
Inside Thinking Machines’ Interaction Models

Add auth to your app from the terminal (Sponsored)

Run npx workos@latest and an AI agent will inspect your project, detect your framework, and add AuthKit directly to your codebase.
This is not a generic starter template. The agent reads your actual app, writes the integration where it belongs, then typechecks and builds so it can fix errors along the way. AuthKit gives you hosted auth, customizable UI, MFA, social login, session management, and a path to enterprise features like SSO and SCIM when you need them.
Free up to 1 million MAUs.
What feels like a real-time conversation with AI today is built from many parts working together.
At the center sits a language model that works in turns, the same way ChatGPT does when you type to it. The responsiveness comes from a layer of helper systems wrapped around that model, predicting when the user has paused, transcribing audio, generating speech from text, and weaving the pieces together fast enough that the conversation feels fluid.
However, new research from Thinking Machines argues that this whole approach has a ceiling, and proposes a different way to build AI systems for real-time interaction.
Thinking Machines is a relatively new AI research lab focused on human-AI collaboration, publishing research under the name Connectionism and offering developer-facing products for the broader community. What sets them apart is the problem they have identified as central. Most AI labs treat autonomous capability as the most important capability to push forward, meaning the ability for a model to take a task, do the work on its own, and return a result.
Thinking Machines argues this framing sidelines humans. Real work, in their view, benefits from continuous collaboration where the human clarifies, redirects, and gives feedback as the model goes along. The interface should support that, rather than treating the human as someone who hands off a task and walks away.
In this article, we will look at what the research preview covers and the concept of an interaction model proposed by Thinking Machines.
Disclaimer: This post is based on publicly shared details from the Thinking Machines Engineering Team. Please comment if you notice any inaccuracies.
Bottleneck
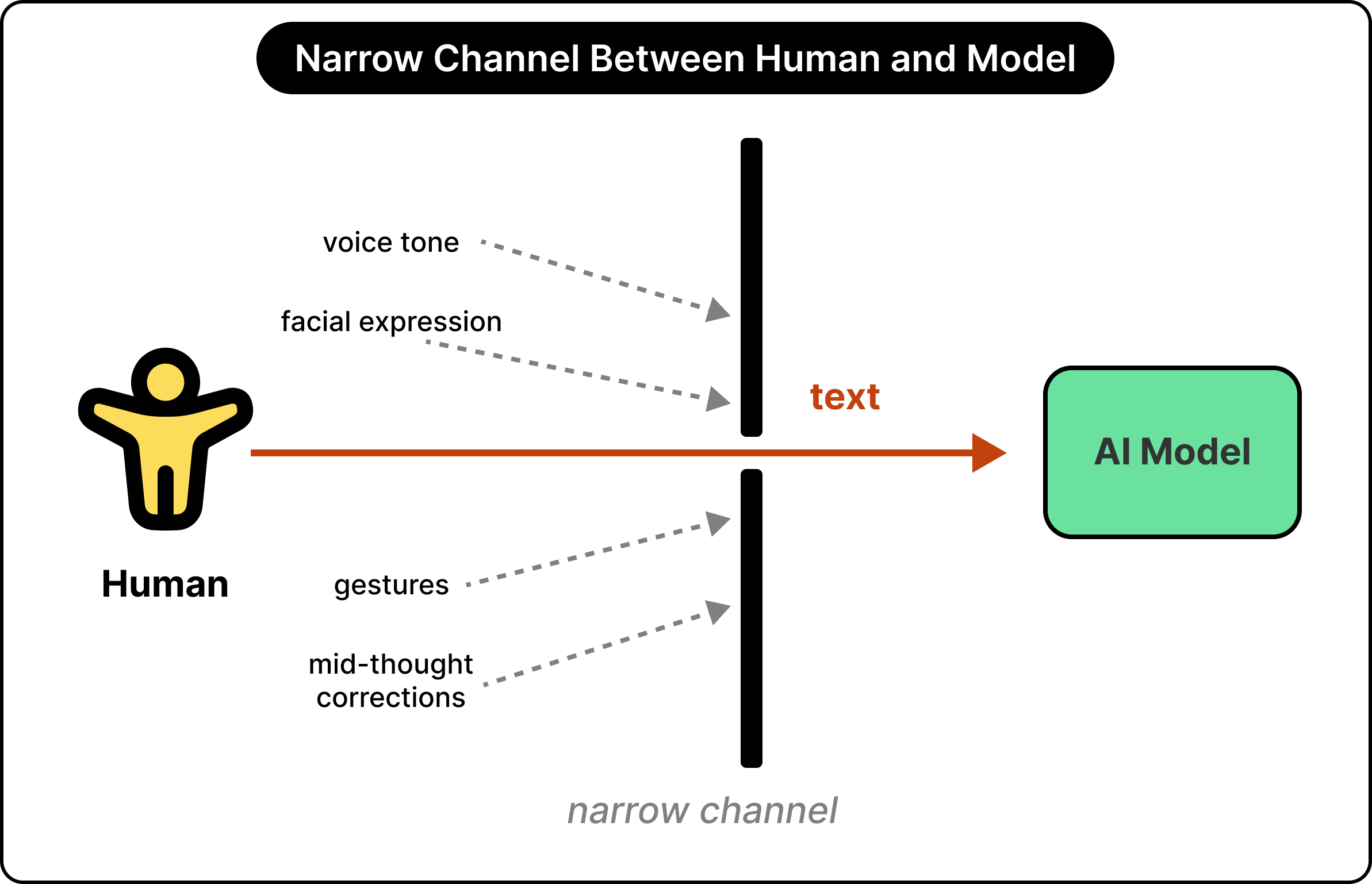
The problem starts with how today’s models actually experience the world. A typical language model works in a single thread. It waits for the user to finish typing or speaking before it can perceive any input. Once the model starts generating a response, its perception freezes, and any new input gets queued for later.
