
How RAG Enables AI For Your Data

✂️ Cut your QA cycles down to minutes with QA Wolf (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobiles apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guarantee
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
Large Language Models like GPT-4 and Claude have transformed the way we interact with computers. However, despite their incredible utility in general scenarios, they face fundamental limitations that prevent them from being immediately useful in many business contexts.
Some of these limitations are as follows:
The LLM's knowledge is often frozen at its training cutoff date. If we ask GPT-4 about events that happened after its training data was collected, it simply won't know unless it connects to the Internet to gather information.
LLMs cannot access private company data. An organization's internal documentation, customer records, product specifications, and proprietary processes are not part of any public model's training data. When employees ask questions about company policies or customers inquire about specific products, a standard LLM can only provide generic responses based on common patterns it may have learned from public internet data.
LLMs also suffer from hallucination, where they generate plausible-sounding but incorrect information. When asked about specific details they don't know, they might confidently provide made-up facts, invent citations, or create fictional scenarios.
Even when LLMs have relevant knowledge, their responses can tend to be generic rather than specific to the required context.
Retrieval-Augmented Generation or RAG solves these problems by giving AI systems access to specific documents and data.
Instead of relying solely on what the model learned during training, RAG allows the system to look up relevant information from a particular document collection before generating a response. Think of it as providing the AI with a reference library it can consult whenever it needs to answer a question.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo
CodeRabbit: Free AI Code Reviews in CLI (Sponsored)

CodeRabbit CLI is an AI code review tool that runs directly in your terminal. It provides intelligent code analysis, catches issues early, and integrates seamlessly with AI coding agents like Claude Code, Codex CLI, Cursor CLI, and Gemini to ensure your code is production-ready before it ships.
