
How Snapchat Serves a Billion Predictions Per Second

New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)

Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Snapchat decides what to show you in roughly 100 milliseconds. In that window, the system has to retrieve a few hundred candidate videos from a corpus of millions, fetch dozens of features about the user and dozens about each candidate, run a deep learning model over every pair, and rank the results. Now consider how this scales when 477 million people open the app every day.
The interesting question is how the system stays fast at this scale. The deeper question is what shape the system has to have to be fast at all.
Snapchat started in 2011 as an ephemeral messaging app where photos disappeared after a few seconds, and it has since grown into a full social platform with Discover, Spotlight, augmented reality lenses, friend suggestions, and an ad business that funds most of the company. Snap reported 946 million monthly active users in late 2025, with about 474 million of them opening the app every day. India is the largest market with over 214 million users, followed by the United States with around 104 million, while France, the Gulf countries, and other regions make up the rest of a global footprint that spans every major social media market.
For Snap, machine learning is closer to the product itself than a feature on top of it. Every session forces the system to make four kinds of decisions.
The first is which content should appear in your Discover and Spotlight feeds.
The second is which ads should win the auction for your attention.
The third is which people should appear in your friend suggestions.
The fourth is which AR lenses and effects should surface for you.
Each decision is shaped by an ML model, each one happens in milliseconds, and each one can be wrong in expensive ways. A bad ad ranking costs revenue directly, while a bad recommendation costs engagement, which costs future revenue.
All of this runs on a single platform called Bento. In this article, we’ll look at how the Snap engineering team built Bento and the challenges they faced along the way.
Disclaimer: This post is based on publicly shared details from the Snap Engineering Team. Please comment if you notice any inaccuracies.
The Shape of a Ranking Workload
A typical web request is roughly symmetric. One request arrives, the server queries a database, builds a response, and sends it back. The shape is one-to-one.
A ranking request is asymmetric. One user opens the app, and the platform has to decide what to show them out of millions of options. Internally, this single request expands into hundreds or thousands of pairs of (user, candidate) that each need a score from a model. After scoring, the system ranks the candidates and returns the top few to the user. A single request comes in, hundreds or thousands of model evaluations happen, and a short ranked list goes back out.
This expansion is what shapes Bento. Almost every architectural decision in the platform is an answer to the question of how to absorb this fanout.
In practice, the work is split across two stages.
The first stage is retrieval, where cheap models filter the full corpus down to a few hundred or thousands of candidates worth scoring.
The second stage is ranking, where expensive models score those candidates carefully and produce the final order.
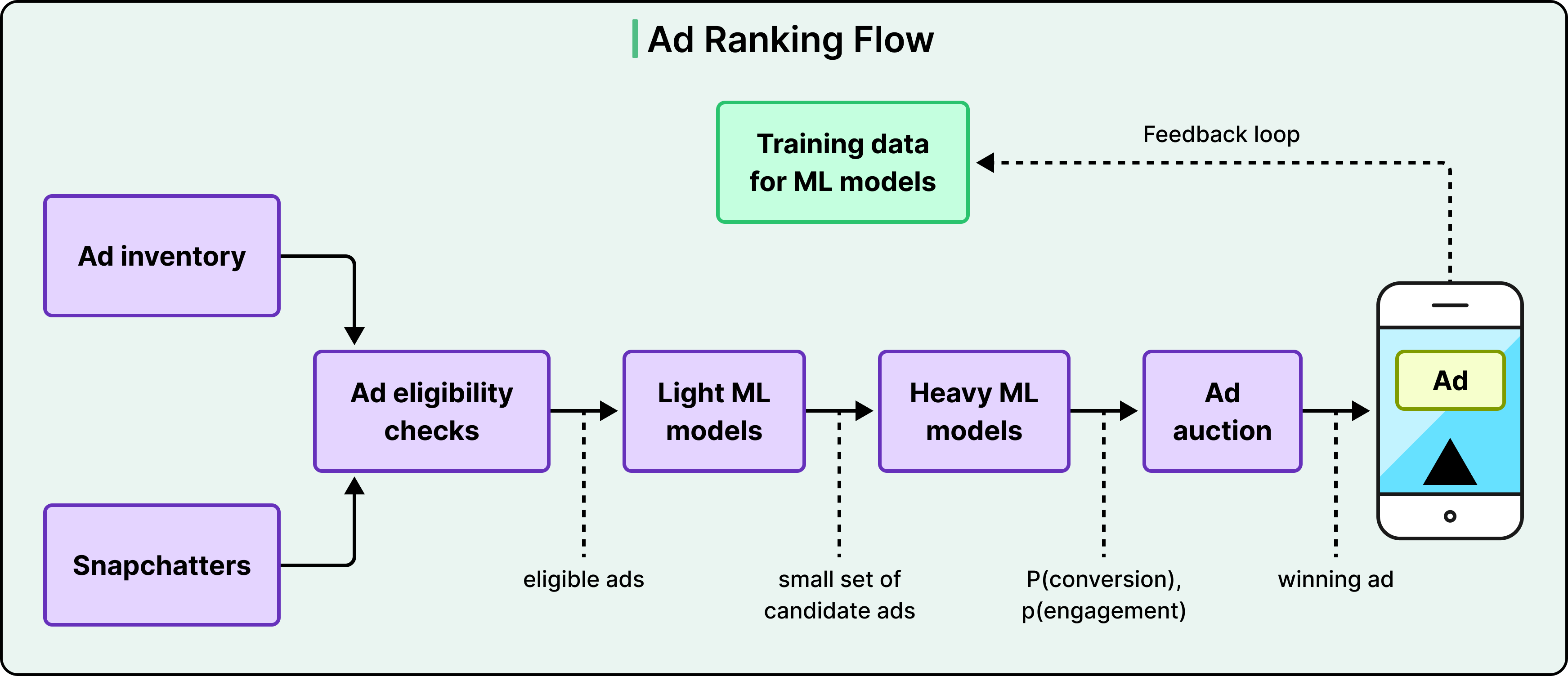
Snap’s ad ranking system follows this pattern explicitly. Light models filter the eligible ad inventory, heavy models predict the probability of conversion and engagement, an auction picks the winner, and the winning ad is served. The user’s response to that ad, whether they click, dismiss, or watch, then flows back into the training data.