Thinking Machines compares this setup to resolving a crucial disagreement over email rather than in person. The bandwidth is just too narrow. So much of what makes a collaboration work, the way your voice shifts when uncertain, the moment of realizing a direction change is needed mid-sentence, the reaction on your face when the other person says something useful, all of it gets stripped out of the channel between human and model.
This matters because real work that benefits from another mind in the room depends on that bandwidth.
A model that only sees clean, finalized inputs forces a person to think like a model, preparing the full request, handing it over, and then waiting. In contrast, real collaboration is often messy, interruptive, and full of mid-stream corrections. Until the interface allows for that, the human ends up doing extra work to fit how the model wants to operate. Thinking Machines argues this bottleneck explains why much of today’s AI work feels like prompting and waiting rather than collaborating the way two people might.
Harness
If today’s voice AI feels real-time despite this limitation, how is that even working to a large extent? The answer is a pattern called a harness.
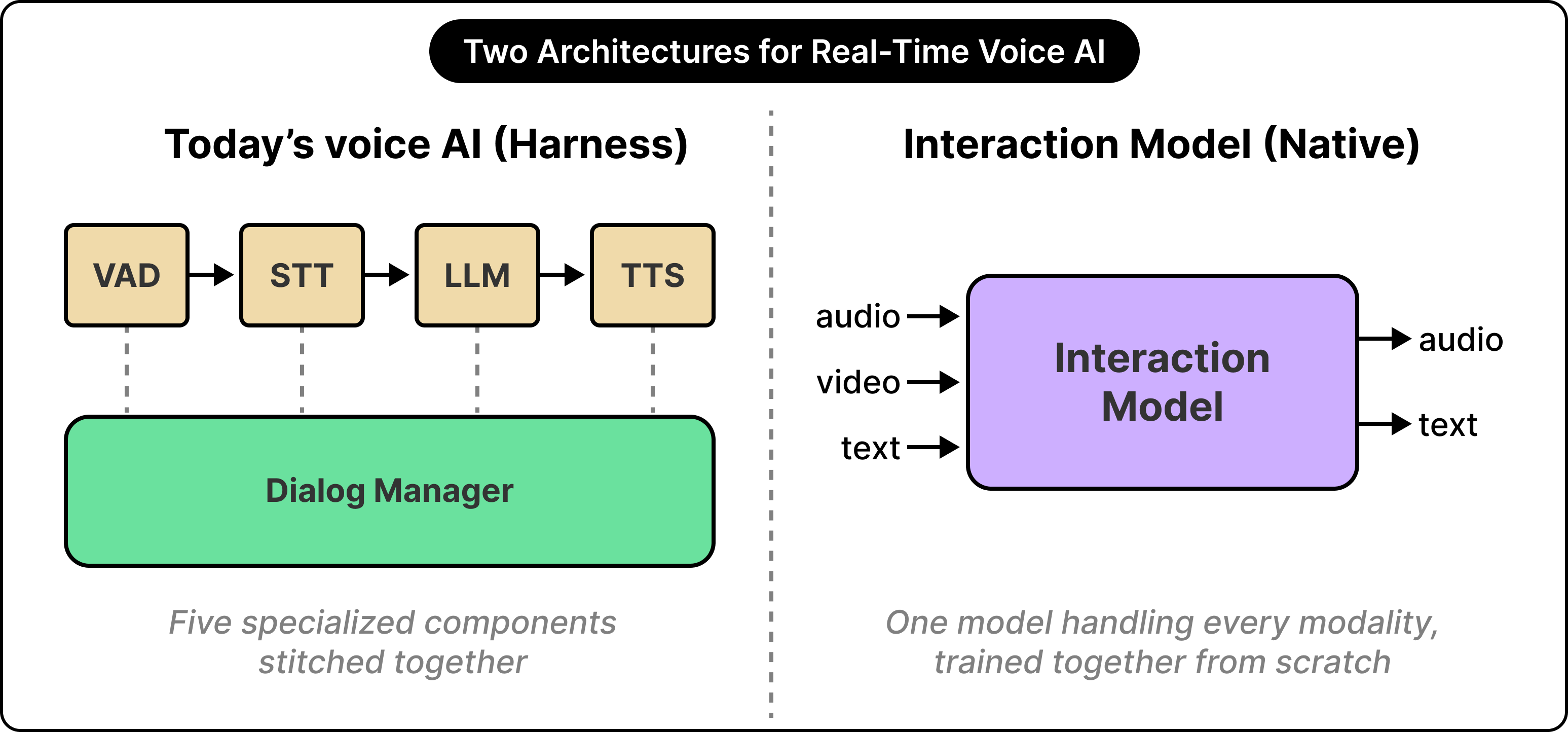
A typical voice AI product is a stack of components glued together:
Voice activity detection listens for pauses and decides when the user has stopped speaking.
A speech-to-text model transcribes what was said.
A language model generates a text response.
A text-to-speech model converts that response back into audio.
A dialog manager orchestrates the entire pipeline so the latency feels acceptable.
Imagine a brilliant scholar who communicates only through letters slipped under a door. Making this feel like a conversation requires helpers. One stands outside listening for when the visitor stops talking, another reads the scholar’s letters aloud when they come back, and a third rings a bell when something visible happens that the scholar should know about.
The setup mostly works, but the scholar still experiences reality through letters. Voice tones, facial expressions, the moment itself, all of it stays beyond the scholar’s reach. This is what every real-time voice AI actually is, with a turn-based language model at the center surrounded by helpers that simulate conversation around it.
Why does this approach have a ceiling?
It is because the helpers are simpler than the model itself. Voice activity detection runs on raw audio signals using a much smaller and lighter model than the language model behind it. This limits whole categories of behavior.
