
How Uber Serves over 150 Million Reads per Second from Integrated Cache

How Coinbase made incident investigations 72% faster (Sponsored)

Writing code is no longer the bottleneck. Instead, engineering orgs spend 70%+ of their time investigating incidents and trying to debug the sh** out of prod.
Engineering teams at Coinbase, DoorDash, Salesforce, and Zscaler use Resolve AI’s AI SRE to help resolve incidents before on-call is out of bed and to optimize costs, team time, and new code created with production context.
Download the free buyer’s guide to learn more about the ROI of AI SRE, or join our online FinServ fireside chat on Jan 22 with eng leaders at MSCI and SoFi to hear how large-scale institutions are evaluating and implementing AI for prod in 2026.
Disclaimer: The details in this post have been derived from the details shared online by the Uber Engineering Team. All credit for the technical details goes to the Uber Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When you open the Uber app to request a ride, check your trip history, or view driver details, you expect instant results. Behind that seamless experience lies a sophisticated caching system. Uber’s CacheFront serves over 150 million database reads per second while maintaining strong consistency guarantees.
In this article, we break down how Uber built this system, the challenges they faced, and the innovative solutions they developed.
Why Caching Matters
Every time a user interacts with Uber’s platform, the system needs to fetch data like user profiles, trip details, driver locations, and pricing information. Reading directly from a database for every request introduces latency and creates a massive load on database servers. When you have millions of users making billions of requests per day, traditional databases cannot keep up.
Caching solves this by storing frequently accessed data in a faster storage system. Instead of querying the database every time, the application first checks the cache. If the data exists there (a cache hit), it returns immediately. If not (a cache miss), the system queries the database and stores the result in cache for future requests.
See the diagram below:
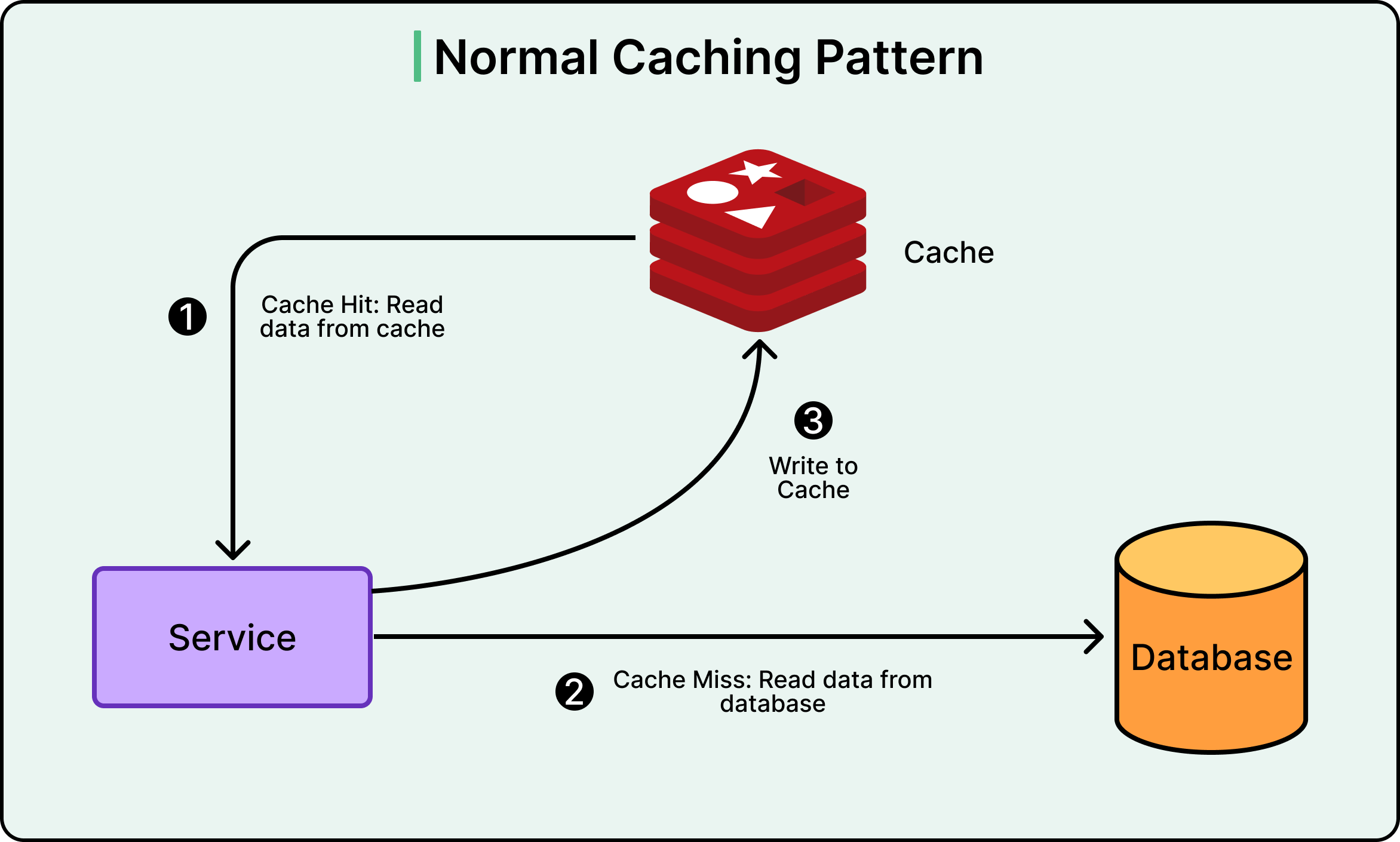
Uber uses Redis, an in-memory data store, as their cache. Redis can serve data in microseconds compared to milliseconds for database queries.
[Coderabbit]
The Architecture: Three Layers Working Together
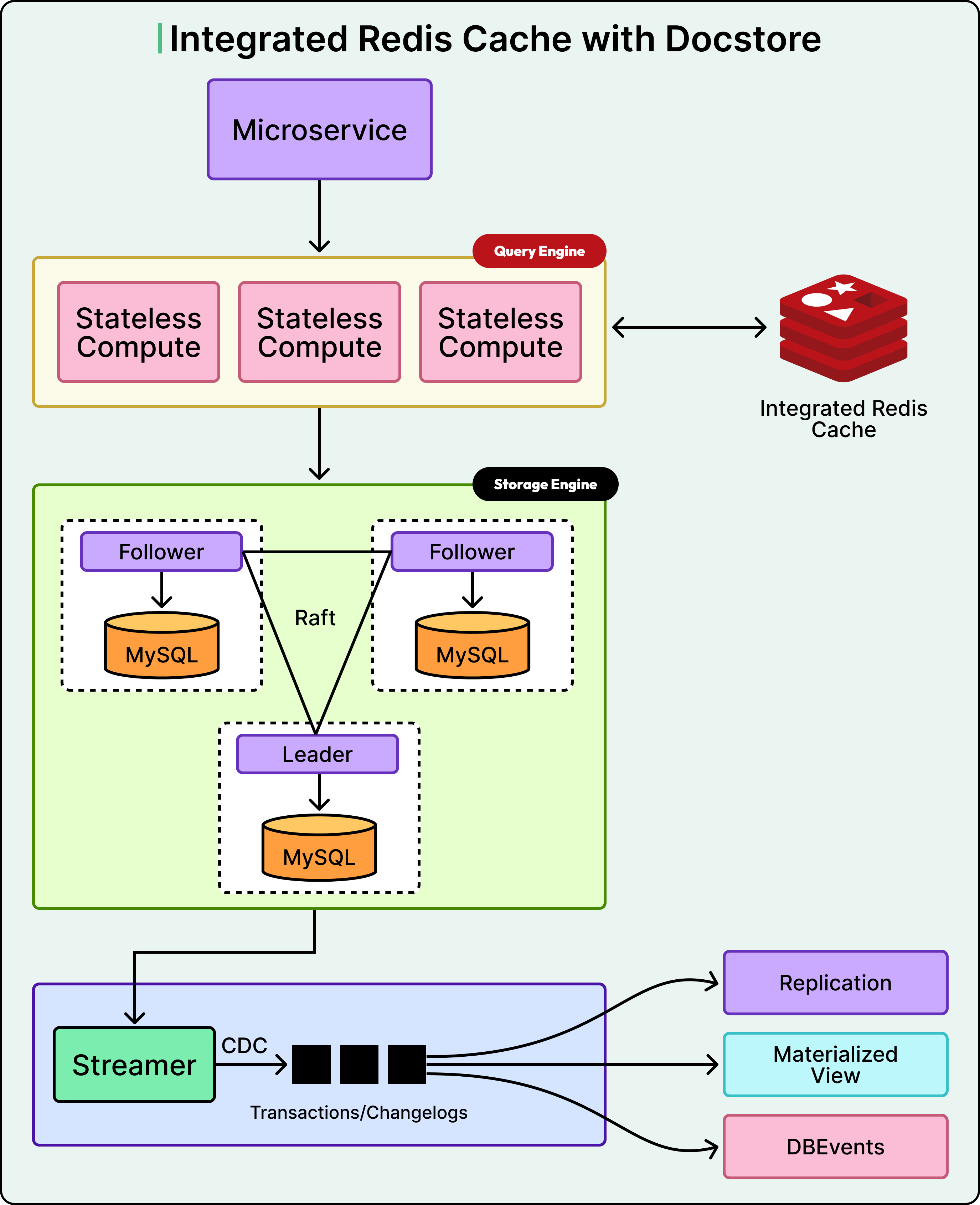
Uber’s storage system, called Docstore, consists of three main components.
The Query Engine layer is stateless and handles all incoming requests from Uber’s services.
The Storage Engine layer is where data actually lives, using MySQL databases organized into multiple nodes.
