
How Uber Uses Integrated Redis Cache to Serve 40M Reads/Second?

80% automated E2E test coverage in 4 months (Sponsored)

Were you aware that despite allocating 25%+ of budgets to QA, 2/3rds of companies still have less than 50% end-to-end test coverage? This means over half of every app is exposed to quality issues.
QA Wolf solves this coverage problem by being the first QA solution to get web apps to 80% automated E2E test coverage in weeks instead of years.
How's QA Wolf different?
We don't charge hourly.
We guarantee results.
We provide all of the tooling and (parallel run) infrastructure needed to run a 15-minute QA cycle.
In 2020, Uber launched their in-house, distributed database named Docstore.
It was built on top of MySQL and was capable of storing tens of petabytes of data while serving tens of millions of requests per second.
Over the years, Docstore was adopted by all business verticals at Uber for building their services. Most of these applications required low latency, higher performance, and scalability from the database, while also supporting higher workloads.
Challenges with Low Latency Database Reads
Every database faces a challenge when dealing with applications that need low-latency read access with a highly scalable design.
Some of these challenges are as follows:
Data retrieval speed from a disk has a threshold. Beyond that, you cannot squeeze out more performance by optimizing an application’s data model and queries to improve latency.
Vertical scaling can take you far but assigning more resources by upgrading to better hosts has limitations. Ultimately, the database engine turns into a bottleneck.
Horizontal scaling by splitting your database into multiple partitions is a promising approach. However, it also gets operationally more complex over time and doesn’t eliminate issues such as hot partitions.
Both vertical and horizontal scaling strategies are costly in the long term. For reference, costs get multiplied 6X to handle three stateful nodes across two regions.
To overcome these challenges, microservices typically make use of caching.
Uber started offering Redis as a distributed caching solution for the various teams. They followed the typical caching design pattern where the service writes to the database and cache while serving reads directly from the cache.
The below diagram shows this pattern:
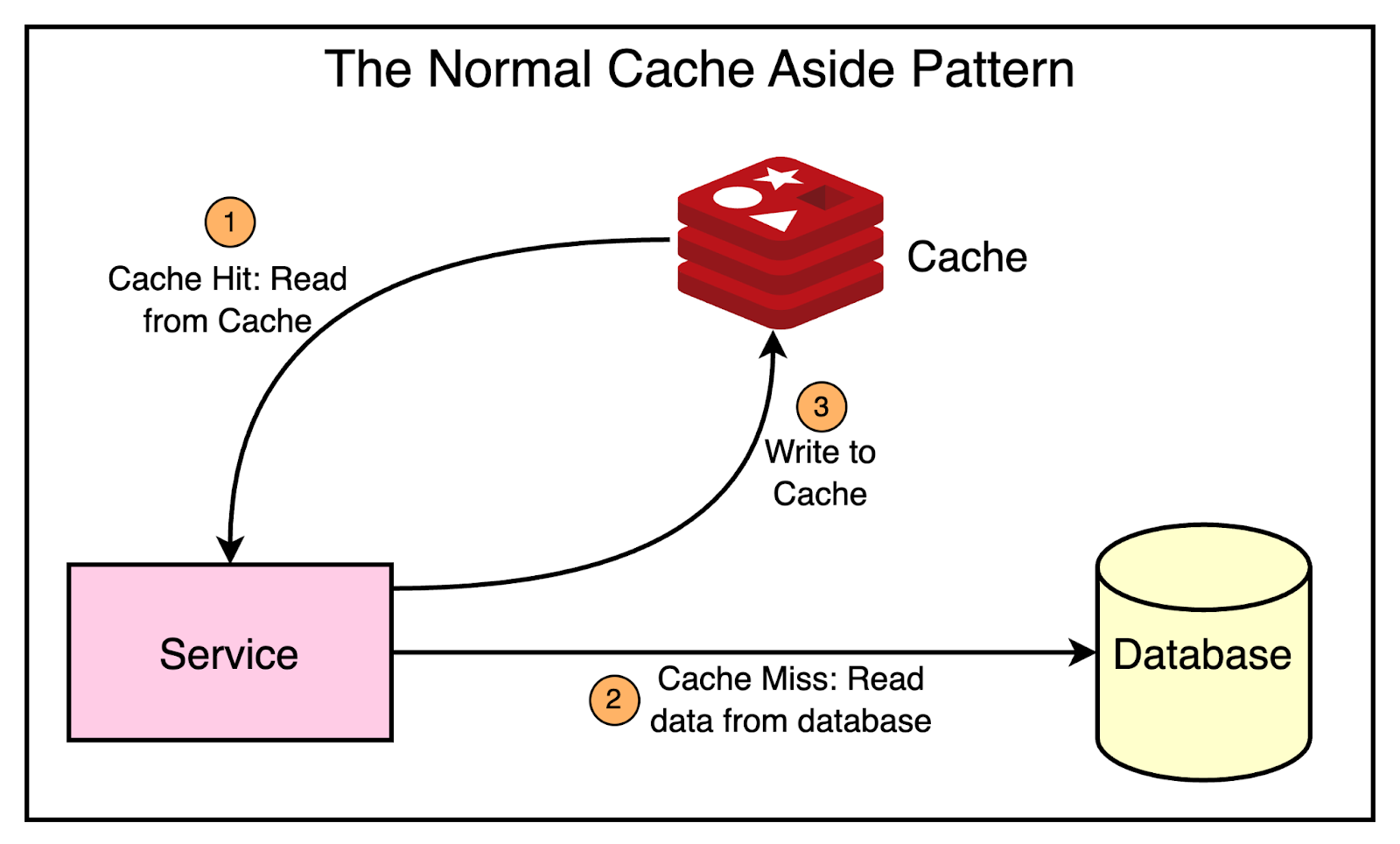
However, the normal caching pattern where a service takes care of managing the cache has a few problems at the scale of Uber.
Each team has to manage its own Redis cache cluster.
The cache invalidation logic is duplicated across multiple microservices and there are chances of deviation.
Services must maintain cache replication to stay hot in case of region failovers.
