
How Pinterest Scaled Its Architecture to Support 500 Million Users

Avoid the widening AI engineering skills gap (Sponsored)

Most AI hype today is about developer productivity and augmentation. This overshadows a more important opportunity: AI as the foundation for products and features that weren’t previously possible.
But, it’s a big jump from building Web 2.0 applications to AI-native products, and most engineers aren’t prepared. That’s why Maven is hosting 50+ short, free live lessons with tactical guidance and demos from AI engineers actively working within the new paradigm.
This is your opportunity to upskill fast and free with Maven’s expert instructors. We suggest you start with these six:
Evaluating Agentic AI Applications - Aish Reganti (Tech Lead, AWS) & Kiriti Badam (Applied AI, OpenAI)
Optimize Structured Data Retrievals with Evals - Hamel Husain (AI Engineer, ex-Github, Airbnb)
CTO Playbook for Agentic RAG - Doug Turnbull (Principal ML Engineer, ex-Reddit, Shopify)
Build Your First Agentic AI App with MCP - Rafael Pierre (Principal AI Engineer, ex-Hugging Face, Databricks)
Embedding Performance through Generative Evals - Jason Liu (ML Engineer, ex-Stitch Fix, Meta)
Design Vertical AI Agents - Hamza Farooq (Stanford instructor, ex-Google researcher)
To go deeper with these experts, use code BYTEBYTEGO to get $100 off their featured AI courses - ends June 30th.
Disclaimer: The details in this post have been derived from the articles/videos shared online by the Pinterest engineering team. All credit for the technical details goes to the Pinterest Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Pinterest launched in March 2010 with a typical early-stage setup: a few founders, one engineer, and limited infrastructure. The team worked out of a small apartment. Resources were constrained, and priorities were clear—ship features fast and figure out scalability later.
The app didn’t start as a scale problem but as a side project. A couple of founders, a basic web stack, and an engineer stitching together Python scripts in a shared apartment. No one was thinking about distributed databases when the product might not survive the week.
The early tech decisions reflected this mindset. The stack included:
Python for the application layer
NGINX as a front-end proxy
MySQL with a read replica
MongoDB for counters
A basic task queue for sending emails and social updates
But the scale increased rapidly. One moment it’s a few thousand users poking around images of food and wedding dresses. Then traffic doubles, and suddenly, every service is struggling to maintain performance, logs are unreadable, and engineers are somehow adding new infrastructure in production.
This isn’t a rare story. The path from minimum viable product to full-blown platform often involves growing pains that architectural diagrams never show. Systems that worked fine for 10,000 users collapse at 100,000.
In this article, we’ll look at how Pinterest scaled its architecture to handle the scale and the challenges they faced along the way.
The Initial Architecture
Pinterest’s early architecture reflected its stage: minimal headcount, fast iteration cycles, and a stack assembled more for momentum than long-term sustainability.
When the platform began to gain traction, the team moved quickly to AWS. The choice wasn’t the result of an extensive evaluation. AWS offered enough flexibility, credits were available, and the team could avoid the friction of setting up physical infrastructure.
The initial architecture looked like this:

The technical foundation included:
NGINX is the front-end HTTP server. It handled incoming requests and routed them to application servers. NGINX was chosen for its simplicity and performance, and it required little configuration to get working reliably.
Python-based web engines, four in total, processed application logic. Python offered a high development speed and decent ecosystem support. For a small team, being productive in the language mattered more than raw runtime performance.
MySQL, with a read slave, served as the primary data store. The read slave allowed some level of horizontal scaling by distributing read operations, which helped reduce load on the primary database. At this point, the schema and data model were still evolving rapidly.
MongoDB was added to handle counters. These were likely used for tracking metrics like likes, follows, or pins. MongoDB’s document model and ease of setup made it a quick solution. It wasn’t deeply integrated or tuned.
A simple task queue system was used to decouple time-consuming operations like sending emails and posting to third-party platforms (for example, Facebook, Twitter). The queue was critical for avoiding performance bottlenecks during user interactions.
This stack wasn’t optimized for scale or durability. It was assembled to keep the product running while the team figured out what the product needed to become.
Rapid Growth and Chaos
As Pinterest’s popularity grew, traffic doubled every six weeks. This kind of growth puts a great strain on the infrastructure.