Enables pre-commit reviews of both staged and unstaged changes, creating a multi-layered review process.
Fits into existing Git workflows. Review uncommitted changes, staged files, specific commits, or entire branches without disrupting your current development process.
Reviews specific files, directories, uncommitted changes, staged changes, or entire commits based on your needs.
Supports programming languages including JavaScript, TypeScript, Python, Java, C#, C++, Ruby, Rust, Go, PHP, and more.
Offers free AI code reviews with rate limits so developers can experience senior-level reviews at no cost.
Flags hallucinations, code smells, security issues, and performance problems.
Supports guidelines for other AI generators, AST Grep rules, and path-based instructions.
What is RAG?
At its core, Retrieval-Augmented Generation is a technique that combines two different processes into one system:
Retrieve relevant information from a collection of documents.
Generate an accurate response by using that information.
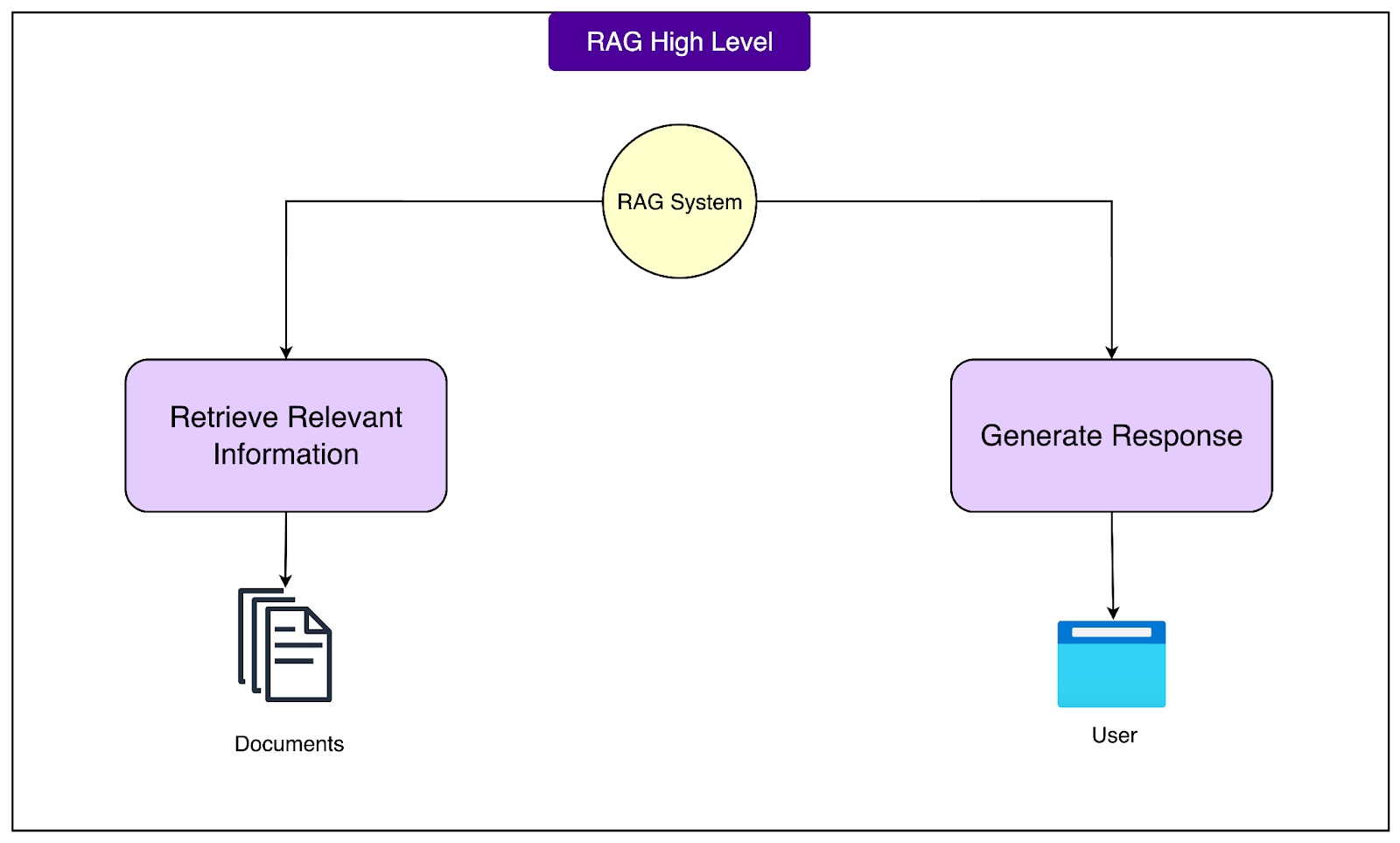
The name itself tells the story. We retrieve relevant documents first, then augment the generation process with that retrieved context.
Imagine walking into a library and asking the librarian a specific question about the local tax code. A regular librarian might share general knowledge about taxes, but a librarian with access to the city's specific tax documents could walk to the right shelf, pull out the relevant manual, read the specific section, and give an exact answer based on those official documents. This is what RAG does.
The difference between RAG and asking an LLM directly is significant. When we ask a standard LLM about a company's vacation policy, it might respond with generic information about typical vacation policies it learned during training. It might say something like "Many companies offer two to three weeks of paid vacation" because that's a common pattern it may have seen.
With RAG, the system first retrieves the actual employee handbook, finds the section about vacation policy, and then generates a response based on that specific document. The answer would be "According to the employee handbook, full-time employees receive 15 days of paid vacation in their first year, increasing to 20 days after three years of service."
