
How Reddit Migrated Comments Functionality from Python to Go

Unwrap Unbeatable Holiday Deals with Verizon (Sponsored)

Reliability shouldn’t cost extra—and Verizon proves it this holiday season. Switch to Verizon and get four lines on Unlimited Welcome for $25 per line/month (with Auto Pay, plus taxes and fees) and everyone gets one of the hottest devices, all on them. No trade-in required. Devices include:
Everyone gets a better deal—flexibility, savings, and support with no extra cost.
Explore Holiday Deals and see here for terms.
Disclaimer: The details in this post have been derived from the details shared online by the Reddit Engineering Team. All credit for the technical details goes to the Reddit Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When you upvote a clever comment on Reddit or reply to a discussion thread, you’re interacting with their Comments model. This model is probably the most important and high-traffic model in Reddit’s architectural setup.
Reddit’s infrastructure was built around four Core Models: Comments, Accounts, Posts, and Subreddits.
These models power virtually everything users do on the platform. For years, all four models were served from a single legacy Python service, with ownership awkwardly split across different teams. By 2024, this monolithic architecture had become a problem:
The service suffered from recurring reliability and performance issues.
Maintaining it had become increasingly difficult for all teams involved.
Ownership responsibilities were unclear and fragmented.
In 2024, the Reddit engineering team decided to break up this monolith into modern, domain-specific Go microservices.
They chose comments as their first migration target because it represented Reddit’s largest dataset and handled the highest write throughput of any core model. If they could successfully migrate comments, they would prove their approach could handle anything.
In this article, we will look at how Reddit carried out this migration and the challenges it faced.
The Easy Part: Migrating Read Operations
Before diving into the complex scenario, it’s worth understanding how Reddit approached the simpler part of this migration: read endpoints.
When you view a comment, that’s a read operation. The server fetches data from storage and returns it to you without changing anything.
Reddit used a testing technique called “tap compare” for read migrations. The concept is straightforward:
A small percentage of traffic gets routed to the new Go microservice.
The new service generates its response internally.
Before returning anything, it calls the old Python endpoint to get that response too.
The system compares both responses and logs any differences.
The old endpoint’s response is what actually gets returned to users.
This approach meant that if the new service had bugs, users never saw them. The team got to validate their new code in production with real traffic while maintaining zero risk to user experience.
The Hard Part: Migrating Write Operations
Write operations are an entirely different challenge. When you post a comment or upvote one, you’re modifying data.
Reddit’s comment infrastructure doesn’t just save your action to one place. It writes to three distinct datastores simultaneously:
Postgres: The primary database where all comment data lives permanently.
Memcached: A caching layer that speeds up reads by keeping frequently accessed comments in fast memory.
Redis: An event store for CDC (Change Data Capture) events that notify other services whenever a comment changes.
The CDC events were particularly critical. Reddit guarantees 100% delivery of these events because downstream systems across the platform depend on them. Miss an event, and you could break features elsewhere.
The team couldn’t simply use basic tap compare for writes because of a fundamental constraint: comment IDs must be unique. You can’t write the same comment twice to the production database because the unique key constraint would reject it.
But without writing to production, how do you validate that your new implementation works correctly?
The Sister Datastore Solution
Reddit’s engineering team came up with a solution they called “sister datastores”. They created three completely separate datastores that mirrored their production infrastructure (Postgres, Memcached, and Redis). The critical difference was that only the new Go microservice would write to these sister stores.
Here’s how the dual-write flow worked:
A small percentage of write traffic is routed to the Go microservice.
Go calls the legacy Python service to perform the real production write.
Users see their comments posted normally (Python is still handling the actual work).
Go performs its own write to the completely isolated sister datastores.
After both writes are complete, the system compares production data against sister data.
