
How WhatsApp Handles 40 Billion Messages Per Day

Build to Prod: Secure, Scalable MCP Servers with Docker (Sponsored)

The AI agent era is here, but running tools in production with MCP is still a mess—runtime headaches, insecure secrets, and a discoverability black hole. Docker fixes that. Learn how to simplify, secure, and scale your MCP servers using Docker containers, Docker Desktop, and the included MCP gateway. From trusted discovery to sandboxed execution and secrets management, Docker gives you the foundation to run agentic tools at scale—with confidence.
Disclaimer: The details in this post have been derived from the articles written by the WhatsApp engineering team. All credit for the technical details goes to the WhatsApp Engineering Team. The links to the original articles and videos are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Messaging platforms don’t get second chances. Missed messages, delayed photos, or dropped calls break trust instantly. And the bigger the user base, the harder it gets to recover from even brief failures.
Some systems thrive under that pressure.
WhatsApp is one of them. It moves nearly 40 billion messages daily, keeps hundreds of millions of users connected, and does it all with a small engineering team. At one point, just over 50 engineers supported the entire backend. Fewer than a dozen focused on the core infrastructure.
This scale is a result of multiple engineering choices that favored simplicity over cleverness, clarity over abstraction, and resilience over perfection. System failures weren’t unexpected, but inevitable. Therefore, the system was designed to keep going when things went sideways.
Erlang played a central role. Built for telecoms, it offered lightweight concurrency, fault isolation, and distributed messaging from the ground up. However, the real advantage came from what was layered on top: smart partitioning, async replication, tightly scoped failover, and tooling.
In this article, we’ll take a technical dive into how WhatsApp built its architecture and the challenges the engineering team faced during this journey.
System Design Principles
At the heart of WhatsApp’s architecture is a surprisingly basic principle: make it simple enough to reason about under stress. When systems operate at a global scale, complexity isn’t a big threat to reliability.
Some guiding principles followed by the WhatsApp engineering team were as follows:
Clarity Over Cleverness: The architecture favors small, focused components. Each service handles one job, minimizing dependencies and limiting the blast radius when things fail.
Async by Default: WhatsApp relies on async messaging throughout. Processes hand off work and move on, keeping the system responsive even when parts of it slow down. This design absorbs load spikes and prevents small glitches from snowballing.
Isolation: Each backend is partitioned into “islands” that can fail independently. Replication flows one way so that if a node drops, its peer takes over.
Seamless Upgrades: Code changes roll out without restarting services or disconnecting users. Discipline around state and interfaces makes this possible.
Quality Through Focus: In the early days, every line of backend code was reviewed by the founding team. That kept the system lean, fast, and deeply understood.