CacheFront is the caching logic implemented within the Query Engine layer, sitting between application requests and the database.
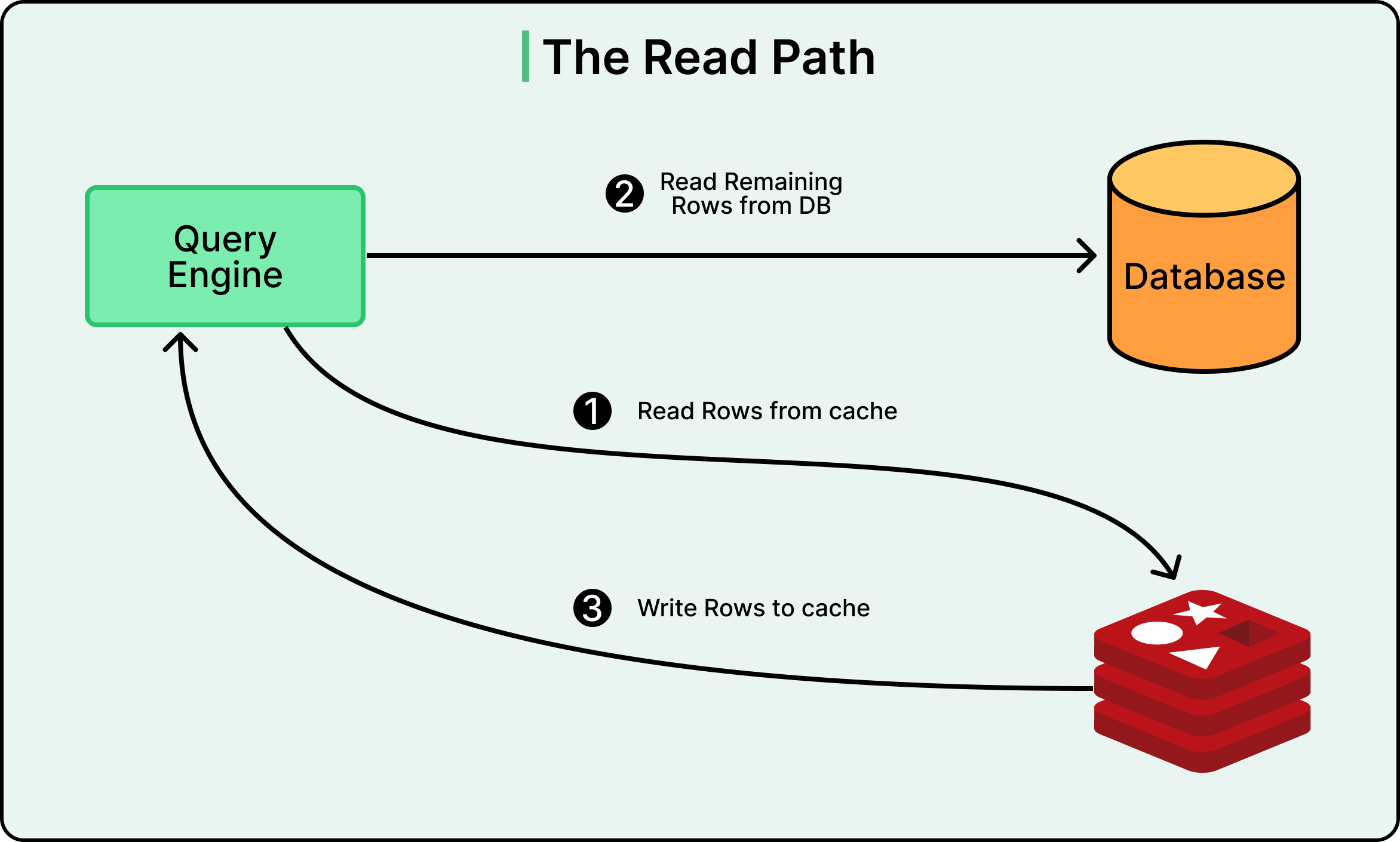
The Read Path
When a read request comes in, CacheFront first checks Redis. If the data exists in Redis, it returns immediately to the client. Uber achieves cache hit rates above 99.9% for many use cases, meaning only a tiny fraction of requests need to touch the database.
If the data does not exist in Redis, CacheFront fetches it from MySQL, writes it to Redis, and returns the result to the client. The system can handle partial cache misses as well. For example, if a request asks for ten rows and seven exist in cache, it only fetches the missing three from the database.
The Write Path
Writes introduce significant complexity to any caching system. When data changes in the database, the cached copies of that data become stale. Serving stale data breaks application logic and creates poor user experiences. For example, imagine updating your destination in the Uber app, but the system keeps showing your old destination because it is reading from an outdated cache entry.
The challenge with refreshing the cache is determining which cache entries need to be invalidated when a write occurs. Uber supports two types of write operations, and they require different approaches.