The main point is that every team that needed caching had to spend a large amount of effort to build and maintain a custom caching solution.
To avoid this, Uber decided to build an integrated caching solution known as CacheFront.
Latest articles
If you’re not a paid subscriber, here’s what you missed this month.

To receive all the full articles and support ByteByteGo, consider subscribing:
Design Goals with CacheFront
While building CacheFront, Uber had a few important design goals in mind:
Reduce the need for vertical or horizontal scaling to support low-latency read requests
Improve the P50 and P99 latencies and stabilize latency spikes
Bring down the resource allocation for the database engine layer
Replace the plethora of custom-built caching solutions created by individual teams for their needs. Instead, move the ownership for maintaining and supporting Redis to the Docstore team.
Make caching transparent from the point of view of the service, allowing teams to just focus on the business logic
Decouple the caching solution from Docstore’s partitioning schema to avoid hot partitions
Support horizontal scalability of the caching layer with cheap host machines and make the entire operation cost-effective
High-Level Architecture with CacheFront
To support these design goals, Uber created its integrated caching solution tied to Docstore.
The below diagram shows the high-level architecture of Docstore along with CacheFront:

As you can see, Docstore’s query engine acts as the entry point for services and is responsible for serving reads and writes to clients.
Therefore, it was the ideal place to integrate the caching layer, allowing the cache to be decoupled from the disk-based storage. The query engine implemented an interface to Redis to store cached data along with mechanisms to invalidate the cache entries.
Handing Cached Reads
CacheFront uses a cache aside or look aside strategy when it comes to reads.
The below steps explain how it works:
The query engine layer receives a read request for one or more rows
The query engine tries to get the rows from Redis and streams the response to the users
Next, it retrieves the remaining rows from the database (if needed)
The query engine asynchronously populates Redis with the rows that are not found in the cache.
Stream the remaining rows to the users.
Refer to the below diagram that explains the process more clearly:

Cache Invalidation with CDC
As you may have heard a million times by now, cache invalidation is one of the two hard things in Computer Science.
One of the simplest cache invalidation strategies is configuring a TTL (Time-to-Live) and letting the cache entries expire once they cross the TTL. While this can work for many cases, most users expect changes to be reflected faster than the TTL. However, lowering the default TTL to a very small value can sink the cache hit rate and reduce its effectiveness.
