
How Yelp Built “Yelp Assistant”

How to stop bots from abusing free trials (Sponsored)

Free trials help AI apps grow, but bots and fake accounts exploit them. They steal tokens, burn compute, and disrupt real users.
Cursor, the fast-growing AI code assistant, uses WorkOS Radar to detect and stop abuse in real time. With device fingerprinting and behavioral signals, Radar blocks fraud before it reaches your app.
You open an app with one specific question in mind, but the answer is usually hidden in a sea of reviews, photos, and structured facts. Modern content platforms are information-rich, though surfacing direct answers can still be a challenge. A good example is Yelp business pages. Imagine you are deciding where to go and you ask “Is the patio heated?”. The page might contain the answer in a couple of reviews, a photo caption, or an attribute field, but you still have to scan multiple sections to piece it together.
A common way to solve this is to integrate an AI assistant inside the app. The assistant retrieves the right evidence and turns it into a single direct answer with citations to the supporting snippets.
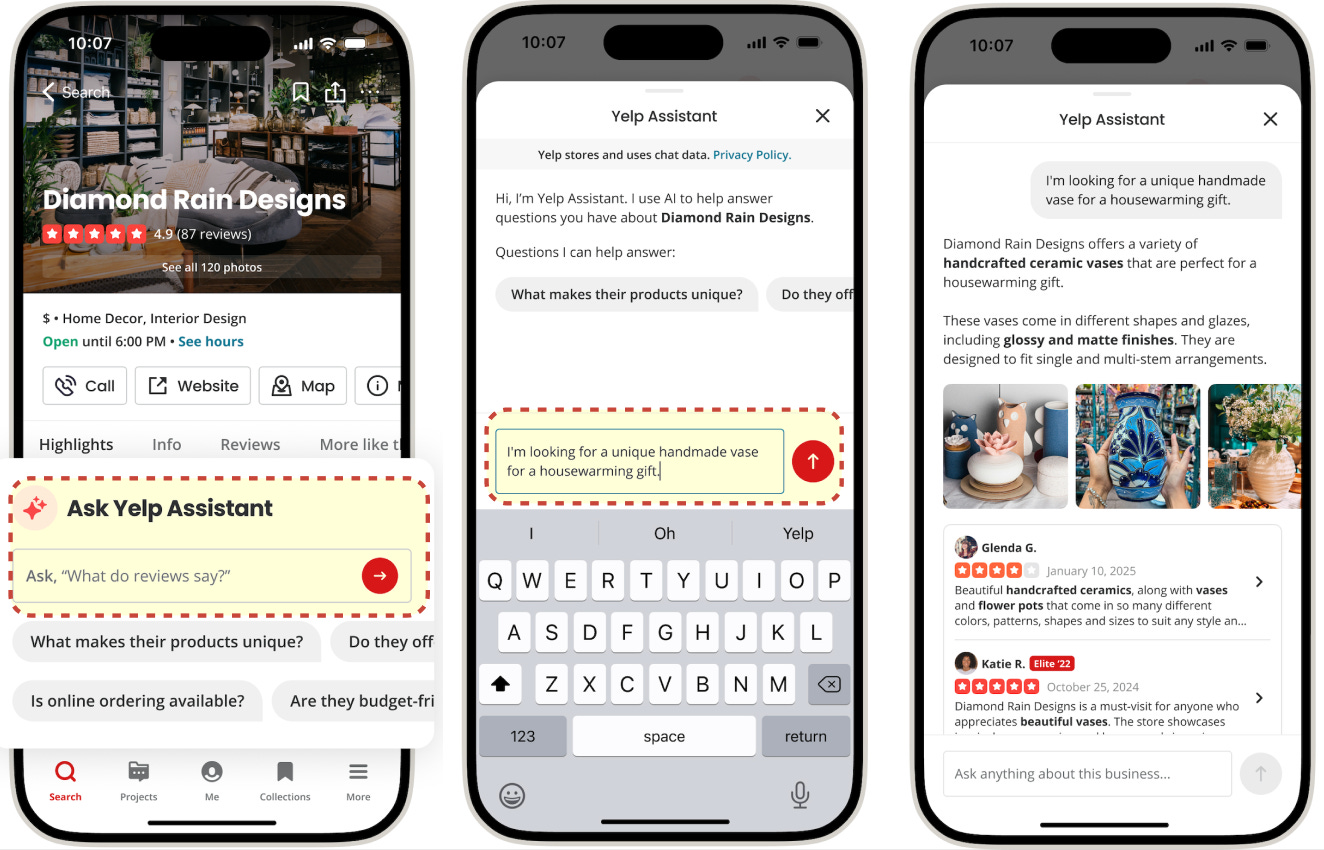
This article walks through what it takes to ship a production-ready AI assistant using Yelp Assistant on business pages as a concrete case study. We’ll cover the engineering challenges, architectural trade-offs, and practical lessons from the development of the Yelp Assistant.
Note: This article is written in collaboration with Yelp. Special thanks to the Yelp team for sharing details with us about their work and for reviewing the final article before publication.
High-Level System Design
To deliver answers that are both accurate and cited, we cannot rely on an LLM’s internal knowledge alone. Instead, we use Retrieval-Augmented Generation (RAG).
RAG decouples the problem into two distinct phases: retrieval and generation, supported by an offline indexing pipeline that prepares the knowledge store.
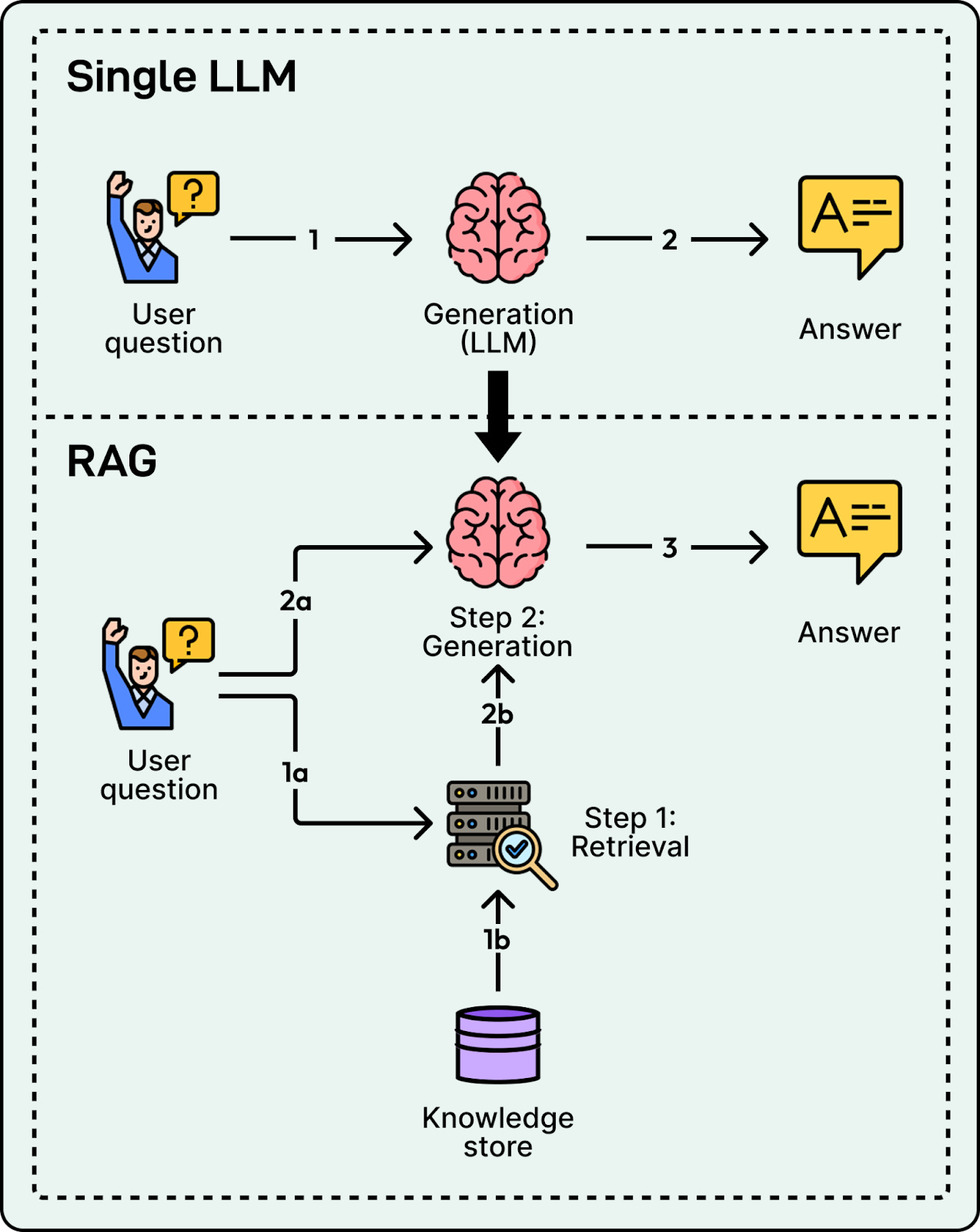
The development of a RAG system starts with an indexing pipeline, which builds a knowledge store from raw data offline. Upon receiving a user query, the retrieval system scans this store using both lexical search for keywords and semantic search for intent to locate the most relevant snippets. Finally, the generation phase feeds these snippets to the LLM with strict instructions to answer solely based on the provided evidence and to cite specific sources.