See the diagram below for a high-level view of how RAG works:
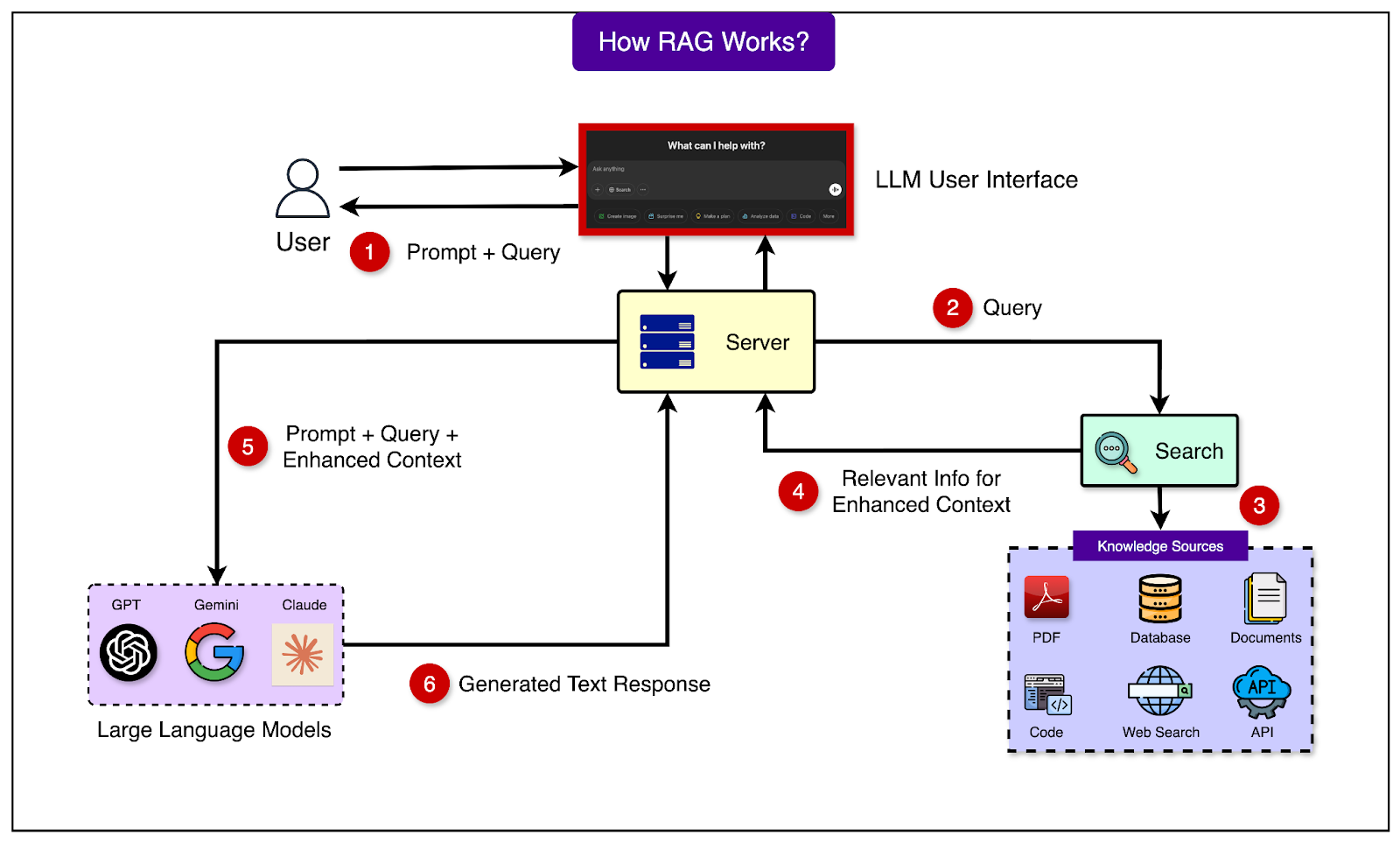
Understanding when we need RAG and when a standard LLM is sufficient is an important factor in making good architectural decisions. Some of the cases when RAG is more useful are as follows:
When the use case involves information that changes frequently, such as product inventories, pricing, or news.
When working with private or proprietary information that wasn't part of the model's training data, like internal documentation, customer records, or confidential research.
When accuracy is critical and hallucination is unacceptable, such as in legal, medical, or financial applications.
When it is important to provide citations or prove where the information came from. The system can point to specific documents and passages, providing transparency and auditability that's impossible with standard LLM responses.
When the application needs to handle large document collections that would be impractical to include in every prompt, RAG's selective retrieval becomes invaluable.
On the other hand, we don't need RAG for general knowledge questions that the LLM can already handle quite well, like explaining common concepts, performing basic reasoning, or creative writing tasks.
How RAG Works - The Journey of a Query
This journey involves two distinct phases that happen at different times:
Document preparation, which occurs once when setting up the system. This can also happen later on when new documents or sources of information are added to the system.
Query processing which happens in real-time whenever a user asks a question.
This two-phase approach is powerful because of the separation of concerns it provides between the computationally intensive document-preparation phase and the latency-sensitive query phase.