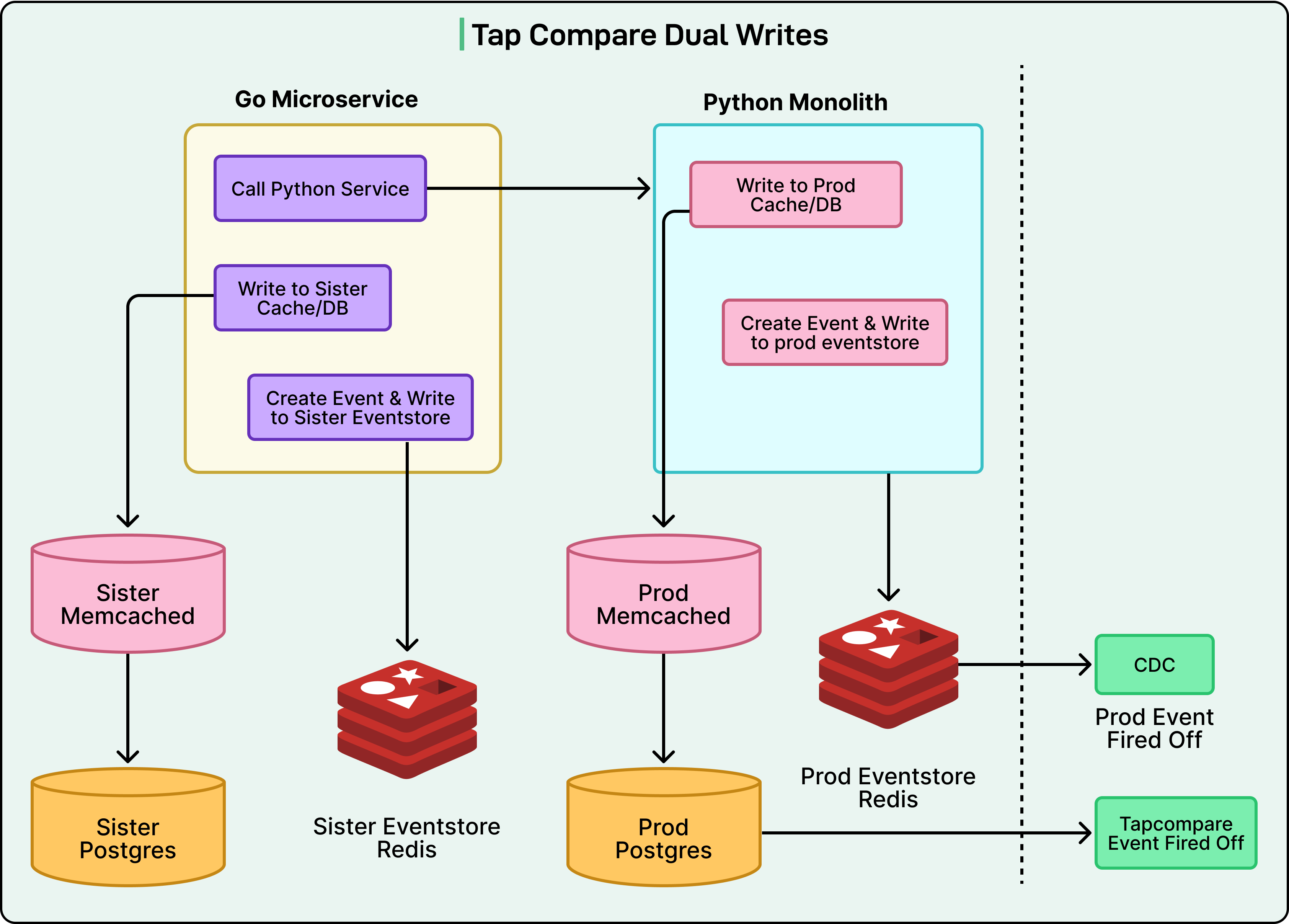
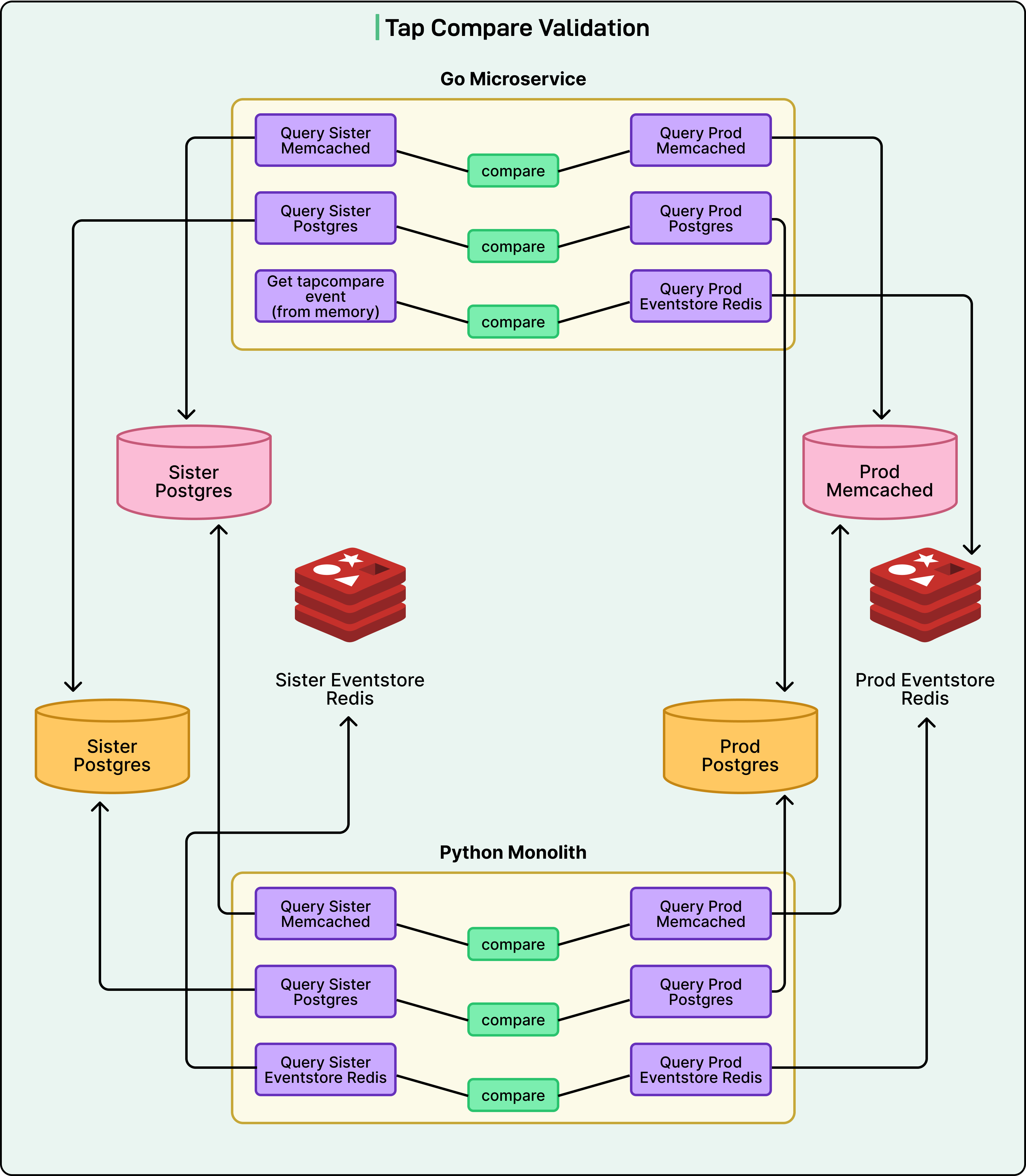
This comparison happened across all three datastores. The Go service would query both production and sister instances, compare the results, and log any differences. The beauty of this approach was that even if Go’s implementation had bugs, those bugs would only affect the isolated sister datastores, never touching real user data.
The Scale of Verification
The verification process was substantial. Reddit migrated three write endpoints:
Create Comment: Posting new comments
Update Comment: Editing existing ones
Increment Comment Properties: Actions like upvoting
Each endpoint wrote to three datastores, and data had to be verified across two different service implementations. This resulted in multiple comparisons running simultaneously, each requiring careful validation and bug fixing.
But even this wasn’t enough. Early in the migration, the team discovered serialization problems. Serialization is the process of converting data structures into a format that can be stored or transmitted. Different programming languages serialize data differently. When Go wrote data to the datastores, Python services sometimes couldn’t deserialize (read back) that data correctly.
To catch these problems, the team added another verification layer.
They ran all tap comparisons through actual CDC event consumers in the legacy Python service. This meant Python code would attempt to deserialize and process events written by Go. If Python could successfully read and handle these events, they knew cross-language compatibility was working. This end-to-end verification ensured not just that Go wrote correct data, but that the entire ecosystem could consume it.
Challenges With Different Languages
Migrating between programming languages introduced unexpected complications beyond serialization.