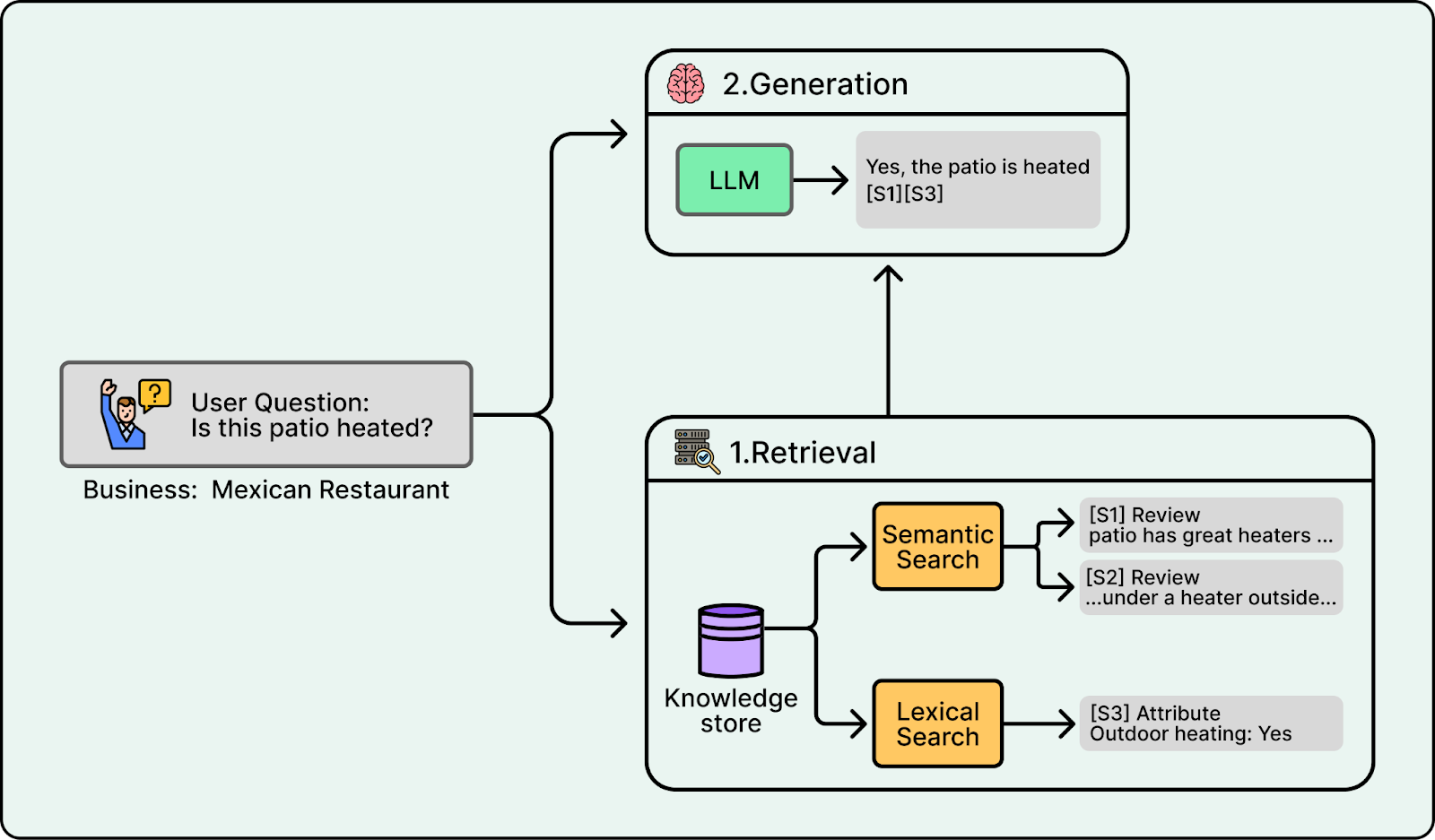
Citations are typically produced by having the model output citation markers that refer to specific snippets. For example, if the prompt includes snippets with IDs S1, S2, and S3, the model might generate “Yes, the patio is heated” and attach markers like [S1] and [S3]. A citation resolution step then maps those markers back to the original sources, such as a specific review excerpt, photo caption, or attribute field, and formats them for the UI. Finally, citations are verified to ensure every emitted citation maps to real retrievable content.

While this system is enough for a prototype, a production system requires additional layers for reliability, safety, and performance. The rest of this article uses the Yelp Assistant as a case study to explore the real-world engineering challenges of building this at scale and the mitigations to solve them.
Live Webinar: Designing for Failure and Speed in Agentic Workflows with FeatureOps (Sponsored)

AI can write code in seconds. You’re the one who gets paged at 2am when production breaks.
As teams adopt agentic workflows, features change faster than humans can review them. When an AI-written change misbehaves, redeploying isn’t fast enough, rollbacks aren’t clean, and you’re left debugging decisions made by your AI overlord.
In this tech talk, we’ll show FeatureOps patterns to stay in control at runtime, stop bad releases instantly, limit blast radius, and separate deployment from exposure.
Led by Alex Casalboni, Developer Advocate at Unleash, who spent six years at AWS seeing the best and worst of running applications at scale.
Data Strategy: From Prototype to Production
A robust data strategy determines what content the assistant can retrieve and how quickly it stays up to date. The standard pipeline consists of three stages beginning with data sourcing where we select necessary inputs like reviews or business hours and define update contracts. Next is ingestion, which cleans and transforms these raw feeds into a trusted canonical format. Finally, indexing transforms these records into retrieval-ready documents using keyword or vector search signals so the system can filter to the right business scope.
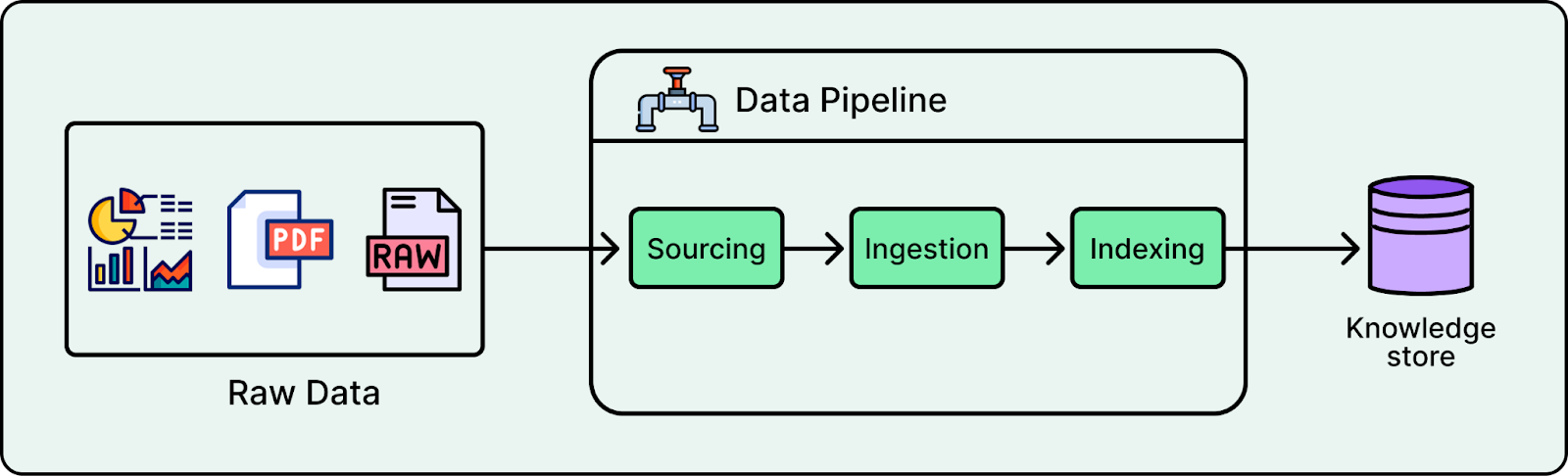
Setting up a data pipeline for a demo is usually simple. For example, Yelp’s early prototype relied on ad hoc batch dumps loaded into a Redis snapshot which effectively treated each business as a static bundle of content.
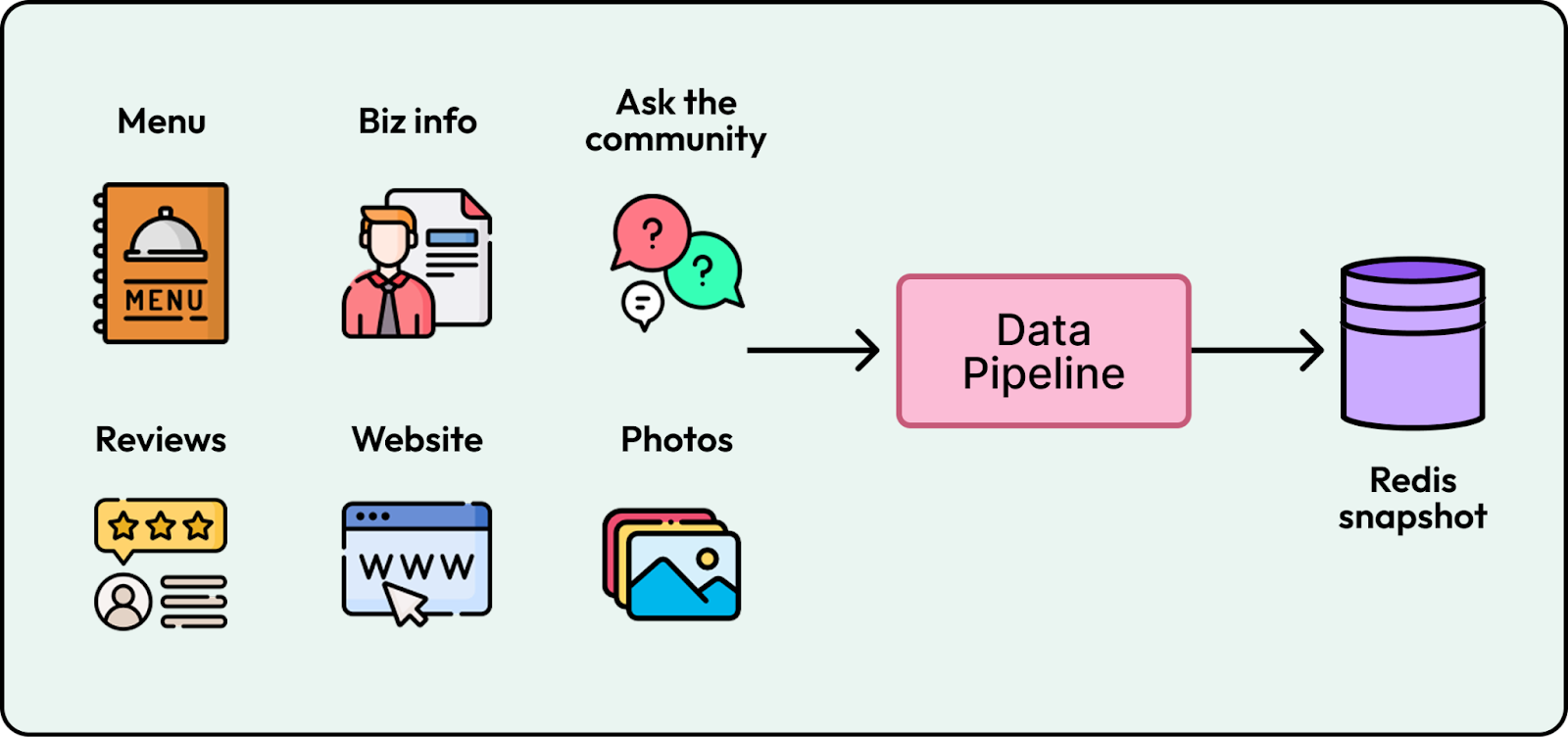
In production, this approach collapses because content changes continuously and the corpus grows without bound. A stale answer regarding operating hours is worse than no answer at all, and a single generic index struggles to find specific needle-in-the-haystack facts as the data volume explodes. To meet the demands of high query volume and near real-time freshness, Yelp evolved their data strategy through four key architectural shifts.
