existing conversational context and new, iterative web searches.
The diagram below shows a general view of how RAG works in principle:
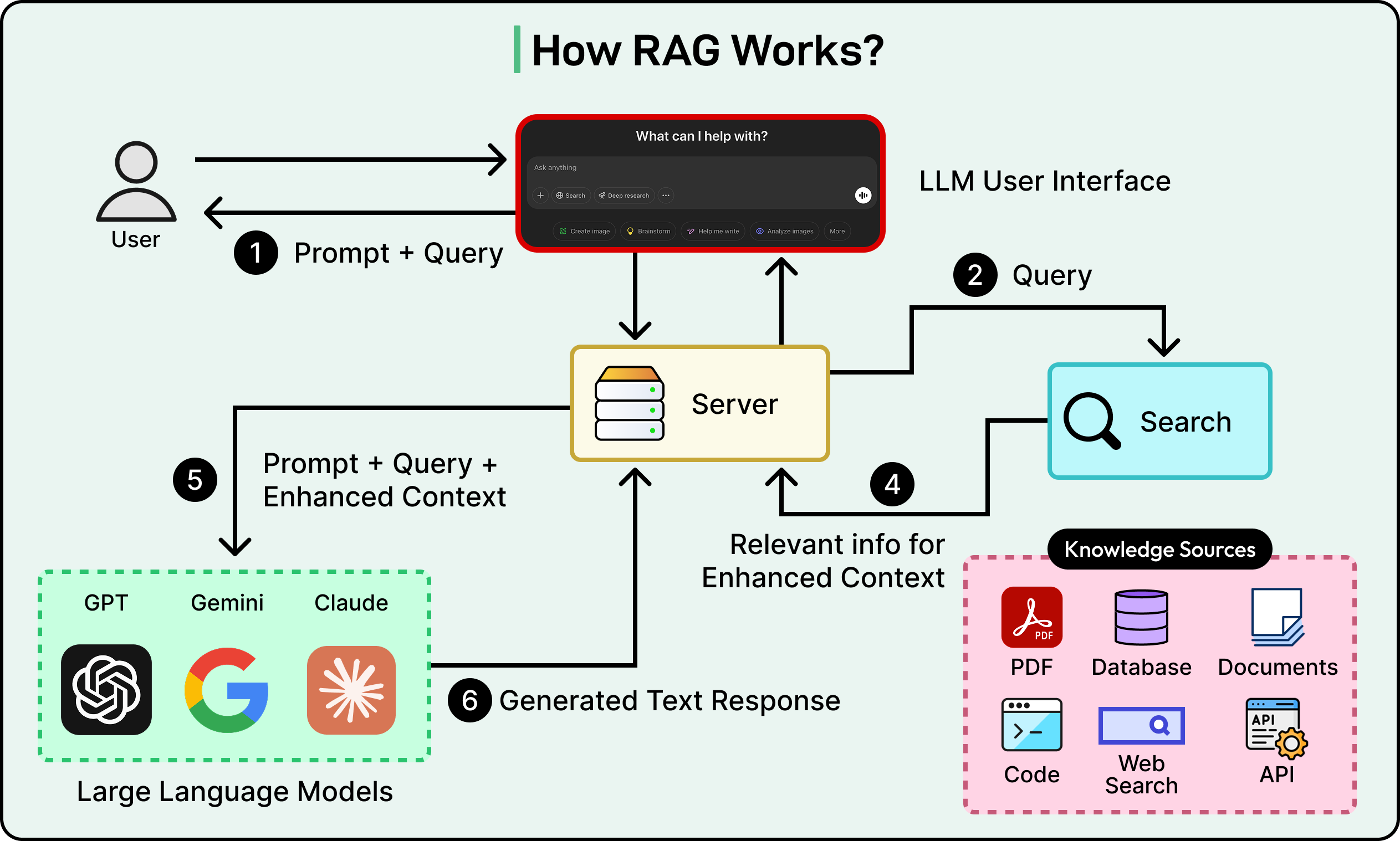
The Orchestration Layer
Perplexity’s core technical competency is not the development of a single, superior LLM but rather the orchestration of combining various LLMs with a high-performance search system to deliver fast, accurate, and cost-efficient answers. This is a complex challenge that needs to balance the high computational cost of LLMs with the low-latency demands of a real-time search product.
