How to Choose a Replication Strategy

In the last issue, we kicked off a 2-part series exploring common data replication strategies. We learned about the leader-follower model - its synchronous and asynchronous variations, consistency considerations, failure handling, and more.
In this issue, we'll examine two alternative approaches - multi-leader and leaderless replication. We'll contrast their designs, dive into how they work, and see the types of use cases where they excel.
By the end, you'll understand the core replication models and how to select the right strategy based on your system needs and constraints. Let's jump back in where we left off last week.
Multi-Leader Replication
Multi-leader replication, sometimes called leader-leader replication, involves the use of multiple primary nodes, also known as leaders, each capable of receiving and processing write requests. These leaders replicate data between each other to stay up to date. Each leader may also have follower replicas for read scaling.
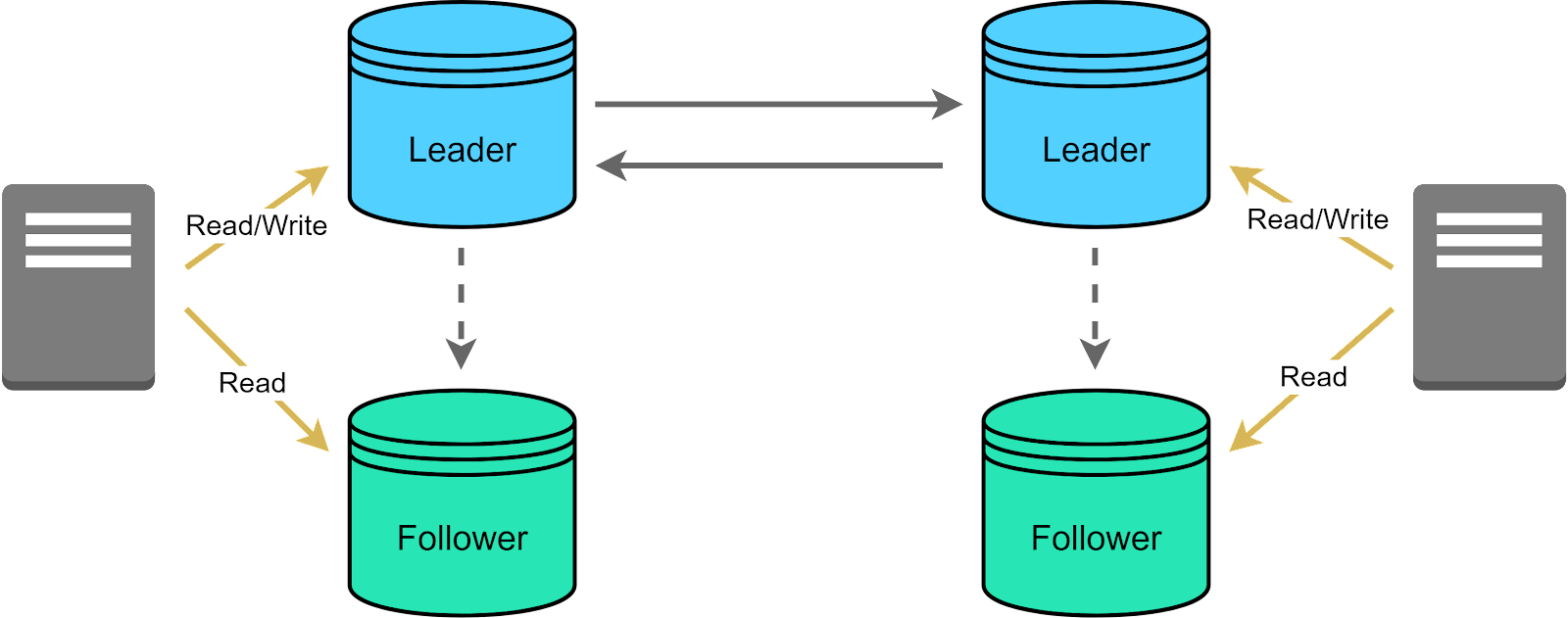
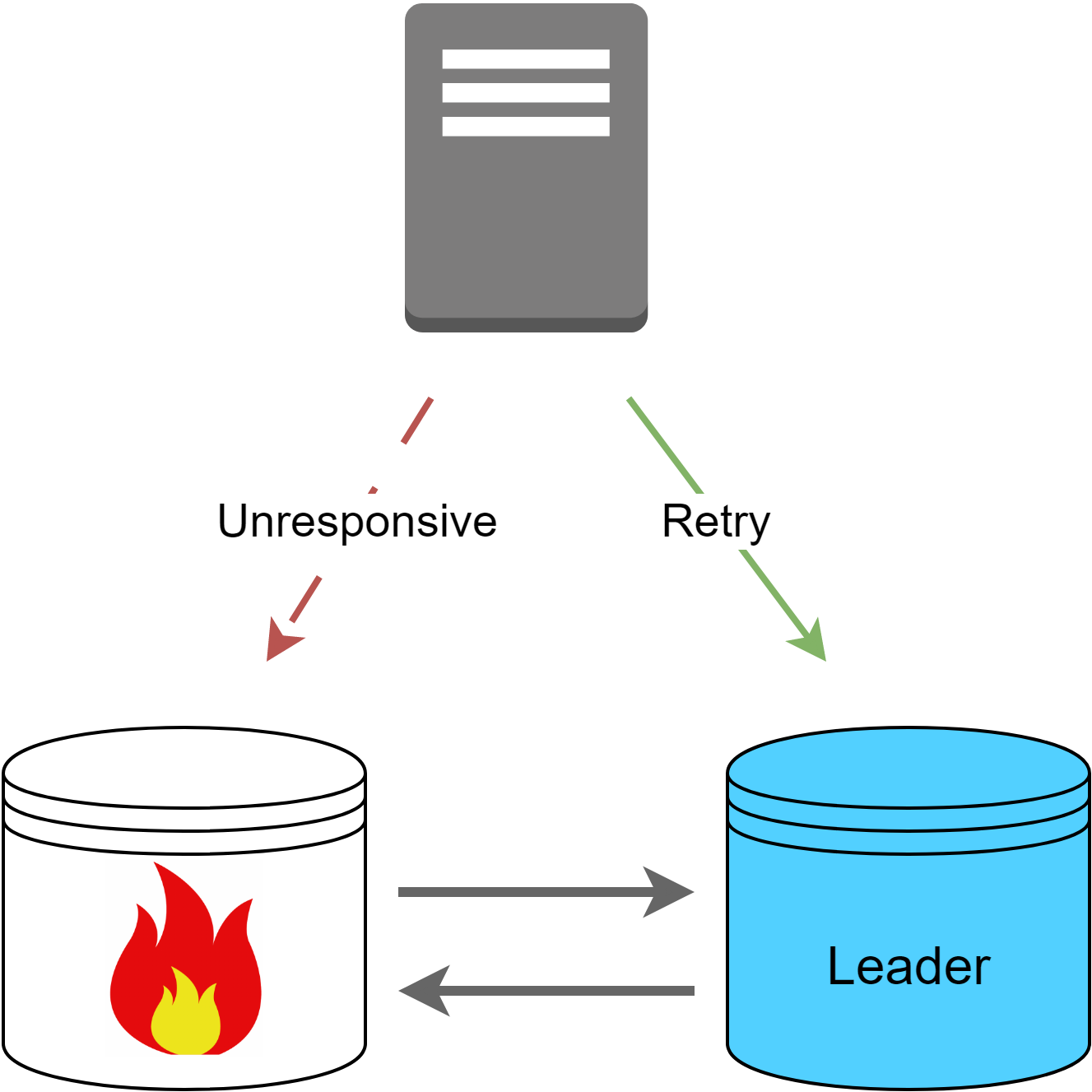
The primary advantage of this model is increased write availability. With multiple active leaders, failure of one node doesn't disrupt writes - other leaders continue handling write requests. This improves upon leader-follower designs where a failed leader halts writes until a new leader is available.