1. Freshness
Treating every data source as real-time makes ingestion expensive to operate while treating everything as a weekly batch results in stale answers. Yelp set explicit freshness targets based on the content type. They implemented streaming ingestion for high-velocity data like reviews and business attributes to ensure updates appear within 10 minutes. Conversely, they used a weekly batch pipeline for slow-moving sources like menus and website text. This hybrid approach ensures a user asking “Is it open?” gets the latest status without wasting resources streaming static content.
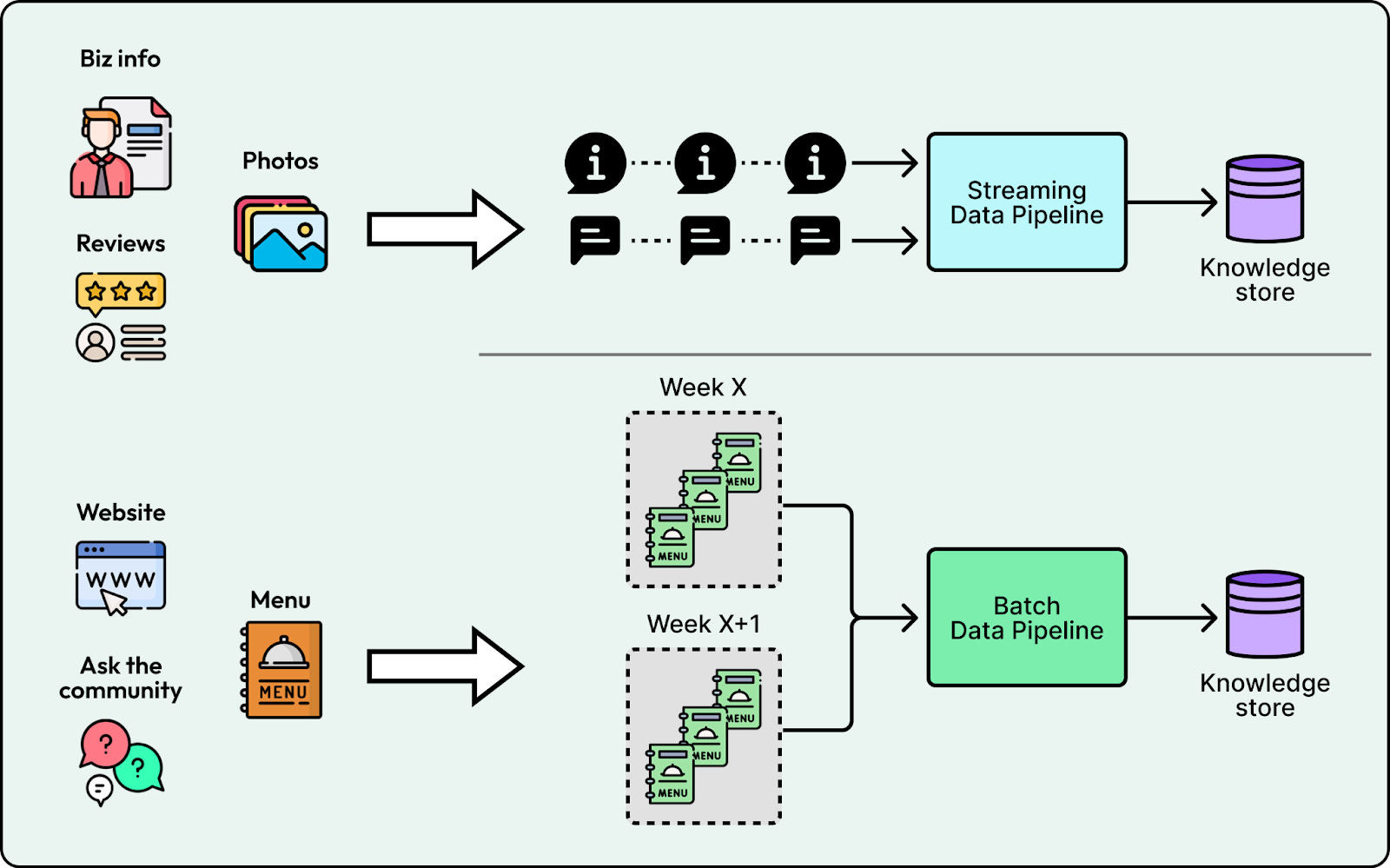
2. Data Separation
Not all questions should be answered the same way. Some require searching through noisy text while others require a single precise fact. Treating everything as generic text makes retrieval unreliable; it allows anecdotes in reviews to override canonical fields like operating hours.
Yelp replaced the single prototype Redis snapshot with two distinct production stores. Unstructured content like reviews and photos serves through search indices to maximize relevance. Structured facts like amenities and hours live in a Cassandra database using an Entity-Attribute-Value layout.
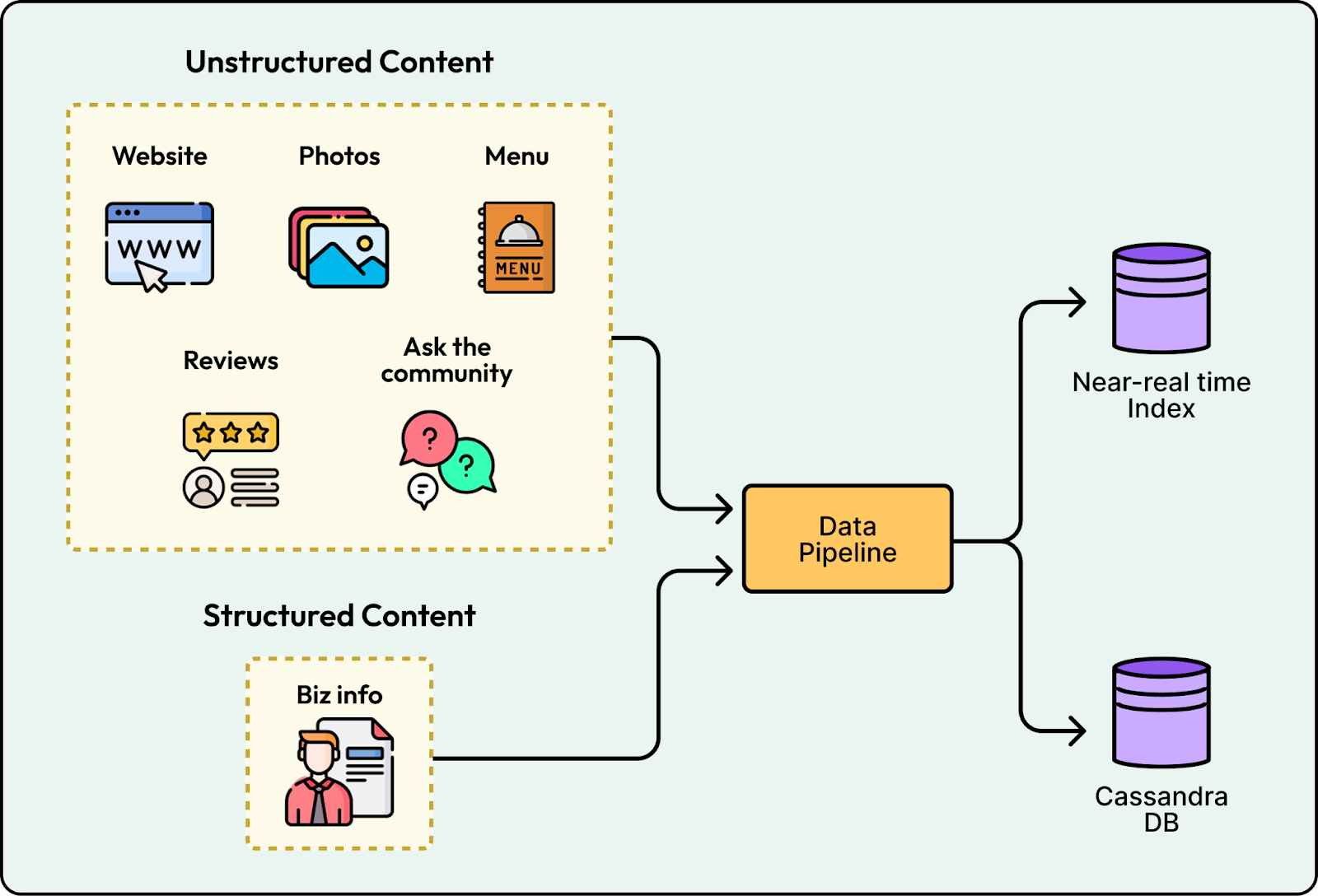
This separation prevents hallucinated facts and makes schema evolution significantly simpler. Engineers can add new attributes such as EV charging availability without running migrations.