To solve this, the architecture is explicitly designed to be model-agnostic.
It leverages a heterogeneous mix of models, including in-house fine-tuned models from the “Sonar” family and third-party frontier models from leading labs like OpenAI (GPT series) and Anthropic (Claude series).
This flexibility is managed by an intelligent routing system. This system uses small, efficient classifier models to first determine the user’s intent and the complexity of their query. Based on this classification, the request is then routed to the most appropriate and cost-effective model for the specific task. For instance, a simple request for a definition might be handled by a small, fast, in-house model, whereas a complex query requiring multi-step reasoning or agentic behavior would be routed to a more powerful and expensive model like GPT-5 or Claude Opus.
This dynamic decision-making process, guided by the principle of using “the smallest model that will still give the best possible user experience,” is a key architectural strategy for managing performance and cost at scale.
This model-agnostic design is more than just a technical optimization, but also serves as a key strategic defense. In an industry where the underlying large language models are rapidly advancing and at risk of becoming commoditized, a naive architecture built entirely on a single third-party API would create significant business risks, including vendor lock-in, unpredictable pricing changes, and dependency on another company’s roadmap.
The Perplexity architecture deliberately mitigates these risks. The goal is to create a system that can leverage different models (like both open source and closed source) and have them work together symbiotically, to the point where the end-user does not need to know or care which specific model is being used.
This architectural choice demonstrates a clear belief that the company’s “moat” is not any single LLM, but the proprietary orchestration system that manages the interaction with these models to provide the best results for the end user.
The Retrieval Engine
The “retrieval” component of Perplexity’s RAG pipeline is the foundation upon which the entire system’s accuracy and relevance are built. The quality of the information retrieved directly dictates the quality of the final answer generated.
Perplexity uses Vespa AI to power its massive and scalable RAG architecture. The selection of Vespa was driven by the need for a platform capable of delivering real-time, large-scale RAG with the high performance, low latency, and reliability demanded by a consumer-facing application serving millions of users.