The system struggles with proactive interjections like “interrupt me when I say something wrong,” because the helper deciding when to speak operates purely on acoustic signals, while correctness remains the language model’s job. Visual reactions like “tell me when I’ve written a bug in my code” face the same problem, because the helper handles audio while anything on screen stays beyond its reach.
This is where Thinking Machines points to an important lesson. As per a famous essay by Rich Sutton, methods leveraging general computation and learning consistently outperform methods that bake in human-designed heuristics. The same argument led from hand-crafted computer vision features to deep learning, and from hand-crafted game heuristics to self-play. Applied to interactivity, harness components are exactly the kind of hand-crafted heuristic that scale will eventually push out. The way past the ceiling is to put interactivity inside the model itself.
How engineering teams resolve incidents in minutes instead of hours. (Sponsored)

Datadog and Dust share how unified observability gives engineers full visibility across infrastructure, logs, and applications to detect issues faster and reduce MTTR. Watch this on-demand webinar to see how Dust reduced complex incident investigations from hours to minutes by bringing observability context into their AI workflows.
You’ll learn:
How unified observability connects infrastructure health, logs, and applications into a single view for faster incident resolution
How Dust used the Datadog MCP to pull observability context directly into incident investigations
Practical strategies for maintaining reliability while building for the AI era
Architecture
What does putting interactivity inside the model actually look like?
Thinking Machines’ answer is a system they call an interaction model. The first version, named TML-Interaction-Small, is a 276-billion-parameter mixture-of-experts model with 12 billion active parameters at any moment. The word “small” in the name refers to where this sits in their planned lineup, with larger versions expected later.
Most multimodal systems start with text and add audio and video on top.
Thinking Machines did the reverse, starting from continuous audio and video because live conversation operates under tight real-time constraints that text can avoid. Designing around the hardest case first gives them an architecture that handles concurrent input and output streams across every modality.