Let’s look at both phases in more detail:
1 - Preparation
The document preparation phase is like organizing a library before it opens. This foundational work happens before any user queries arrive and involves several crucial steps. See the diagram below:
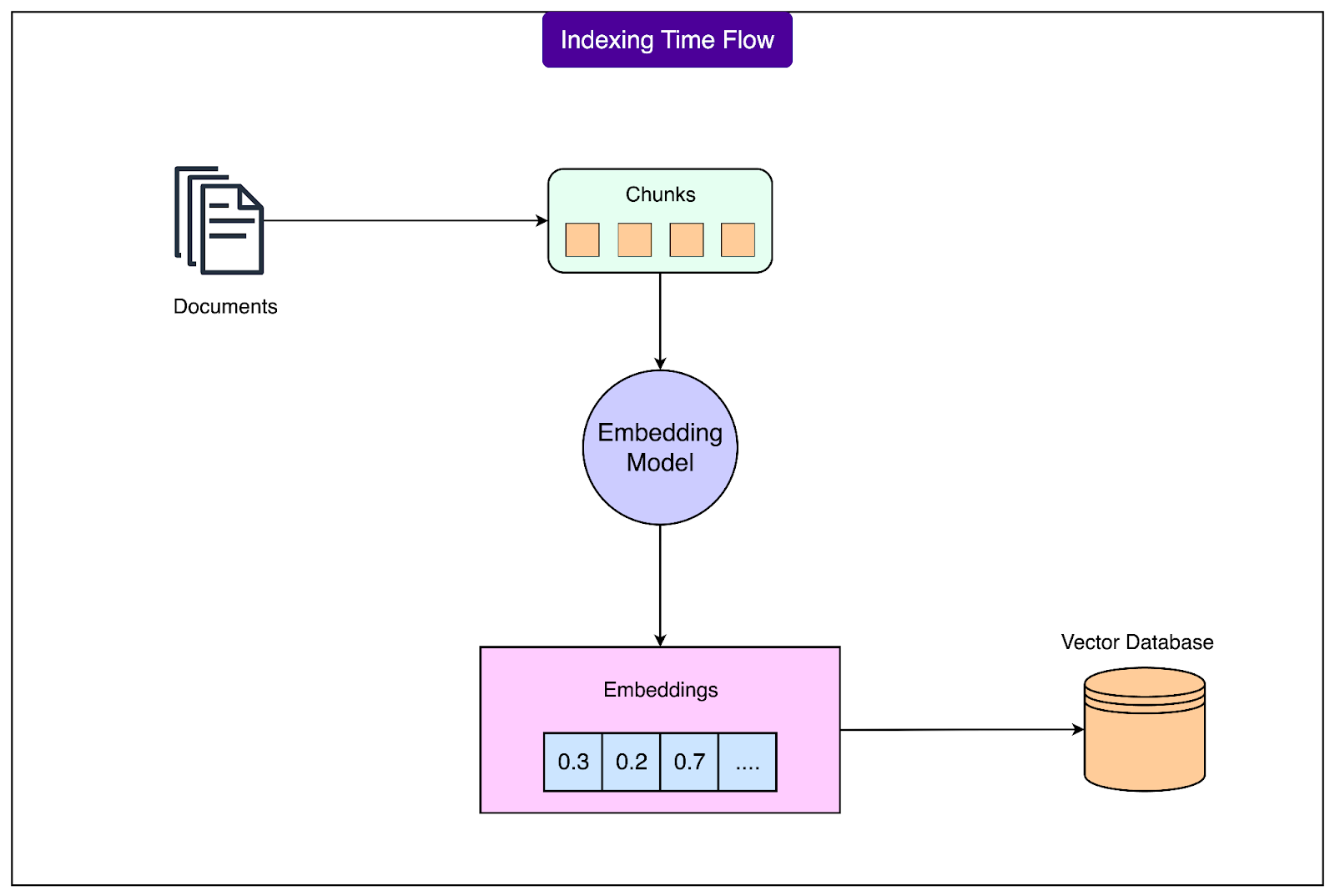
The overall process works as follows:
First, the documents need to be collected and processed. Each document (PDFs, Word documents, web pages, or database records) must be converted into plain text that the system can work with. This extraction process handles various formats and ensures that the actual content is cleanly separated from formatting and metadata.
Once the text is extracted, the system breaks it into smaller chunks. This chunking is necessary because documents are usually too long to process as single units. A 50-page technical manual might be split into hundreds of smaller passages, each containing a few paragraphs. The size of these chunks matters. Too small, and they lack context. Too large, and they become less precise. Most systems use chunks of 500 to 1000 words, often with some overlap between consecutive chunks to preserve context across boundaries.
