
How Uber Eats Handles Billions of Daily Search Queries

Be part of P99 CONF – All things performance (Sponsored)

Obsessed with performance and low latency engineering? Discuss your optimizations and lessons learned with ~30K like-minded engineers… at P99 CONF 2025!
P99 CONF is a highly technical conference known for lively discussion. ScyllaDB makes it free and virtual, so it’s open to experts around the world. Core topics for this year include Rust, Zig, databases, event streaming architectures, measurement, compute/infrastructure, Linux, Kubernetes, and AI/ML.
If you’re selected to speak, you’ll be in amazing company. Past speakers include the creators of Postgres, Bun, Honeycomb, tokio, and Flask – plus engineers from today’s most impressive tech leaders.
Bonus: Early bird registrants get 30-day access to the complete O’Reilly library & learning platform, plus free digital books
Disclaimer: The details in this post have been derived from the articles/videos shared online by the Uber Eats engineering team. All credit for the technical details goes to the Uber Eats Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Uber Eats set out to increase the number of merchants available to users by a significant multiple. The team referred to it as nX growth. This wasn’t a simple matter of onboarding more restaurants. It meant expanding into new business lines like groceries, retail, and package delivery, each with its scale and technical demands.
To accommodate this, the search functionality needed to support this growth across all discovery surfaces:
Home feed, where users browse curated carousels.
Search, covering restaurant names, cuisines, and individual dishes.
Suggestions, which include autocomplete and lookahead logic.
Ads, which plug into the same backend and share the same constraints.
The challenge wasn’t just to show more. It was to do so without increasing latency, without compromising ranking quality, and without introducing inconsistency across surfaces.
A few core problems made this difficult:
Vertical expansion: Grocery stores often include over 100,000 items per location. Retail and package delivery add their indexing complexity.
Geographic expansion: The platform shifted from neighborhood-level search to intercity delivery zones.
Search scale: More merchants and more items meant exponential growth in the number of documents to index and retrieve.
Latency pressure: Every additional document increases compute costs in ranking and retrieval. Early attempts to scale selection caused 4x spikes in query latency.
To support nX merchant growth, the team had to rethink multiple layers of the search stack from ingestion and indexing to sharding, ranking, and query execution. In this article, we look at the breakdown of how Uber Eats rebuilt its search platform to handle this scale without degrading performance or relevance.
The 2025 State of Testing in DevOps Report (Sponsored)

mabl’s 6th State of Testing in DevOps Report explores the impact of software testing, test automation, organizational growth, and DevOps maturity across the software development lifecycle.
Search Architecture Overview
Uber Eats search is structured as a multi-stage pipeline, built to balance large-scale retrieval with precise, context-aware ranking.
Each stage in the architecture has a specific focus, starting from document ingestion to final ranking. Scaling the system for millions of merchants and items means optimizing each layer without introducing bottlenecks downstream.

Ingestion and Indexing
The system ingests documents from multiple verticals (restaurants, groceries, retail) and turns them into searchable entities.
There are two primary ingestion paths:
Batch Ingestion: Large-scale updates run through Apache Spark jobs. These jobs transform raw source-of-truth data into Lucene-compatible search documents, partition them into shards, and store the resulting indexes in an object store. This is the backbone for most index builds.
Streaming Ingestion: Real-time updates flow through Kafka as a write-ahead log. A dedicated ingestion service consumes these updates, maps them to the appropriate shard, and writes them into the live index.
Priority-Aware Ingestion: Not all updates are equal. The system supports priority queues so urgent updates, like price changes or store availability, are ingested ahead of less critical ones. This ensures high-priority content reflects quickly in search results.
Retrieval Layer
The retrieval layer acts as the front line of the search experience. Its job is to fetch a broad set of relevant candidates for downstream rankers to evaluate.
Recall-focused retrieval: The system fetches as many potentially relevant documents as possible, maximizing coverage. This includes stores, items, and metadata mapped to the user’s location.
Geo-aware matching: Given that most searches are tied to physical delivery, the retrieval process incorporates location constraints using geo-sharding and hex-based delivery zones. Queries are scoped to shards that map to the user’s region.
First-Pass Ranking
Once the initial candidate set is retrieved, a lightweight ranking phase begins.