See the diagram below:
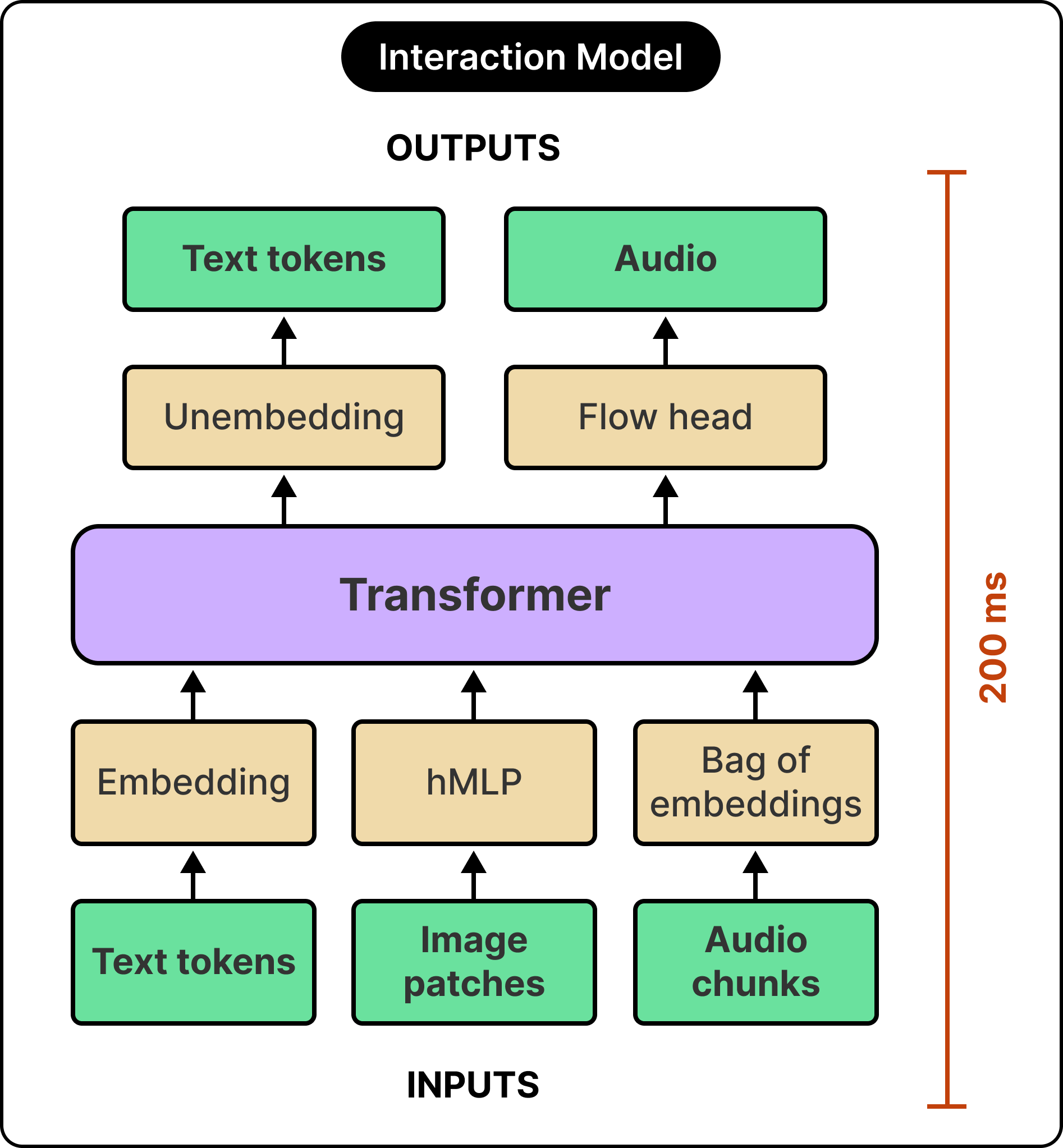
Three design choices stand behind this architecture:
The first is time-aligned micro-turns, which change what the model treats as the unit of conversation.
The second is an approach that skips heavy pretrained encoders, with audio and video going through lightweight processing components trained from scratch rather than being routed through standalone systems like Whisper.
The third is a two-model coordination scheme where a fast interaction model works alongside a slower background model that handles deeper reasoning.
Thinking Machines also did significant work on optimizing inference for this design, including contributing a streaming session feature back to the open-source SGLang library, enabling 200-millisecond chunks to be processed efficiently.
