
How Pinterest Transfers Hundreds of Terabytes of Data With CDC

How to Build Secure MCP Auth With OAuth 2.1 (Sponsored)

Securely authorizing access to an MCP server is complex. You need PKCE, scopes, consent flows, and a way to revoke access when needed.
This guide from WorkOS explains how to implement OAuth 2.1 in a production-ready setup, with clear steps and examples.
WorkOS Connect and AuthKit handle the full flow from authorization to token management.
Disclaimer: The details in this post have been derived from the details shared online by the Pinterest Engineering Team. All credit for the technical details goes to the Pinterest Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them. Apache®, Apache Kafka®, and Kafka® are trademarks of the Apache Software Foundation. Debezium® is a trademark of Red Hat, Inc.
Change Data Capture (CDC) has become an essential technique for modern data platforms. It allows companies to detect and record changes in their databases as they happen, rather than relying on slow batch jobs. This enables real-time analytics, faster data synchronization across systems, and more efficient processing of large datasets.
At Pinterest, the need for a reliable and scalable CDC system became clear as the company’s data infrastructure grew to support millions of queries per second and thousands of database shards.
The Pinterest Engineering team built a generic CDC platform to solve these challenges. Their approach adapts popular open-source tools like Debezium and Apache Kafka to work at a massive scale, while avoiding deep customizations that would make upgrades difficult later. Instead of building isolated solutions for each use case, Pinterest created a unified architecture that can support the entire company’s data needs.
In this article, we look at Pinterest’s CDC system and understand how the team dealt with the various challenges they faced.
What is CDC?
Change Data Capture, or CDC, is a method used to detect and record any change that happens inside a database. These changes include the addition of new data (insert), modification of existing data (update), or removal of data (delete). Instead of repeatedly scanning the entire database to find what has changed, CDC tracks these changes as they happen and makes them available to other systems in real time.
See the diagram below that shows this process.
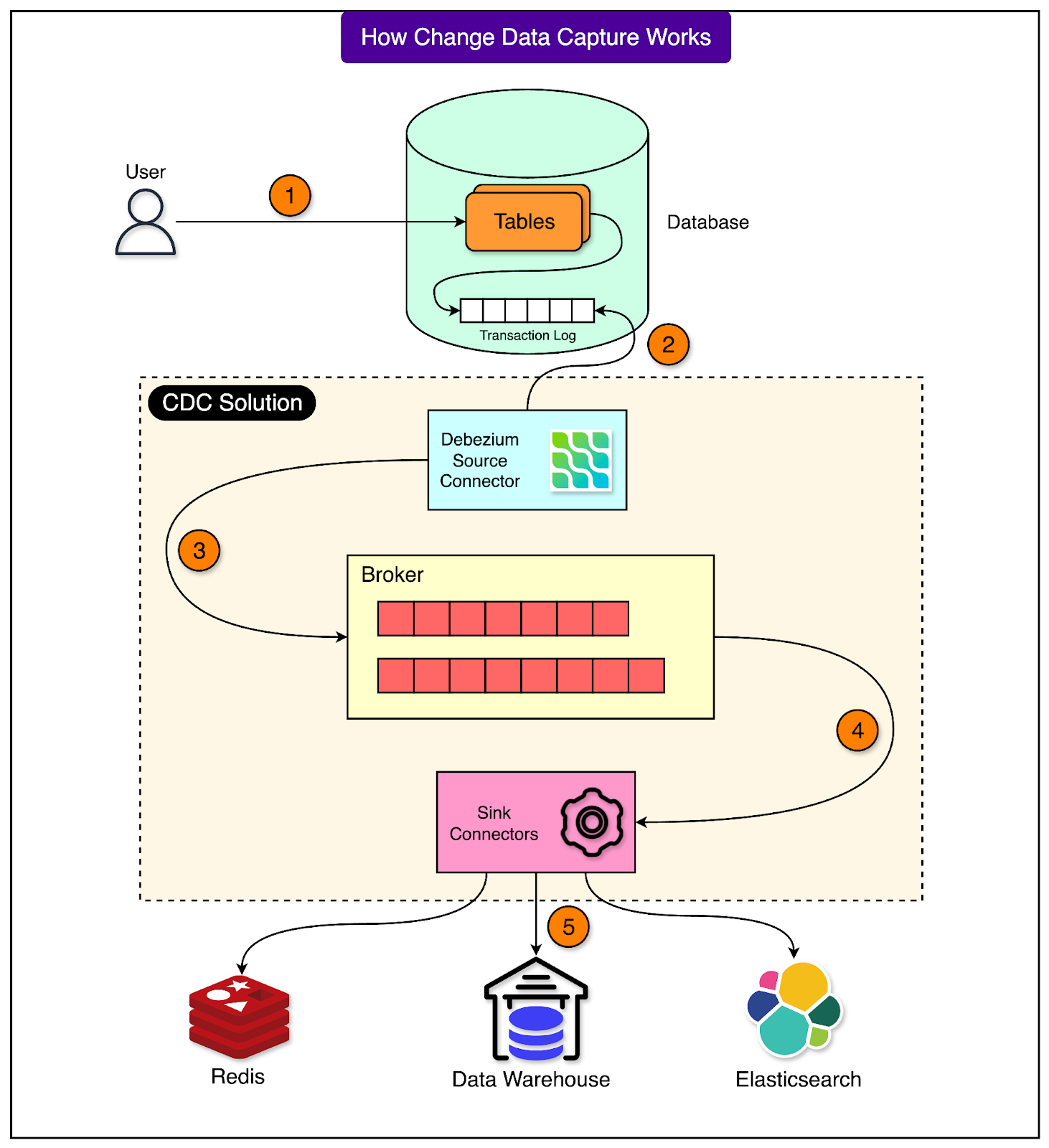
Pinterest uses CDC as a core part of its data platform. It powers several critical functions such as real-time analytics, recommendation engines, fraud detection, and keeping different internal systems in sync. For example, when a user saves a new pin or updates their profile, these changes need to quickly flow to many downstream services. CDC ensures this happens efficiently and reliably.
CDC is important for several reasons:
Real-time data processing: Traditional systems use batch jobs that run every few hours. CDC lets systems respond the moment new data arrives.
Better data integration: Multiple systems can stay in sync without repeatedly copying entire datasets.
Lower load on source databases: Only incremental changes are captured, which reduces unnecessary database work.
Audit and compliance: All changes are logged, which helps track data history for legal or security purposes.
The Initial Solution
Before building a unified system, Pinterest had many different CDC setups across various teams.
Each team created its own solution to solve a specific problem. While this worked in the short term, it created bigger issues over time. The various systems behaved differently. There was no clear responsibility when something broke, and overall reliability suffered. In a company handling huge amounts of data, this kind of fragmentation quickly became a bottleneck.
To solve these problems, the Pinterest Engineering team decided to build a single generic CDC platform that everyone could use. The goal was to provide one reliable and scalable system instead of many separate ones. This approach would reduce duplication of effort, make upgrades easier, and give teams a consistent way to capture and process database changes.
The new generic CDC platform was designed with several clear goals, such as:
The system should process data quickly and ensure that no changes are missed. It should guarantee at least once processing, which means every change is captured and delivered at least once, even if retries are needed.
Pinterest operates databases with up to 10,000 shards. The platform needed to handle this scale without major performance issues.
The system had to distribute work evenly across machines while minimizing the impact on the original databases.
Teams needed flexibility to adjust settings for their use cases and access detailed metrics to track system health.
Architecture Overview
Pinterest’s databases are extremely large and distributed. Instead of storing all data in one place, the company divides it into thousands of smaller parts called shards.
A shard is simply a portion of the database that can be stored and managed separately. This design helps scale the system to handle millions of queries per second, but it also makes tasks like Change Data Capture more complicated.
Pinterest chose to build its CDC system on top of Red Hat Debezium, an open-source platform that tracks database changes and streams them into systems like Kafka.
Debezium works well when dealing with a single shard, but Pinterest needed a way to manage thousands of shards at once. Instead of changing Debezium’s code directly, which would make future upgrades hard, the Pinterest Engineering team decided to split the system into two layers: a control plane and a data plane. This separation allowed them to scale without heavily modifying the underlying tools.