The math gets large quickly. If hundreds of millions of users each trigger a few ranking requests per session, and each request scores hundreds of candidates, the total prediction volume crosses a billion per second. Snap reports that exact number, along with 1 TB per second of feature reads and 10 trillion events per day flowing through the feature pipelines.
This design creates four distinct kinds of pressure on the platform:
Latency pressure comes from the simple fact that users will abandon the app if a feed takes too long to load.
Scale pressure comes from the sheer prediction volume itself.
Freshness pressure comes from the requirement that a user who just liked a video should immediately see the system respond to that signal.
Iteration pressure comes from the need for ML engineers to ship hundreds of experiments per month to keep the models competitive.
These pressures pull in different directions, since latency wants smaller models, scale wants cheaper compute, freshness wants real-time pipelines, and iteration wants flexible tooling. The point of Bento is to make all four tractable at the same time.
The platform splits cleanly into two halves. One half produces models, while the other half serves them. Almost all of the unusual engineering lives in the second half.
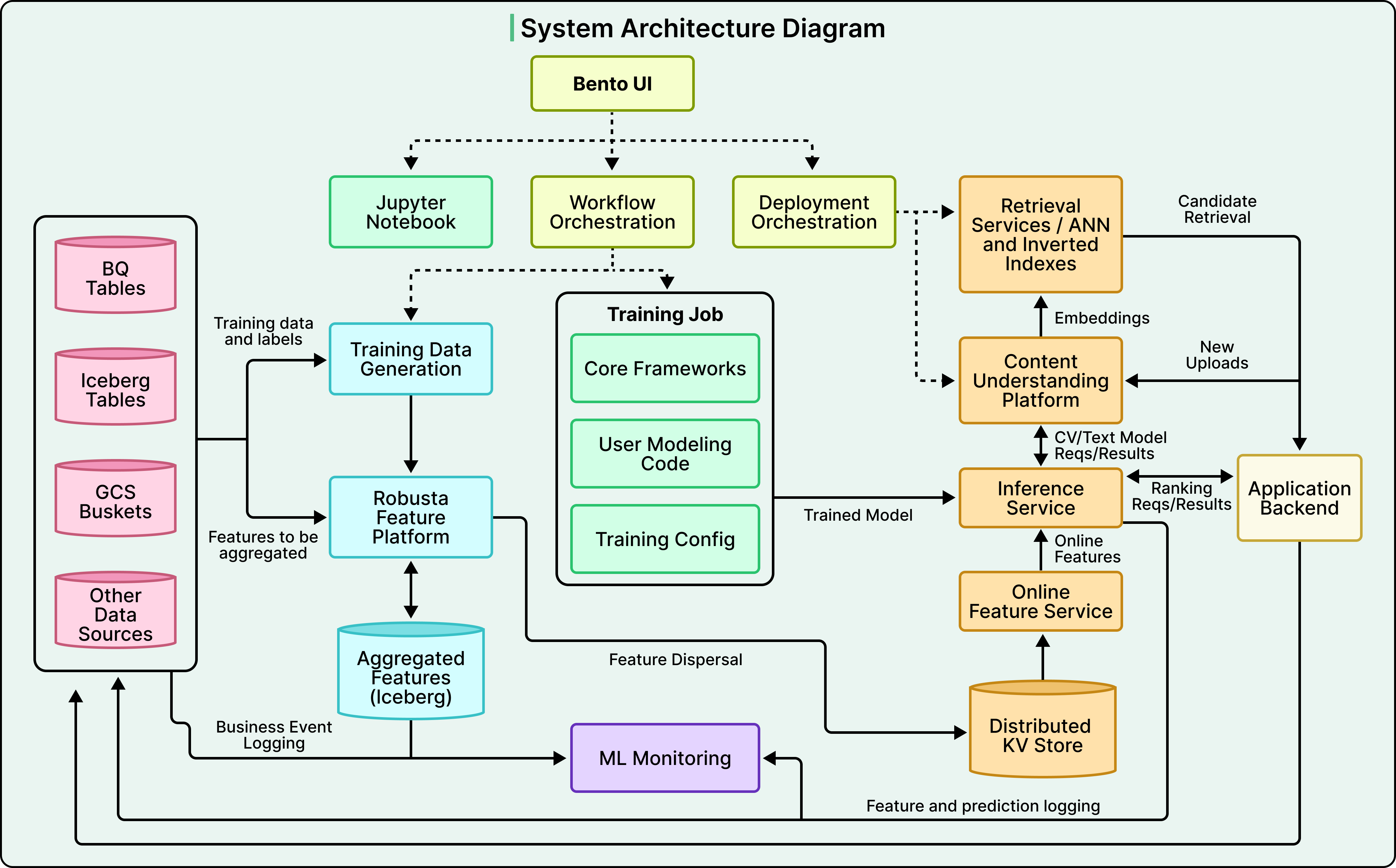
The Training Pipeline
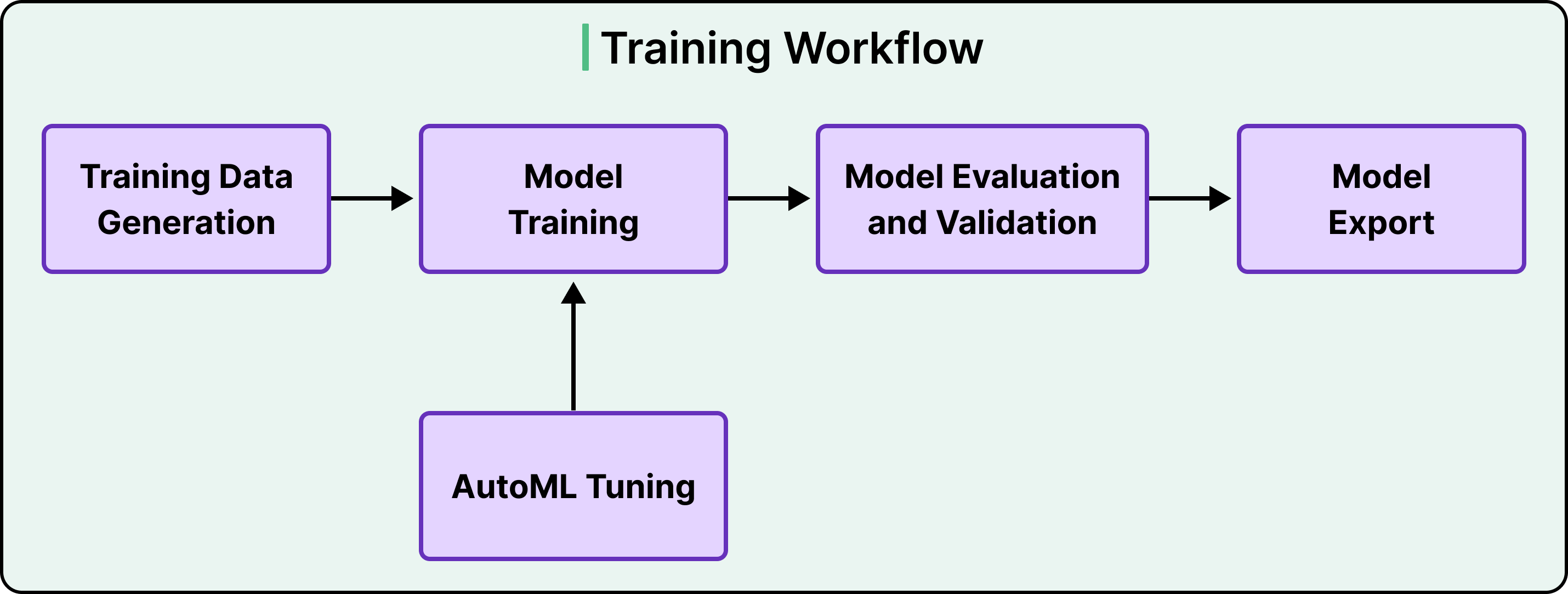
The training half of Bento follows a familiar four-stage workflow.
Training data is generated from raw events and aggregated features. The model trains on GPU or TPU hosts, the trained model is evaluated against held-out data, and finally, the model is exported into a form ready for serving. Bento orchestrates these stages using Kubeflow, an open-source workflow engine built for ML pipelines.
The interesting design choice in this half is how Snap structures the training code itself. Rather than letting every team write its own model code from scratch, Bento splits training applications into three layers.
The Core framework is a shared internal library built on TensorFlow and Keras that standardizes common patterns for ranking and recommendation models.
User model code is what an individual ML engineer writes to express their specific model.
Training configuration is a YAML file that specifies the hardware, the input data, and the runtime options.