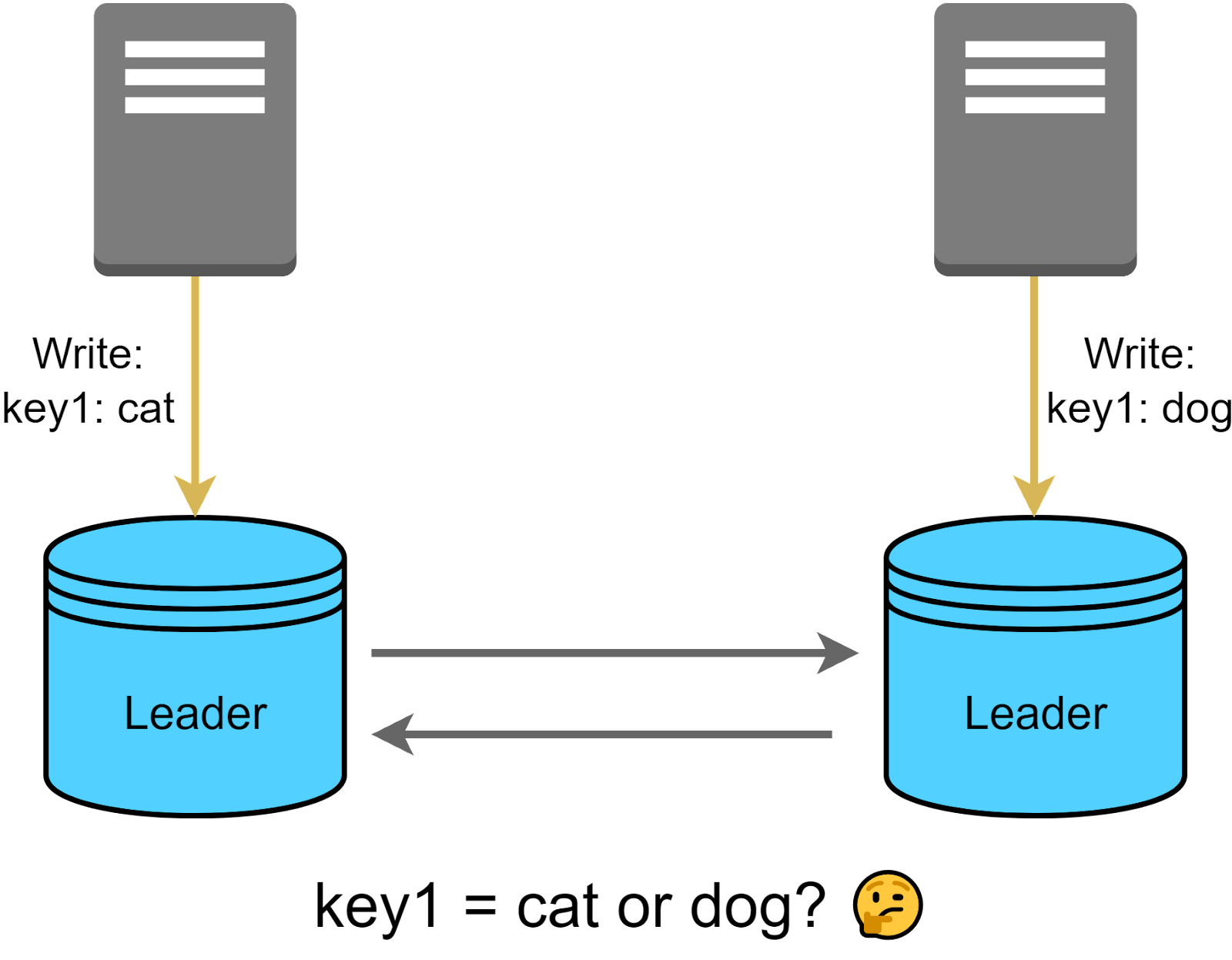
However, multi-leader replication comes with its own set of challenges. For instance, with multiple leaders handling write requests, conflicting changes may occur when leaders modify the same data concurrently.