WhatsApp Server Architecture
Delivering a message sounds simple, until millions of phones start talking at once. At WhatsApp's scale, even small inefficiencies compound quickly.
The diagram below shows the high-level WhatsApp architecture:
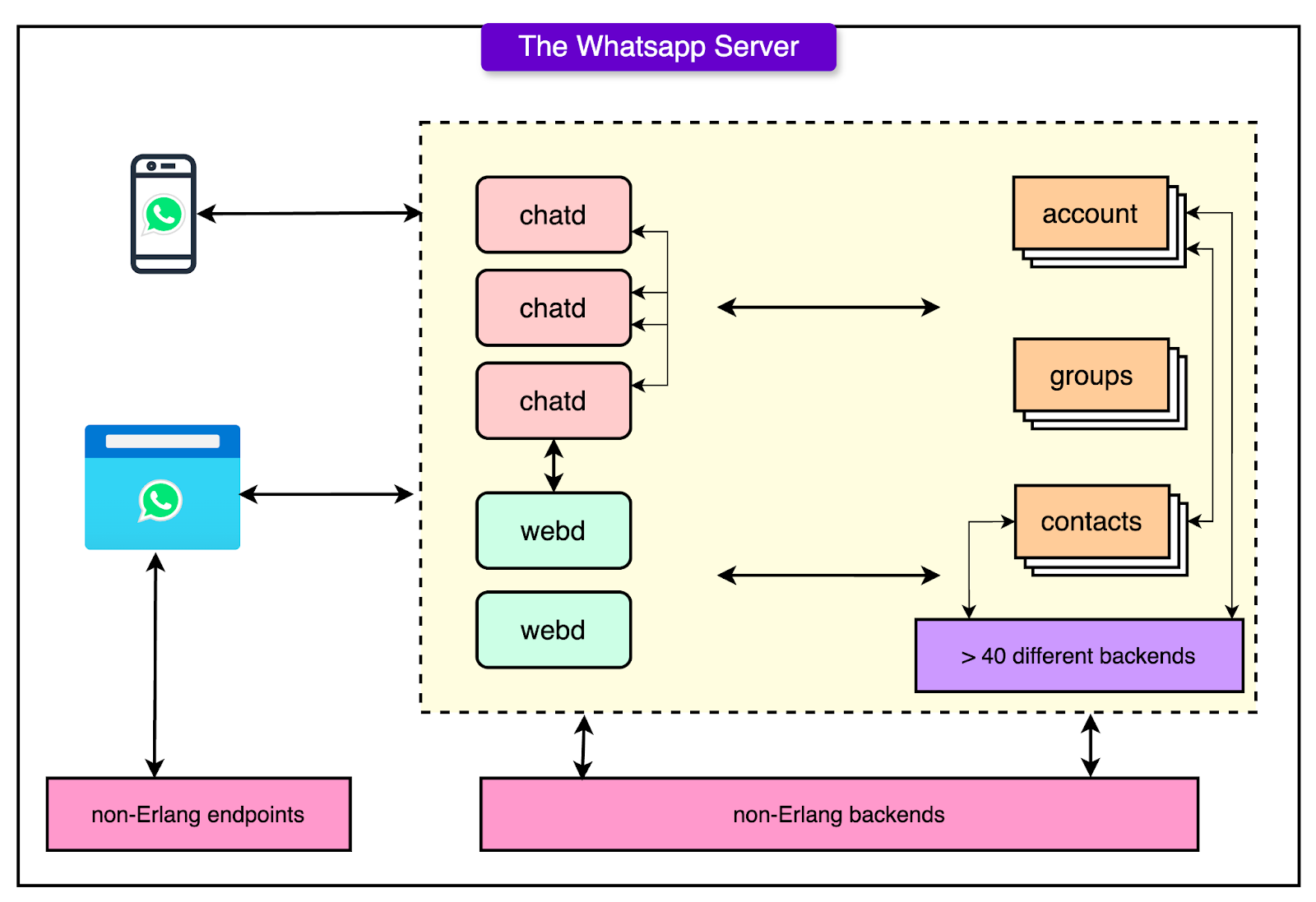
The architecture focuses on three goals: speed, reliability, and resource isolation. Some key aspects of the architecture are as follows:
A Connection is a Process
When a phone connects to WhatsApp, it establishes a persistent TCP connection to one of the frontend servers. That connection is managed as a live Erlang process that maintains the session state, manages the TCP socket, and exits cleanly when the user goes offline.
There is no connection pooling and no multiplexing, but just one process per connection. This design maps naturally onto Erlang's strengths and makes lifecycle management straightforward. If something goes wrong, like a dropped network packet or app crash, the process dies, and with it, all associated memory and state.
Stateful and Smart on the Edge
The session process isn’t a dumb pipe. It actively coordinates with backends to pull user-specific data:
Authentication: Verifies the client identity and session validity.
Blocking and Permissions: Checks whether the user is allowed to send messages or has been restricted.
Pending Messages and Notifications: Queries message queues and notification subsystems.
This orchestration happens quickly and in parallel. By keeping session logic close to the edge, the system avoids round-trip and minimizes latency for first-message delivery.
Scaling Frontend Connections
At peak, a single chat server can manage upwards of a million concurrent connections. Erlang handles this effortlessly, thanks to its process model and non-blocking IO. Each session lives independently, so one slow client doesn’t affect others.
To maintain performance at that scale, frontend servers avoid unnecessary work by adopting some strategies:
Typing indicators and presence updates (for example, “online,” “last seen”) are batched and rate-limited.
Message acknowledgments use lightweight protocol messages, not full API calls.
Idle sessions are monitored and culled when inactive for too long.
This keeps frontend load proportional to active engagement, not just raw connection count.
Efficient Message Flow
When two users are online and start chatting, their session processes coordinate through backend chat nodes. These nodes are tightly interconnected and handle routing at the protocol level, not the application level. Messages move peer-to-peer within the backend mesh, minimizing hops.
Presence, typing states, and metadata updates add volume. For every message, multiple related updates might flow:
Delivery receipts
Typing notifications
Group membership changes
Profile picture updates
Each of these messages travel through the same architecture, but with reduced delivery guarantees. Not every typing status needs to arrive.
The Role of Erlang
Erlang plays a key role in the efficiency of WhatsApp’s backend.
Most backend stacks buckle when faced with millions of users doing unpredictable things at once. However, Erlang’s runtime is designed from the ground up to handle massive concurrency, soft failure, and fast recovery.