To make cache invalidation more relevant, Uber leveraged Flux, Docstore’s change data capture and streaming service. Flux works by tailing the MySQL binlog events for each database cluster and publishes the events to a list of consumers. It powers replication, materialized views, data lake ingestions, and data consistency validations among various nodes.
For cache invalidation, a new consumer was created that subscribes to the data events and invalidates/upserts the new rows in Redis.
The below diagram shows the read and write paths with cache invalidation.

There were some key advantages of this approach:
They could make the cache consistent with the database within seconds of the database change as opposed to minutes (depending on the TTL).
Also, using binlogs made sure that uncommitted transactions couldn’t pollute the cache.
However, there were also a couple of issues that had to be ironed out.
1 - Deduplicating Cache Writes
Since writes happen to the cache simultaneously between the read and write paths, it was possible to write a stale row to the cache by overwriting the newest value.
To prevent this, they deduplicated writes based on the timestamp of the row set in MySQL.
This timestamp served as a version number and was parsed from the encoded row value in Redis using the EVAL command.
2 - Stronger Consistency Requirement
Even though cache invalidation using CDC with Flux was faster than relying on TTL, it still provided eventual consistency.
However, some use cases required stronger consistency guarantees such as the reading-own-writes guarantee.
For such cases, they created a dedicated API to the query engine that allowed users to explicitly invalidate the cached rows right after the corresponding writes were completed. By doing so, they didn’t have to wait for the CDC process to complete for the cache to become consistent.