The next step transforms these text chunks into numerical representations known as embeddings. Each chunk gets converted into a list of numbers that captures its semantic meaning. For example, a chunk about "quarterly financial reports" might become a vector like [0.23, -0.45, 0.67, ...] with hundreds or thousands of dimensions. These numbers encode the meaning of the text in a way that allows mathematical comparison. Similar concepts produce similar number patterns, which enables the system to find related content even when different words are used.
These embeddings, along with the original text chunks and their metadata, are then stored in a specialized vector database. This database is optimized for finding similar vectors. It indexes the embeddings in a way that allows rapid similarity searches across millions of chunks. The metadata stored alongside each chunk typically includes the source document, page numbers, timestamps, and any other relevant information that might be useful for filtering or attribution.
2 - User Query Processing
When a user submits a query, the real-time query processing phase begins. This phase needs to be fast and efficient since users expect quick responses.
See the diagram below for a high level view of the process:
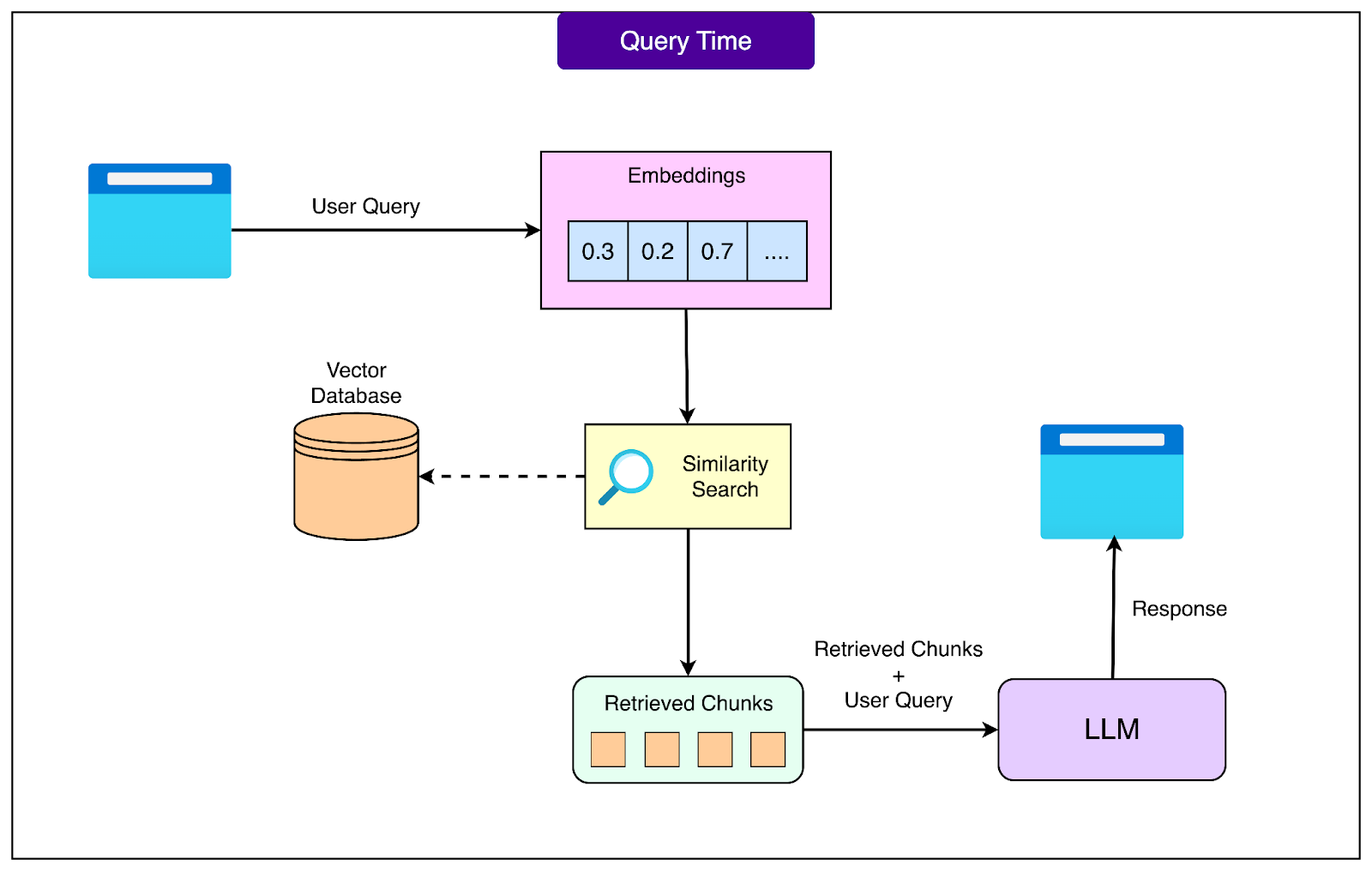
Here’s how it works in more detail:
The journey starts when the user's question enters the system. That question first goes through the same embedding process as the document chunks. For example, the question "What is our refund policy for electronics?" gets converted into its own numerical vector using the same embedding model that processed the documents.
