How to Build High Throughput Systems

When we build software systems, one of the most important goals is making sure they can handle large amounts of work efficiently.
High-throughput systems are capable of processing vast quantities of data or transactions in a given timeframe. Throughput refers to the amount of work a system completes in a specific time period. For example, a web server might process 10K requests per second, or a database might handle 50K transactions per minute. The higher the throughput, the more work gets done in the same amount of time.
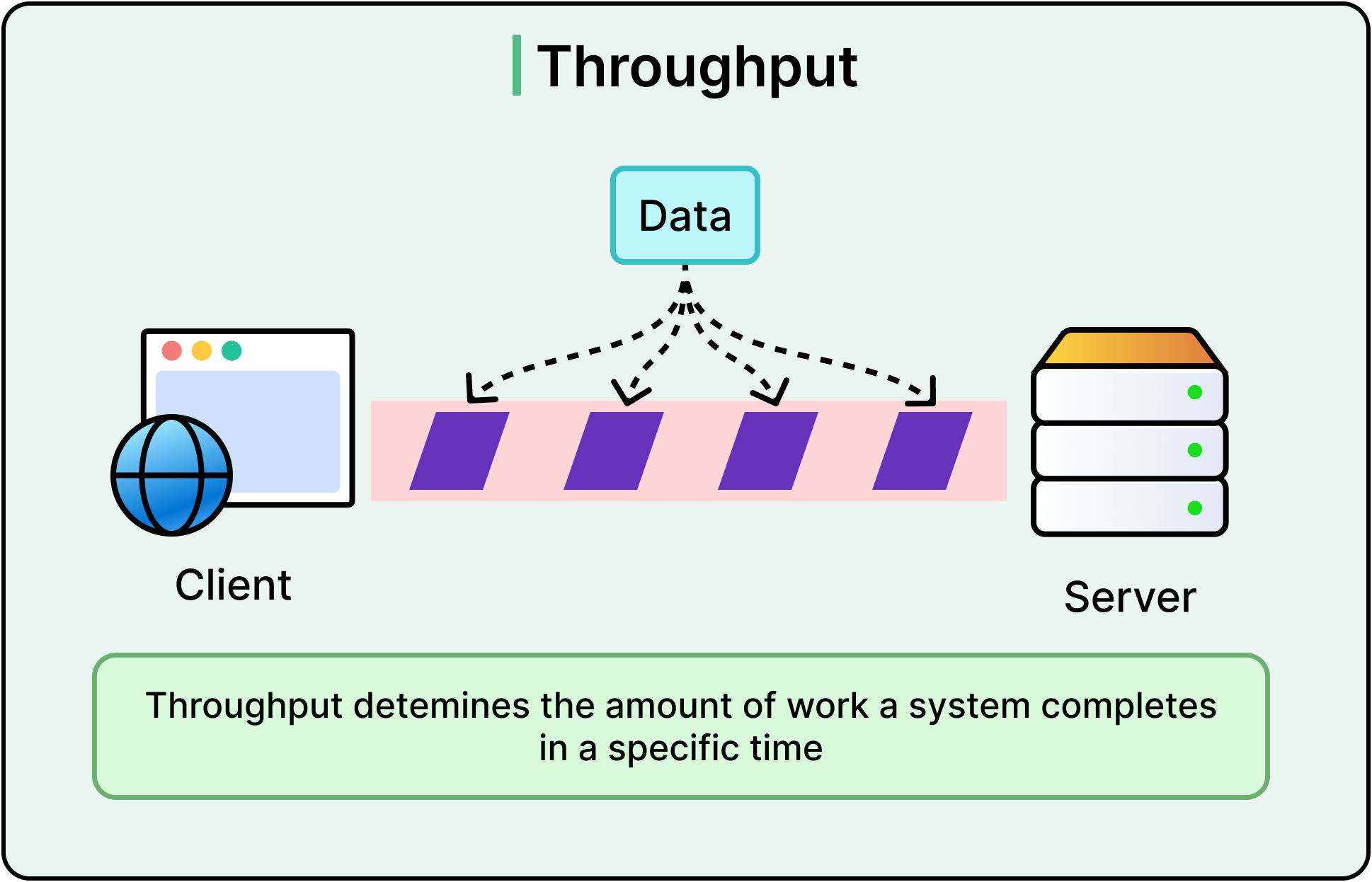
Throughput is different from latency. Latency measures how long it takes to complete a single operation, from start to finish. While throughput measures the volume of operations the system handles over time. For example, a system can have low latency but low throughput if it processes each request quickly but can only handle a few at once. Conversely, a system might have high throughput but high latency if it processes many requests simultaneously, but each request takes longer to complete.
There is often a tradeoff between these two metrics. When we batch multiple operations together, we increase throughput because the system processes many items at once. However, this batching introduces waiting time for individual operations, which increases latency. Similarly, processing every request immediately reduces latency but may limit throughput if the system becomes overwhelmed.
In this article, we will go through the fundamental concepts and practical strategies for building systems that can handle high volumes of work without breaking down under pressure.