Here’s a comparative chart about query latency that Perplexity has been able to achieve:
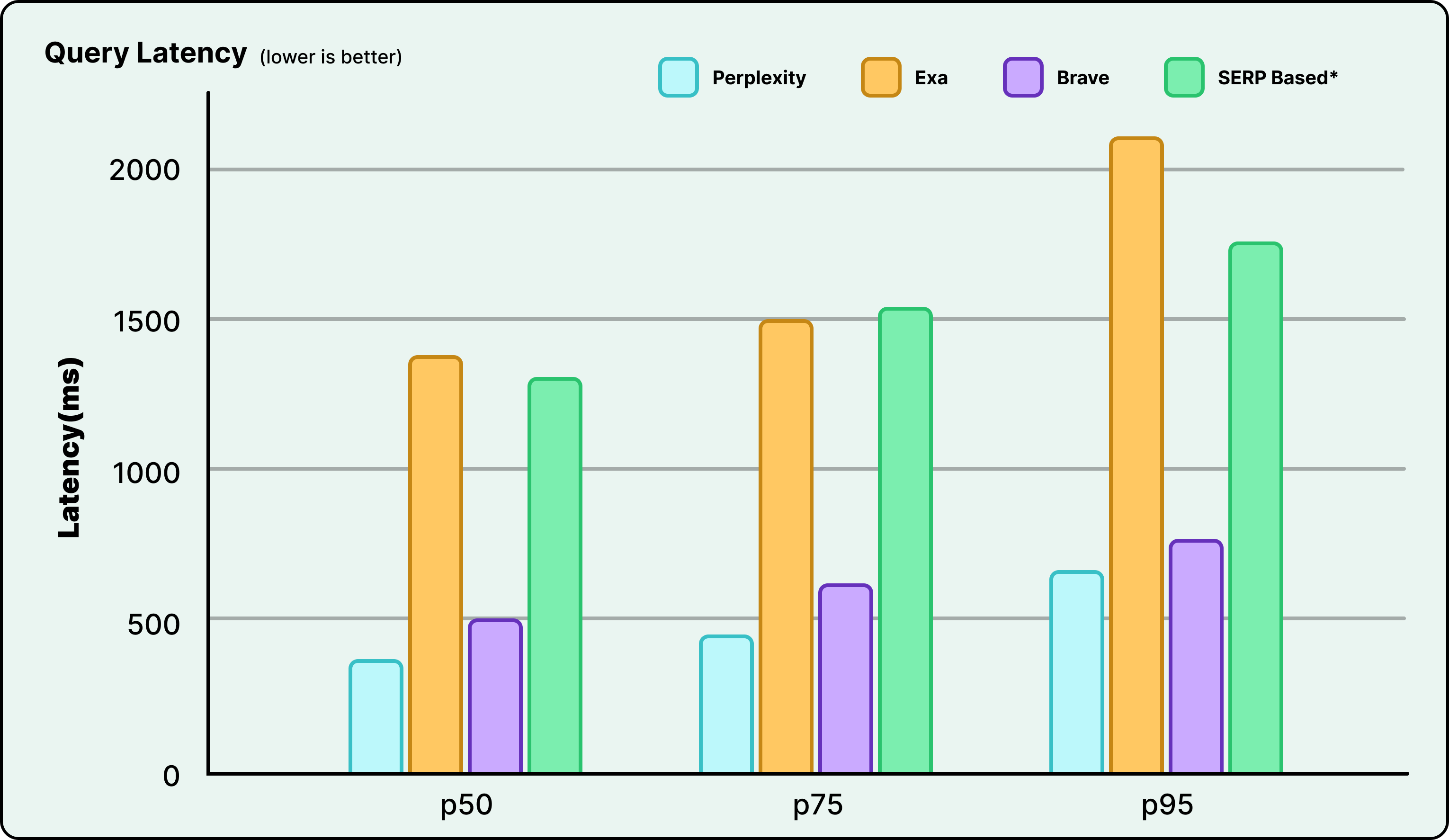
A key advantage of Vespa is its unified nature. It integrates multiple critical search technologies, including vector search for semantic understanding, lexical search for precision, structured filtering, and machine-learned ranking, into a single, cohesive engine. This integrated approach eliminates the significant engineering overhead and complexity that would arise from attempting to stitch together multiple disparate systems, such as a standalone vector database combined with a separate keyword search engine like Elasticsearch.
This decision to build on Vespa was also driven by the need to focus on limited engineering resources. Building a web-scale, real-time search engine from the ground up is an extraordinarily difficult and capital-intensive endeavor, a problem that companies like Google and Yahoo (where Vespa originated) have invested decades and billions of dollars to solve.
Perplexity’s core mission is not to reinvent search indexing but to build a novel answer engine on top of a search foundation. By strategically outsourcing the mature and largely “solved” problem of distributed, real-time search to a specialized platform like Vespa, Perplexity’s relatively small engineering team of around 38 people has been able to focus its efforts on the unique and differentiating parts of its technology stack, made up of the following pieces:
The RAG orchestration logic.
The fine-tuning of its proprietary Sonar models.
The hyper-optimization of its in-house ROSE inference engine.
This is a classic “build vs. buy” decision executed at the highest architectural level.
Indexing and Retrieval Infrastructure
The infrastructure built on Vespa is designed to handle the unique demands of an AI-powered answer engine, prioritizing scale, freshness, and a deep understanding of content.
Here are the key aspects of the same:
1 - Web-Scale Indexing
The system operates on a massive index that covers hundreds of billions of webpages.
Perplexity’s crawling and indexing infrastructure tracks over 200 billion unique URLs, supported by fleets of tens of thousands of CPUs and a multi-tier storage system with over 400 petabytes in hot storage alone.
Vespa’s distributed architecture is fundamental to managing this scale. It automatically, transparently, and dynamically partitions and distributes content across a cluster of many nodes. Crucially, it co-locates all information, indexes, and the computational logic for a given piece of data on the same node, which distributes the query load effectively and avoids the network bandwidth bottlenecks that can cripple large-scale systems.