With the query now in vector form, the system searches the vector database for the most similar document chunks. This similarity search is fast because it uses mathematical operations rather than text comparison. The database might contain millions of chunks, but specialized algorithms can find the most relevant ones in milliseconds. Typically, the system retrieves the top 3 to 10 most relevant chunks based on their similarity scores.
These retrieved chunks then need to be prepared for the language model. The system assembles them into a context, often ranking them by relevance and sometimes filtering based on metadata or business rules. For instance, more recent documents might be prioritized over older ones, or certain sources might be considered more authoritative than others.
The language model now receives both the user's original question and the retrieved context. The prompt might contain the following details:
Context documents provided.
User's specific question.
Instructions to answer based on the provided context.
Guidelines for handling information not found in the context.
The language model processes this augmented prompt and generates a response. Since it has specific, relevant information in its context, the response can be accurate and detailed rather than generic. The model can quote directly from the retrieved documents, synthesize information from multiple chunks, and provide specific answers grounded in the source material.
Finally, the response often goes through post-processing before reaching the user. This might include adding citations that link back to source documents, formatting the response for better readability, or checking that the answer properly addresses the question. Some systems also log the query, retrieved documents, and response for analytics and improvement purposes.
Embeddings - The Heart of RAG
The fundamental challenge in information retrieval is that people express the same ideas in countless different ways. Traditional keyword search, which looks for exact word matches, fails to capture these variations.
For example, if the document says "The company permits product returns within 30 days", but a user searches for "How long can I send items back?", the keyword search finds nothing despite the obvious relationship between these texts.
Consider the variety of ways someone might ask about a computer problem: "laptop won't start," "computer fails to boot," "system not powering on," or "PC is dead." These phrases share almost no common words, yet they all describe the same issue. A keyword-based system would treat these as completely different queries and miss troubleshooting guides that use different terminology. This vocabulary mismatch problem has plagued information retrieval systems for decades.
Embeddings solve this by capturing semantic meaning rather than surface-level word matches.
Semantic meaning refers to what the text actually means, not just the specific words used. When text gets converted to embeddings, the resulting numbers represent the concepts and ideas in that text. Sentences about returning products end up with similar number patterns, whether they use words like "return," "refund," "send back," or "exchange."
The process of converting text to numbers might seem mysterious, but the principle is straightforward.
An embedding model reads the text and outputs a list of numbers, typically hundreds or thousands of them.
These numbers position the text as a point in a multi-dimensional space.
We think of this like coordinates on a map, except instead of just two dimensions like latitude and longitude, embeddings use hundreds of dimensions to capture the many nuances of meaning.