Pinterest hit this scale with a team of just three engineers. In response, the team added technologies reactively. Each new bottleneck triggered the introduction of a new system:
MySQL remained the core data store, but began to strain under concurrent reads and writes.
MongoDB handled counters.
Cassandra was used to handle distributed data needs.
MBase was introduced—less for fit, more because it was promoted as a quick fix.
Redis entered the stack for caching and fast key-value access.
The result was architectural entropy. Multiple databases, each with different operational behaviors and failure modes, created complexity faster than the team could manage.
Each new database seemed like a solution at first until its own set of limitations emerged. This pattern repeated: an initial phase, followed by operational pain, followed by another tool. By the time the team realized the cost, they were maintaining a fragile web of technologies they barely had time to understand.
This isn’t rare. Growth exposes every shortcut. What works for a smaller-scale project can’t always handle production traffic. Adding tools might buy time, but without operational clarity and internal expertise, it also buys new failure modes.
By late 2011, the team recognized a hard truth: complexity wasn’t worth it. They didn’t need more tools. They needed fewer, more reliable ones.
Post-Rearchitecture Stack
After enduring repeated failures and operational overload, Pinterest stripped the stack down to its essentials.
The architecture stabilized around three core components: MySQL, Redis, and Memcached (MIMC). Everything else (MongoDB, Cassandra, MBase) was removed or isolated.
Let’s look at each in more detail.
MySQL
MySQL returned to the center of the system.
It stored all core user data: boards, pins, comments, and domains. It also became the system of record for legal and compliance data, where durability and auditability were non-negotiable. The team leaned on MySQL’s maturity: decades of tooling, robust failover strategies, and a large pool of operational expertise.