This layering is what enables hundreds of experiments per day. An engineer can change one line in the configuration to swap input datasets, or modify a few lines of model code to test a new feature, and trigger a full training run. The shared Core framework means experiments are comparable, because they share the same scaffolding, while the configuration layer means experiments are cheap to launch.
The model export step is where Bento does something different. Modern recommendation models have an unusual computational shape. They include large embedding tables, where each user ID or video ID maps to a learned vector, and these tables are bound by memory size. They also include dense neural network layers on top of those embeddings, which are bound by compute capacity. Running both on the same hardware wastes one resource or the other.
Bento’s export step splits the compute graph, putting dense matrix multiplication on the GPU and embedding lookups along with feature parsing on the CPU. In other words, the same trained model produces different exported versions for different inference hardware.
Models go through this process repeatedly rather than once. Bento fully automates incremental training, where new events are continuously appended to the training data, models retrain on the updated data, and new versions deploy automatically after passing validation. A model in production is materially different from the same model a week earlier.
This whole process produces a trained model that is ready for serving, which is where the harder problem begins.
The Serving Path
The serving half of Bento is where the asymmetric workload from earlier becomes a set of concrete engineering problems.
A request comes in, features have to be fetched, the model has to score hundreds or thousands of candidates, and the result has to come back within the latency budget. Each of these steps presents its own challenges, and Bento’s design reflects opinionated choices about how to handle them.
The most consequential of those choices involves the feature store, which sits between the offline world where models are trained and the online world where they are served.
The Feature Store Split
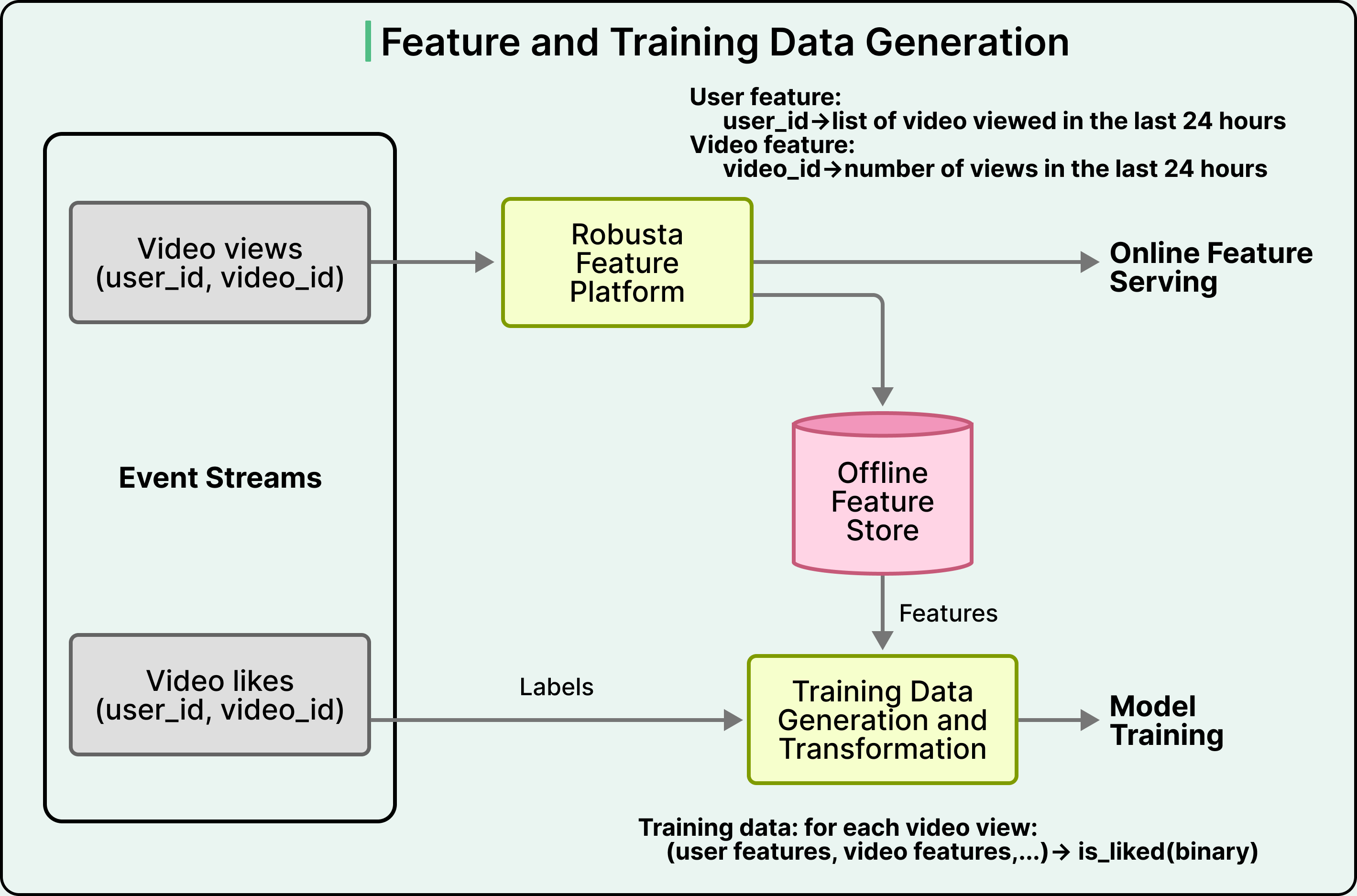
A feature is a numerical input to a model derived from raw data. A simple example is the number of videos a user watched in the last 24 hours. More complex features might involve embeddings learned during training, statistical aggregations over time windows, or counts grouped by various keys. A model takes dozens or hundreds of features as input and produces a prediction.