Managing Conflict
Conflicts are a natural outcome in multi-leader replication models given that multiple leaders can perform write operations simultaneously. Effective conflict management is a complex task, but it is crucial for ensuring data consistency and integrity.
Here are some commonly employed conflict resolution strategies.
Last Write Wins
This is a straightforward method where the most recent change takes precedence. While easy to implement, it risks discarding important updates.
Conflict-free Replicated Data Types (CRDTs)
CRDTs allow for seamless reconciliation of conflicting changes by merging them. CRDTs come in various types for different kinds of data like counters, sets, and lists, and automatically resolve conflicts without requiring a separate conflict resolution process.
Operational Transformation
Operational transformation is often used in real-time collaborative applications. It takes the operation itself into account, not just the state of the data. This method is complex to implement but offers fine-grained control.
Application-specific Resolution
In some cases, conflict resolution logic can be pushed to the application level. The application can employ domain-specific rules or even involve human intervention for resolving conflicts.
Data Partitioning
Another alternative is to partition data across multiple leaders to minimize conflicting changes. However, implementing cross-partition transactions requires careful coordination, and potential hot spots on busy data partitions need to be managed effectively. It’s worth noting that this strategy can reduce the overall write throughput across the cluster.
Replication Lag and Inconsistent Reads
As with leader-follower replication, multi-leader systems are susceptible to replication lag and inconsistent reads. They cause temporary inconsistencies between leaders until updates fully propagate. Applications must be designed with this in mind.
Use Cases
What are some use cases for multi-leader replication? For applications that have users globally, multi-leader replication can reduce the latency for end-users by allowing them to interact with a nearby leader node.
Systems that cannot afford downtime, such as financial transaction platforms, can benefit from having multiple leaders. Even if one goes down, operations continue.
For applications with heavy write loads, distributing the write operations across multiple leaders can prevent any single node from becoming a bottleneck.
Tradeoffs and Challenges
In essence, multi-leader replication is particularly useful for applications that prioritize high write availability, fault tolerance, and globally-distributed data accessibility. Many modern databases can leverage this replication strategy, either natively, or with an extension, with varying degrees of success.
Multi-leader replication provides high availability but requires careful design around consensus, conflict detection, and resolution mechanisms. When implemented well, it can be a powerful approach for maximizing write throughput and availability.
In the next section, we’ll explore the leaderless replication model which takes a different approach.
Leaderless Replication
Leaderless replication takes a quorum-based approach. This concept may sound a bit strange, especially when we've just spent some time discussing models that operate under a clear hierarchy. In a leaderless system, any node in the network has the authority to accept write operations. The absence of a single leader fundamentally changes the dynamics of our system.