Lexical matching: Uses direct term overlap between the user’s query and the indexed document fields.
Fast filtering: Filters out low-relevance or out-of-scope results quickly, keeping only candidates worth further evaluation.
Efficiency-focused: This stage runs directly on the data nodes to avoid unnecessary network fanout. It's designed for speed, not deep personalization.
Hydration Layer
Before documents reach the second-pass ranker, they go through a hydration phase.
Each document is populated with additional context: delivery ETAs, promotional offers, loyalty membership info, and store images. This ensures downstream components have all the information needed for ranking and display.
Second-Pass Ranking
This is where the heavier computation happens, evaluating business signals and user behavior.
Personalized scoring: Models incorporate past orders, browsing patterns, time of day, and historical conversion rates to prioritize results that match the user’s intent.
Business metric optimization: Ranking is also shaped by conversion likelihood, engagement metrics, and performance of past campaigns, ensuring search results aren’t just relevant, but also effective for both user and platform.
The Query Scaling Challenge
Scaling search isn't just about fetching more documents. It's about knowing how far to push the system before performance breaks.
At Uber Eats, the first attempt to increase selection by doubling the number of matched candidates from 200 to 400 seemed like a low-risk change. In practice, it triggered a 4X spike in P50 query latency and exposed deeper architectural flaws.
The idea was straightforward: expand the candidate pool so that downstream rankers have more choices. More stores mean better recall. However, the cost wasn’t linear because of the following reasons:
Search radius grows quadratically: Extending delivery range from 5 km to 10 km doesn’t double the document count—it increases the search area by a factor of four. Every added kilometer pulls in a disproportionately larger set of stores.
Retrieval becomes I/O-bound: The number of documents per request ballooned. Queries that once matched a few thousand entries now had to sift through tens of thousands. The Lucene index, tuned for fast lookups, started choking during iteration.
Geo-sharding Mismatches
The geo-sharding strategy, built around delivery zones using hexagons, wasn't prepared for expanded retrieval scopes.
As delivery radii increased, queries began touching more distant shards, many of which were optimized for different traffic patterns or data distributions. This led to inconsistent latencies and underutilized shards in low-traffic areas.
Pipeline Coordination Gaps
Ingestion and query layers weren’t fully aligned.
The ingestion service categorizes stores as “nearby” or “far” based on upstream heuristics. These classifications didn’t carry over cleanly into the retrieval logic. As a result, rankers treated distant and local stores the same, skewing relevance scoring and increasing CPU time.
Geospatial Indexing with H3 and the Sharding Problem
Uber Eats search is inherently geospatial. Every query is grounded in a delivery address, and every result must answer a core question: Can this store deliver to this user quickly and reliably?
To handle this, the system uses H3, Uber’s open-source hexagonal spatial index, to model the delivery world.
H3-Based Delivery Mapping
Each merchant’s delivery area is mapped using H3 hexagons:
The world is divided into hexagonal tiles at a chosen resolution.
A store declares delivery availability to a specific set of hexes.
The index then builds a reverse mapping: for any hex, which stores deliver to it?
This structure makes location-based lookups efficient. Given a user’s location, the system finds their H3 hexagon and retrieves all matching stores with minimal fanout.

Where Ingestion Fell Short
The problem wasn’t the mapping but the metadata.
Upstream services were responsible for labeling stores as “close” or “far” at ingestion time. This binary categorization was passed downstream without actual delivery time (ETA) information.
Once ingested, the ranking layer saw both close and far stores as equivalent. That broke relevance scoring in subtle but important ways.
Consider this:
Hexagon 7 might have two stores marked as “far.”
One is 5 minutes away, the other 30.
To the search system, they look the same.
That lack of granularity meant distant but high-converting stores would often outrank nearby ones. Users saw popular chains from across the city instead of the closer, faster options they expected.
Sharding Techniques
Sharding determines how the system splits the global index across machines.
A good sharding strategy keeps queries fast, data well-balanced, and hotspots under control. A bad one leads to overloaded nodes, inconsistent performance, and painful debugging sessions.
Uber Eats search uses two primary sharding strategies: Latitude sharding and Hex sharding. Each has trade-offs depending on geography, query patterns, and document distribution.