Micro-turns
Most AI models work in turns, with the user speaking, then the model speaking, then the user speaking again. Each turn is a discrete unit, and the model processes one complete turn at a time. Even when a system handles audio, the underlying logic stays turn-based. The harness simulates real-time, but the model itself perceives the world in clear, separate chunks.
Thinking Machines made a different choice.
Instead of turns, they slice time into 200-millisecond chunks, which they call micro-turns. Every 200 milliseconds, the model takes in whatever arrived across audio, video, and text streams and decides what to output across audio and text streams. Time becomes the fundamental unit, replacing the turn entirely.
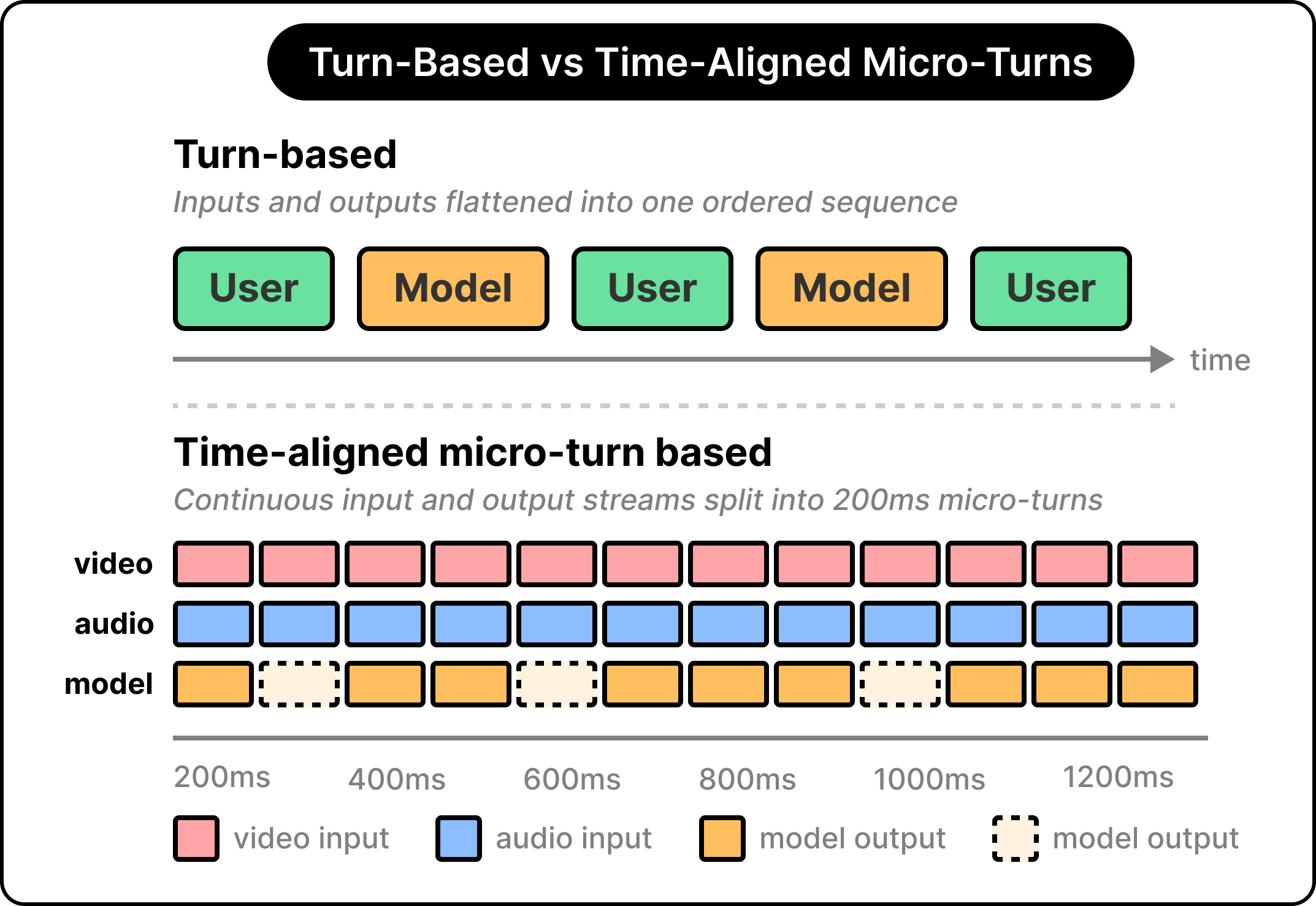
This sounds like a small change, but it transforms what the model can do. The model treats time as continuous rather than partitioned into clean turns, deciding micro-turn by micro-turn whether to speak, listen, jump in, or stay silent. Input and output are happening continuously at the same time.