Scale and Resiliency with CacheFront
The basic requirement of CacheFront was ready once they started supporting reads and cache invalidation.
However, Uber also wanted this solution to work at their scale. They also had critical resiliency needs around the entire platform.
To achieve scale and resiliency with CacheFront, they utilized multiple strategies.
Compare cache
Measurements are the key to proving that a system works as expected. The same was the case with CacheFront.
They added a special mode to CacheFront that shadows read requests to cache, allowing them to run a comparison between the data in the cache and the database to verify that both were in sync. Any mismatches such as stale rows are logged as metrics for further analysis.
The below diagram shows a high-level design of the Compare cache system.
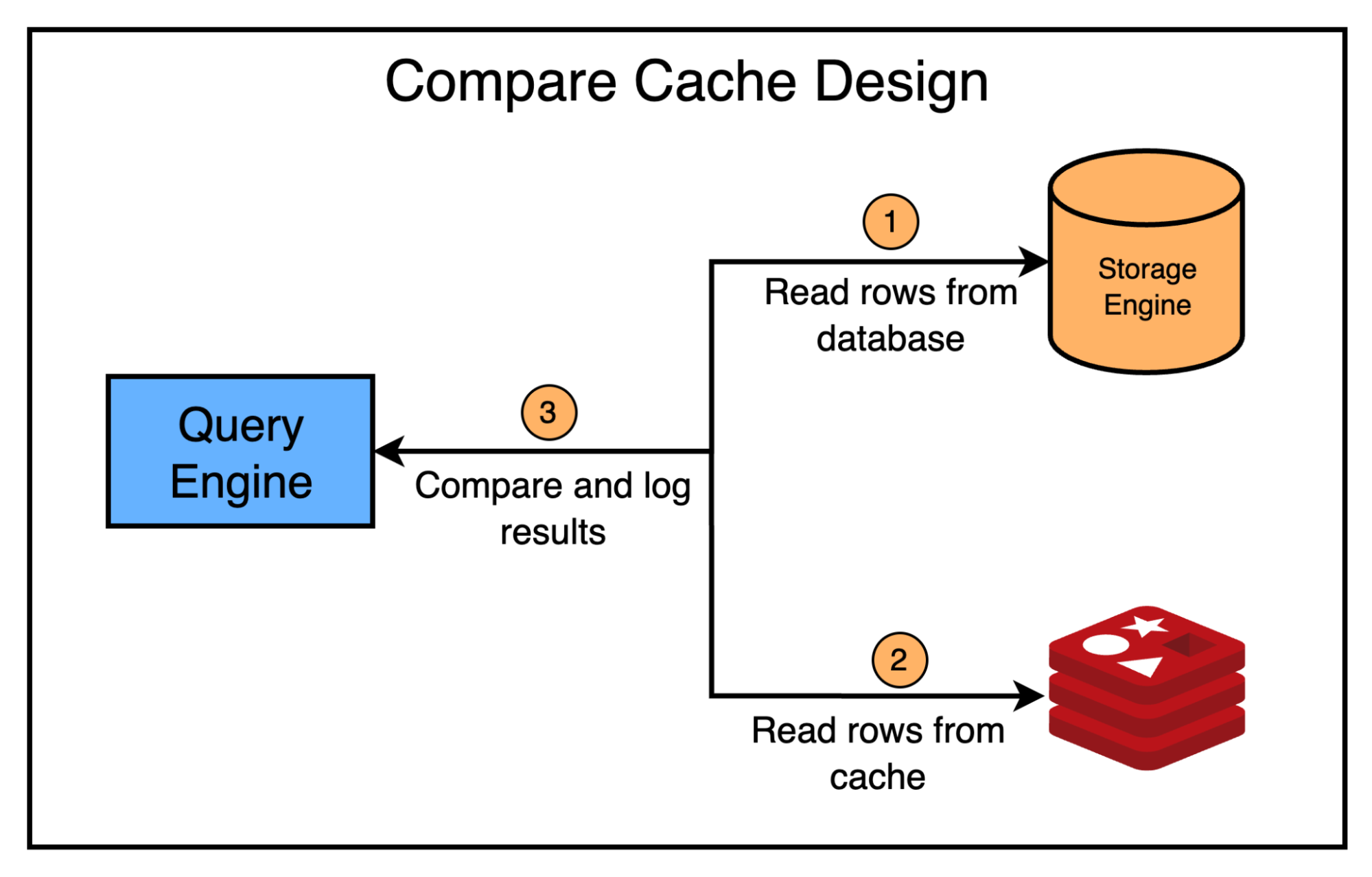
Based on the results from this system, Uber found that the cache was 99.99% consistent.
Cache Warming
In a multi-region environment, a cache is only effective if it is always warm. If that’s not the case, a region fail-over can result in cache misses and drastically increase the number of requests to the database.
Since a Docstore instance spawned in two different geographical regions with an active-active deployment, a cold cache meant that you couldn’t scale down the storage engine to save costs since there was a high chance of heavy database load in the case of failover.
To solve this problem, the Uber engineering team used cross-region Redis replication.