Latitude Sharding
Latitude sharding divides the world into horizontal bands. Each band corresponds to a range of latitudes, and each range maps to a shard. The idea is simple: group nearby regions based on their vertical position on the globe.
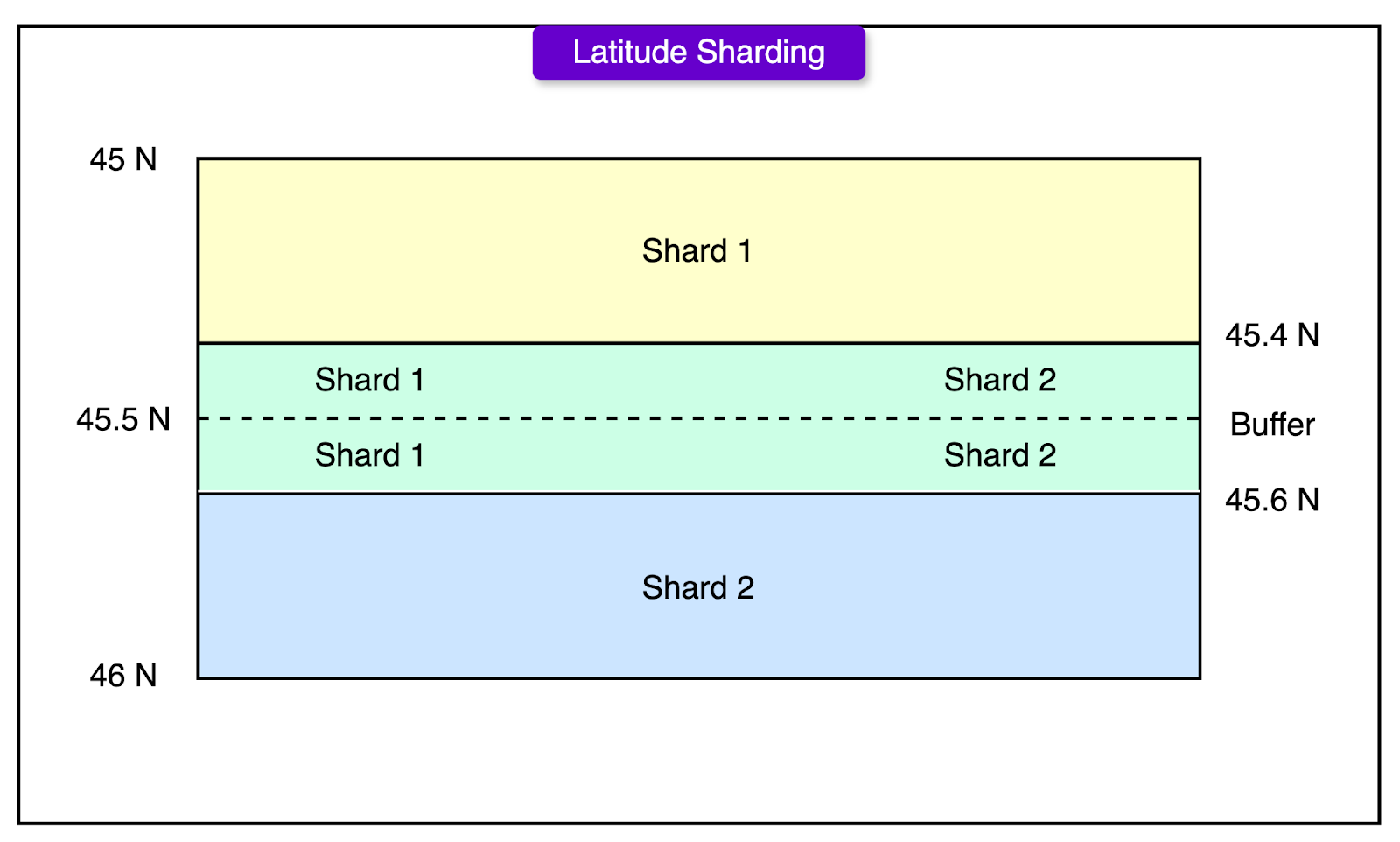
Shard assignment is computed offline using Spark. The process involves two steps:
Slice the map into thousands of narrow latitude stripes.
Group adjacent stripes into N roughly equal-sized shards, based on document count.