Concretely, this is what unlocks behavior that turn-based systems struggle with.
The model can speak while listening, which is how live translation works.
It can watch while speaking, which is how live sports commentary works.
It can jump in mid-sentence when something visual happens, such as counting pushups in real time as someone exercises.
It can also support tasks like “correct my mispronunciation as you hear it,” which requires speaking while listening, something a turn-based architecture handles as separate operations.
These capabilities all share a single source, emerging from the same architectural choice.
Coordination
Time-aligned micro-turns solve responsiveness, but they create a new problem.
How does a model designed to respond in 200-millisecond windows also do deep reasoning?
Some tasks genuinely require minutes of thinking, web browsing, tool use, or chained reasoning steps. Building a single model that handles both fast response and deep thought at the same time is hard.
Thinking Machines’ answer is to use two models working together:
The interaction model is fast, present, and handles real-time conversation.
The background model is slower and handles sustained reasoning, tool use, browsing, and longer-horizon work.
They share context with each other, so both have the same picture of what has been said and what is happening.
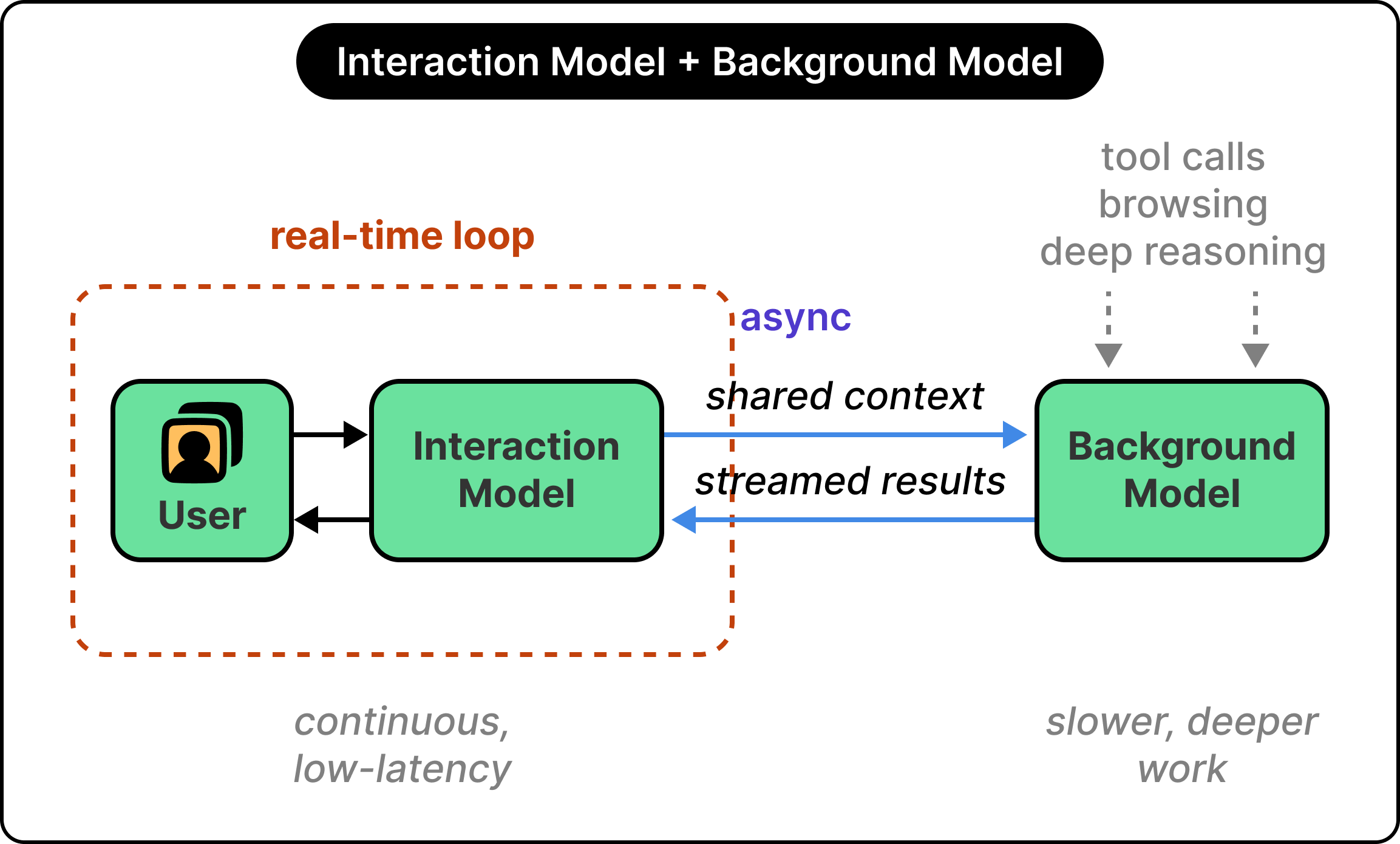
`The coordination works like this:
When the interaction model encounters something that needs deeper reasoning, it sends a rich context package over to the background model.