2 - Real-Time Freshness
For an answer engine, information staleness is a critical failure mode. The system must reflect the world as it is, right now.
Perplexity’s infrastructure is engineered for this, processing tens of thousands of index update requests every second to ensure the index provides the freshest results available.
This is enabled by Vespa’s unique index technology, which is capable of cheaply and efficiently mutating index structures in real time, even while they are being actively read by serving queries. It allows for a continuous stream of updates without degrading query performance.
To manage this process, an ML model is trained to predict whether a candidate URL needs to be indexed and to schedule the indexing operation at the most useful time, calibrated to the URL’s importance and likely update frequency.
3 - Fine-Grained Content Understanding
The system’s understanding of content goes much deeper than the document level.
Perplexity’s indexing infrastructure divides documents into “fine-grained units” or “chunks”. Rather than returning the entire content of a long article, Vespa’s layered ranking capabilities allow it to score these individual chunks by their relevance to the query.
This means the system can identify and return only the most relevant paragraphs or sentences from the most relevant documents, providing a much more focused and efficient context for the LLM to process.
Here’s a screenshot that shows Perplexity typically presents its search results:

4 - Self-Improving and AI-Powered Content Parsing
To contend with the unstructured and often inconsistent nature of the open web, Perplexity’s indexing operations utilize an AI-powered content understanding module.
This module dynamically generates and adapts parsing rulesets to extract semantically meaningful content from diverse websites.
This module is not static. It optimizes itself through an iterative AI self-improvement process. In this loop, frontier LLMs assess the performance of current rulesets on dimensions of completeness and quality. The system then uses these assessments to formulate, validate, and deploy proposed changes to address error classes, ensuring the module continuously evolves. This process is crucial for segmenting documents into the self-contained, atomic units of context that are ideal for LLMs.
5 - Hybrid Search and Ranking Capabilities
The high quality of Perplexity’s answers is fundamentally limited by the quality of the information it retrieves. Therefore, its ranking algorithm acts as a critical quality gatekeeper for the entire RAG pipeline.
Perplexity leverages Vespa’s advanced capabilities to implement a multi-stage architecture that progressively refines results under a tight latency budget. Here are the key aspects:
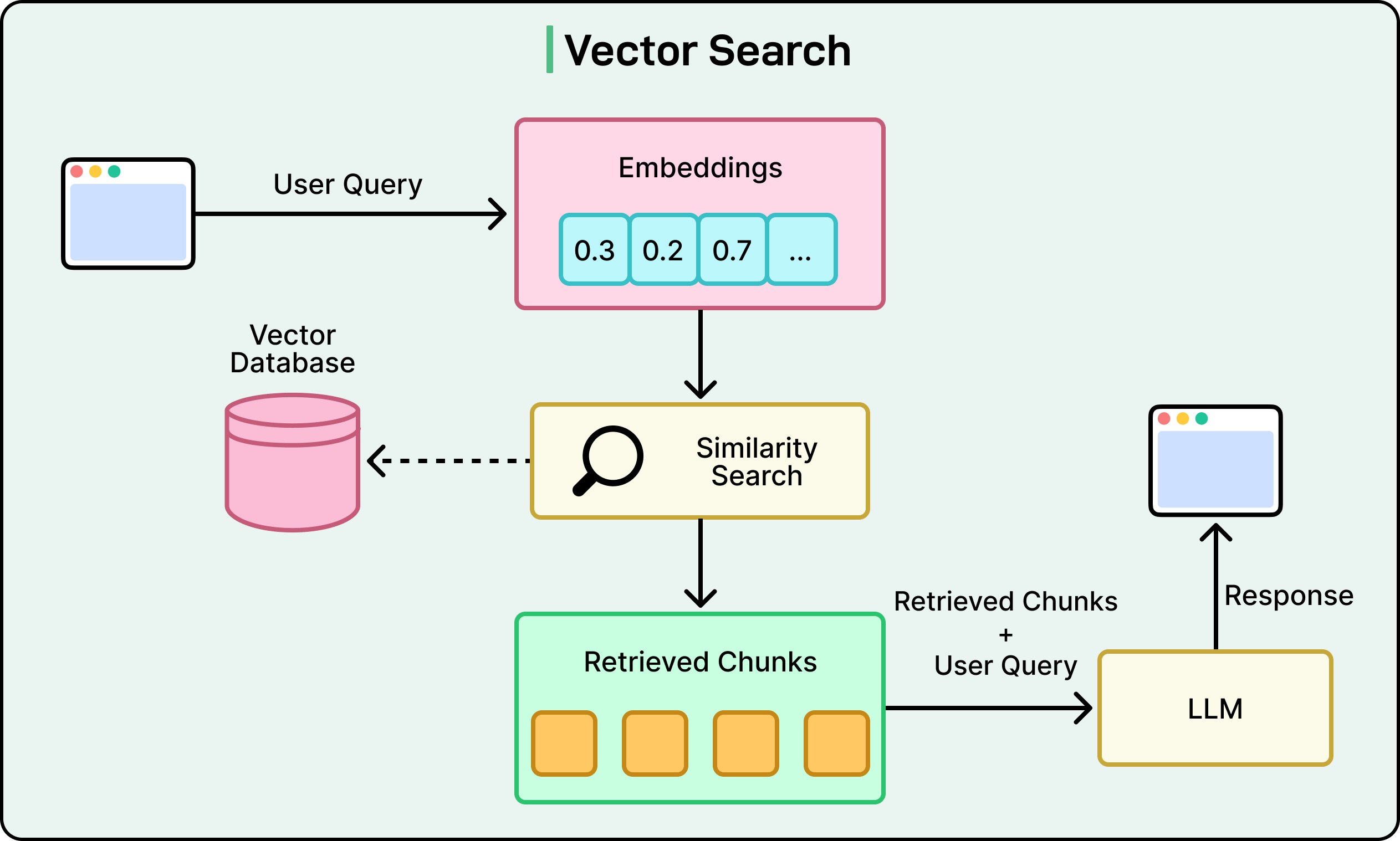
