
How Shopify Manages its Petabyte Scale MySQL Database

Generate Handwritten SDKs (Sponsored)

Invest hundreds of hours your team doesn't have in maintaining SDKs by hand or generate crappy SDKs that leave a bad taste in your users' mouths. That's two bad options. Fortunately, you can now use Speakeasy to generate ergonomic type-safe SDKs in over 10 languages. We've worked with language experts to create a generator that gets the details right. With Speakeasy you can build SDKs that your team is proud of.
Disclaimer: The details in this post have been derived from the article originally published on the Shopify Engineering Blog. All credit for the details about Shopify’s architecture goes to their engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Shopify has revolutionized the e-commerce landscape by empowering small business owners to establish and grow their online presence.
With millions of merchants relying on their platform globally, Shopify’s infrastructure has evolved to handle the ever-increasing demands of their user base.
At the heart of Shopify’s infrastructure lies their MySQL database, which has grown to an impressive petabyte scale. Managing a database of this magnitude presents significant challenges, especially when considering Shopify’s commitment to providing a zero-downtime service.
Their direct customers are business owners, who depend on their online stores to generate revenue and sustain their livelihoods. Any downtime or service disruption can have severe consequences for these merchants, potentially leading to lost sales and damaged customer relationships.
In this post, we will look at how Shopify manages its critical MySQL database in three major areas:
Shard balancing with zero downtime
Maintaining read consistency with database replication
Database backup and restore
Each area is critical for operating a database at Shopify’s scale. For us, it’s a great opportunity to derive some key learnings.
Shard Balancing with Zero Downtime
Shopify runs a large fleet of MySQL database instances.
These instances are internally known as shards and are hosted within pods.
Each shard can store the data for one or more shops. See the diagram below where the MySQL shard within pod 1 contains the data for shop ABC and FOO.

As traffic patterns for individual shops change, certain database shards become unbalanced in their resource utilization and load.
For example, if both shop ABC and shop FOO launch a mega sale simultaneously, it will result in a surge of traffic causing the database server to struggle. To deal with this, Shopify moves one of the shop’s data to another shard.
This process is known as shard balancing and it’s important for multiple reasons such as:
Mitigating the risk of database failure
Improving the productivity of the infrastructure
Guaranteeing that buyers can always access their favorite shops (no downtime)
An interesting takeaway from these reasons is how successful companies are focused on the customer experience even when dealing with largely technical concerns. A well-balanced shard is not directly visible to the end user. However, an unbalanced shard can indirectly impact the user experience negatively.
The second takeaway is a strong focus on cost. This is evident from the idea of improving the infrastructure’s productivity, which ultimately translates to savings.
Let’s now investigate how Shopify runs the shard rebalancing process.
The Concept of Pods
Shopify’s infrastructure is composed of many pods.
Each pod is an isolated instance of the core Shopify application and a MySQL database shard. There are other data stores such as Redis and Memcached but we are not concerned about them right now.
A pod houses the data for one or more shops. Web requests for shops arrive at the Nginx load balancer that consults a routing table and forwards the request to the correct pod based on the shop.
The concept of pods in Shopify’s case is quite similar to cells in a cell-based architecture.
Nginx acts as the cell router and the application layer is the same across all pods. It has access to a routing table that maps a shop to a particular shard. See the diagram below:

However, there is also a slight difference from cell-based architecture. The data in each pod varies depending on the shops hosted in a pod’s database instance.
As discussed earlier, each pod consists of a shard or a partition of the data.
Shopify’s data model works well with this topology since “shop” is an identifier for most tables. The shop acts as a natural partition between data belonging to different customers. They can attach a shop_id field to all shop-owned tables and use it as a sharding key.
The trouble starts when multiple shops living on the same pod become too big, resulting in higher database usage for some shards and lower usage for others. There are two problems when this happens:
The high-traffic shards are at an increased risk of failure due to over-utilization.
Shards with low database usage are not used productively resulting in a higher cost of operation.
The graph below highlights the variation in database usage per shard that developed over time as merchants came on board and grew. Each line represents the database usage for a unique shard on a given day.