Point writes are straightforward. These are INSERT, UPDATE, or DELETE queries where the exact rows being modified are specified in the query itself. For example, updating a specific user’s profile by their user ID. With point writes, you know exactly which cache entries to invalidate because the row keys are part of the query.
Conditional updates are far more complex. These are UPDATE or DELETE queries with WHERE clauses that filter based on conditions. For example, marking all trips longer than 60 minutes as completed. Before executing the query, you do not know which rows will match the condition, and therefore cannot invalidate the cache entries because you do not know which ones are affected.
This uncertainty meant that Uber initially could not invalidate the cache synchronously during writes. They had to rely on other mechanisms.
The Original Solution
Uber’s initial approach used a system called Flux, which implements Change Data Capture.
Flux monitors the MySQL binary logs, which record every change made to the database. When a write commits, MySQL writes it to the binlog. Flux tails these logs, sees which rows changed, and then invalidates or updates the corresponding entries in Redis. See the diagram below:
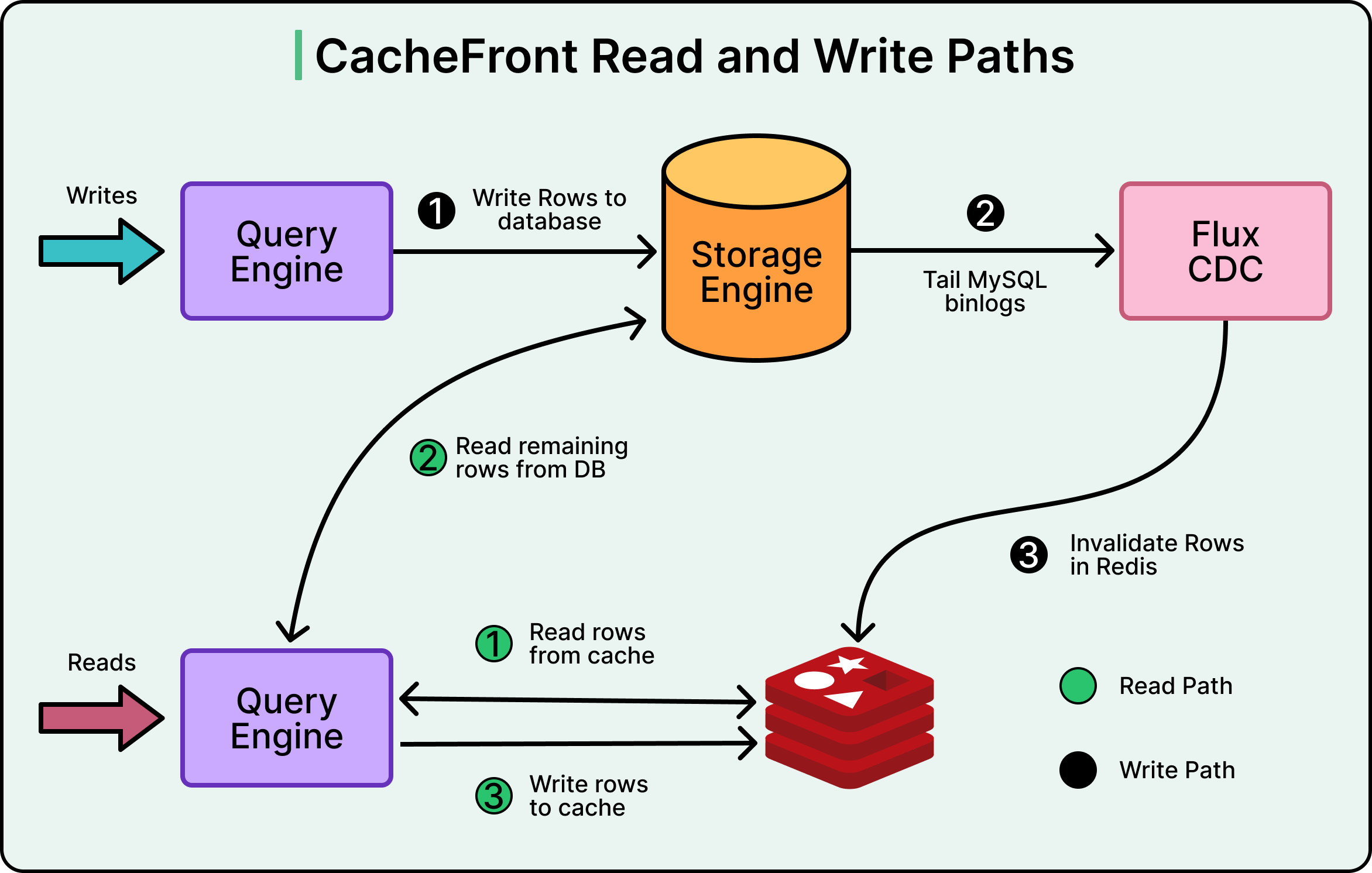
This approach worked, but had a critical limitation. Flux operates asynchronously, meaning there is a delay between when data changes in the database and when the cache gets updated. This delay is usually sub-second but can stretch longer during system restarts, deployments, or when handling topology changes.
This asynchronous nature creates consistency problems. If a user writes data and immediately reads it back, they might get the old cached value because Flux has not yet processed the invalidation. This violates read-your-own-writes consistency, which is a fundamental expectation in most applications.
The system also relied on Time-To-Live expiration. Every cache entry has a TTL that determines how long it stays in the cache before expiring. Uber’s default recommendation is 5 minutes, though this can be adjusted based on application requirements. TTL expiration acts as a backstop, ensuring that even if invalidations fail, stale data eventually gets removed.
However, TTL-based expiration alone is insufficient for many use cases. Service owners wanted higher cache hit rates, which pushed them to increase TTL values. However, longer TTLs mean data stays cached longer, improving hit rates but also increasing the window for serving stale data.
The Consistency Challenges
As Uber scaled CacheFront, three main sources of inconsistency emerged.
Cache invalidation delays from Flux created read-your-own-writes violations where a write followed immediately by a read could return stale data.
Cache invalidation failures occurred when Redis nodes became temporarily unresponsive, leaving stale entries until TTL expiration.
