Multi-Region Architecture: Going Global Without Going Broke

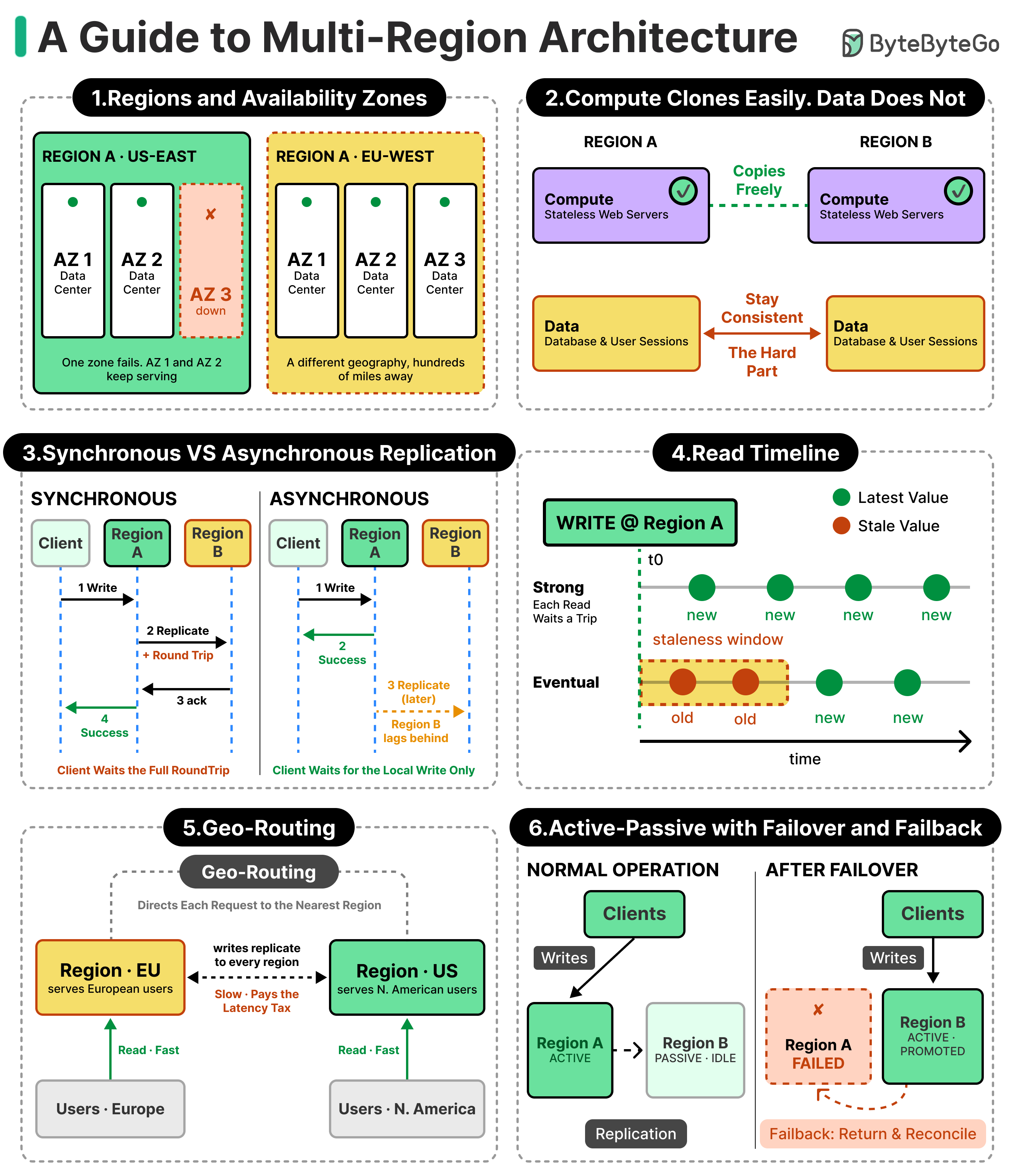
When an application grows geographically, it is logical to start serving it from a second region to improve latency and availability. However, adding a second region to an application can make it slower and less reliable than it was with one.
That runs against the instinct, which says more locations should mean faster service and steadier uptime, which is often the case. But once the same data lives in two places at once, a new class of problem appears that can nullify the advantages of multi-region deployments.
Let’s look at a short example. Picture two edits to the same piece of data, made at nearly the same instant, one handled by a server on the US East Coast and one by a server in Frankfurt, right as the network link between those regions drops. Both edits are saved locally. Each region now holds a different version of that data, with no shared record of which one came first. When the link comes back, one of the two versions has to be chosen over the other. The way a system handles that question has a large effect on what a global footprint costs to build and to run.
Going global is better understood as a progression than as a single decision. In this article, we will start with the building blocks, the small set of concepts every regional design rests on, then work through the common setups in order, from a single region with backups up to running every region at once. Each step buys something concrete: lower latency, higher availability, or the ability to keep data inside a country’s borders. Each one also has a price, in money and in the consistency tradeoffs it introduces.