One major issue involved database interactions. Python uses an ORM (Object-Relational Mapping), which is a tool that simplifies database queries. Reddit’s Go services don’t use an ORM and instead write direct database queries.
It turned out that Python’s ORM had hidden optimizations that the team didn’t fully understand. When they started ramping up the Go service, it put unexpected pressure on the Postgres database. The same operations that ran smoothly in Python were causing performance issues in Go.
Fortunately, they caught this early and optimized their Go queries. They also established better monitoring for database resource utilization. This experience taught them that future migrations would need careful attention to database access patterns, not just application logic.
The Race Condition Problem
Another tricky issue was race conditions in the tap compare logs.
The team started seeing mismatches that didn’t make sense. They would spend hours investigating, only to discover that the “bug” wasn’t a bug at all, but a timing problem.
Here’s an example scenario:
User updates a comment, changing the text to “hello”
Go writes “hello” to the sister datastore
Go calls Python to write “hello” to production
In those milliseconds, another user edits the same comment to “hello again”
When Go compares its write against production, they don’t match
These timing-based false positives made debugging difficult.
Was a mismatch caused by a real bug in the Go implementation, or just unlucky timing?
The team developed custom code to detect and ignore race condition mismatches. For future migrations, they plan to implement database versioning, which would let them compare only updates that happened from the same logical change.
Interestingly, this problem was specific to certain datastores:
Redis eventstore: No race condition issues because they used unique event IDs
Postgres and Memcached: Race conditions were common and needed special handling
Testing Strategy and Comment Complexity
Much of the migration time was spent manually reviewing tap compare logs in production.
When differences appeared, engineers would investigate the code, fix issues, and verifthat y those specific mismatches stopped appearing. Since tap compare logs only capture differences, once a problem was fixed, those logs would disappear.
This production-heavy testing approach worked, but it was time-consuming. The team realized they needed more comprehensive local testing before deploying to production. Part of the challenge was the sheer complexity of comment data.
A comment might seem like simple text, but Reddit’s comment model includes numerous variations:
Simple text vs rich text formatting vs media content
Photos and GIFs with different dimensions and content types
Subreddit-specific workflows (some use Automod requiring approval states)
Various types of awards that can be attached
Different moderation and approval states
All these variations create thousands of possible combinations for how a single comment can be represented in the system. The initial testing strategy covered common use cases locally, then relied on “tap compare” in production to surface edge cases. For future migrations, the team plans to use real production data to generate comprehensive test cases before ever deploying to production.
Why Go Instead of Python Microservices?
An important question that can come up in this scenario is this: if language differences caused so many problems, why not just create Python microservices instead?
Just sticking to Python would have avoided serialization issues and database access pattern changes entirely.
The answer reveals Reddit’s strategic infrastructure direction. Reddit’s infrastructure organization has made a strong commitment to Go for several reasons:
Concurrency advantages: For high-traffic services, Go can run fewer pods while achieving higher throughput than Python.
Existing ecosystem: Go is already widely used across Reddit’s infrastructure.
Better tooling: The existing Go support makes development easier and more consistent.
The engineering team considered only Go for this migration. From their perspective, the strategic long-term benefits of standardizing on Go outweighed the short-term challenges of cross-language compatibility.
Conclusion
The migration succeeded completely. All comment endpoints now run on the new Golang microservice with zero disruption to users. Comments became the first of Reddit’s four core models to fully escape the legacy monolith.
While the primary goal was maintaining performance parity while improving reliability, the migration delivered an unexpected bonus: all three migrated write endpoints saw their p99 latency cut in half. P99 latency measures how long the slowest 1% of requests take, which matters because those slow requests represent the worst user experience.