See the diagram below:
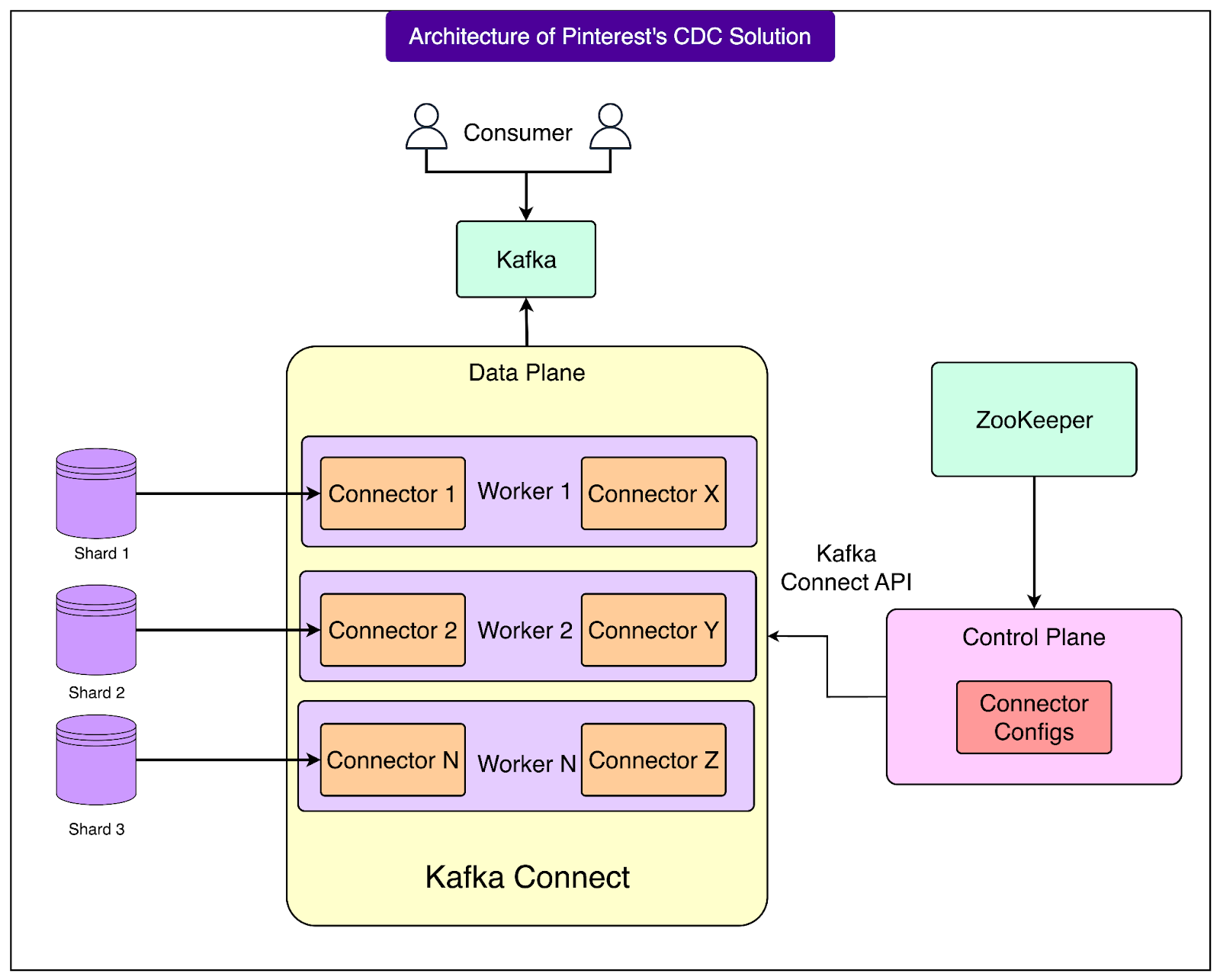
Control Plane
The control plane acts as a central coordinator. Its job is to make sure that all the Debezium connectors (the components that read database changes) are correctly set up, running smoothly, and automatically fixed if something goes wrong.
It runs on a single EC2 host in an AWS Auto Scaling Group. The group is set with a minimum and maximum size of one machine. This means if the machine goes down, AWS will automatically replace it.
The control plane executes its main loop once every minute. Its workflow has three main steps:
Determine the ideal state: It reads the connector configuration and the database topology from ZooKeeper, which stores information about all shards. This gives a clear picture of how many connectors should be running and what their configurations should be.
Check the current state: It then queries Kafka Connect to see what connectors are actually running and how they are configured at that moment.
Reconcile differences: If there are new shards, they create new connectors. If existing configurations are outdated, it updates them. If any connectors have failed, it restarts them.
After completing these steps, the control plane emits detailed metrics that help engineers monitor the health and performance of the system.
Data Plane
The data plane is where the real CDC work happens. This is the layer that connects directly to databases, reads the changes, and streams them into Kafka.
Here are some key details about it:
It runs Kafka Connect in distributed mode on a separate cluster that spans three Availability Zones (AZs) in AWS. Using multiple AZs makes the system more resilient because even if one zone has issues, the others keep running.
All machines in this cluster are part of the same Kafka Connect group. This allows them to share the work automatically.