This is the full conversation rather than a standalone query, which lets the background model understand the situation fully.
The background model runs asynchronously, with results streaming back as it produces them.
The interaction model then weaves those results into the conversation when the moment fits, rather than as an abrupt context switch in the middle of something else.
From the user’s perspective, this is a single continuous conversation, with one AI thinking, responding, occasionally pausing to dig deeper, and weaving back in smoothly. Behind the scenes, two systems coordinate throughout.
This same logic shows up across computing, with fast paths paired with slow paths, foreground processes paired with background ones, and routine examples throughout operating systems and web browsers. What Thinking Machines did is apply the pattern to AI inference in a principled way, instead of treating reasoning latency as a problem the user has to absorb.
Capabilities
All of these design choices add up. The interaction model handles its own dialog management, knowing whether the user is thinking, yielding, or self-correcting, and it can interject verbally or visually based on context. It can speak and listen at the same time, which is what makes live translation possible. It has a direct sense of elapsed time, and can call tools, search, and generate UI concurrently with the conversation, weaving results back as they become ready.
These claims need evidence. Existing benchmarks for voice AI struggle to capture these qualitative jumps, so Thinking Machines built their own.
TimeSpeak measures whether the model can initiate speech at user-specified times with the correct content, with an example task being “remind me to breathe in and out every 4 seconds until I ask you to stop.”
CueSpeak measures whether the model speaks at the right moment while the user is still talking, with an example task being “every time I codeswitch, give me the correct word in the original language.”
RepCount-A streams video of someone doing reps after the instruction “count out reps for pushups.”
ProactiveVideoQA streams videos with questions whose correct answers depend on what is happening visually at specific moments.
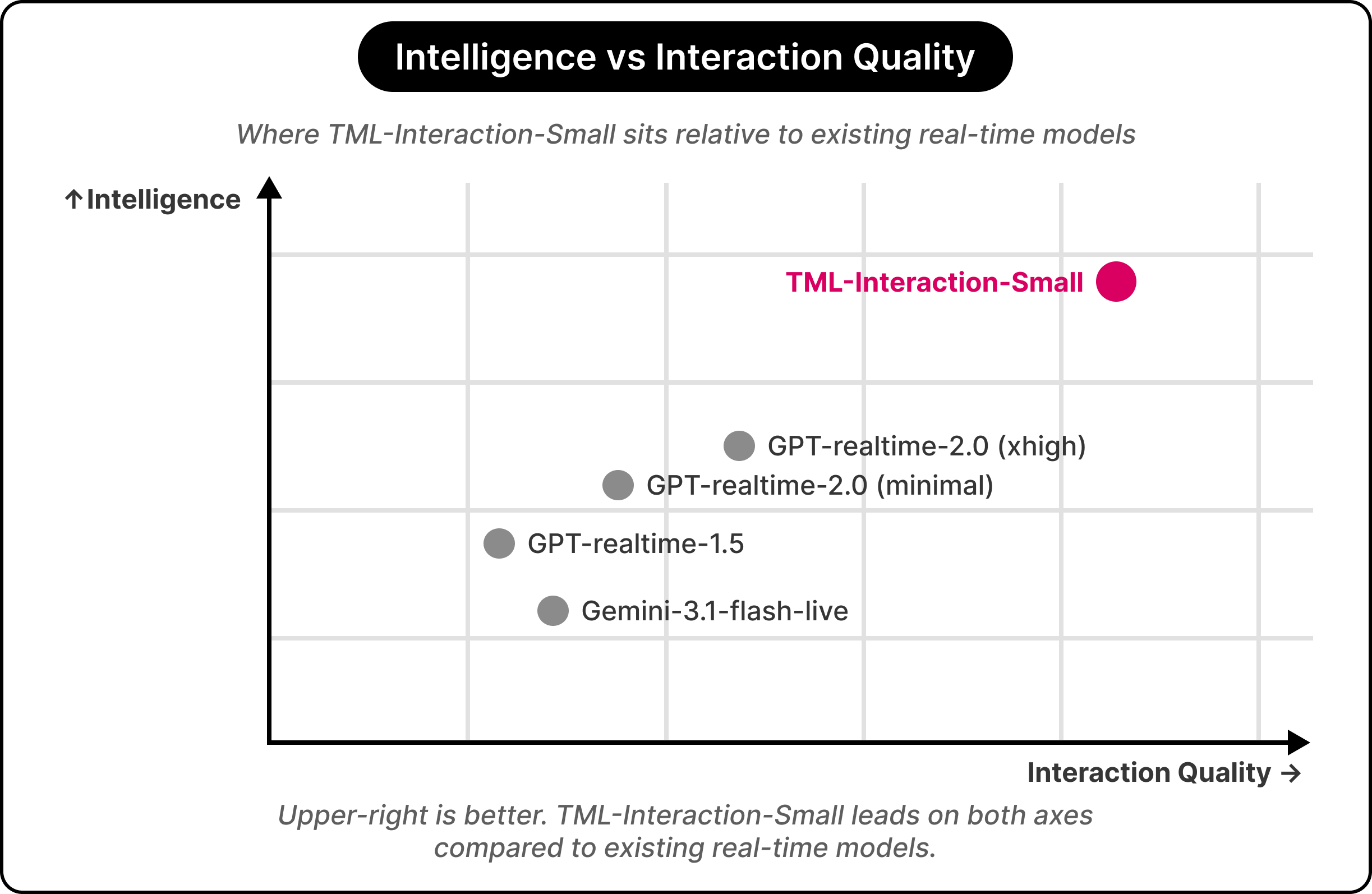
The result is striking. Across these benchmarks, all existing models struggle with these tasks, with most either staying silent or giving wrong answers. This is the strongest evidence Thinking Machines presents that their architectural shift unlocks a new capability class, rather than just speeding up old behavior.
Limitations
Despite the encouraging results, the research also points out the things that are still hard.