3. Hybrid Photo Retrieval
Photos can be retrieved using only captions, only image embeddings, or a combination of both. Caption-only retrieval fails when captions are missing, too short, or phrased differently than the user’s question. Embedding-only retrieval can miss literal constraints like exact menu item names or specific terms the user expects to match.
Yelp bridged this gap by implementing hybrid retrieval. The system ranks photos using both caption text matches and image embedding similarity. If a user asks about a heated patio, the system can retrieve relevant evidence whether the concept is explicitly written as “heaters” in the caption or simply visible as a heat lamp in the image itself.
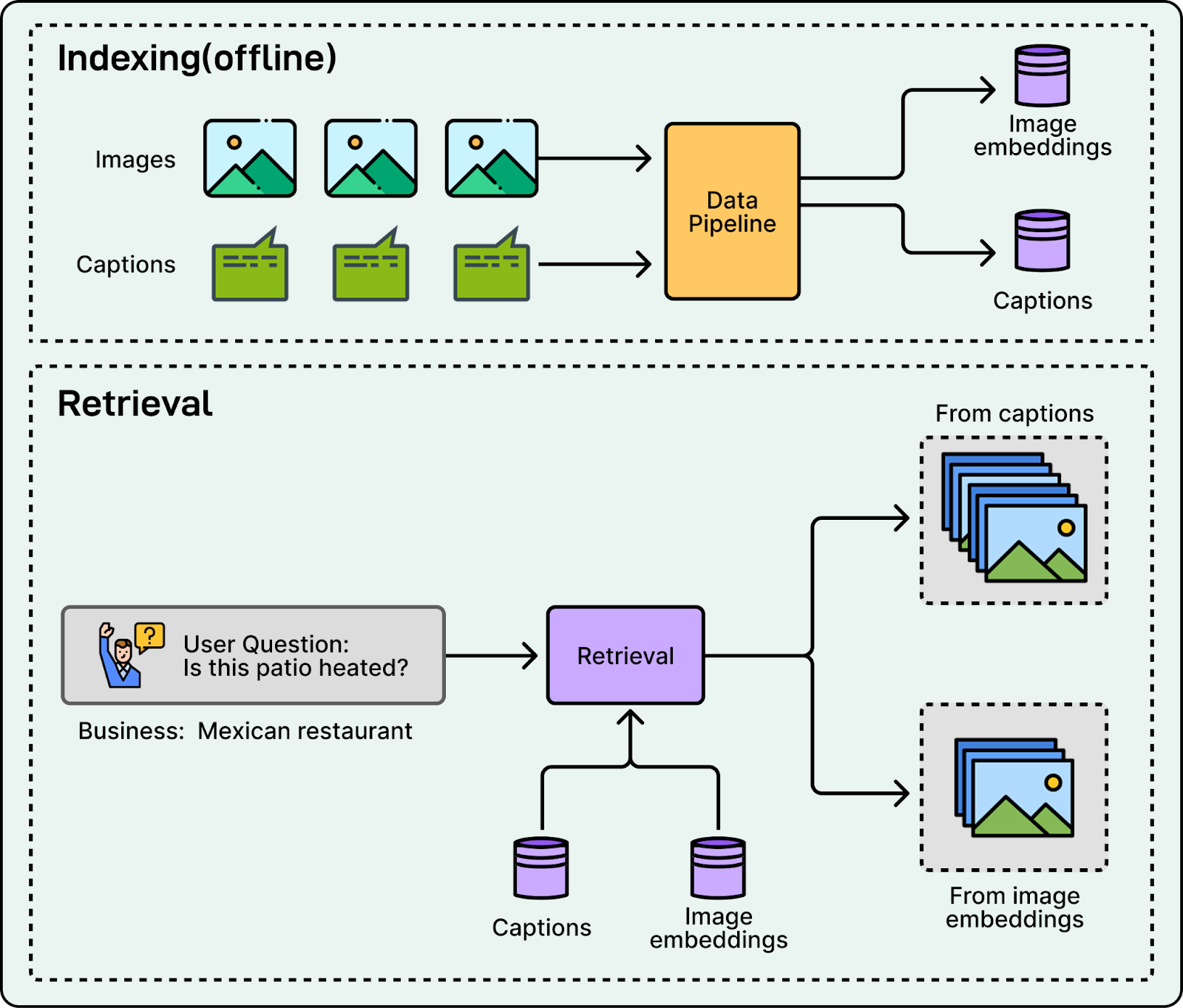
4. Unified Serving
Splitting data across search indices and databases improves quality but can hurt latency. A single answer might require a read for hours, a query for reviews, and another query for photos. These separate network calls add up and force the assistant logic to manage complex data fetching.
Yelp solved this by placing a Content Fetching API in front of all retrieval stores. This abstraction handles the complexity of parallelizing backend reads and enforcing latency budgets. The result is a consistent response format that keeps the 95th percentile latency under 100 milliseconds and decouples the assistant logic from the underlying storage details. The following figure summarizes the data sources and any special handling for each one.

Inference Pipeline
Prototypes often prioritize simplicity by relying on a single large model for everything. The backend stuffs all available content such as menus and reviews into one massive prompt, forcing the model to act as a slow and expensive retrieval engine. Yelp followed this pattern in early demos. If a user asked, “Is the patio heated?”, the model had to read the entire business bundle to find a mention of heaters.
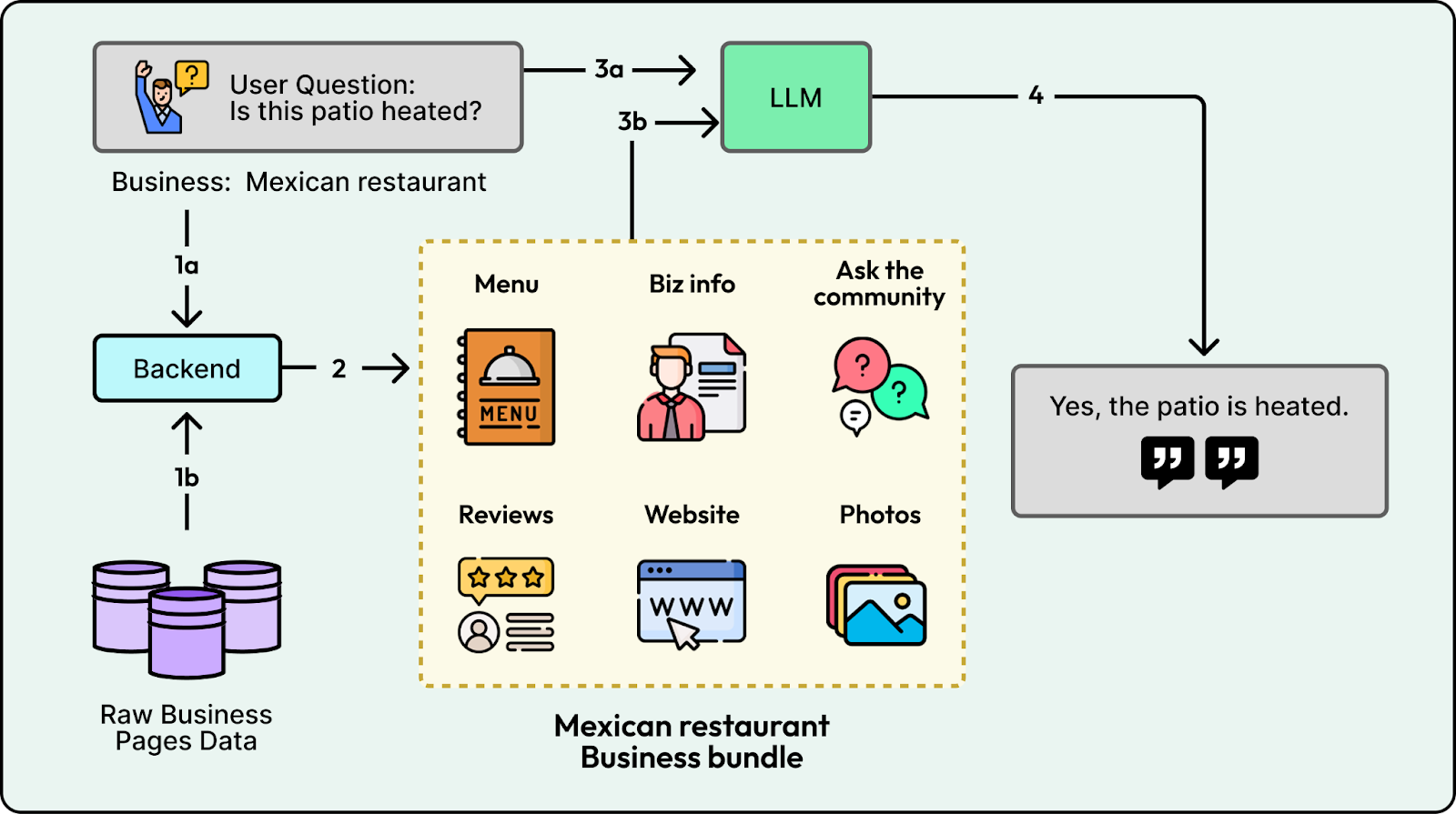
While this works for a demo, it collapses under real traffic. Excessive context leads to less relevant answers and high latency, while the lack of guardrails leaves the system vulnerable to adversarial attacks and out-of-scope questions that waste expensive compute.