To avoid boundary misses, buffer zones are added. Any store that falls near the edge of a shard is indexed in both neighboring shards. The buffer width is based on the maximum expected search radius, converted from kilometers into degrees of latitude.
The benefits of this approach are as follows:
Time zone diversification: Shards include cities from different time zones (for example, the US and Europe). This naturally spreads out traffic peaks, since users in different zones don’t search at the same time.
Query locality: Many queries resolve within a single shard. That keeps fanout low and speeds up ranking.
The downsides are as follows:
Shard imbalance: Dense urban areas near the equator (for example, Southeast Asia) pack far more stores per degree of latitude than sparsely populated regions. Some shards grow much larger than others.
Slower index builds: Indexing time is gated by the largest shard. Skewed shard sizes lead to uneven performance and increased latency.
Hex Sharding
To address the limitations of latitude sharding, Uber Eats also uses Hex sharding, built directly on top of the H3 spatial index. Here’s how it works:
The world is tiled using H3 hexagons at a fixed resolution (typically level 2 or 3).
Each hex contains a portion of the indexed documents.
A bin-packing algorithm groups hexes into N shards with roughly equal document counts.
Buffer zones are handled similarly, but instead of latitude bands, buffer regions are defined as neighboring hexagons at a lower resolution. Any store near a hex boundary is indexed into multiple shards to avoid cutting off valid results.
The benefits are as follows:
Balanced shards: Bin-packing by document count leads to far more consistent shard sizes, regardless of geography.
Better cache locality: Queries scoped to hexes tend to access tightly grouped data. That improves memory access patterns and reduces retrieval cost.
Less indexing skew: Because hexes are spatially uniform, indexing overhead stays predictable across regions.
As a takeaway, latitude sharding works well when shard traffic needs to be spread across time zones, but it breaks down in high-density regions.
Hex sharding offers more control, better balance, and aligns naturally with the geospatial nature of delivery. Uber Eats uses both, but hex sharding has become the more scalable default, especially as selection grows and delivery radii expand.
Index Layout Optimizations
When search systems slow down, it’s tempting to look at algorithms, infrastructure, or sharding. But often, the bottleneck hides in a quieter place: how the documents are laid out in the index itself.
At Uber Eats scale, index layout plays a critical role in both latency and system efficiency. The team optimized layouts differently for restaurant (Eats) and grocery verticals based on query patterns, item density, and retrieval behavior.
Eats Index Layout
Restaurant queries typically involve users looking for either a known brand or food type within a city. For example, “McDonald’s,” “pizza,” or “Thai near me.” The document layout reflects that intent.
Documents are sorted as:
City
Restaurant
Items within each restaurant
This works for the following reasons:
Faster city filtering: Queries scoped to San Francisco don’t need to scan through documents for Tokyo or Boston. The search pointer skips irrelevant sections entirely.
Improved compression: Lucene uses delta encoding. Grouping items from the same store, where metadata like delivery fee or promo is often repeated, yields tighter compression.
Early termination: Documents are sorted by static rank (for example, popularity or rating). Once the system retrieves enough high-scoring results, it stops scanning further.
Grocery Index Layout
Grocery stores behave differently. A single store may list hundreds or thousands of items, and queries often target a specific product ( “chicken,” “milk,” “pasta”) rather than a store.
Here, the layout is:
City
Store (sorted by offline conversion rate)
Items grouped tightly under each store
This matters for the following reasons:
Per-store budget enforcement: To avoid flooding results from one SKU-heavy store, the system imposes a per-store document budget. Once a store’s quota is met, the index skips to the next.
Diverse results: Instead of returning 100 versions of “chicken” from the same retailer, the layout ensures results are spread across stores.
Faster skip iteration: The tight grouping allows the system to jump across store boundaries efficiently, without scanning unnecessary items.
Performance Impact
The improvements of these indexing strategies were pretty good:
Retrieval latency dropped by 60%
P95 latency improved by 50%
Index size reduced by 20%, thanks to better compression

ETA-Aware Range Indexing
Delivery time matters. When users search on Uber Eats, they expect nearby options to show up first, not restaurants 30 minutes away that happen to rank higher for other reasons. But for a long time, the ranking layer couldn’t make that distinction. It knew which stores delivered to a given area but not how long delivery would take.