However, Docstore also had its own cross-region replication. Since operating both replication setups simultaneously could result in consistent data between the cache and database, they enhanced the Redis cross-region replication by adding a new cache warming mode.
Here’s how the cache warming mode works:
They tail the Redis write stream to replicate keys to the remote region
In the remote region, they don’t directly update the cache. Instead, they issue read requests to the query engine layer for the replicated keys
In the case of a cache miss, the query engine layer reads the data from the database and writes it to the cache. The response stream is discarded.
The below diagram shows this approach in detail:
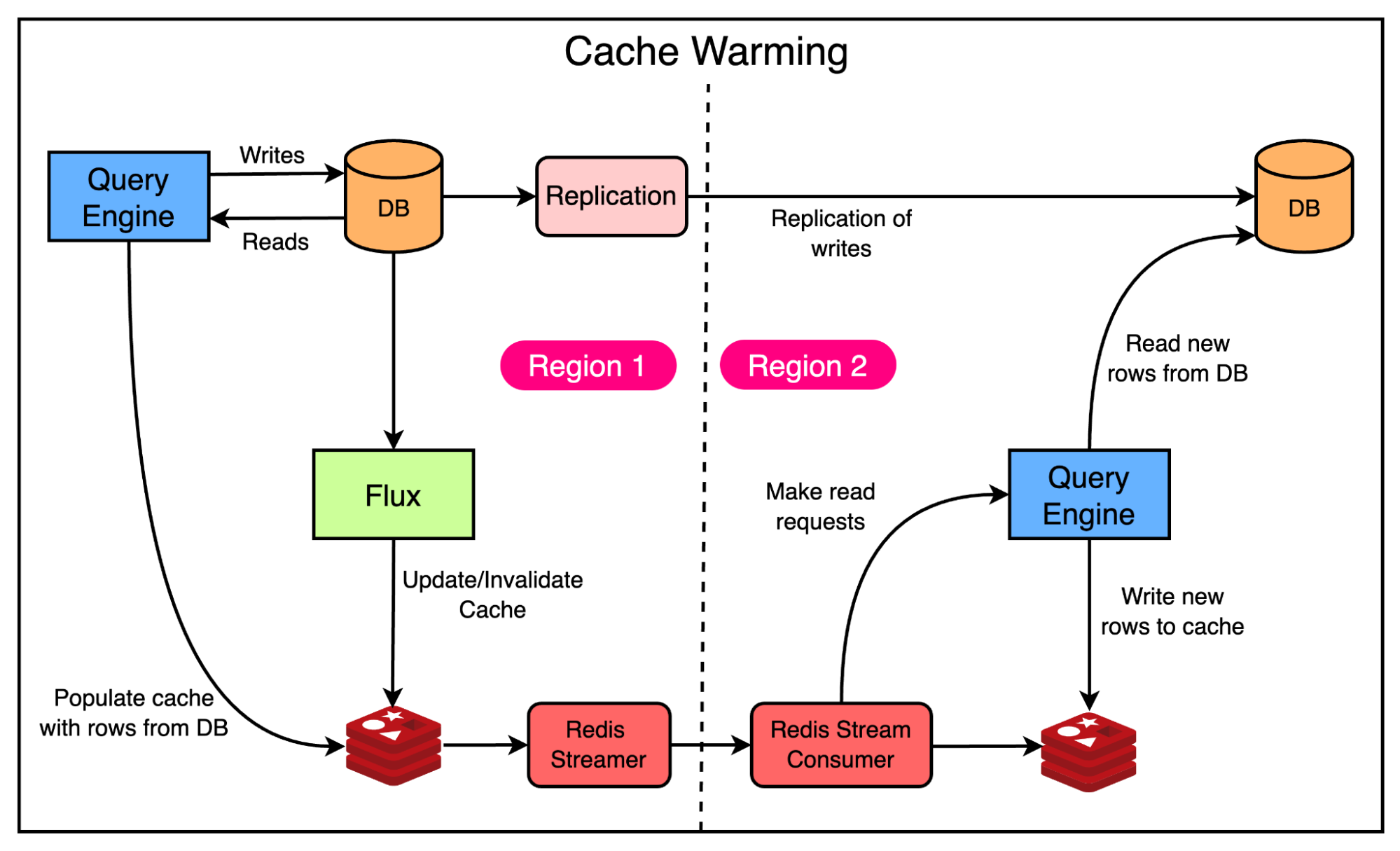
Replicating keys instead of values makes sure that the data in the cache is consistent with the database in its respective region. Also, it ensures that the same set of cached rows is present in both regions, thereby keeping the cache warm in case of a failover.
Sharding
Some large customers of Docstore within Uber can generate a very large number of read-write requests. It was challenging to cache all of it within a single Redis cluster that’s limited by the maximum number of nodes.
To mitigate this, they allowed a single Docstore instance to map to multiple Redis clusters. This helped avoid a massive surge of requests to the database in case multiple nodes in a single Redis cluster go down.
However, there was still a case where a single Redis cluster going down may create a hot shard on the database. To prevent this, they sharded the Redis cluster using a scheme that was different from the database sharding scheme. This makes sure that the load from a single Redis cluster going down is distributed between multiple database shards.
The below diagram explains this scenario in more detail.