Dense Retrieval (Vector Search): This technique allows the system to move beyond keywords to match content at a semantic or conceptual level. It uses vector embeddings to understand the meaning behind a user’s query and find contextually similar documents, even if they do not share the same words.
Sparse Retrieval (Lexical Search): While vector search is excellent for capturing broad meaning, it can lack precision. Sparse retrieval, which includes traditional keyword-based techniques and ranking functions like BM25, provides this necessary precision. It allows the system to perform exact matches on rare terms, product names, internal company monikers, and other specific identifiers where semantic ambiguity is undesirable.
Machine-Learned Ranking: The true power of the system lies in its ability to combine these different signals. Vespa enables Perplexity to implement advanced, multi-phase ranking models. In this process, an initial set of candidate documents might be retrieved using a combination of lexical and vector search. Then, a more sophisticated machine-learning model evaluates these candidates, using a rich set of features (such as lexical relevance scores, vector similarity, document authority, freshness, user engagement signals, and other metadata) to produce a final, highly accurate ranking.
The diagram below shows how Vector Search typically works in the context of an RAG system:
The ranking stack is co-designed with Perplexity’s user-facing products, allowing it to leverage rich, automated signals from millions of daily user requests to continuously enrich its training data.
The Generation Engine
After Perplexity finds the best information on the web, the next step is to turn it into a clear, easy-to-read answer.
This is handled by the “generation engine,” which is the AI brain that writes the response. To do this, Perplexity uses a clever, two-part strategy: it combines its own custom-built AI models with a selection of the most powerful models from other leading technology labs. This hybrid approach allows the company to perfectly balance cost, speed, and access to the most advanced AI capabilities.
The first part of this strategy is Perplexity’s own family of AI models, known as Sonar. These models are not built entirely from scratch, which would be incredibly expensive and time-consuming. Instead, Perplexity starts with powerful, publicly available open-source models. They then “fine-tune” them for their specific needs.
Perplexity trains these base models on its own vast collection of data, teaching them the special skills required to be a great answer engine. These skills include the ability to summarize information accurately, correctly add citations to sources, and stick strictly to the facts that were found during the web search. Every time a user interacts with the service, Perplexity gathers more data that helps it continuously improve its Sonar models, making them smarter and more helpful over time.