The challenge is that features have to exist in two places at once.
Offline, where models are trained, features live in a large analytical database, and Snap uses Apache Iceberg for this purpose.
Online, where models are served, features live in a fast key-value store optimized for low-latency reads.
These two stores must agree with each other. If the same feature is computed differently in the two places, the model will train on one distribution and serve on a different one, which produces a class of bugs called train and serve skew. The model performs well in offline evaluation and poorly in production. This problem is the central operational concern of every mature ML team, and it is rarely covered in tutorials.
Snap’s feature platform is called Robusta, and it is built on Apache Spark.
Robusta is responsible for keeping the two stores in sync. It processes 10 trillion events per day, computes aggregated features over sliding time windows, and writes results to both the offline Iceberg store and the online key-value store. The online feature store alone holds 800 TB of data and serves 1 TB per second of reads.
Two Strategies for High Fanout
The asymmetric workload from earlier becomes a concrete problem at the feature layer. A single ranking request needs features for one user and many candidate documents, and fetching all those features over the network would be too slow.
Bento uses two different strategies depending on the use case.
The first strategy is unusual. For many ranking workloads, Snap collocates document features directly on the inference engine instances. When a request arrives, the system performs one user feature lookup from the central online store and forwards the request to inference. The inference engine then reads document features from local memory during scoring, which eliminates network fanout entirely. The tradeoff is that each inference instance has to hold the full document feature corpus in memory, which is expensive. At Snap’s scale, the math works out, since the latency reduction and cost savings outweigh the memory cost. At smaller scales, this approach would be wasteful, and a remote feature store is the standard answer.
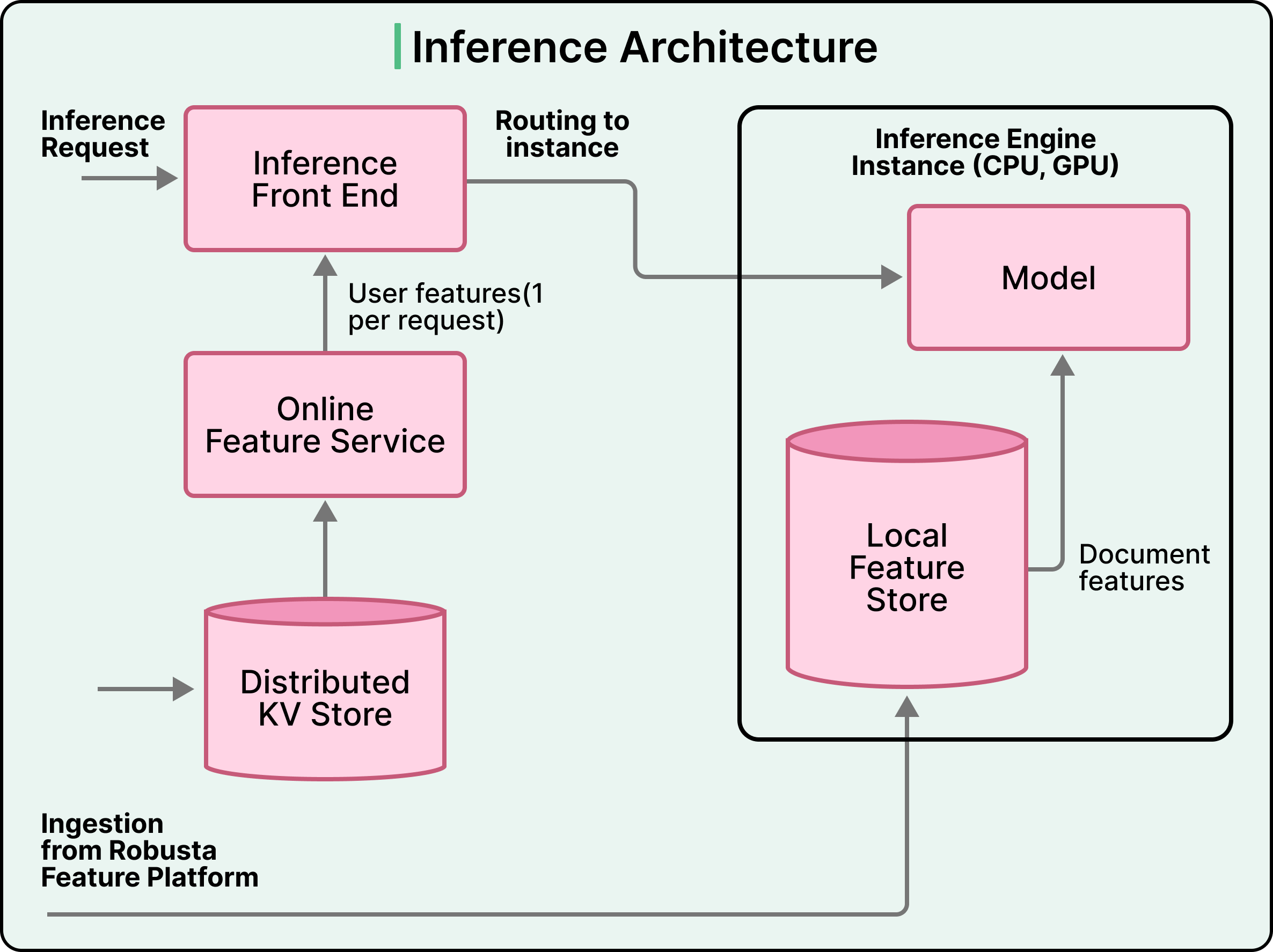
The second strategy handles cases where the document corpus is too large to fit on every inference instance. For these, Snap built a separate Retrieval service that performs Approximate Nearest Neighbor search, which is a fast similarity search over learned embeddings, along with inverted index lookups and forward index lookups in a single pass. The Retrieval service returns a small, pre-hydrated candidate set with features attached, ready to be sent to the inference engine.
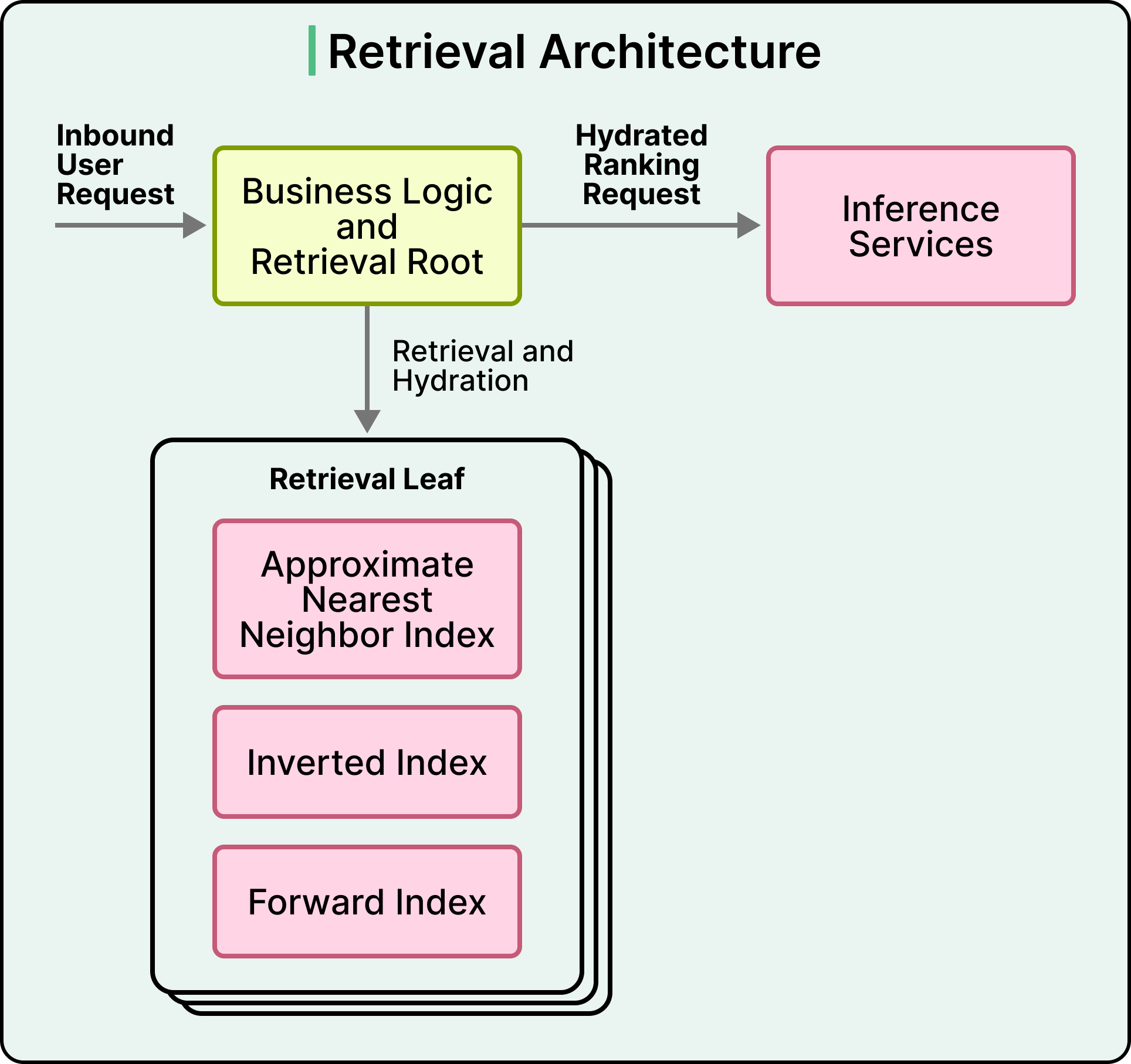
Both strategies are valid, and the choice between them depends on corpus size, access patterns, and how much memory is acceptable on inference instances.