Finally, cache refills from lagging MySQL follower nodes could introduce outdated data if the follower had not yet replicated recent writes from the leader.
Staleness Beyond TTL
There was another subtle consistency issue that was related to how stale cached data can actually become. Most engineers assume that if you set a TTL of 5 minutes, stale data will exist for at most 5 minutes. This assumption is incorrect.
Consider this scenario:
A row was written to the database one year ago and has not been accessed since.
At time T, which is today, a read request comes in. The cache does not have this row, so it is fetched from the database and cached. The cached entry now contains one-year-old data.
Moments later, a write request updates this row in the database. Flux attempts to invalidate the cache entry, but the invalidation fails due to a temporary Redis issue. Now, the cache still contains the one-year-old value while the database has the fresh value.
For the next hour, assuming a one-hour TTL, every read request will return the one-year-old cached data.
In other words, the staleness is not bounded by the TTL duration. Even though TTL is only 1 hour, the application may be serving data that’s actually 1 year out of date. The TTL only controls how long the cache entry lives, not how old the data inside it can be.
This problem becomes more severe with longer TTLs. Service owners wanting higher cache hit rates would increase TTL to 24 hours or more. If an invalidation failed, they could serve extremely outdated data for the entire duration.
The Breakthrough: Making Conditional Updates Trackable
The fundamental blocker for synchronous cache invalidation was not knowing which rows changed during conditional updates.
Uber made two critical changes to their storage engine to solve this:
First, they converted all deletes to soft deletes by setting a tombstone flag instead of removing rows.
Second, they implemented strictly monotonic timestamps at microsecond precision, making each transaction uniquely identifiable.
With these guarantees, the system can now determine which rows were modified. When rows get updated, their timestamp column is set to the transaction’s unique timestamp. Just before committing, the system executes a lightweight query to select all row keys modified within that transaction’s timestamp window. This query is fast because the data is already cached in MySQL’s storage engine, and the timestamp column is indexed.