However, MySQL had one critical limitation: it didn’t scale horizontally out of the box. Pinterest addressed this by sharding and, more importantly, designing systems to tolerate that limitation. Scaling became a question of capacity planning and box provisioning, not adopting new technologies.
The diagram below shows how sharding works in general:
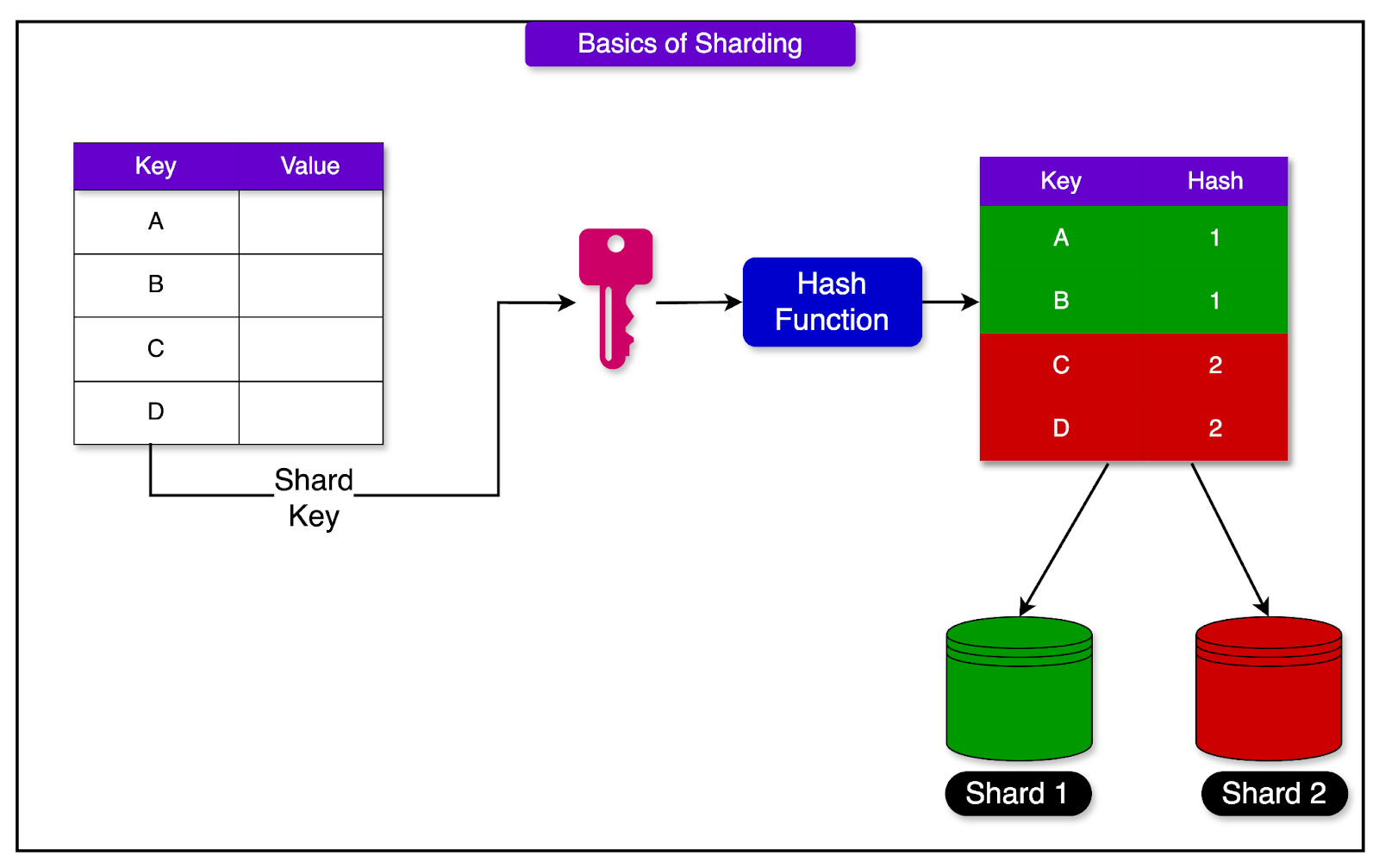
Redis
Redis handled problems that MySQL couldn’t solve cleanly:
Feeds: Pushing updates in real-time requires low latency and fast access patterns.
Follower graph: The complexity of user-board relationships demanded a more dynamic, memory-resident structure.
Public feeds: Redis provided a true list structure with O(1) inserts and fast range reads, ideal for rendering content timelines.
Redis was easier to operate than many of its NoSQL competitors. It was fast, simple to understand, and predictable, at least when kept within RAM limits.

Durability Modes: Choosing Trade-offs Explicitly
Redis offers several persistence modes, each with clear implications:
No persistence: Everything lives in RAM and disappears on reboot. It’s fast and simple, but risky for anything critical.
Snapshotting (RDB): Periodically saves a binary dump of the dataset. If a node fails, it can recover from the last snapshot. This mode balances performance with recoverability.
Append-only file (AOF): Logs every write operation. More durable, but with higher I/O overhead.
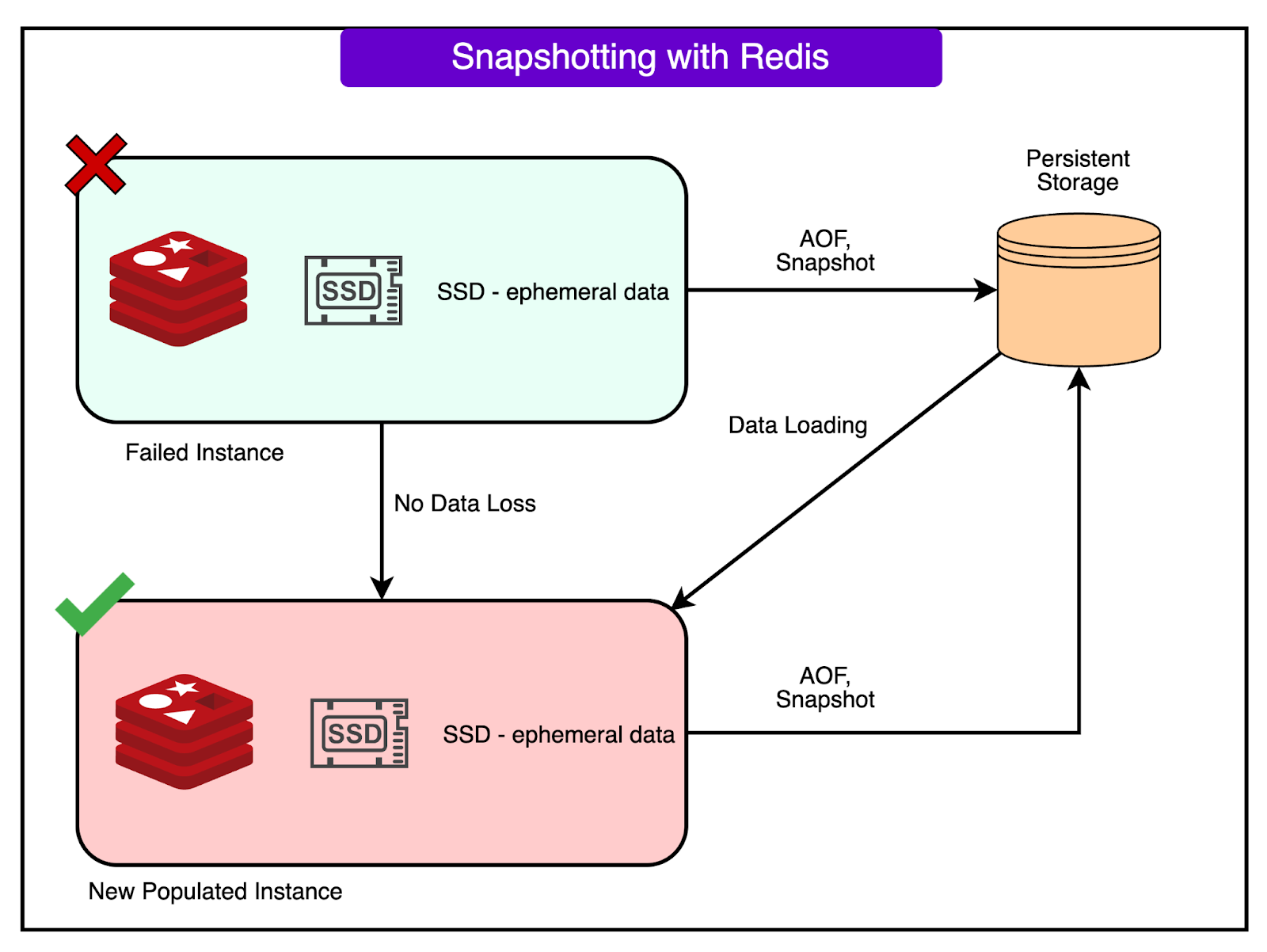
Pinterest leaned heavily on Redis snapshotting. It wasn’t bulletproof, but for systems like the follower graph or content feeds, the trade-off worked: if a node died, data from the last few hours could be rebuilt from upstream sources. This avoided the latency penalties of full durability without sacrificing recoverability.
The diagram below shows snapshotting with Redis.
Why Redis Over MySQL?
MySQL remained Pinterest’s source of truth, but for real-time applications, it fell short:
Write latency increased with volume, especially under high concurrency.