Balancing the Shards
Shopify faces two key challenges when it comes to rebalancing shards for optimal resource utilization:
Which shops should live on which shards?
How to move a shop from one shard to another with minimal downtime?
A simplistic approach of evenly distributing shops across shards is not effective due to the varying data sizes and resource requirements of each shop. Some shops may consume a disproportionate amount of resources, leading to an imbalanced shard utilization.
Instead, Shopify employs a data-driven approach to shard rebalancing.
They analyze historical database utilization and traffic data for each shard to identify usage patterns and classify shops based on their resource requirements. The analysis takes into account factors such as:
Shop size
Time required to move the shop
Occurrence of flash sales
Other relevant metrics
Nevertheless, this is an ongoing process that requires continuous optimization. Shopify also uses data analysis and machine learning algorithms to make better decisions.
Moving the Shop
Moving a shop from one shard to another is straightforward: select all records from all tables having the required shop_id and copy them to another MySQL shard.
However, there are three main constraints Shopify has to deal with:
Availability: The shop move must be performed online without visible downtime or interruption to the merchant’s storefront. In other words, customers should be able to interact with the storefront throughout the process.
Data Integrity: No data must be lost or corrupted during the transition. Also, all writes to the source database during the migration should also get copied.
Throughput: The shop move should be completed in a reasonable amount of time.
As expected, availability is critical. Shopify doesn’t want any visible downtime. While there’s a possibility for some downtime, the end user should not feel the impact.
Also, data integrity is crucial. Imagine there was a sale that got wiped out because the shop was moving from one shard to another. This would be unacceptable for the business owner.
As you can notice, each technical requirement is driven by strong business drivers.
Let us now look at each step in the process:
Phase One: Batch Copying and Tailing the Binlog
To perform the data migration, Shopify uses Ghostferry. It’s an in-house tool written in Go.
Later on, Shopify made it open-source. At present, Ghostferry’s GitHub repository has around 690+ stars.
Let’s assume that Pod 1 has two shops - ABC and FOO. Both shops decided to run a sale and expect a surge of traffic. Based on Shopify’s rebalancing strategy, Shop ABC should be moved from Pod 1 to Pod 2 for better resource utilization.
The diagram below shows the initial state where the traffic for Shop ABC is served by Pod 1. However, the copy process has started.

Ghostferry uses two main components to copy over data:
Batch copying
Tailing the binlog
In batch copying, Ghostferry iterates over the tables on the source shard, selects the relevant rows based on the shop’s ID, and writes these rows to the target shard. Each batch of writes is performed within a separate MySQL transaction to ensure data consistency.
To ensure that the rows being migrated are not modified on the source shard, Ghostferry uses MySQL’s SELECT…FOR UPDATE clause. This statement implements locking reads, which means that the selected rows from the source shard are write-locked for the duration of the transaction.
Ghostferry also starts tailing MySQL’s binlog to track and replicate changes that occur on the source shard to the target shard. The binlog serves as a sink for events that describe the modifications made to a database, making it the authoritative source of truth.
In essence, both batch copying and tailing the binlog take place together.
Phase Two: Entering Cutover
The only opportunity for downtime is during the cutover. Therefore, the cutover is designed to be a short process.