What Makes The Inference Engine Cheap
Once a request reaches the model, several optimizations make the actual scoring fast and economical. Two of these optimizations are worth understanding in detail.
The first is the GPU and CPU compute graph split mentioned earlier. The model export step produces a hardware-specific version that places dense matrix math on the GPU and embedding lookups, along with feature parsing on the CPU. This split avoids two waste patterns at once. Putting embeddings on the GPU wastes scarce GPU memory on lookup tables, while putting dense math on the CPU wastes time on operations a GPU could parallelize easily. The split costs more engineering effort during export, and it pays back many times over during serving.
The second is data plane optimization, and this is the most striking specific result in the entire blog. Bento’s engineers found that a large fraction of inference latency was being spent on serialization and deserialization of feature data, rather than on the model itself. They redesigned the inference APIs so that features could be fetched and transferred as raw bytes, with deserialization happening only inside the inference engine. Combined with custom Protobuf optimizations, this single change resulted in 2x lower latency and 10x cheaper data plane costs. The lesson is that at scale, the boring machinery of the system, including serialization, RPC framing, and network transport, often dominates the cost. Most of the cost lives outside the model itself.
Other optimizations exist as well. Request batching, model co-location across inference fleets, and build-level tuning for the underlying hardware each contribute incrementally to performance and cost. The two optimizations described above carry most of the lesson.
Once the prediction is made and the ranked feed is returned, the system’s job continues. The most important part of an ML platform happens after the response goes out.
The Feedback Loop
Every prediction Bento makes is logged, along with the features used to make it. The user actions taken in response are also logged, including whether they watched the video, dismissed the ad, or sent a friend request. These logs flow back into the training data pipeline, where new training records are generated. Incremental training then runs on the updated data, new model versions are exported, and after passing validation, the deployment system rolls out the new versions while older versions retire.
Two kinds of monitoring run continuously alongside this loop:
The first watches statistical properties of features and predictions over time. If the mean of a feature drifts, or the distribution of predictions shifts, the change is often a signal that something upstream has broken.
The second kind of monitoring compares online and offline behavior directly. The same prediction is recomputed offline using the offline feature store, and the result is compared to what the online system produced.
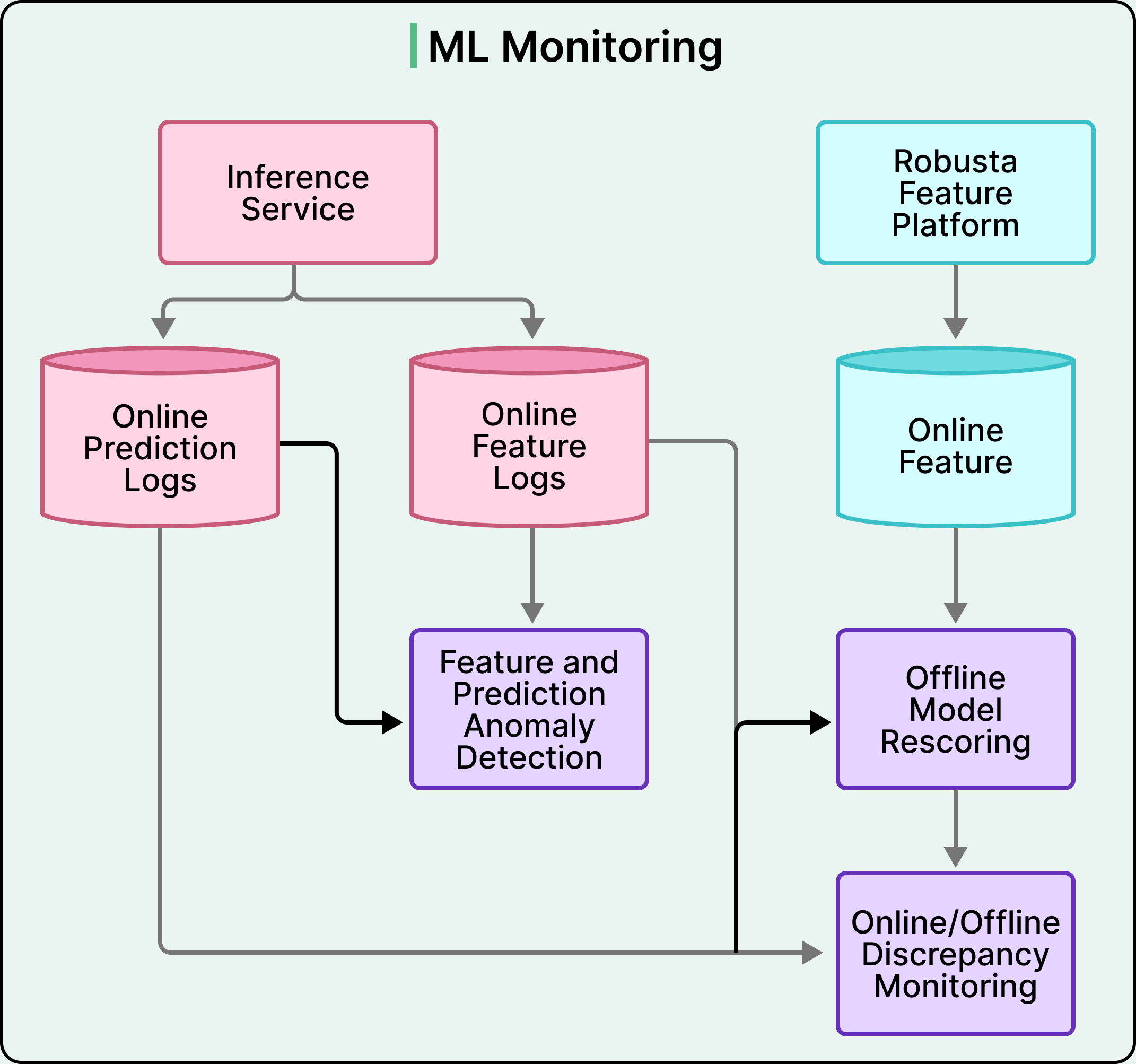
Any discrepancy points to the train and serve skew problem from earlier.
The deployment control plane uses a reconciliation pattern borrowed from Kubernetes. The system stores a desired state, which describes which models should be deployed, in what configuration, and on which fleets, and it continuously compares this desired state to the actual running state. Any differences are closed automatically. This approach is what makes large-scale ML deployments safe at this volume, since manual deployment at this scale would be too error-prone to be viable.