The second part of the strategy involves integrating the “best of the best” from the wider AI world. For its paying subscribers, Perplexity offers access to a curated selection of the most advanced models available, such as OpenAI’s GPT series and Anthropic’s Claude models. This gives users the option to use the absolute most powerful AI for tasks that require deep reasoning, creativity, or complex problem-solving.
To make this work smoothly, Perplexity uses a service called Amazon Bedrock, which acts like a universal adapter, allowing them to easily plug these different third-party models into their system without having to build a separate, custom integration for each one.
This “best of both worlds” approach is the key to Perplexity’s business model.
Perplexity’s Inference Stack
Having powerful AI models is one thing, but delivering fast and affordable answers to millions of people is a massive technical challenge.
Running AI models is incredibly expensive, so Perplexity has built a sophisticated, high-performance system to do it efficiently. This system, known as the “inference stack,” is the engine that makes the entire service possible.
At the heart of this system is a custom-built engine named ROSE. Perplexity created ROSE to do two things very well.
First, it needed to be flexible, allowing the engineering team to quickly test and adopt the latest AI models as they are released.
Second, it needed to be a platform for extreme optimization, squeezing every last bit of performance out of the models to make them run faster and cheaper.
ROSE is primarily built in Python and leverages PyTorch for its model definitions. This choice provides the flexibility and ease of development needed to adapt to new and varied model architectures. However, for components where performance is absolutely critical, such as the serving logic and batch scheduling algorithms, the team is migrating the codebase to Rust. This move leverages Rust’s performance, which is comparable to C++, along with its strong memory safety guarantees, making it an ideal choice for high-performance, reliable systems code.
The engine is architected around a core LLM engine that can load model weights and generate decoded tokens. It supports advanced decoding strategies, including speculative decoding and MTP (Multi-Token Prediction) decoders, which can improve latency.
This entire operation runs on the Amazon Web Services (AWS) cloud platform, using pods of state-of-the-art NVIDIA H100 GPUs. These GPUs are essentially super-powered computer chips designed specifically for AI use cases. To manage this fleet of powerful hardware, Perplexity uses industry-standard tools like Kubernetes to orchestrate all the moving parts and ensure the system runs smoothly and can handle huge amounts of traffic.