Here are some core features of Erlang:
In Erlang, every connection, every user session, and every internal task runs as a lightweight process. They’re managed by the BEAM virtual machine, which can spin up hundreds of thousands (sometimes millions) of them on a single node without choking.
Each process runs in isolation with its memory and mailbox. It can crash without taking down the system.
Erlang plays exceptionally well with large, multi-core boxes. As core counts increase, the BEAM scheduler spreads processes across them with minimal coordination overhead. This is SP scalability (Single Process or Single Point scaling), where node count stays constant while internal capacity grows.
Erlang’s “let it crash” philosophy is a pragmatic response to the unpredictability of distributed systems. Supervisors monitor child processes, restarting them if they fail. Failures stay local. There’s no chain reaction of exceptions or retries.
Erlang has a Gen Factory that dispatches work across multiple processes. Each mini-factory can handle its own stream of input, reducing contention and spreading load more evenly. This model keeps WhatsApp’s backend humming even under spikes in traffic.
Backend Systems and Isolation
Backend systems tend to become monoliths unless there’s a strong reason to split them up.
WhatsApp had one: survival at scale. When millions of users are relying on real-time messaging, even a minor backend hiccup can ripple through the system.
Here are a few strategies they adopted:
Divide by Function, Not Just Load
The backend is split into over 40 distinct clusters, each handling a narrow slice of the product. Some handle message queues. Others deal with authentication, contact syncing, or presence tracking. Multimedia, push notifications, and spam filtering each get their own space.
This kind of logical decoupling does a few things well:
Limits failure scope: If the spam filter crashes, message delivery doesn’t.
Speeds up iteration: Teams can deploy changes to one backend without risk to others.
Optimizes hardware: Some services are memory-bound, others are CPU-heavy. Isolation lets each run on the hardware it needs.
Decoupling isn’t free. It adds coordination overhead. However, at WhatsApp’s scale, the benefits outweigh the costs.
Redundancy Through Erlang Clustering
Erlang’s distributed model plays a key role in backend resilience. Nodes within a cluster run in a fully meshed topology and use native distribution mechanisms to communicate. If one node drops, others pick up the slack.
State is often replicated or reconstructible. Clients can reconnect to a new node and resume where they left off. Supervisors and health checks ensure that failed processes restart quickly, and clusters self-heal in the face of routine hardware faults.
There’s no single master node, no orchestrator dependency, and minimal need for human intervention.
“Islands” of Stability
To go further, the system groups backend nodes into what are called “islands.” Each island acts as a small, redundant cluster responsible for a subset of data, like a partition in a distributed database.

Here’s how the island approach works:
Each island typically has two or more nodes.
Data partitions are assigned deterministically to one node as primary and another as secondary.
If the primary goes down, the secondary takes over instantly.
Islands replicate data within themselves but remain isolated from other islands.
This setup adds a layer of fault tolerance without requiring full replication across the entire system. Most failures affect only one island, and recovery is scoped tightly.
Database Design and Optimization
When messages need to move at sub-second latency across continents, traditional database thinking doesn't apply. There’s no room for complex joins, heavyweight transactions, or anything that introduces blocking. WhatsApp's architecture leans hard into a model built for speed, concurrency, and volatility.
Here are some core database-related features:
Key-Value Store in RAM
Data access follows a key-value pattern almost universally. Each piece of information, whether it’s a user session, a pending message, or a media pointer, has a predictable key and a compact value.
And whenever possible, data lives in memory.
In-memory structures like Erlang’s ETS (Erlang Term Storage) tables provide fast, concurrent access without external dependencies. These structures are native to the VM and don’t require network hops or disk seeks. Read and write throughput remains consistent under pressure because memory latency doesn’t spike with load.
Databases Embedded in the VM
Instead of reaching out to external storage layers, most database logic is embedded directly within the Erlang runtime. This tight integration reduces the number of moving parts and avoids the latency that creeps in with networked DB calls.

Some backend clusters maintain their internal data stores, implemented using a mix of ETS tables and write-through caching layers. These stores are designed for short-lived data, like presence updates or message queues, that don’t require permanent persistence.
For long-lived data like media metadata, records are still kept in memory as long as possible. Only when capacity demands or eviction policies kick in does the data flush to disk.
Lightweight Locking and Fragmentation
Concurrency isn’t just about spawning processes. It’s also about managing locks.
To minimize lock contention, data is partitioned into what are called “DB Frags”: fragments of ETS tables distributed across processes.

Each fragment handles a small, isolated slice of the keyspace. All access to that fragment goes through a single process on a single node. This allows for:
Serialized access per key: No races, no locks.
Horizontal scale-out: More fragments mean more throughput.
Targeted replication: Each fragment is replicated independently to a paired node.
