How to Build a Smart Chatbot in 10 mins with LangChain

A large number of people have shown a keen interest in learning how to build a smart chatbot. To help us gain a better understanding of the process, I'm excited to bring you a special guest post by Damien Benveniste. He is the author of The AiEdge newsletter and was a Machine Learning Tech Lead at Meta. He holds a PhD from The Johns Hopkins University.
Below, he shares how to build a smart chatbot in 10 minutes with LangChain.
Subscribe to Damien's The AiEdge newsletter for more. You can also follow him on LinkedIn and Twitter.
LangChain is an incredible tool for interacting with Large Language Models (LLM.) In this deep dive, I’ll show you how to use databases, tools and memory to build a smart chatbot. At the end, I show how to ask ChatGPT for investment advice. This article covers:
What is LangChain?
Indexing and searching new data
Let’s get some data
Pinecone: A vector database
Storing the data
Retrieving data with ChatGPT
Giving ChatGPT access to tools
Providing a conversation memory
Putting everything together
Giving access to Google Search
Utilizing the database as a tool
Solving a difficult problem: Should I invest in Google today?
What is LangChain?
LangChain is a package to build applications using LLMs. It is composed of 6 modules:

Prompts: This module allows you to build dynamic prompts using templates. It can adapt to different LLM types depending on the context window size and input variables used as context, such as conversation history, search results, previous answers, and more.
Models: This module provides an abstraction layer to connect to most available third- party LLM APIs. It has API connections to ~40 public LLMs, chat and embedding models.
Memory: This gives the LLMs access to the conversation history.
Indexes: Indexes refer to ways to structure documents so that LLMs can best interact with them. This module contains utility functions for working with documents and integration to different vector databases.
Agents: Some applications require not just a predetermined chain of calls to LLMs or other tools, but potentially to an unknown chain that depends on the user’s input. In these types of chains, there is an agent with access to a suite of tools. Depending on the user’s input, the agent can decide which – if any – tool to call.
Chains: Using an LLM in isolation is fine for some simple applications, but many more complex ones require the chaining of LLMs, either with each other, or other experts. LangChain provides a standard interface for Chains, as well as some common implementations of chains for ease of use.
Currently, the API is not well documented and is disorganized, but if you are willing to dig into the source code, it is well worth the effort. I advise you to watch the following introductory video to get more familiar with it:
I now demonstrate how to use LangChain. You can install all the necessary libraries by running the following:
pip install pinecone-client langchain openai wikipedia google-api-python-client unstructured tabulate pdf2imageIndexing and searching new data
One difficulty with LLMs is that they only know what they learned during training. So how do we get them to use private data? One way is to make new text data discoverable by the LLM. The typical way to do this is to convert all private data into embeddings stored in a vector database. The process is as follows:
Chunk the data into small pieces
Pass that data through an LLM. The resulting final layer of the network can be used as a semantic vector representation of the data
The data can then be stored in a database of the vector representation used to recover that piece of data
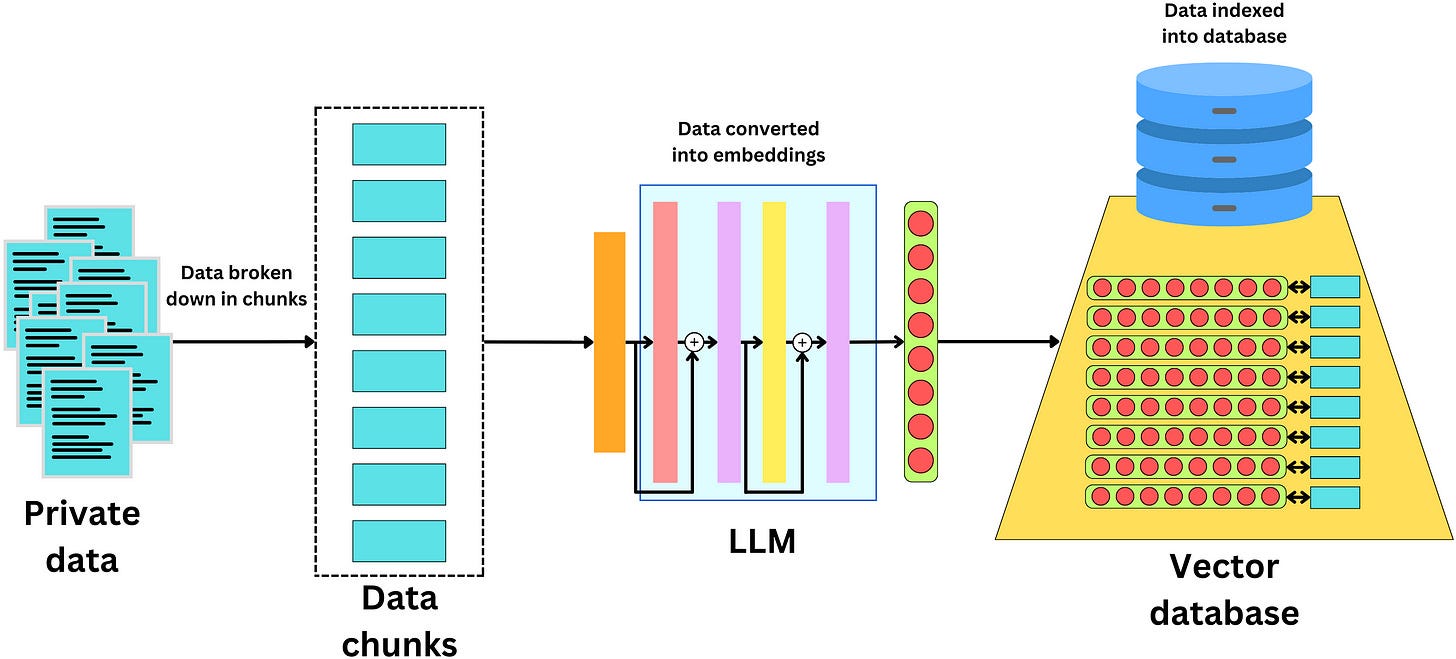
A question which we ask can be converted into an embedding, which is the query. We can then search for pieces of data located close to it in the embedding space and feed relevant documents to the LLM for it to extract an answer from:

Let’s get some data
I sourced interesting data for a demonstration and selected the earnings reports of tech giant, Alphabet (Google): https://abc.xyz/investor/previous/

For simplicity, I downloaded and stored the reports on my computer’s hard drive:

We can now load those documents into memory with LangChain, using 2 lines of code:
from langchain.document_loaders import DirectoryLoader
loader = DirectoryLoader(
'./Langchain/data/', # my local directory
glob='**/*.pdf', # we only get pdfs
show_progress=True
)
docs = loader.load()
docs
We split them into chunks. Each chunk corresponds to an embedding vector.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0
)
docs_split = text_splitter.split_documents(docs)
docs_split
For this reason, we need to convert the data into embeddings and store them in a database.
Pinecone: A vector database
To store the data, I use Pinecone. You can create a free account and automatically get API keys with which to access the database:

In the “indexes” tab, click on “create index.” Give it a name and a dimension. I used “1536” for the dimension, as it is the size of the chosen embedding from the OpenAI embedding model. I use the cosine similarity metric to search for similar documents:

This will create a vector table:

Storing the data
Before continuing, make sure to get a OpenAI API key by signing up to the OpenAI platform:

Let’s first write down our API keys
import os
PINECONE_API_KEY = ... # find at app.pinecone.io
PINECONE_ENV = ... # next to api key in console
OPENAI_API_KEY = ... # found at platform.openai.com/account/api-keys
os.environ['OPENAI_API_KEY'] = OPENAI_API_KEYWe upload the data to the vector database. The default OpenAI embedding model used in Langchain is 'text-embedding-ada-002' (OpenAI embedding models.) It is used to convert data into embedding vectors
import pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
# we use the openAI embedding model
embeddings = OpenAIEmbeddings()
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_ENV
)
doc_db = Pinecone.from_documents(
docs_split,
embeddings,
index_name='langchain-demo'
)We can now search for relevant documents in that database using the cosine similarity metric
query = "What were the most important events for Google in 2021?"
search_docs = doc_db.similarity_search(query)
search_docs
Retrieving data with ChatGPT
We can now use a LLM to utilize the database data. Let’s get an LLM such as GPT-3 using:
from langchain import OpenAI
llm = OpenAI()or we could get ChatGPT using
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()Let’s use the RetrievalQA module to query that data:
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=doc_db.as_retriever(),
)
query = "What were the earnings in 2022?"
result = qa.run(query)
result
> 'The total revenues for the full year 2022 were $282,836 million, with operating income and operating margin information not provided in the given context.'RetrievalQA is actually a wrapper around a specific prompt. The chain type “stuff“ will use a prompt, assuming the whole query text fits into the context window. It uses the following prompt template:
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{context}
{question}Here the context will be populated with the user’s question and the results of the retrieved documents found in the database. You can use other chain types: “map_reduce”, “refine”, and “map-rerank” if the text is longer than the context window.
Giving ChatGPT access to tools