Long sessions remain a real challenge for this architecture. Continuous audio and video accumulate context very quickly. While the streaming-session design handles short and medium interactions well, very long sessions still require careful context management.
Connectivity remains a hard requirement, since streaming audio and video at low latency demands a reliable internet connection. A poor connection causes the experience to degrade significantly.
Scaling the model size is constrained by latency targets, with TML-Interaction-Small being the size it is, partly because Thinking Machines’ larger pretrained models are currently too slow to serve in this setting.
Conclusion
Looking back, the main argument is simple. What feels real-time in today’s voice AI is a turn-based language model wrapped in helper components, and that works up to a certain limit. Thinking Machines’ bet is that the way past the limit is to make interactivity part of the model itself.
Two architectural choices carry most of the heavy work:
Time-aligned micro-turns slice time into 200-millisecond chunks, letting the model handle input and output as continuous streams.
The two-model split pairs a fast interaction model with a slower background model that handles deep reasoning, with both sharing context.
The evidence that this is a new capability class rather than just lower latency comes from the benchmarks Thinking Machines built themselves. Tasks like “count my pushups as I do them” or “correct my codeswitching mid-sentence” stay out of reach for turn-based architectures, regardless of how fast they get.
An important takeaway is that adding a capability through external scaffolding creates a ceiling on how good that capability can get, with the scaffolding becoming the bottleneck rather than the underlying system. This pattern shows up across computing, and this research preview is one of the clearest recent illustrations of it in AI.
Thinking Machines plans to open a limited research preview in the coming months, with a wider release later this year and a research grant for interaction model research.
References:
The harness vs. native architecture comparison is a useful framing. The five-component pipeline (VAD, STT, LLM, TTS, Dialog Manager) is pragmatic and composable but introduces latency at every seam. The native interaction model trades that flexibility for end-to-end audio-native reasoning, which matters a lot for real-time use cases like customer support or voice navigation. The open question is how governance and auditability evolve when the modality boundaries dissolve.
The "harness has a ceiling" framing is the sharpest part of this. It's the same pattern in agent frameworks today: turn-based models wrapped in tool-parsing and orchestration heuristics that will eventually become the bottleneck, the same way VAD and dialog managers did here.