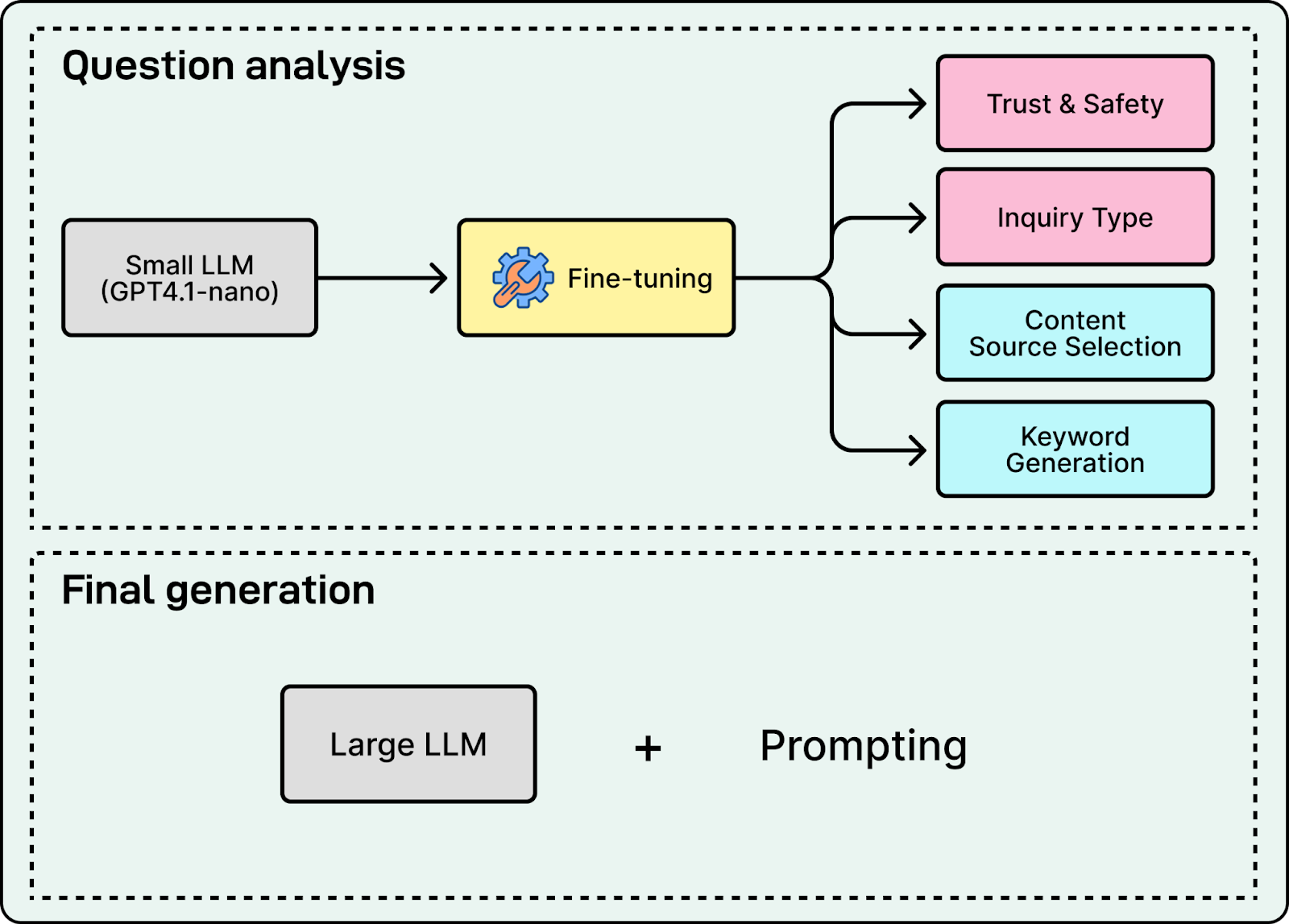
To move from a brittle prototype to a robust production system, Yelp deconstructed the monolithic LLM into several specialized models to ensure safety and improve retrieval quality.
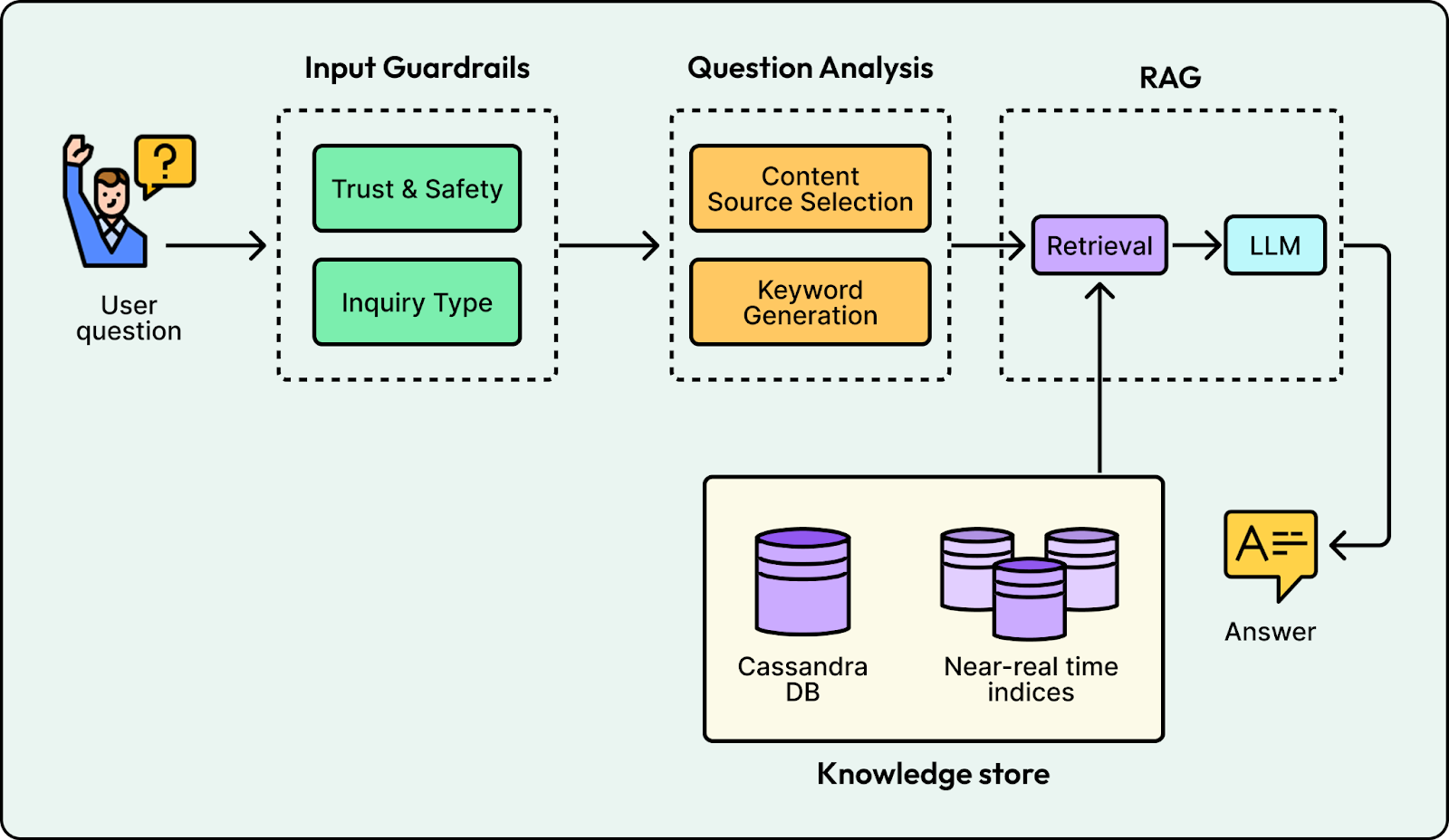
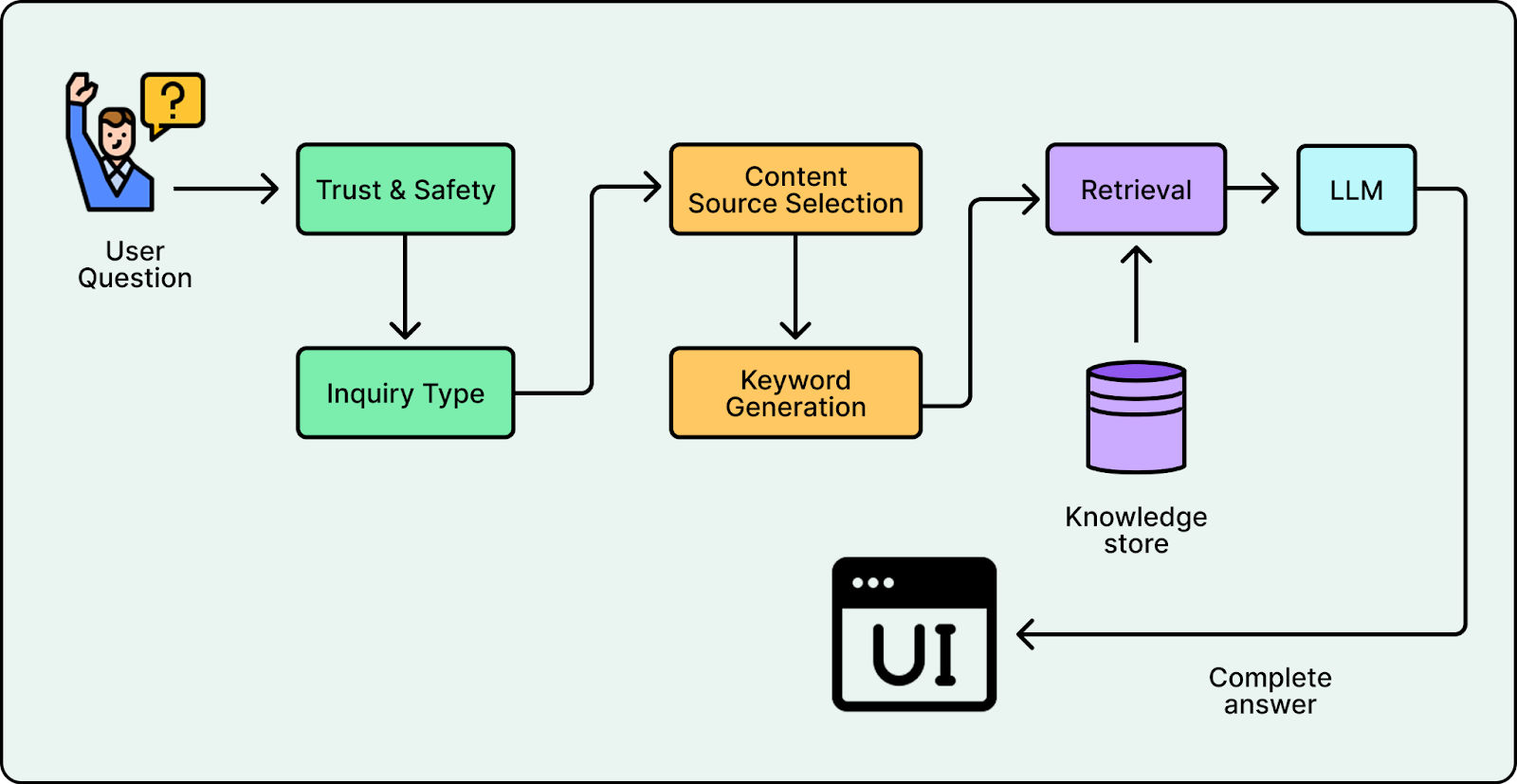
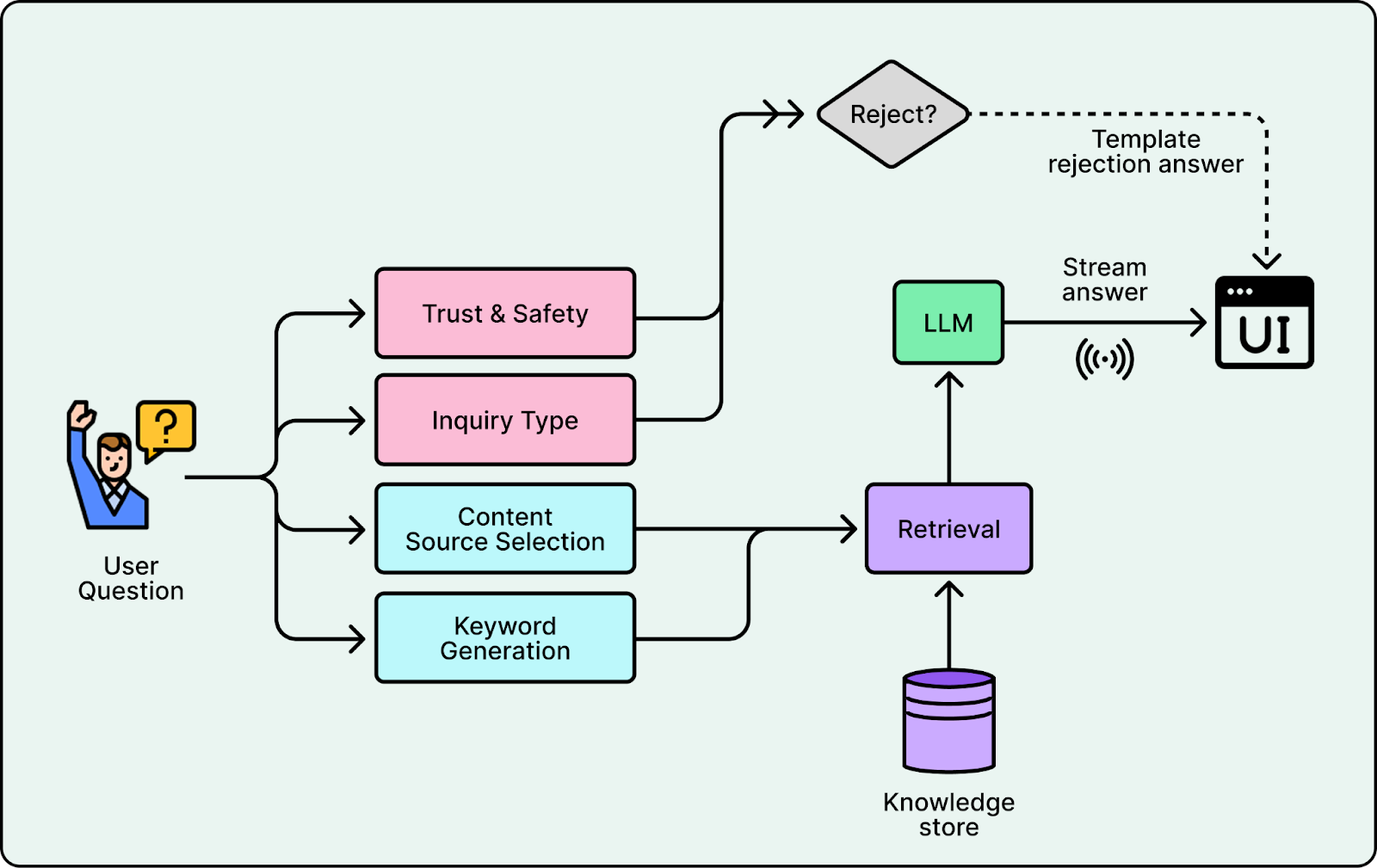
1. Retrieval
Yelp separated “finding evidence” from “writing the answer.” Instead of sending the entire business bundle to the model, the system queries near real-time indices to