See the diagram below:
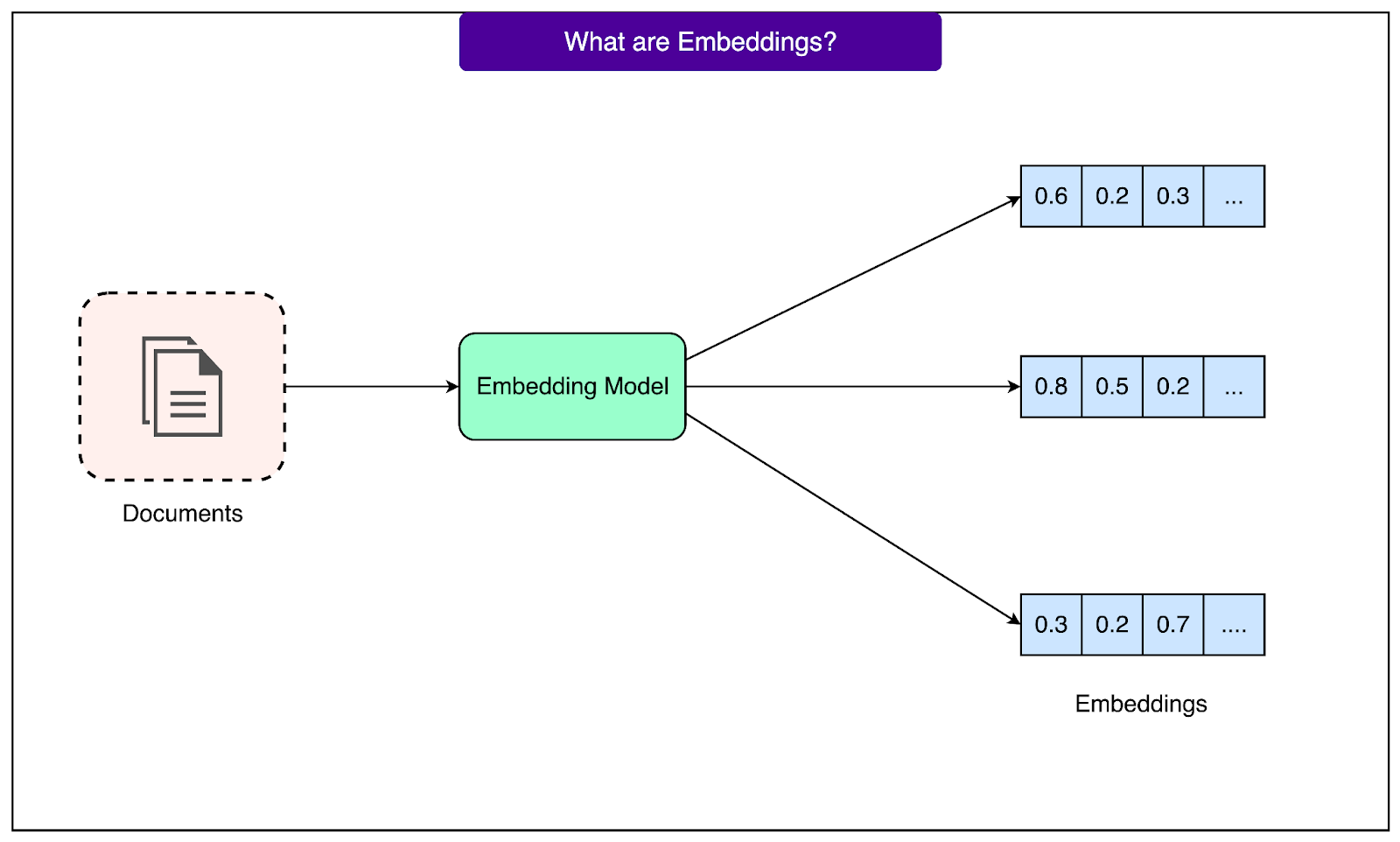
This numerical representation enables mathematical operations that would be impossible with raw text. Most importantly, we can calculate the distance between two embeddings to measure how similar their meanings are. For example, text about "laptop repairs" and "computer fixes" will have embeddings that are close together in this space, while "laptop repairs" and "cooking recipes" will be far apart. This distance calculation happens through simple mathematics, making it extremely fast even with millions of documents.
The reason similar meanings create similar number patterns comes from how embedding models are trained.
During training, the model sees millions of examples of text and learns that certain words and phrases appear in similar contexts. For example, words like "doctor" and "physician" show up in similar sentences, get used interchangeably, and relate to the same concepts. The model learns to assign them similar numerical patterns. This learning happens automatically through exposure to vast amounts of text, without anyone explicitly programming these relationships.
What makes embeddings particularly fascinating is that we don't fully understand what each dimension represents. When an embedding model outputs 768 numbers for a piece of text, we can't simply say dimension 1 represents "formality" or dimension 547 represents "technical complexity." These dimensions emerge naturally during training as the model figures out what patterns it needs to track to understand language effectively. Some dimensions might loosely correlate with concepts we recognize, like sentiment or topic, but many capture abstract patterns that don't map to any concept we have words for.