With the ability to track all modified rows, Uber redesigned the write path.
When a write request comes into the Query Engine, it registers a callback that executes when the storage engine responds. The response includes the success status, the set of affected row keys, and the transaction’s commit timestamp.
The callback uses this information to invalidate corresponding cache entries in Redis. This invalidation can happen synchronously (within the request context, adding latency but providing the strongest consistency) or asynchronously (queued to run outside the request context, avoiding latency but with slightly weaker guarantees).
See the diagram below:
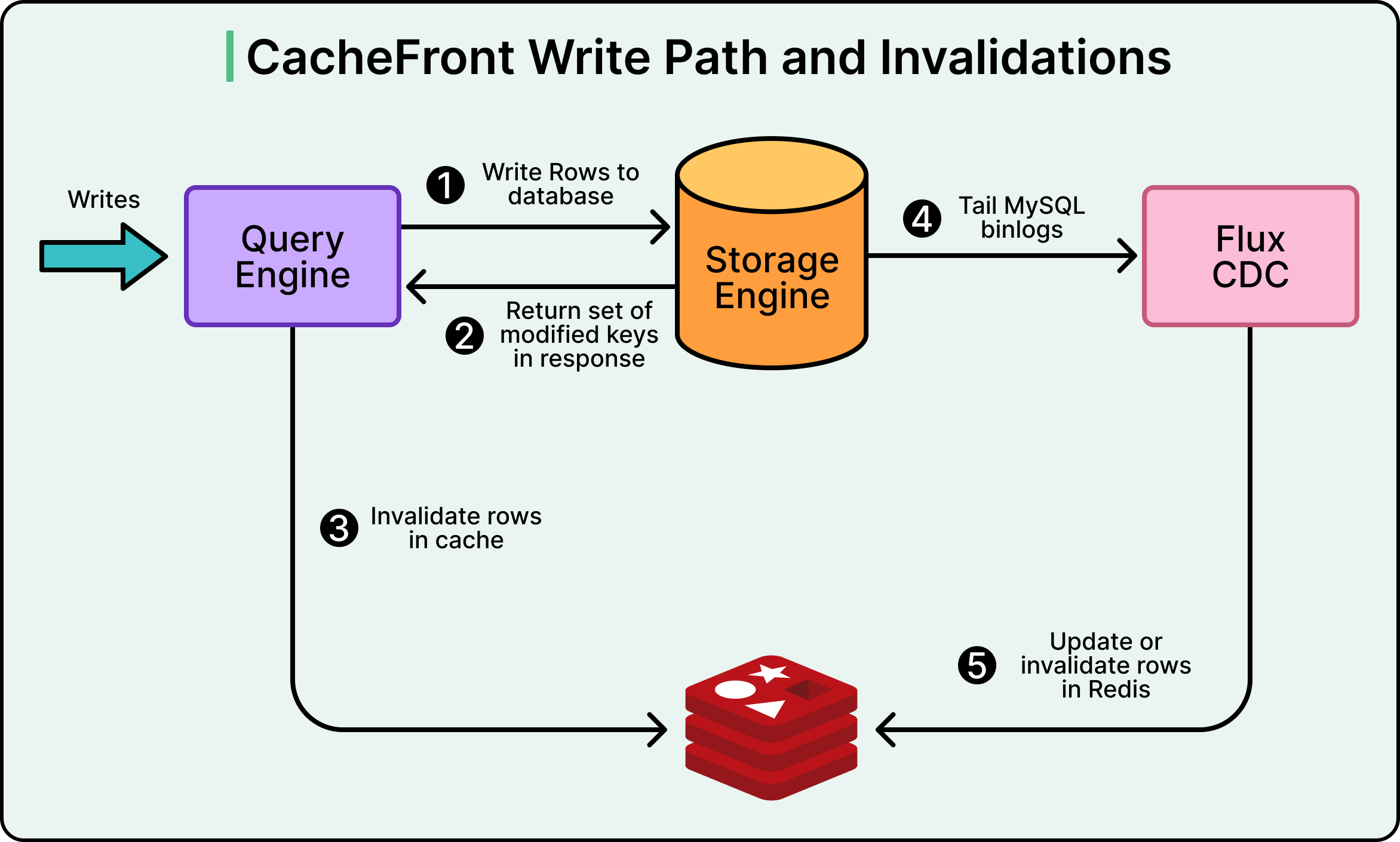
Critically, even if cache invalidation fails, the write request still succeeds. The system does not fail writes due to cache issues, preserving availability.
The Triple Defense Strategy
As you can see, Uber now runs three parallel mechanisms for keeping the cache consistent.
TTL expiration automatically removes entries after their configured lifetime (default 5 minutes).
Flux runs in the background, tailing MySQL binlogs and asynchronously invalidating cache entries.
Lastly, the new write-path invalidation provides immediate, synchronous cache updates when data changes.
Having three independent systems working together proved far more effective than relying on any single approach.
The Cache Inspector
To validate improvements and measure cache consistency, Uber built Cache Inspector. This tool uses the same CDC pipeline as Flux but with a one-minute delay. Instead of invalidating cache, it compares binlog events with what is stored in Redis, tracking metrics like stale entries found and staleness duration.
The results were encouraging. For tables using 24-hour TTLs, Cache Inspector found essentially zero stale values over week-long periods while cache hit rates exceeded 99.9%. This measurement capability allowed Uber to confidently increase TTL values for appropriate use cases, dramatically improving performance without sacrificing consistency.