Each machine can run multiple Debezium connectors, and each connector handles a single database shard.
As data changes occur in the shards, these connectors stream the changes into Kafka topics for downstream systems to consume.
Kafka Layer
At the center of the system is Apache Kafka, which acts like a durable, high-speed messaging backbone. It plays three important roles:
Storing connector metadata: Kafka keeps internal records about all connectors in special topics. These topics are not visible to end users but are critical for coordination.
Storing CDC data: All captured database changes are written into pre-configured Kafka topics. These topics are then available for any system or team at Pinterest that wants to consume real-time data.
Coordinating distributed workers: Kafka Connect uses a subset of Kafka brokers to manage coordination tasks such as leader election (deciding which machine takes the lead in managing tasks) and keeping workers synchronized.
Technical Challenges and Solutions
Building a CDC system at Pinterest’s scale brought several real-world challenges. The platform processes millions of queries per second and terabytes of data every day, which can push even well-designed systems to their limits.
The Pinterest Engineering team encountered multiple issues during deployment and scaled the system through targeted technical solutions. Let’s look at a few of the major challenges:
Scalability and Out-of-Memory (OOM) Errors
Some datasets were so large that they created backlogs in the CDC tasks. A backlog happens when incoming data changes accumulate faster than the system can process them. This caused out-of-memory (OOM) errors, where CDC tasks ran out of available memory and failed.
To handle this, Pinterest introduced bootstrapping from the latest offset, which means that when a new CDC task starts, it begins reading from the most recent point in the data stream instead of replaying the entire historical dataset.
This reduced the amount of data the task had to process at startup. They also added rate limiting, which controls how quickly data is ingested to prevent memory from being overwhelmed.
Rebalancing Timeout Issues
Each CDC connector is assigned to a host machine. With around 3,000 connectors per cluster, Pinterest saw frequent task rebalancing in Kafka Connect. Rebalancing is the process of redistributing tasks across available hosts. However, in this case, it happened too often and unpredictably.
Some problems were as follows:
All connectors were temporarily shifting to a single host, causing overload.
High latency during deployments and failovers.
Increased risk of duplicate tasks, where more than one host processes the same data.
The root cause was that the default rebalance.timeout.ms setting was too short. Kafka Connect did not wait long enough before moving tasks, causing constant reshuffling.
Pinterest increased the rebalance timeout to 10 minutes, giving Kafka Connect enough time to stabilize task assignments. This led to a more balanced and predictable distribution of work across hosts.
Failover Recovery Delays
Pinterest’s key-value (KV) store clusters could take more than two hours to perform a leader failover. A leader failover occurs when the main server in a cluster goes down and leadership shifts to another server. During this period, CDC tasks would fail because they were still pointing to the old leader.
The control plane reacted by deleting and recreating tasks repeatedly, which caused constant rebalancing over long periods.
Pinterest allowed CDC workers themselves to handle shard discovery and failover instead of relying on the control plane for this. This change reduced failover recovery latency to under one minute and avoided unnecessary task reshuffling.
Duplicate Tasks and CPU Overload
A known Kafka bug (KAFKA-9841) caused multiple hosts to run duplicate instances of the same CDC task. This created several problems:
Duplicate data was sent downstream.
Workloads became uneven across hosts.
Frequent rebalances occurred.
CPU usage spiked to 99 percent, pushing systems to their limit.
Pinterest upgraded to Kafka 2.8.2 version 3.6, which included a fix for this bug. They also kept the rebalance timeout at the increased value. After applying these changes:
Each task ran on a single host as expected.
CPU usage dropped to a stable level of around 45 percent.
The system was able to run 3,000 tasks cleanly without the instability seen earlier.
Conclusion
Pinterest’s journey with Change Data Capture offers a practical look at how to run open-source data tools at massive scale. By building on top of Debezium and Kafka, the Pinterest Engineering team created a system that can handle thousands of database shards and millions of queries per second, all while keeping data flowing reliably in real time.
A major strength of their design is the clear separation between the control plane and the data plane. The control plane acts as a centralized coordinator, managing connector configurations and ensuring everything stays in sync. The data plane focuses on streaming actual database changes across a distributed cluster. This split allowed Pinterest to scale without modifying the core Debezium code, which keeps the system easier to maintain and upgrade in the future.
Pinterest also demonstrated that operating CDC at this scale requires attention to the small details. Problems like frequent task rebalancing, long failover times, memory overload, and duplicate tasks required careful tuning, configuration changes, and targeted upgrades.
References:
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are, what you do, and how I can improve ByteByteGo
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.