Tree-based structures (for example, B-trees) make inserts and updates slower and harder to optimize for queue-like workloads.
Query flexibility came at the cost of performance predictability.
Redis offered a better fit for these cases:
Feeds: Users expect content updates instantly. Redis handled high-throughput, low-latency inserts with predictable performance.
Follower graph: Pinterest’s model allowed users to follow boards, users, or combinations. Redis stores this complex relationship graph as in-memory structures with near-zero access time.
Caching: Redis served as a fast-access layer for frequently requested data like profile overviews, trending pins, or related content.
Memcached (MIMC): Cache Layer Stability
MIMC served as a pure cache layer. It didn’t try to be more than that, and that worked in its favor.
It offloaded repetitive queries, reduced latency, and helped absorb traffic spikes. Its role was simple but essential: act as a buffer between user traffic and persistent storage.
Microservices and Infrastructure Abstraction
As Pinterest matured, scaling wasn’t just about systems. It was also about the separation of concerns.
The team began pulling tightly coupled components into services, isolating core functionality into defined boundaries with clear APIs.
Service Boundaries That Mattered
Certain parts of the architecture naturally became services because they carried high operational risk or required specialized logic:
Search Service: Handled query parsing, indexing, and result ranking. Internally, it became a complex engine, dealing with user signals, topic clustering, and content retrieval. From the outside, it exposed a simple interface: send a query, get relevant results. This abstraction insulated the rest of the system from the complexity behind it.
Feed Service: Managed the distribution of content updates. When a user pinned something, the feed service handled propagation to followers. It also enforced delivery guarantees and ordering semantics, which were tricky to get right at scale.