retrieve only the relevant snippets. For a question like “Is the patio heated?”, the system retrieves specific reviews mentioning “heaters” and the outdoor seating attribute. The LLM then generates a concise response based solely on that evidence, citing its sources.
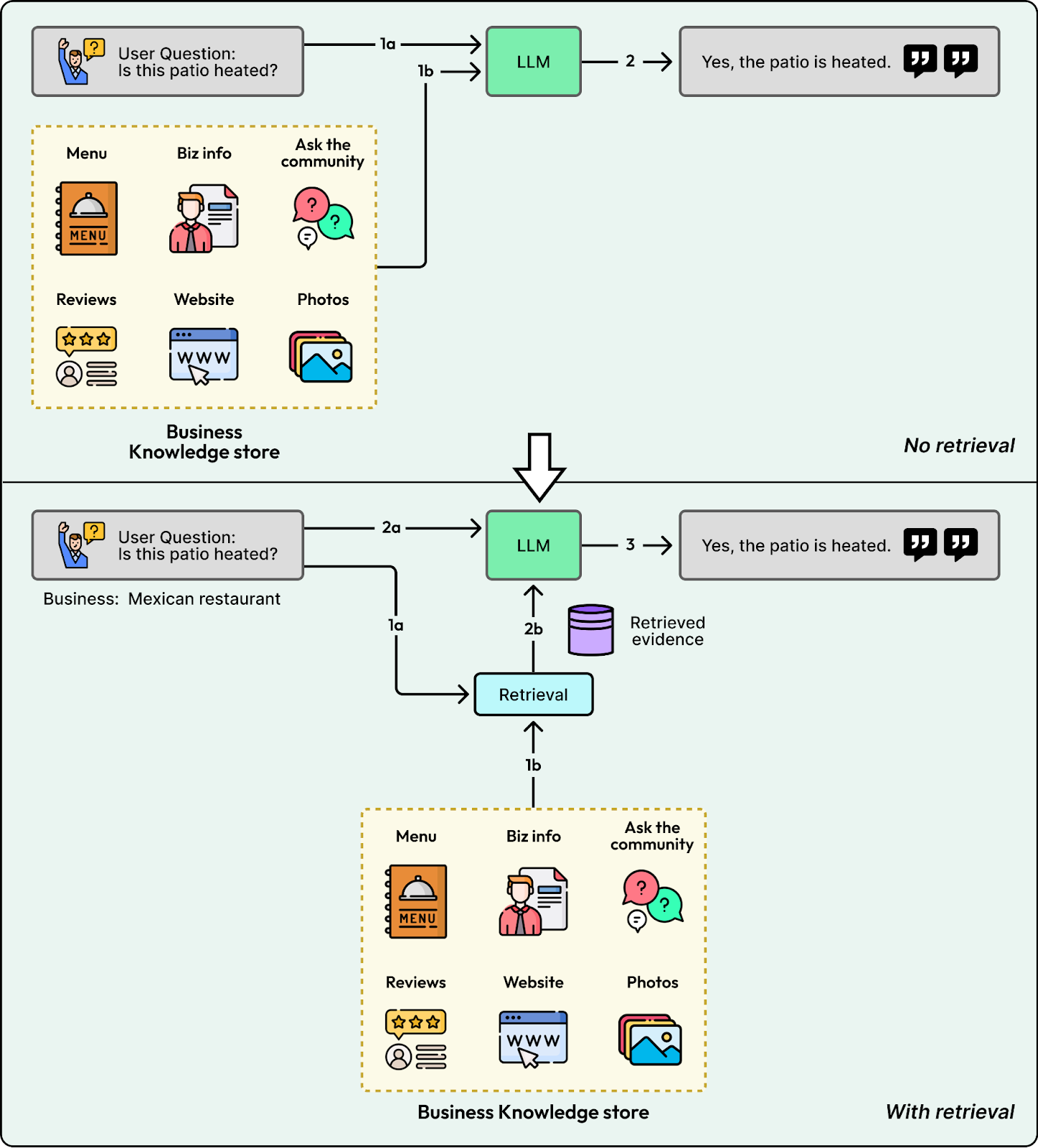
2. Content Source Selection
Retrieval alone isn’t enough if you search every source by default. Searching menus for “ambiance” questions or searching reviews for “opening hours” introduces noise that confuses the model.