The improvements were substantial:
The legacy Python service occasionally had latency spikes reaching 15 seconds
New Go service shows consistently lower and more stable latency
Typical latency stays well under 100 milliseconds
See the charts below that show the latency improvements for various scenarios:
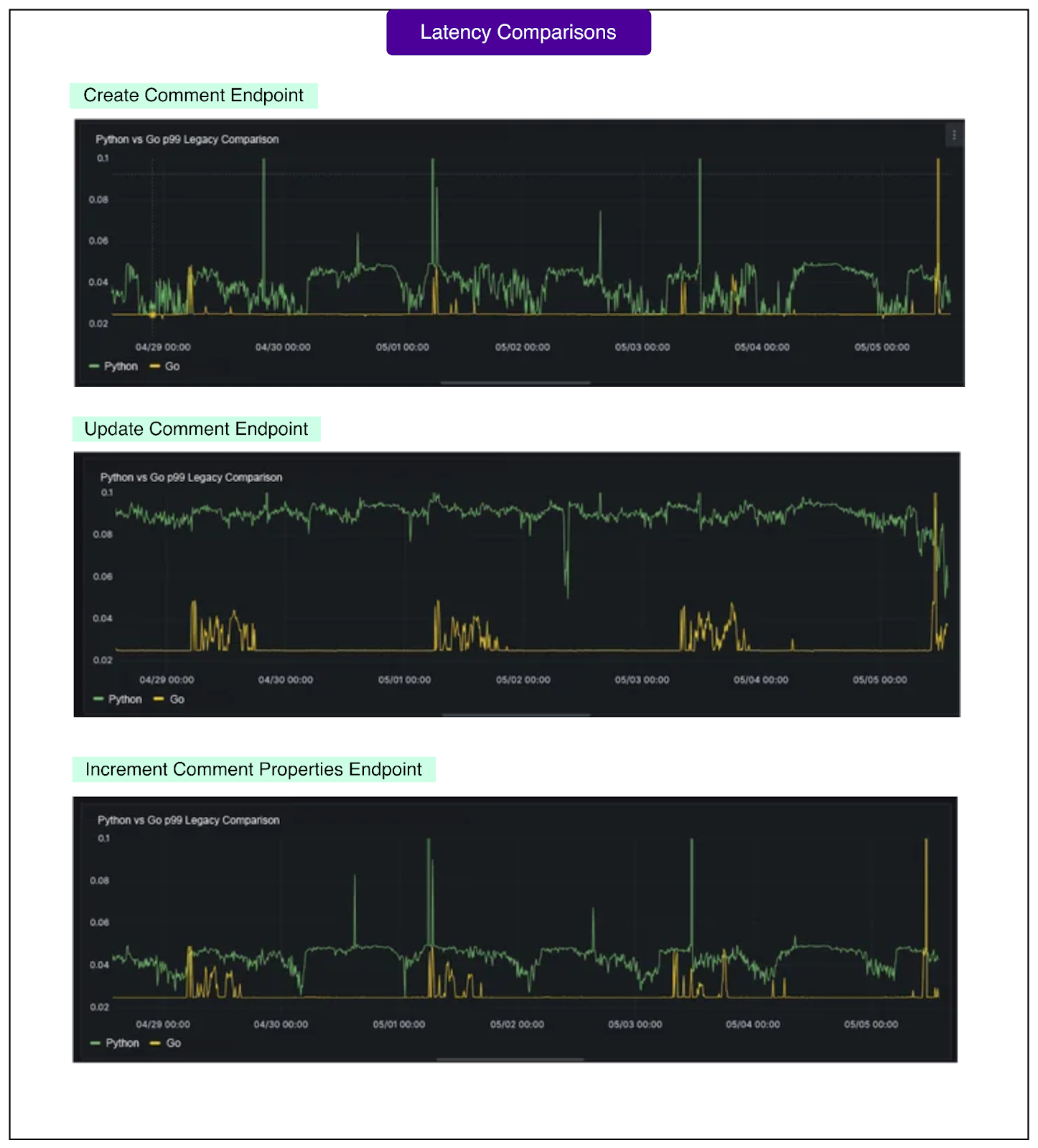
The migration also provided some valuable lessons for future work:
Database versioning is essential for handling race conditions properly by tracking which version of data is being compared
Comprehensive local testing informed by real production data will reduce debugging time in production
Database monitoring matters when changing how services access data, not just when changing application logic
End-to-end verification must include actual downstream consumers, not just byte-level data comparison
Custom tooling helps automate parts of the manual review process (like their race condition detection code)
As they continue migrating the remaining core models (Accounts have been completed, while Posts and Subreddits are in progress), these lessons will make each subsequent migration smoother.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Thanks for such a great content. Awesome 🔥🙌
Some good content, but felt like too much AI Slopness in this article. Feel like the quality of the Newsletter is going down.
Funny to see even the comments seem from Bots/AI