MySQL Service: Became one of the first hardened services. It sat between applications and the underlying database shards. This layer implemented safety checks, access controls, and sharding logic. By locking down direct access, it avoided mistakes that previously caused corrupted writes, like saving data to the wrong shard.
PinLater: Asynchronous Task Processing
Background jobs were offloaded to a system called PinLater. The model was simple: tasks were written to a MySQL-backed queue with a name, payload, and priority. Worker pools pulled from this queue and executed jobs.
This design had key advantages:
Tasks were durable.
Failure recovery was straightforward.
Prioritization was tunable without major system redesign.
PinLater replaced ad hoc queues and inconsistent task execution patterns. It introduced reliability and consistency into Pinterest’s background job landscape.
Service Discovery with Zookeeper
To avoid hardcoded service dependencies and brittle connection logic, the team used Zookeeper as a service registry. When an application needed to talk to a service, it queried Zookeeper to find available instances.
This offered a few critical benefits:
Resilience: Services could go down and come back up without breaking clients.
Elasticity: New instances could join the cluster automatically.
Connection management: Load balancing became less about middleware and more about real-time awareness.

Data Pipeline and Monitoring
As Pinterest scaled, visibility became non-negotiable. The team needed to know what was happening across the system in real-time. Logging and metrics weren’t optional but part of the core infrastructure.
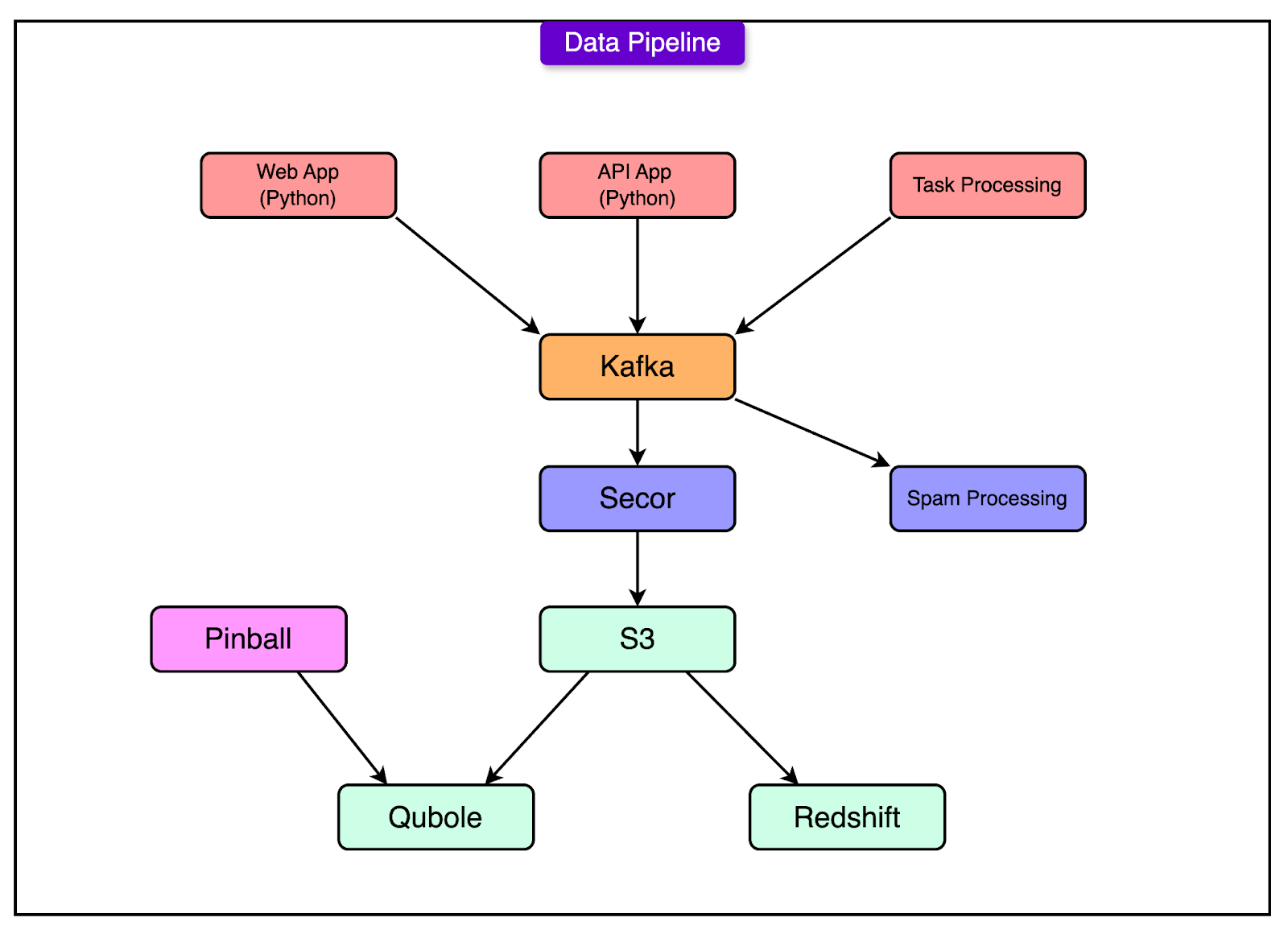
Kafka at the Core
The logging backbone started with Kafka, a high-throughput, distributed message broker. Every action on the site (pins, likes, follows, errors) pushed data into Kafka. Think of it as a firehose: everything flows through, nothing is lost unless explicitly discarded.