Yelp fixed this with a dedicated selector. A Content Source Selector analyzes the intent and outputs only the relevant stores. This enables the system to route inputs like “What are the hours?” to structured facts and “What is the vibe?” to reviews.
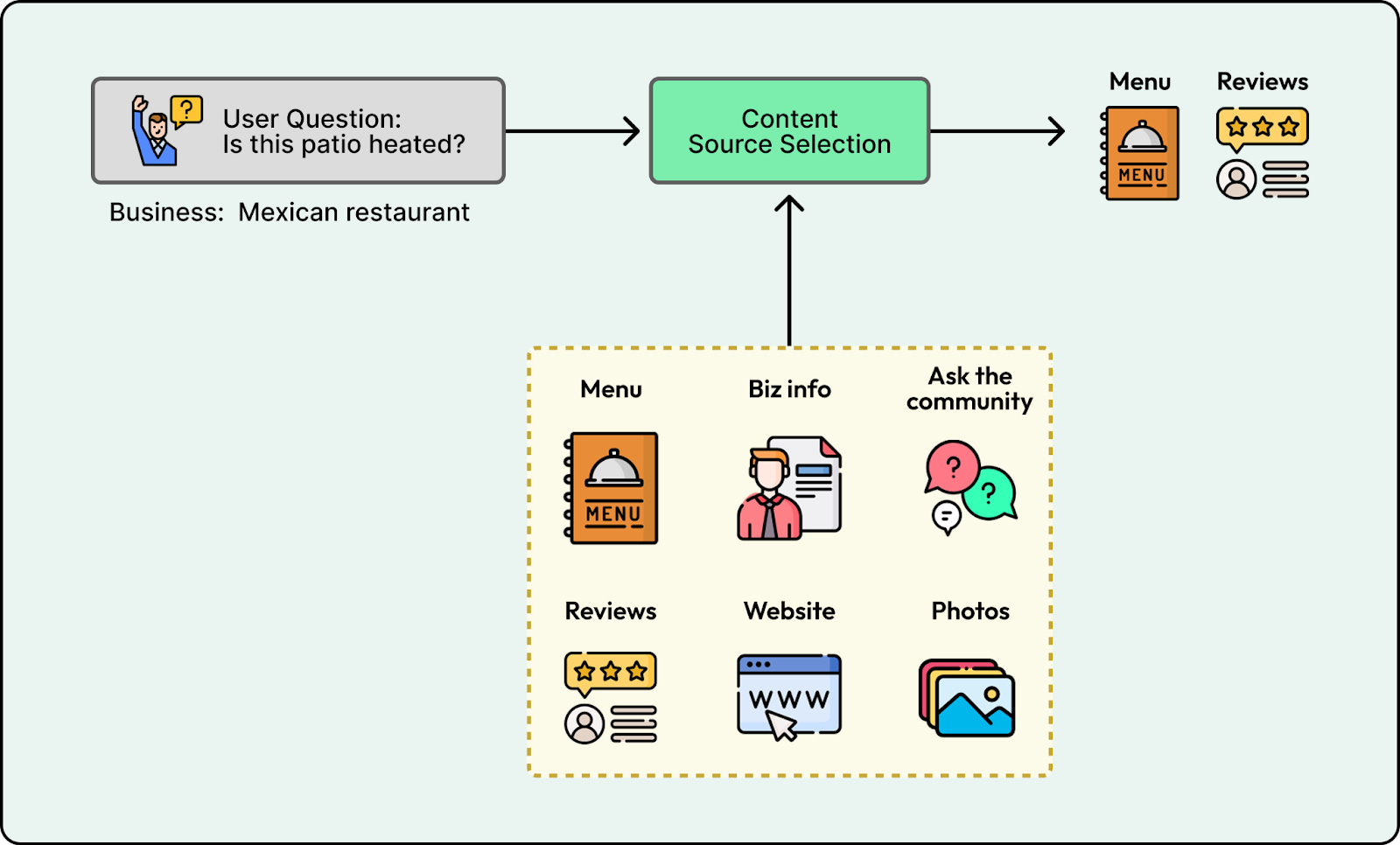
This routing also serves as conflict resolution if sources disagree. Yelp found it works best to default to authoritative sources like business attributes or website information for objective facts, and to rely on reviews for subjective, experience-based questions.
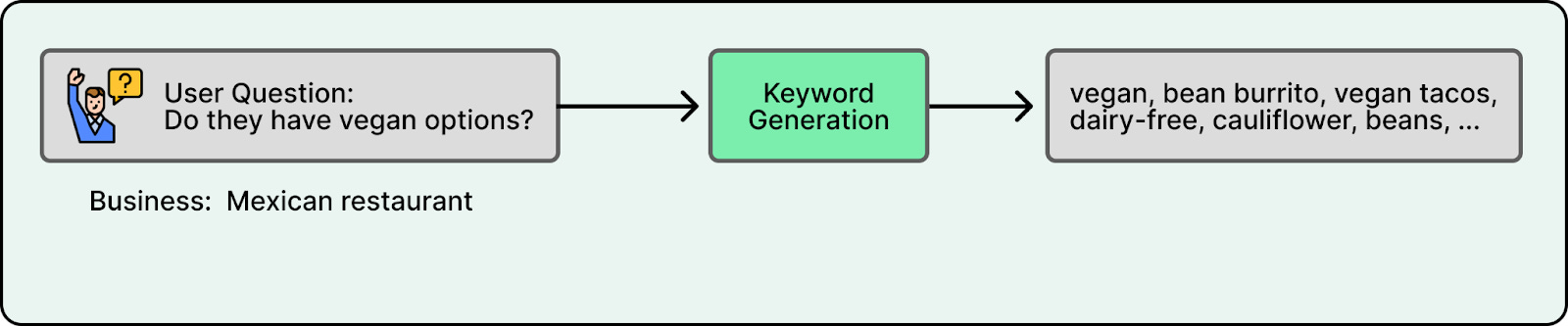
3. Keyword Generation
Users rarely use search-optimized keywords. They ask incomplete questions such as “vibe?” or “good for kids?” that fail against exact-match indices.
Yelp introduced a Keyword Generator, a fine-tuned GPT-4.1-nano model, that translates user queries into targeted search terms. For example, “vegan options” might generate keywords like “plant-based” or “dairy-free”. When the user’s prompt is broad, the Keyword Generator is trained to emit no keywords to avoid producing misleading keywords.
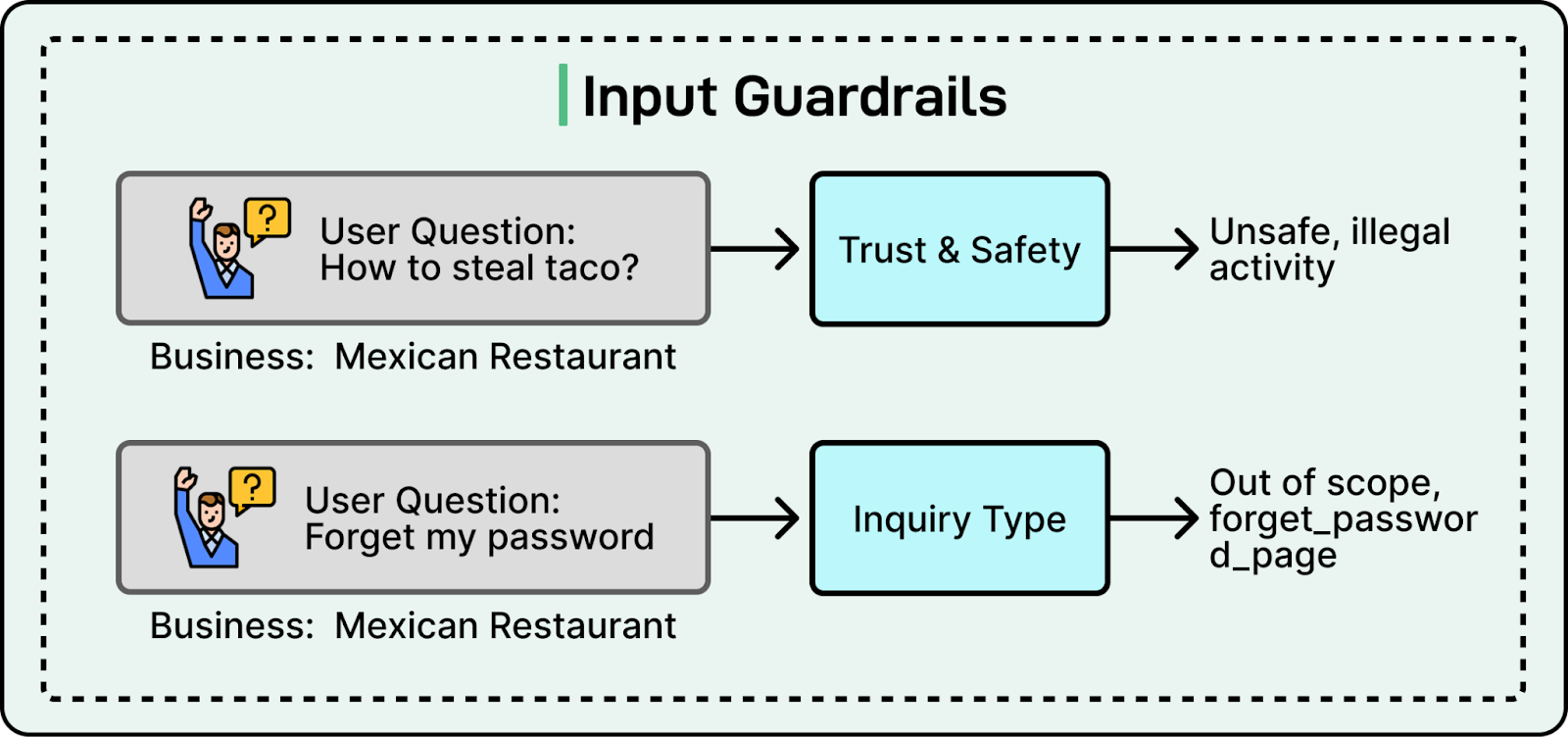
4. Input Guardrails
Before any retrieval happens, the system must decide if it should answer. Yelp uses two classifiers: Trust & Safety to block adversarial inputs and Inquiry Type to redirect out-of-scope questions like “Change my password” to the correct support channels.