See the diagram below that shows how Perplexity deployed LLM production on a massive scale using NVIDIA.
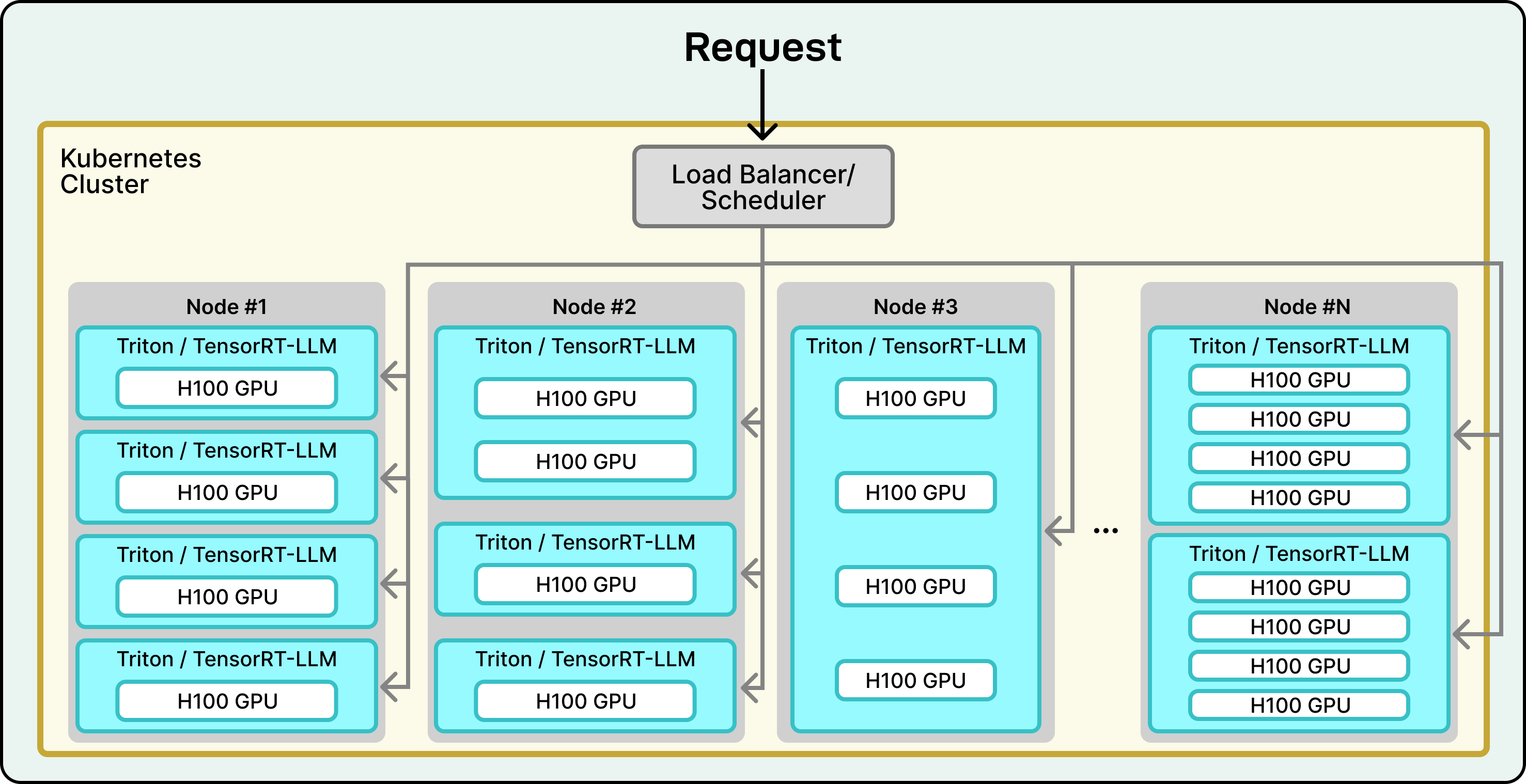
The decision to build this complex system in-house instead of simply paying to use other AI models has a huge payoff. By controlling the entire stack, from the software engine down to the hardware, Perplexity can optimize everything for its specific needs. This control directly leads to faster response times for users and lower costs for the business.
Conclusion
The technical architecture of Perplexity AI reveals that its power as an “AI Google” does not stem from a single, magical Large Language Model.
Instead, its success is the result of the engineering of a complete, end-to-end system where each component is carefully chosen and deeply optimized to work in concert with the others.
First is the world-class retrieval engine, built upon the scalable and real-time foundation of Vespa.ai. This system provides high-quality, fresh, and relevant information that serves as the factual bedrock for every answer. It also has a sophisticated hybrid ranking algorithm acting as the critical gatekeeper.
Second is the flexible, model-agnostic orchestration layer. This core logic intelligently parses user intent and routes queries to the most appropriate generative model, whether it be a cost-effective, in-house Sonar model fine-tuned for specific tasks or a state-of-the-art frontier model from a third-party lab. This layer provides the economic and strategic flexibility necessary to compete in a rapidly evolving AI landscape.
Third is the hyper-optimized, in-house inference stack, centered around the ROSE engine. This custom-built system, running on state-of-the-art NVIDIA hardware within the AWS cloud, extracts every last drop of performance and cost-efficiency out of the models it serves.
References:
Spotlight: Perplexity AI Serves 400 Million Search Queries a Month Using NVIDIA Inference Stack
Deep Dive Read With Me: Perplexity CTO Denis Yarats on AI-Powered Search
Perplexity Builds Advanced Search Engine Using Anthropic’s Claude 3 in Amazon Bedrock
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
i love these deep dives into how entire specific apps/sites work
I love using Perplexity but knowing how the business made architectural decisions to optimize the business but also deliver the best user experience is enlightening. I feel like I learned so much about RAG and Perplexity as a business, thank you!