Kafka solved a few key problems:
It decoupled producers from consumers. Application servers didn’t need to know who would process the data or how.
It buffered spikes in traffic without dropping events.
It created a single source of truth for event data.
Secor + S3: Durable, Queryable Logs
Once the data hit Kafka, it flowed into Secor, an internal tool that parsed and transformed logs. Seor broke log entries into structured formats, tagged them with metadata, and wrote them into AWS S3.
This architecture had a critical property: durability. S3 served as a long-term archive. Once the data landed there, it was safe. Even if downstream systems failed, logs could be replayed or reprocessed later.
The team used this pipeline not just for debugging, but for analytics, feature tracking, and fraud detection. The system was designed to be extensible. Any new use case could hook into Kafka or read from S3 without affecting the rest of the stack.
Real-Time Monitoring
Kafka wasn’t only about log storage. It enabled near-real-time monitoring. Stream processors consumed Kafka topics and powered dashboards, alerts, and anomaly detection tools. The moment something strange happened, such as as spike in login failures, a drop in feed loads, it showed up immediately.
This feedback loop was essential. Pinterest didn’t just want to understand what happened after a failure. They wanted to catch it as it began.
Conclusion
Pinterest’s path from early chaos to operational stability left behind a clear set of hard-earned lessons, most of which apply to any system scaling beyond its initial design.
First, log everything from day one. Early versions of Pinterest logged to MySQL, which quickly became a bottleneck. Moving to a pipeline of Kafka to Seor to S3 changed the game. Logs became durable, queryable, and reusable. Recovery, debugging, analytics, everything improved.
Second, know how to process data at scale. Basic MapReduce skills went a long way. Once logs landed in S3, teams used MapReduce jobs to analyze trends, identify regressions, and support product decisions. SQL-like abstractions made the work accessible even for teams without deep data engineering expertise.
Third, instrument everything that matters. Pinterest adopted StatsD to track performance metrics without adding friction. Counters, timers, and gauges flowed through UDP packets, avoiding coupling between the application and the metrics backend. Lightweight, asynchronous instrumentation helped spot anomalies early, before users noticed.
Fourth, don’t start with complexity. Overcomplicating architecture early on, especially by adopting too many tools too fast, guarantees long-term operational pain.
Finally, pick mature, well-supported technologies. MySQL and Memcached weren’t flashy, but they worked. They were stable, documented, and surrounded by deep communities. When something broke, answers were easy to find.
Pinterest didn’t scale because it adopted cutting-edge technology. It scaled because it survived complexity and invested in durability, simplicity, and visibility. For engineering leaders and architects, the takeaways are pragmatic:
Design systems to fail visibly, not silently.
Favor tools with proven track records over tools with bold promises.
Assume growth will outpace expectations, and build margins accordingly.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Great blog, there are a few typos which can be corrected, like:
1. `MBase` should be `HBase`.
2. `Seor` should be `Secor` in the `Conclusion`.
Thanks
Your every blog gives extensive knowledge about parts and tools of software systems. Before this blog I thought Redis is used only for cache but if concern is only cache MIMC is better option.