This is because the ingestion pipeline didn’t include ETA (Estimated Time of Delivery) information between stores and hexagons. That meant:
The system treated all deliverable stores as equal, whether they were 5 minutes or 40 minutes away.
Ranking logic had no signal to penalize faraway stores when closer alternatives existed.
Popular but distant stores would often dominate results, even if faster options were available.
This undermined both user expectations and conversion rates. A store that looks promising but takes too long to deliver creates a broken experience.
The Solution: Range-Based ETA Bucketing
To fix this, Uber Eats introduced ETA-aware range indexing. Instead of treating delivery zones as flat lists, the system:
Binned stores into time-based ranges: Each store was indexed into one or more delivery buckets based on how long it takes to reach a given hex. For example:
Range 1: 0 to 10 minutes
Range 2: 10 to 20 minutes
Range 3: 20 to 30 minutes
Duplicated entries across ranges: A store that’s 12 minutes from one hex and 28 minutes from another would appear in both Range 2 and Range 3. This added some storage overhead, but improved retrieval precision.
Ran range-specific queries in parallel: When a user queried from a given location, the system launched multiple subqueries—one for each ETA bucket. Each subquery targeted its corresponding shard slice.

This approach works for the following reasons:
Recall improves: The system surfaces more candidates overall, across a wider range of delivery times without overloading a single query path.
Latency drops: By splitting the query into parallel, bounded range scans, each shard does less work, and total response time shrinks.
Relevance becomes proximity-aware: Rankers now see not just what a store offers, but how fast it can deliver, enabling better tradeoffs between popularity and speed.
Conclusion
Scaling Uber Eats search to support nX merchant growth wasn’t a single optimization. It was a system-wide redesign.
Latency issues, ranking mismatches, and capacity bottlenecks surfaced not because one layer failed, but because assumptions across indexing, sharding, and retrieval stopped holding under pressure.
This effort highlighted a few enduring lessons that apply to any high-scale search or recommendation system:
Documents must be organized around how queries behave. Misaligned layouts waste I/O, increase iteration cost, and cripple early termination logic.
A good sharding strategy accounts for document distribution, query density, and even time zone behavior to spread traffic and avoid synchronized load spikes.
When profiling shows document iteration taking milliseconds instead of microseconds, the problem isn’t ranking but traversal. Optimizing storage access patterns often yields bigger wins than tuning ranking models.
Storing the same store in multiple ETA buckets increases index size, but dramatically reduces compute at query time. Every gain in recall, speed, or freshness has to be weighed against storage, complexity, and ingestion cost.
Breaking queries into ETA-based subranges, separating fuzzy matches from exact ones, or running proximity buckets in parallel all help maintain latency while expanding recall.
In a system touched by dozens of teams and services, observability is a prerequisite. Latency regressions, ingestion mismatches, and ranking anomalies can't be fixed without precise telemetry and traceability.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
A powerful and insightful breakdown of geospatial indexing, ranking pipelines, and query optimization at scale.
As someone who has designed geospatial AI systems from the ground up, I deeply resonate with their approach: dividing the Earth’s surface using H3 indexing, leveraging distributed KV stores, and structuring retrieval pipelines that scale with spatial complexity.
The benefits are clear - but so is the cost.
Geospatial search systems offer tremendous value:
- Location-aware retrieval enables faster, more relevant, and proximity-sensitive results
- H3 or similar indexes make spatial queries efficient and scalable
- KV-based architectures are well-suited for fast lookups at scale
However, from my direct experience:
- Implementing these systems requires highly specialized knowledge, spanning geospatial computation, distributed systems, and indexing theory.
- Building and operating custom search infrastructures with technologies like Apache Spark, Lucene, Kafka, and distributed object storage introduces significant architectural and maintenance costs.
- Relational databases simply do not perform well for geospatial or proximity-based queries at real-world scale. Without dedicated spatial indexing and storage design, query latency becomes unacceptable.
While global tech giants can afford these systems, their complexity and niche knowledge requirements have prevented broader adoption, especially in local or regional contexts.
I believe it’s time to democratize geospatial search infrastructure to make it understandable, usable, and relevant for local communities, small businesses, and municipalities.
We don’t just need better tools -- we need better narratives, education, and shared frameworks to bring these ideas to life at human scale.