Snap’s blog mentions that over a recent two-year period, ranking model size grew 20x and training data grew 40x. The platform absorbed this growth in the course of normal operation. That kind of scaling headroom is what a feedback loop buys you. The platform is less a fixed pipeline that produces a model and more a continuously running system that produces a stream of model versions, each one shaped by the data the previous version generated.
Conclusion
Bento is built around a single observation about the work it does. Ranking requests are asymmetric, since one user request expands into hundreds or thousands of model evaluations before collapsing back into a short ranked list. This design, multiplied by 474 million daily users and the four operational pressures it creates around latency, scale, freshness, and iteration, drives almost every architectural decision in the platform.
The platform handles the work in two halves.
The training half generates models through a four-stage workflow, with a layered code structure that lets engineers run hundreds of experiments per day, and a model export step that splits the compute graph between GPU and CPU to match the unusual computational shape of recommendation models.
The serving half handles the harder operational problems, including the dual existence of features in offline and online stores, the high-fanout problem solved by either feature collocation or a dedicated Retrieval service, and the inference-time optimizations that produced 2x latency reductions and 10x lower data plane costs. Around all of this runs a continuous feedback loop that turns each prediction into the next round of training data, with monitoring that watches for drift and a deployment control plane that reconciles desired and running state automatically.
The numbers Bento operates at are large, including hundreds of models trained per day, more than 100,000 training compute hours per day, 800 TB of online feature data, 1 TB per second of feature reads, and over a billion predictions per second. These figures are interesting on their own, but they matter most as the conditions that make the architectural choices intelligible across the entire platform.
References
The billion predictions per second is impressive but it's actually the easier constraint to solve. Thats parallelism. The harder constraint is the 100ms budget for any single prediction, because latency is an architecture problem and you cant parallelise your way out of it.
Everything downstream, the retrieval/ranking split and the compute graph separation between GPU and CPU, is shaped by that single number. The system's architecture is really a latency budget expressed as infrastructure.
Loved the point about train-serve skew - it's one of those problems that sounds mundane until you realise it's quietly responsible for half the "why is our model underperforming in production" conversations that happen in ML teams worldwide.
What's interesting to me is how this infrastructure story maps onto Snap's broader business survival arc.
People forget that Snap was left for dead twice - first when Instagram cloned Stories in 2016 and stripped them of what felt like their core identity, then again when TikTok redefined what a feed could even be. Both times, the obituaries were written. Both times, Snap responded not by out-featuring the competition by out-engineering them - AR, ephemeral identity and a recommendation engine that can rival what Meta is running.
When your ranking system can predict conversion probability accurately enough to win auctions against Google and Meta inventory, you've crossed a threshold which explains why the revenue story has stabilised despite the platform being written off repeatedly.
The shift from a messaging app to a full ML-powered content platform wasn't a pivot, but a quiet infrastructure rebuild that a lot of us (myself included) missed - thank you for putting this into perspective so coherently.