The result is a system where reads and writes rarely block, and scaling up just means adding more fragments and processes.
Async Writes and Parallel Disk I/O
For persistence, writes happen asynchronously and outside the critical path. Most tables operate in an async_dirty mode, meaning they accept updates without requiring confirmation or transactional guarantees. This keeps latency low, even when disks get slow.
Behind the scenes, multiple transaction managers (TMs) push data to disk and replication streams in parallel. If one TM starts to lag, others keep the system moving. IO bottlenecks are absorbed by fragmenting disk writes across directories and devices, maximizing throughput.
Offline Caching: Don’t Write What Will Be Read Soon
When a phone goes offline, its undelivered messages queue up in an offline cache. This cache is smarter than a simple buffer. It uses a write-back model with a variable sync delay. Messages are written to memory first, then flushed to disk only if they linger too long.
During high-load events, like holidays, this cache becomes a critical buffer. It allows the system to keep delivering messages even when the disk can’t keep up. In practice, over 98% of messages are served directly from memory before ever touching persistent storage.
Replication and Partitioning
Replication sounds simple until it isn’t.
At scale, it gets tricky fast. Bidirectional replication introduces locking, contention, and coordination overhead. Cross-node consistency becomes fragile. And when things go wrong, everything grinds to a halt.
WhatsApp follows a different strategy.
Each data fragment is owned by a single node: the primary. That node handles all application-layer reads and writes for its fragment. It pushes updates to a paired secondary node, which passively receives and stores the changes.

The secondary never serves client traffic. It’s there for failover only.
This model avoids one of the nastiest problems in distributed systems: concurrent access to shared state. There are no conflicting writes, no race conditions, and no need for transactional locks across nodes. If the primary fails, the secondary is promoted, and replication flips.
Also, instead of running one massive table per service, WhatsApp breaks data into hundreds and sometimes thousands of fragments. Each fragment is a small, isolated slice of the total dataset, typically hashed by a user ID or session key.
These fragments are:
Bound to a single node for writes.
Replicated to one other node.
Mapped to processes through consistent hashing.
This sharding scheme reduces contention, improves locality, and allows the system to scale horizontally without reshuffling state.
Each group of nodes managing a set of fragments is called an island. An island typically consists of two nodes: a primary and a secondary. The key is that each fragment belongs to only one island, and each island operates independently.
Scaling Challenges
WhatsApp's backend scaled not just because of clever design, but because teams learned where things cracked under pressure and fixed them before they exploded.
Some of the scaling challenges the WhatsApp team faced are as follows:
When Hashes Collided
Erlang’s ETS tables rely on hash-based indexing for fast access. In theory, that works fine. In practice, a collision in the hash function can degrade performance.
A subtle bug emerged when two layers of the system used the same hash function with different goals. The result was thousands of entries ending up in the same buckets, while others stayed empty.
The fix was change the seed of the hash function: a two-line patch that instantly improved throughput by 4x in that subsystem.
Selective Receive
Erlang's selective receive feature lets processes pull specific messages from their mailbox. This was handy for control flow, but dangerous under load.
In high-throughput situations, like loading millions of records into memory, selective receive turned into a bottleneck. Processes got stuck scanning for the right message.
Engineers worked around this by draining queues into temp storage, splitting logic across worker processes, and avoiding selective receive in performance-critical paths.
Cascading Failures Aren’t Always Load-Related
One of the most severe outages didn’t start with a CPU spike or traffic surge. It started with a router. A backend router silently dropped a VLAN, causing a massive disconnect-reconnect storm across the cluster.
What followed was a perfect storm: overloaded message queues, stuck nodes, unstable cluster state. At one point, internal queues grew from zero to four million messages in seconds. Even robust processes like PG2, normally fault-tolerant, began behaving erratically, queueing messages that couldn’t be delivered.
The only solution was a hard reset. The system had to be shut down, rebooted node by node, and carefully stitched back together.
Conclusion
WhatsApp’s backend is elegant in the trenches. It’s built to handle chaos without becoming chaotic, to scale without centralization, and to fail without taking users down with it.
From Erlang’s lightweight processes to carefully fragmented data and one-way replication, every design choice reflects a deep understanding of operational reality at massive scale.
The architecture is pragmatic: meant to withstand sudden spikes, silent regressions, and global outages.
References:
Erlang Factory 2014 - That's 'Billion' with a 'B': Scaling to the Next Level at WhatsApp
A Reflection on Building the WhatsApp Server - Code BEAM 2018
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
Backend engineering is beautiful.
Kudos to the team for the ingenious design 👏
It's worth noting that you can get the benefits of Erlang and the BEAM on the JVM through Akka.