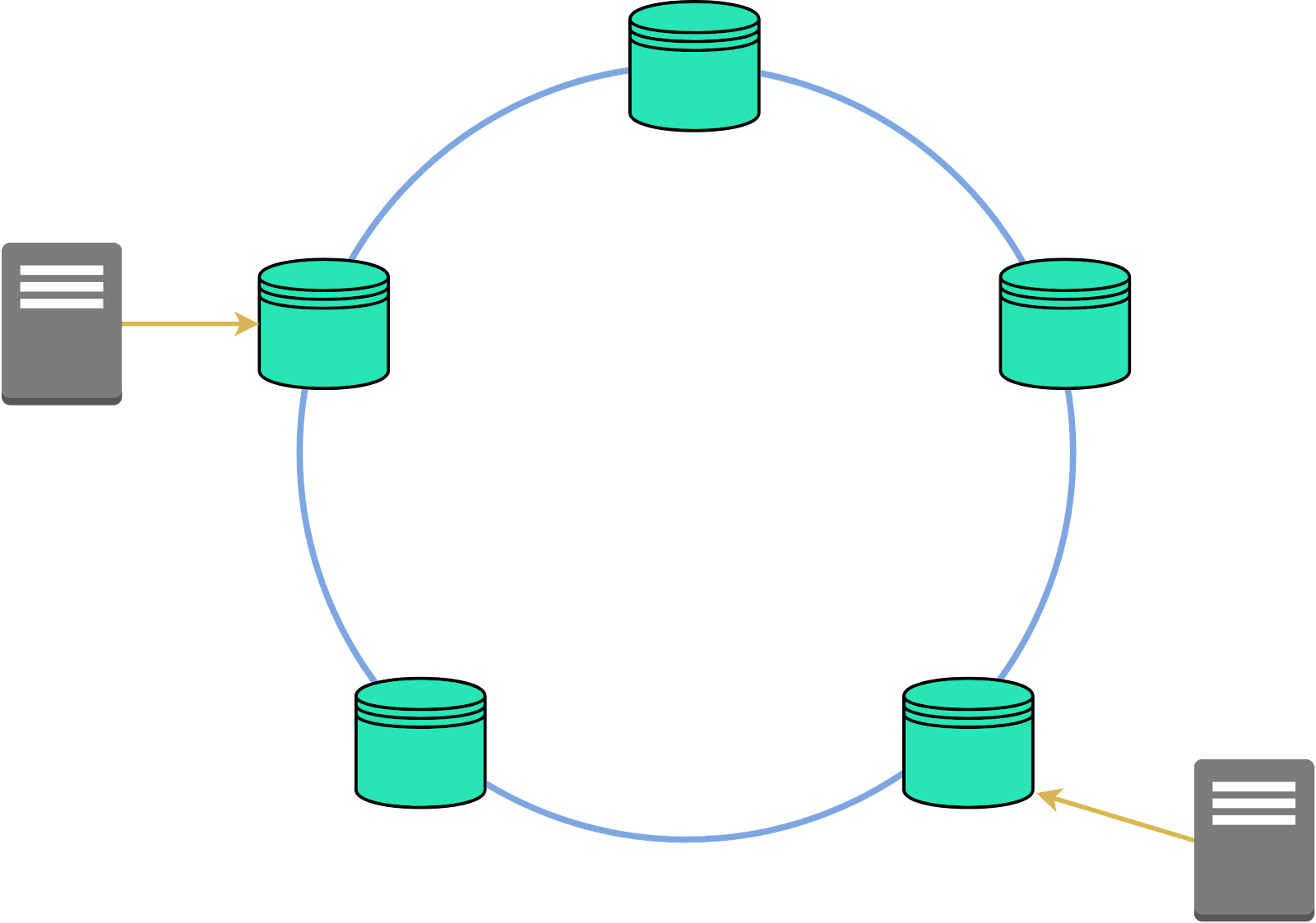
Quorum Writes and Reads
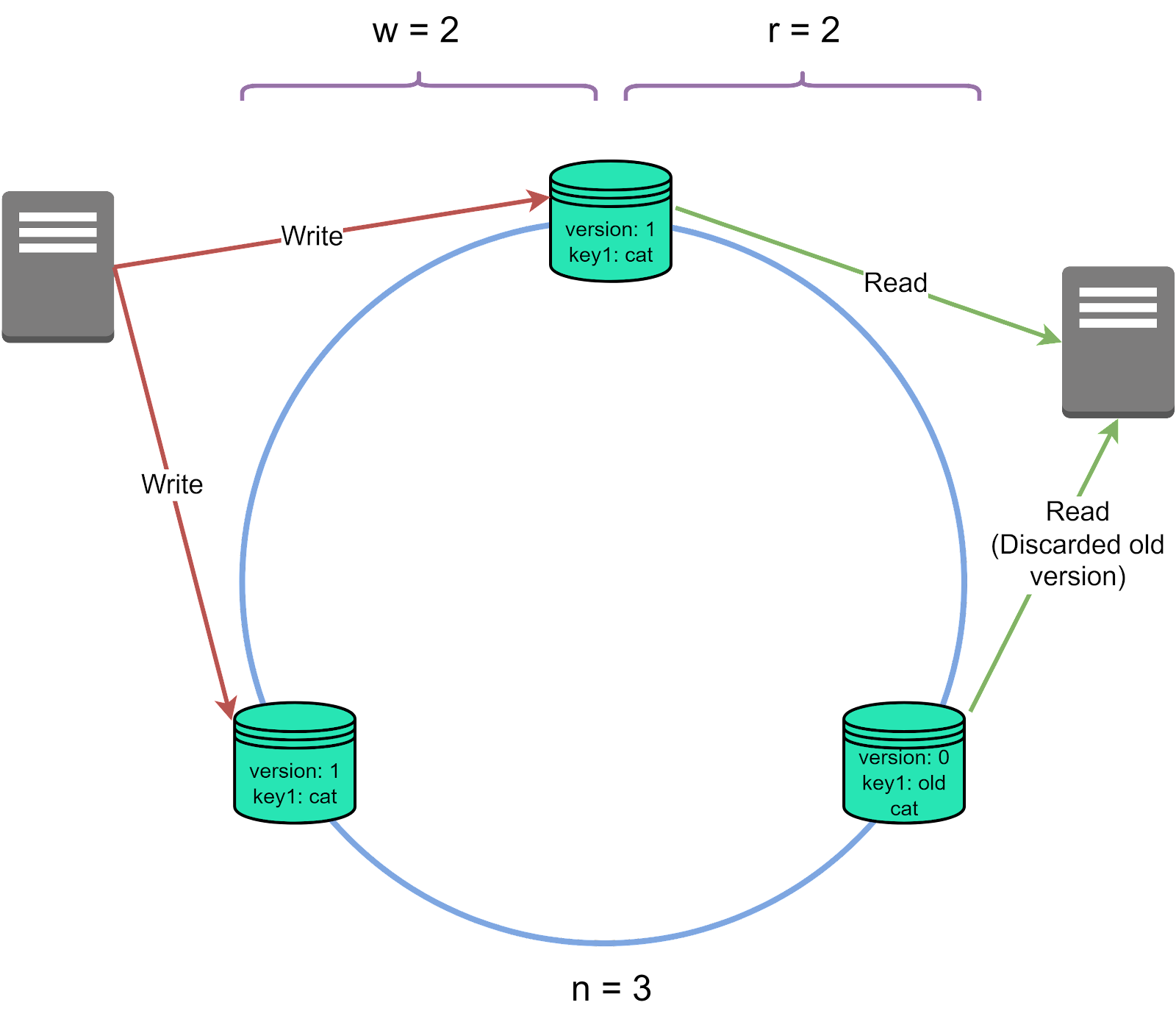
Now, let's start with a key concept that underpins leaderless replication: 'quorum writes and reads'. In a system without a leader, we don't rely on any single node to validate a read or write operation. Instead, we aim for consensus among a certain number of nodes. This number is called the 'quorum'. Using a quorum approach balances high availability with data accuracy, since we no longer require full consensus across all nodes.
In this system, we use three important values.
'n' is the total number of nodes in our system.
'W', the write quorum, is the minimum number of nodes that need to agree for a write to be considered successful.
'r', the read quorum, is the minimum number of nodes that need to agree for a read to be valid.
For strong consistency, a general guideline is to have w + r > n. It ensures that any read overlaps with any write and returns the most recent value.
For example, imagine a system with 3 nodes (n=3). If we configure w to 2, that means we need two out of three nodes to acknowledge a write request before it is deemed successful. If one of the nodes went down, the write operations could still continue. This idea works similarly for reads. If r is set to 2, the read operation would query 2 nodes and return the most recent data between the two.