It's important to understand that embedding models and large language models serve completely different purposes in an RAG system.
An embedding model is specialized for one task: converting text to meaningful numbers. It cannot generate text, answer questions, or hold conversations. It simply reads text and outputs vectors. These models are relatively small, fast, and efficient at their single job.
In contrast, LLMs are massive models designed to understand and generate human-like text. They can write, answer questions, summarize, translate, and perform countless other language tasks. However, they're much larger, slower, and more expensive to run than embedding models.
This specialization is why RAG systems use two separate models. The embedding model efficiently converts all the documents and queries into vectors, enabling fast similarity search. The LLM then takes the retrieved relevant documents and generates intelligent, contextual responses.
Building an RAG System
When building a retrieval-augmented generation (RAG) system, the first step is understanding the requirements clearly. As with most systems, everything begins with the users. Some questions that should be asked are as follows:
Is the system being designed for internal employees, where speed is less important than accuracy and reliability?
Or for external customers, where fast responses and a polished experience matter most?
Next, we need to look closely at the document landscape. The scale matters in terms of handling a hundred files or hundreds of thousands. Different volumes demand different storage and retrieval strategies. The possible types of content (PDFs, Word docs, Confluence pages, or Notion databases) determine the ingestion and preprocessing pipelines. Equally important is understanding the query patterns by answering questions as follows:
Are most queries straightforward lookups, such as “What’s our vacation policy?”, or do they require complex reasoning like “Compare Q3 and Q4 sales strategies”?
Do users expect citations and audit trails, or just conversational answers?
The answer to these questions defines how sophisticated the system must be. Once requirements are clear, we can move to the technology stack. Some of the most popular tools and technologies are as follows:
At the heart of the system lies the large language model (LLM). Closed-source options like OpenAI’s GPT-4, Anthropic’s Claude, Google’s Gemini, or Cohere’s enterprise models are easy to adopt and deliver strong performance, but they come with vendor lock-in and data privacy concerns. Open-source models like Llama 3, Mistral, or specialized domain models (BioBERT for medicine and FinBERT for finance) give more control and flexibility, but require GPU infrastructure and in-house expertise to run at scale.
Alongside the LLM, we need an embedding model. OpenAI’s text-embedding-3 or Cohere’s embed-v3 are common choices, while open-source sentence-transformers offer free alternatives. Specialized models such as E5 or Instructor embeddings can further improve domain-specific accuracy. An important point to note is that the LLM and embedding model don’t need to come from the same provider.
The third building block is the vector database, where embeddings are stored and searched. Cloud-managed services like Pinecone, Weaviate Cloud, or Qdrant Cloud are excellent for getting started quickly and scaling smoothly, though they come at a higher price. Self-hosted solutions like ChromaDB, Milvus, Elasticsearch with vector search, or PostgreSQL’s pgvector extension give more control and may be cheaper long-term, but require DevOps investment. The right choice depends on the data volume (hundreds of thousands versus billions of vectors), query load (dozens versus tens of thousands of requests per second), and budget.
Finally, we need an orchestration framework. Few teams build everything from scratch. LangChain is the most popular, with a wide ecosystem and abstractions for nearly every component, though it can feel heavy for simple cases. LlamaIndex is designed specifically for document-heavy RAG applications and offers clean data ingestion and query pipelines. Haystack is production-focused, with strong support for complex workflows.
Conclusion
Retrieval-Augmented Generation represents a practical solution to the very real limitations of LLMs in business applications. By combining the power of semantic search through embeddings with the generation capabilities of LLMs, RAG enables AI systems to provide accurate, specific answers based on the organization's own documents and data.
Understanding RAG's core concepts helps make informed decisions about whether it's right for a particular use case. If we need AI that can access private company information, provide current updates, cite sources, or maintain strict accuracy, RAG is likely the answer. The two-phase architecture of document preparation and query processing makes it scalable and efficient, while the use of embeddings ensures that users find relevant information regardless of how they phrase their questions.
The field of RAG continues evolving rapidly, with improvements in retrieval techniques, better embedding models, and more sophisticated generation strategies. However, the fundamental principles covered here remain constant.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Best article on RAG!
Very well broken down. Easy to understand.