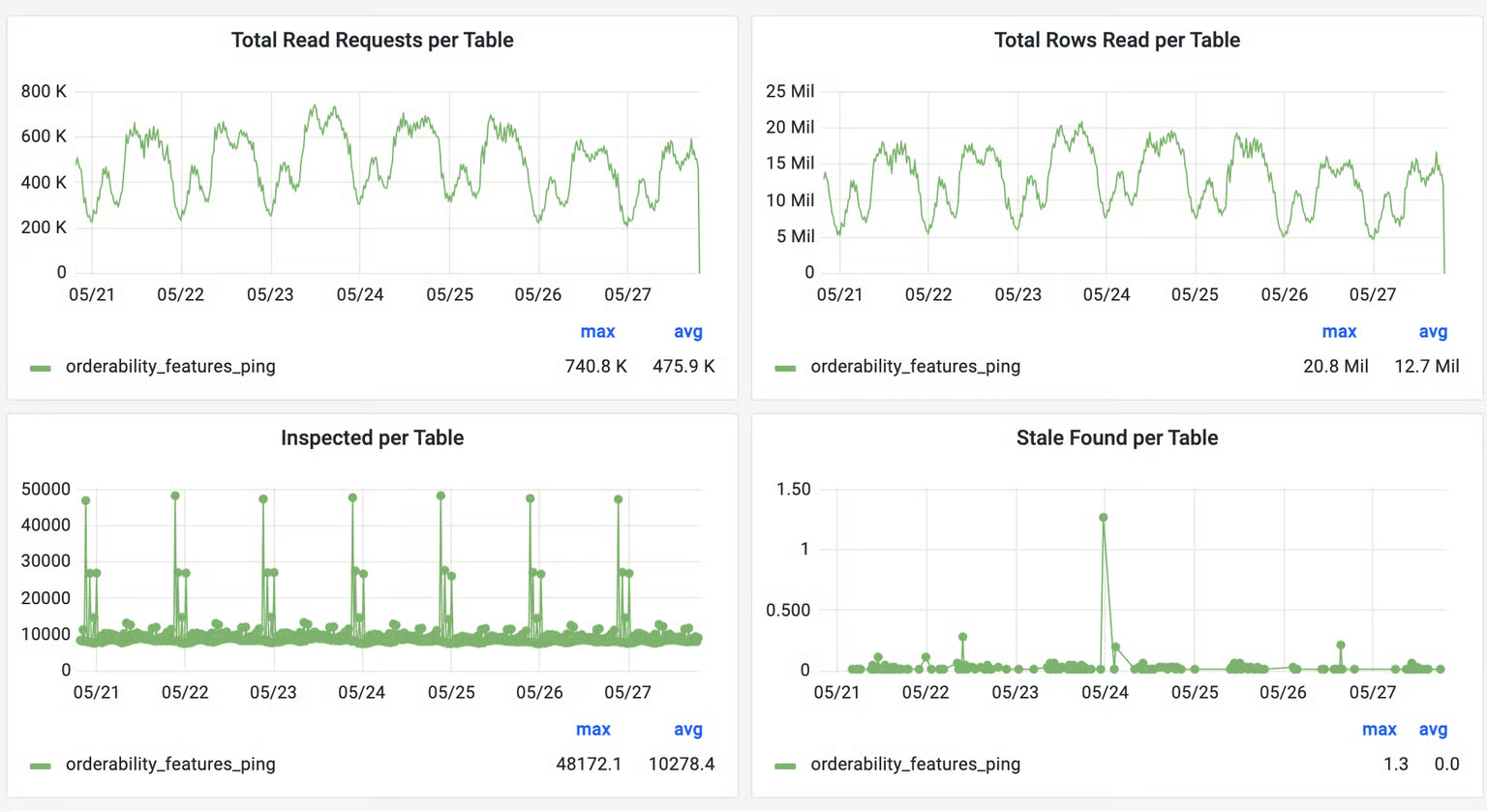
Beyond core invalidation improvements, Uber implemented numerous optimizations such as adaptive timeouts that adjust based on load, negative caching for non-existent data, pipelined reads to batch requests, circuit breakers for unhealthy nodes, connection rate limiters, and compression to reduce memory and bandwidth usage.
Conclusion
Today, CacheFront serves over 150 million rows per second during peak hours. Cache hit rates exceed 99.9% for many use cases. The system has scaled by nearly 4 times since the original implementation, while actually improving consistency guarantees.
By solving the cache invalidation problem with synchronous invalidation from the write path, combined with asynchronous CDC and TTL-based expiration, Uber achieved strong consistency with high performance at massive scale.
References:
🚀 Learn AI in the New Year: Become an AI Engineer Cohort 3 Now Open
After the amazing success of Cohorts 1 and 2 (with close to 1,000 engineers joining and building real AI skills), we are excited to announce the launch of Cohort 3 of Become an AI Engineer!

regarding:
> For the next hour, assuming a one-hour TTL, every read request will return the one-year-old cached data
In the previous statement you mentioned:
> Most engineers assume that if you set a TTL of 5 minutes, stale data will exist for at most 5 minutes. This assumption is incorrect.
so how does it changed from 5mins to 1hour?