Here’s what happens during the cutover phase:
Ghostferry initiates the cutover phase when the queue of pending binlog events to be replayed on the target shard becomes small. The queue is considered small when the difference between the newly generated binlog events on the source shard and the events being replayed on the target shard is nearly real-time.
Once the cutover phase begins, all write operations on the source database are stopped. This ensures that no new binlog events are generated.
At this point, Ghostferry records the final binlog coordinate of the source database, which serves as the stopping coordinate.
Ghostferry then processes the remaining queue of binlog events until it reaches the stopping coordinate. When the stopping coordinate is reached, the copying process is complete, and the target shard is in sync with the source shard.
Phase Three: Switch Traffic and Prune Stale Data
In the last phase, the shop mover process updates the routing table to associate the shop with its new pod.
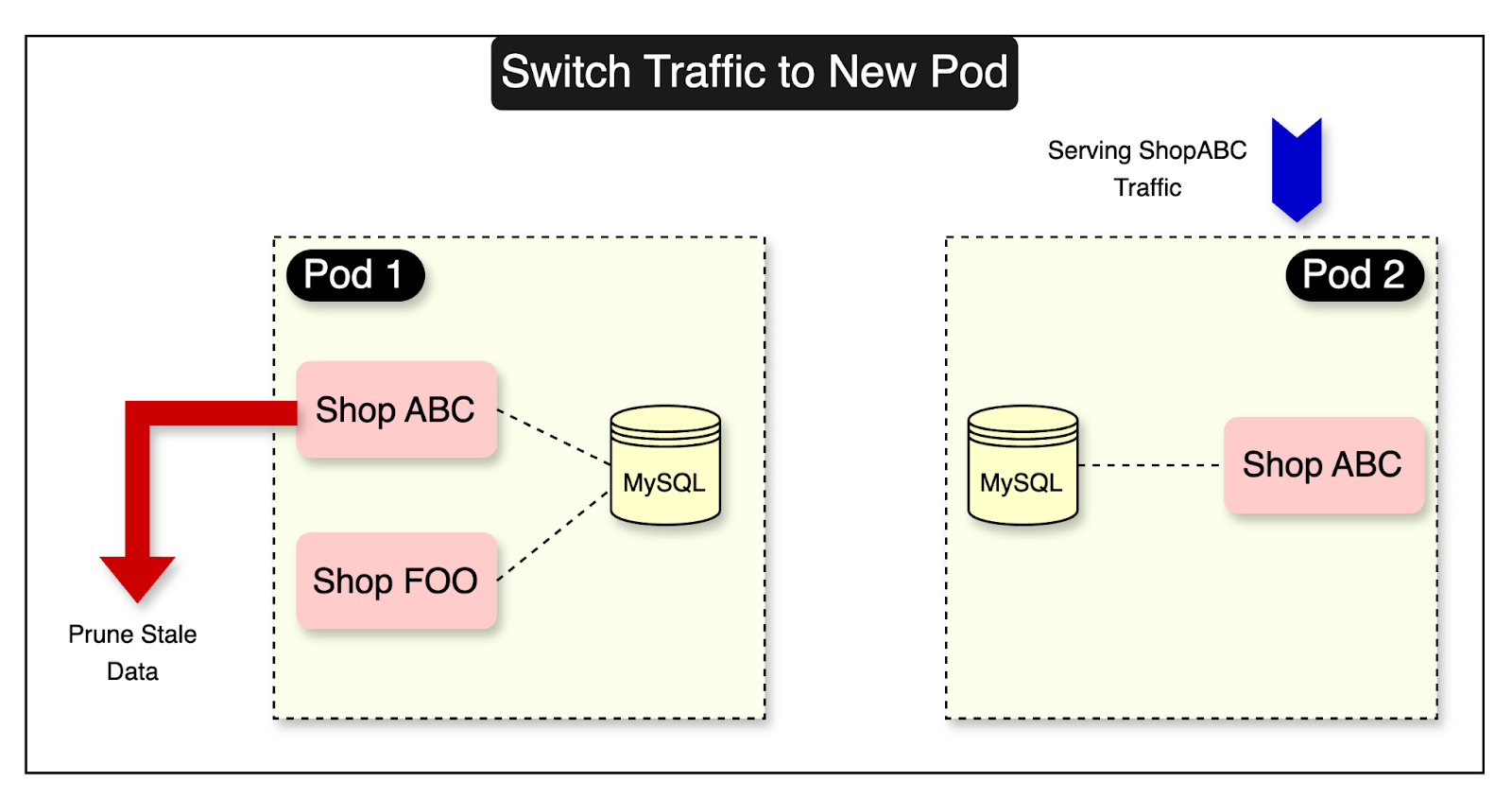
The shop is now served from the new pod. However, the old pod still contains the shop data.
They perform a verification to ensure that the movement is successful. If no issues are identified during the verification process, stale data of shop ABC on the old pod is deleted.
Read Consistency with Database Replication
The second major learning point from data management at Shopify’s scale is related to database replication.
Read replicas are copies of a primary database that are used to handle read-only queries. They help distribute the read workload across multiple servers, reducing the load on the primary database server. This allows the primary servers to be used for time-sensitive read/write operations.
An interesting point to note here is that read replicas don’t handle all the reads. Time-sensitive reads still go to the primary servers.
Why is this the case?
The unavoidable reason is the existence of replication lag.
Any database replication process will have some lag. The implication is that applications reading from a replica might end up reading stale data. However, this may not be acceptable for some specific reads. For example, a customer updating the profile information and not seeing the updates reflected on the profile page.
Also, reads are not always atomic. There can be a scenario where related pieces of data are assembled from the results of multiple queries.
For example, consider the below sequence of events:
The customer places an order for two items: Item A and Item B.
The order processing system sends a query to read replica 1 to check the inventory for Item A.
At the same time, it sends another query to read replica 2 to check the inventory for Item B.
Imagine that between steps 2 and 3, the inventory for Item B gets updated on the master and the item is sold out. However, replica 2 has a higher replication lag compared to replica 1. This means that while replica 1 returns the updated inventory, replica 2 returns the outdated inventory for Item B.
This can create inconsistency within the application.
The diagram below shows this scenario:

To use replication effectively, Shopify had to solve this issue:
There were two potential solutions Shopify considered but did not use:
Tight Consistency: One way was to enforce tight consistency to deal with variable lag. This means all replicas are guaranteed to be up to date with the primary server. However, this solution negates the benefits of using replica and also reduces the overall availability of write operations. Even if one of the replicas is down, the write operation can fail.
Causal Consistency: Another approach was causal consistency based on a global transaction identifier (GTID). Each transaction in the primary server will have a GTID, which will be preserved during replication. The disadvantage of this approach was the need to implement special software on each replica that would report its GTID back to the proxy that makes the server selection.
Finally, Shopify settled on a solution to implement monotonic read consistency. In this approach, successive reads should follow a consistent timeline even if the data read is not real-time.
This can be ensured by routing a series of related reads to the same server so that successive reads fetch a consistent state even if it’s not the latest state. See the diagram below for reference:

To implement this technically, Shopify had to take care of two points:
Determine if a request is related to another request.
Determine the server where the request should go.
Any application that requires read consistency within a series of requests supplies a unique identifier common to those requests. This identifier is passed within query comments as a key-value pair.
The diagram below shows the complete process:

The identifier is a UUID that represents a series of related requests.
The UUID is labeled as consistent_read_id within the comments and goes through an extraction followed by a hashing process to determine the server that should receive all the requests that contain this identifier.
Shopify’s approach to consistent reads was simple to implement and had a low overhead in terms of processing. Its main drawback was that intermittent server outages can introduce read consistencies but this tradeoff was acceptable to them.
Database Backup and Restore
The last major learning point from Shopify’s data management is related to how they manage database backup and restore.
As mentioned earlier, Shopify runs a large fleet of MySQL servers. These servers are spread across three Google Cloud Platform (GCP) regions.
Initially, Shopify’s data backup process was as follows:
Use Percona’s Xtrabackup utility
Store output in files
Archive them on Google Cloud Storage
While the process was robust, it was time-consuming. Backing up a petabyte of data spread across multiple regions was too long. Also, the restore time for each shard was more than six hours. This meant Shopify had to accept a very high Recovery Time Objective (RTO).
To bring the RTO down to just 30 minutes, Shopify redesigned the backup and restore process. Since their MySQL servers ran on GCP’s VM using Persistent Disk (PD), they decided to leverage PD’s snapshot feature.
Let’s look at each step of the process in detail.
Taking a Backup
Shopify developed a new backup solution that uses GCP API to create persistent disk snapshots of their MySQL instances.
They deployed this backup tooling as a CronJob within their Kubernetes infrastructure. The CronJob is configured to run every 15 minutes across all clusters in all available regions. The tool creates snapshots of MySQL instances nearly 100 times a day across all shards, resulting in thousands of daily snapshots.
The diagram below shows the process:

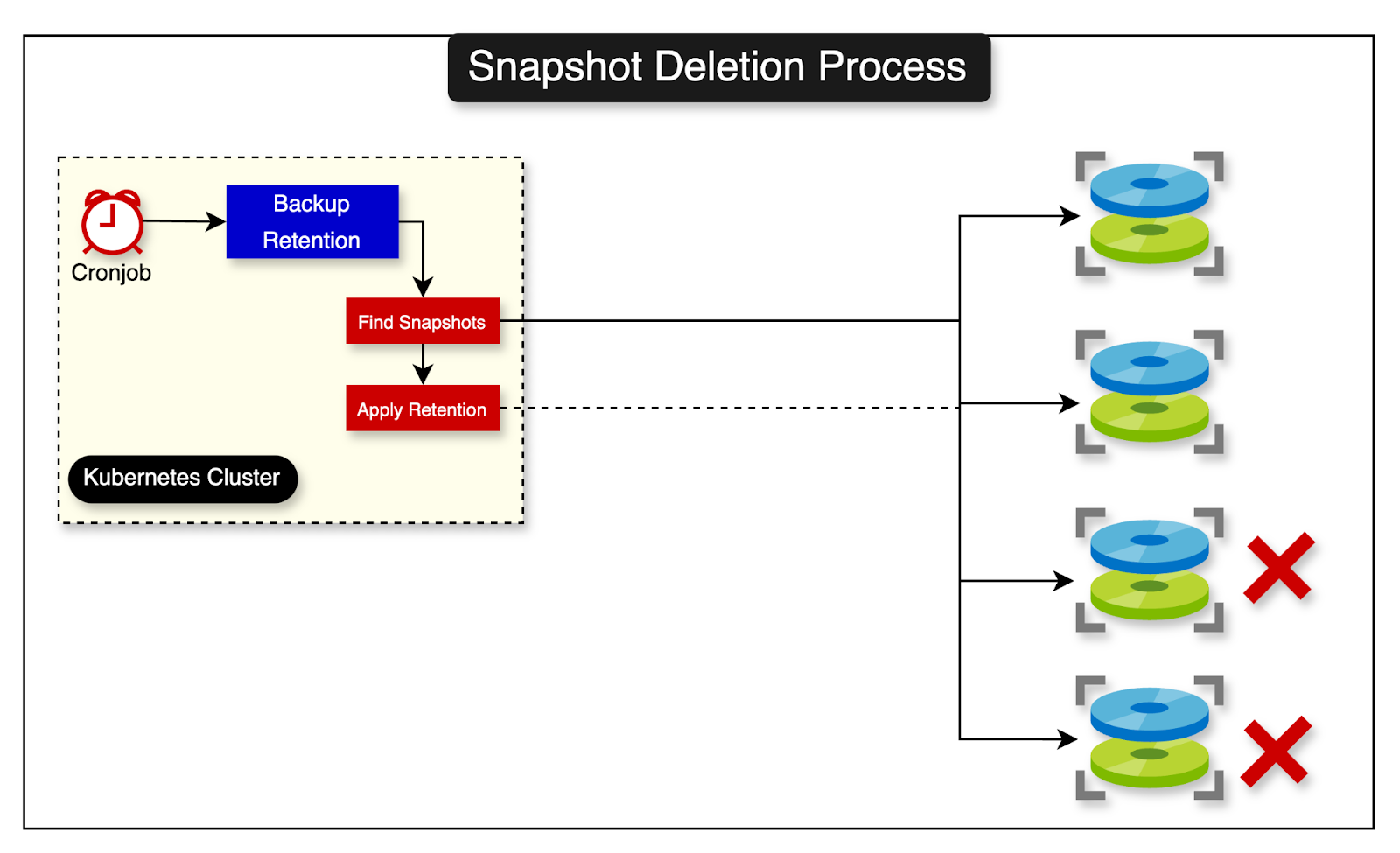
Retaining Snapshots
Since the backup process generated so many snapshots, Shopify also wanted to have a retention process to keep the important snapshots only. This was to keep the costs down.
They built another tool that implements the retention policy and deployed it using another CronJob on Kubernetes.
The diagram below shows the snapshot deletion process based on the retention policy.
Performing a Restore
Having a very recent snapshot readily available enables Shopify to clone replicas with the most up-to-date data possible.
The process of restoring the backup is quite simple. It involves the following steps:
Create new PDs using the latest snapshot as the source.
Start MySQL on top of the newly created disks.
By exporting a snapshot to a new PD volume, Shopify can restore the database in a matter of minutes. This approach has reduced their RTO to less than 30 minutes, including the time needed to recover from any replication lag.
The diagram below shows the database restore process:

Conclusion
Shopify’s database management techniques are a great example of how simple solutions can help organizations achieve the needed scale. Also, it shows that companies like Shopify have a strong focus on the user experience and cost while making any technical decision.
In this post, we’ve seen a glimpse of how Shopify manages its petabyte-scale MySQL database. Some of the key things we’ve covered are as follows:
Shard balancing with zero downtime is important for efficient resource utilization and a good customer experience.
Database replication improves the availability and performance but also creates issues related to lag. A clear consistency model is needed to counter the effects of replication lag.
A quick and efficient database backup and restore process is important to minimize the recovery time.
References:
What happens to data lost during the 30 minute recovery window for a shard if transactions have happened and money has been exchanged but theres no longer a record or order id in the dB?
You are saying that while copying Shop A from one shard to another, they are write-locking the records that are part of the current batch that's being copied over while also keeping a binlog to capture recent updates on these records like a CDC (Change Data Capture) process.
If they are locking these transactions, then what happens during a sale surge for an item that has only 1 unit left? Are people locked out of the payment checkout process until the copy is complete? If the transactions are write-locked, then what's the point of having a binlog for this record if it's not gonna be able to capture recent changes? Having a binlog and write-locking seem to be mutually exclusive.
Can you clarify what happens to this final unit when multiple people are fighting over its purchase during a surge sale while the record(s) for this item is being copied over to another shard?