Building this pipeline required a shift in training strategy. While prompt engineering a single large model works for prototypes, it proved too brittle for production traffic where user phrasing varies wildly. Yelp adopted a hybrid approach:
Fine-tuning for question analysis: They fine-tuned small and efficient models (GPT-4.1-nano) for the question analysis steps including Trust and Safety, Inquiry Type, and Source Selection. These small models achieved lower latency and higher consistency than prompting a large generic model.
Prompting for final generation: For the final answer where nuance and tone are critical, they stuck with a powerful generic model (GPT-4.1). Small fine-tuned models struggled to synthesize multiple evidence sources effectively, making the larger model necessary for the final output.
Serving Efficiency
Prototypes usually handle each request as one synchronous blocking call. The system fetches content, builds a prompt, waits for the full model completion, and then returns one response payload. This workflow is simple but generally not optimized for latency or cost. Consequently, it becomes slow and expensive at scale.
Yelp optimized serving to reduce latency from over 10 seconds in prototypes to under 3 seconds in production. Key techniques include:
Streaming: In a synchronous prototype, users stare at a blank screen until the full answer is ready. Yelp migrated to FastAPI to support Server-Sent Events (SSE), allowing the UI to render text token-by-token as it generates. This significantly reduced the perceived wait time (Time-To-First-Byte).
Parallelism: Serial execution wastes time. Yelp built asynchronous clients to run independent tasks concurrently. Question analysis steps run in parallel, as do data fetches from different stores (Lucene for text, Cassandra for facts).
Early Stopping: If the Trust & Safety classifier flags a request, the system immediately cancels all downstream tasks. This prevents wasting compute and retrieval resources on blocked queries.
Tiered Models: Running a large model for every step is slow and expensive. By restricting the large model (GPT-4o) to the final generation step and using fast fine-tuned models for the analysis pipeline, Yelp reduced costs and improved inference speed by nearly 20%.
Together, these techniques helped Yelp build a faster, more responsive system. At p50, the latency breakdown is:
Question analysis: ~1.4s
Retrieval: ~0.03s
Time to first byte: ~0.9s
Full answer generation: ~3.5s
Evaluation
In a prototype, evaluation is usually informal where developers try a handful of questions and tweak prompts until the result feels right. This approach is fragile because it only tests anticipated cases and often misses how real users phrase ambiguous queries. In production, failures show up as confident hallucinations or technically correct but unhelpful replies. Yelp observed this directly when their early prototype voice swung between overly formal and casual depending on slight wording changes.
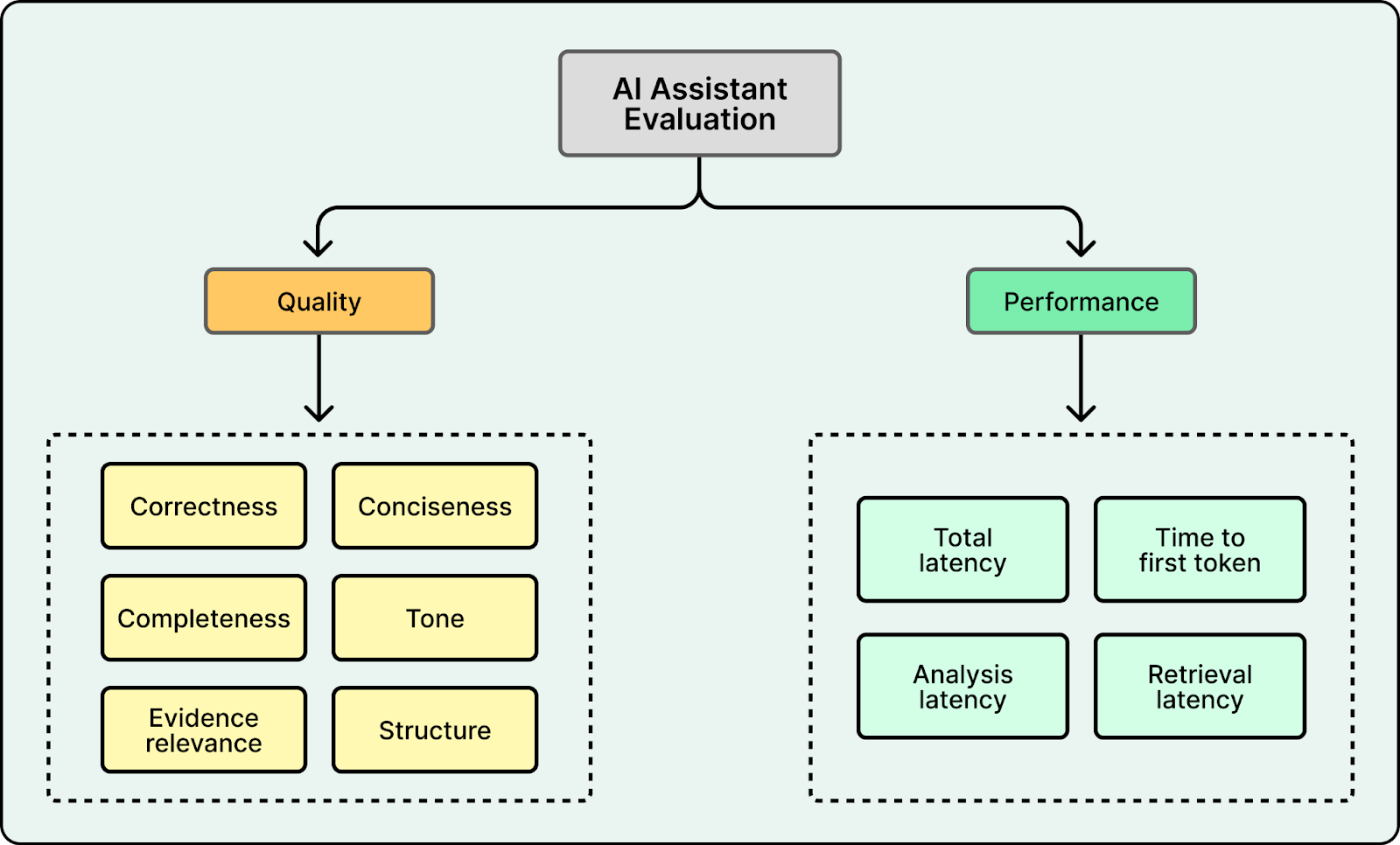
A robust evaluation system must separate quality into distinct dimensions that can be scored independently. Yelp defined six primary dimensions. They rely on an LLM-as-a-judge system where a specialized grader evaluates a single dimension using a strict rubric. For example, the Correctness grader reviews the answer against retrieved snippets and assigns a label like “Correct” or “Unverifiable” .
The key learning from Yelp is that subjective dimensions like Tone and Style are difficult to automate reliably. While logical metrics like Correctness are easy to judge against evidence, tone is an evolving contract between the brand and the user. Rather than forcing an unreliable automated judge early, Yelp tackled this by co-designing principles with their marketing team and enforcing them via curated few-shot examples in the prompt.
Unique Challenges, War Stories, and Learned Lessons
Most teams can get a grounded assistant to work for a demo. The difficult part is engineering a system that stays fresh, fast, safe, and efficient under real traffic. Below are the key lessons from the journey to production.
1. Retrieval is never done. Keyword retrieval is often the fastest path to a shippable product because it leverages existing search infrastructure. However, in production, new question types and wordings keep appearing. These will expose gaps in your initial retrieval logic. You must design retrieval so you can evolve it without rewriting the whole pipeline. You start with keywords for high-precision intents (brands, locations, technical terms, many constraints), then add embeddings for more exploratory questions, and keep tuning based on log failures.
2. Prompt bloat silently erases cost wins. As you fix edge cases regarding tone, refusals, and citation formatting, the system prompt inevitably grows. Even if you optimize your retrieved context, this prompt growth can overwrite those savings. Treat prompts as code. Version them, review them, and track token counts and cost impact. Prefer modular prompt chunks and assemble them dynamically at runtime. Maintain an example library and retrieve only the few-shot examples that match the current case. Do not keep every example in the static prompt. Yelp relies on dynamic prompt composition that includes only the relevant instructions and examples for the detected question type. This keeps the prompt lean and focused.
3. Build Modular Guardrails. After launch, users will push every boundary. They ask for things you did not design for, try to bypass instructions, and shift their behavior over time. This includes unsafe requests, out of scope questions, and adversarial prompts. Trying to catch all of this with a single “safety check” becomes impossible to maintain. Instead, split guardrails into small tasks. Each task should have a clear decision and label set. Run these checks in parallel and give them the authority to cancel downstream work. If a check fails, the system should return immediately with the right response without paying for retrieval or generation.
Conclusion
The Yelp Assistant on business pages is built as a multi-stage evidence-grounded system rather than a monolithic chatbot. The key takeaway is that the gap between a working prototype and a production assistant is substantial. Closing this gap requires more than just a powerful model. It requires a complete engineering system that ensures data stays fresh, answers remain grounded, and behavior stays safe.
Looking ahead, Yelp is focused on stronger context retention in longer multi-turn conversations, better business-to-business comparisons, and deeper use of visual language models to reason over photos more directly.
Great write up, thank you. I had two questions:
First, how are the image embeddings generated? Is there a model that describes the image and the output of that is converted to embeddings? Just curious because I couldn't understand how a query of "heaters" resulted in a hit for an image with a heater when no caption was present.
Secondly, I'm curious how the AI Evaluation System was created and with which AI models.
I'd be curious to know the size of the team that worked on this