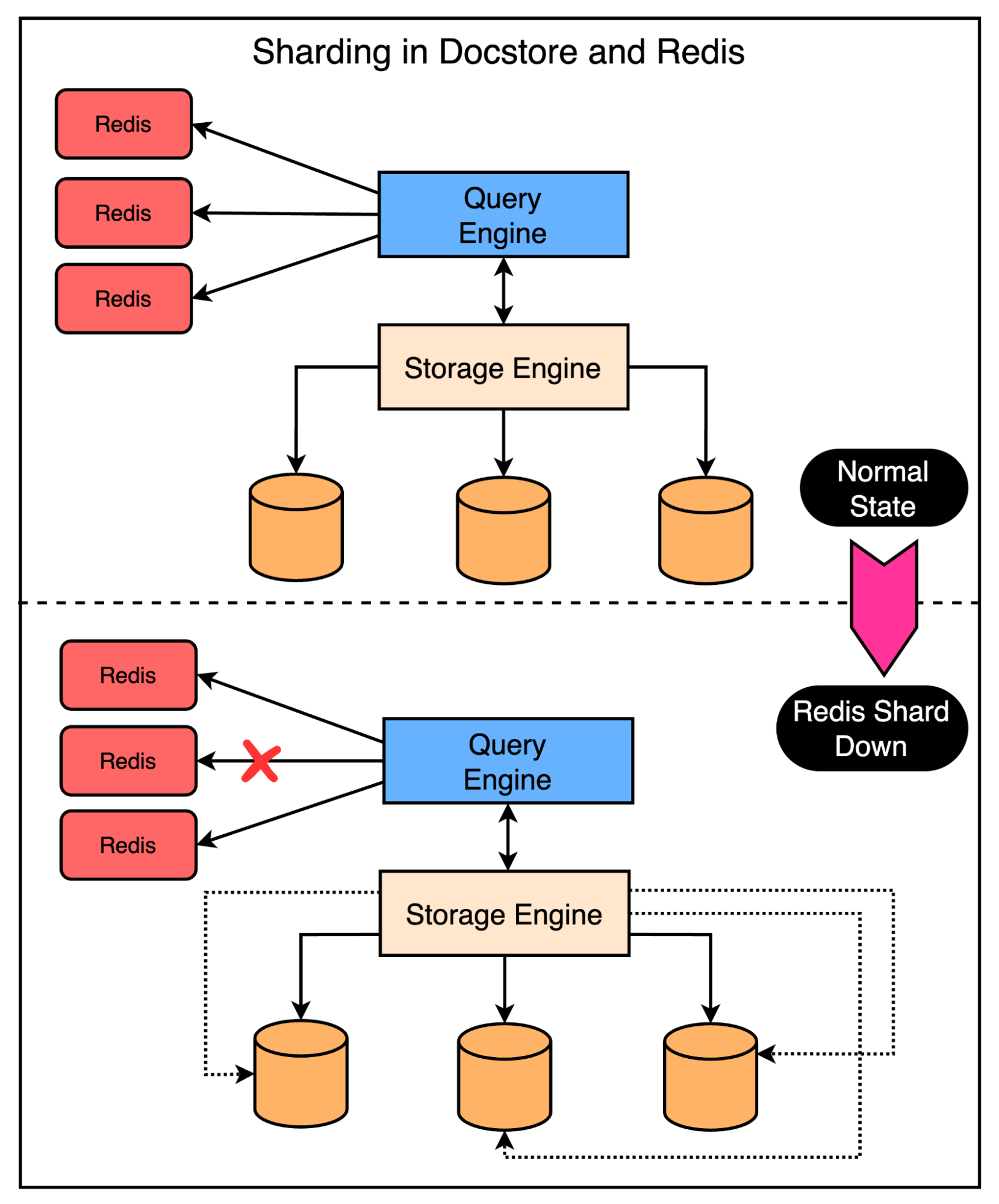
Circuit Breaker
When a Redis node goes down, a get/set request to that node generates an unnecessary latency penalty.
To avoid this penalty, Uber implemented a sliding window circuit breaker to short-circuit such requests. They count the number of errors on each node for a particular bucket of time and compute the number of errors within the sliding window’s width.
See the below diagram to understand the sliding window approach:

The circuit breaker is configured to short-circuit a fraction of the requests to a node based on the error count. Once the threshold is hit, the circuit breaker is tripped and no more requests can be made to the node until the sliding window passes.
Results and Conclusion
Uber’s project of implementing an integrated Redis cache with Docstore was quite successful.
They created a transparent caching solution that was scalable and managed to improve latency, reduce load, and bring down costs.
Here are some stats that show the results:
The P75 latency went down by 75% and the P99.9 latency went down by over 67% while also limiting latency spikes
Cache invalidation using flux and compare cache provided a cache consistency of 99.9%.
Sharding and cache warming made the setup scalable and fault-tolerant, allowing a use case with over 6M reads per second with a 99% cache hit rate to successfully failover to a remote region.
Costs were down significantly as the same use case of 6M reads per second approximately required 60K CPU cores for the storage engine. With CacheFront, they achieved the same results with just 3K Redis cores.
At present, CacheFront supports over 40M requests per second in production and the number is growing every day.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.