
Multimodal LLMs Basics: How LLMs Process Text, Images, Audio & Videos

Yesterday’s data can’t answer today’s questions. (Sponsored)

Static training data can’t keep up with fast-changing information, leaving your models to guess. We recommend this technical guide from You.com, which gives developers the code and framework to connect GenAI apps to the live web for accurate, real-time insights.
What you’ll get:
A step-by-step Python tutorial to integrate real-time search with a single GET request
The exact code logic to build a “Real-Time Market Intelligence Agent” that automates daily briefings
Best practices for optimizing latency, ensuring zero data retention, and establishing traceability
Turn “outdated” into “real-time.”
For a long time, AI systems were specialists confined to a single sense. For example:
Computer vision models could identify objects in photographs, but couldn’t describe what they saw.
Natural language processing systems could write eloquent prose but remained blind to images.
Audio processing models could transcribe speech, but had no visual context.
This fragmentation represented a fundamental departure from how humans experience the world. Human cognition is inherently multimodal. We don’t just read text or just see images. We simultaneously observe facial expressions while listening to the tone of voice. We connect the visual shape of a dog with the sound of a bark and the written word “dog.”
To create AI that truly operates in the real world, these separated sensory channels needed to converge.
Multimodal Large Language Models represent this convergence. For example, GPT-4o can respond to voice input in just 232 milliseconds, matching human conversation speed. Google’s Gemini can process an entire hour of video in a single prompt.
These capabilities emerge from a single unified neural network that can see, hear, and read simultaneously.
But how does a single AI system understand such fundamentally different types of data? In this article, we try to answer this question.
Cut Complexity and Drive Growth with Automation (Sponsored)

What if you could spend most of your IT resources on innovation, not maintenance?
The latest report from the IBM Institute for Business Value explores how businesses are using intelligent automation to get more out of their technology, drive growth & cost the cost of complexity.
A Shared Mathematical Language
The core breakthrough behind multimodal LLMs is quite simple. Every type of input, whether text, images, or audio, gets converted into the same type of mathematical representation called embedding vectors. Just as human brains convert light photons, sound waves, and written symbols into uniform neural signals, multimodal LLMs convert diverse data types into vectors that occupy the same mathematical space.
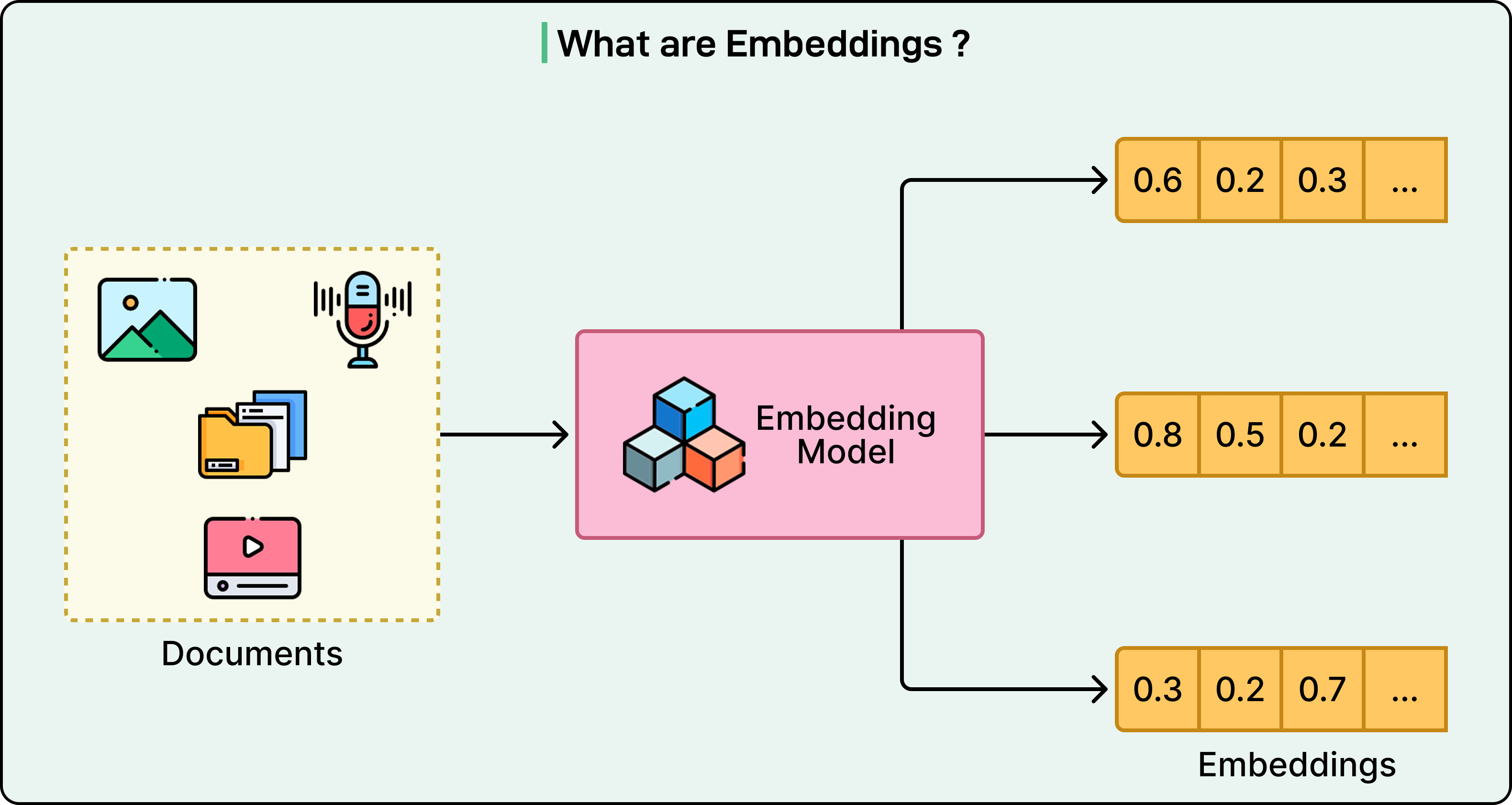
Let us consider a concrete example. A photograph of a dog, the spoken word “dog,” and the written text “dog” all get transformed into points in a high-dimensional mathematical space. These points cluster together, close to each other, because they represent the same concept.
This unified representation enables what researchers call cross-modal reasoning. The model can understand that a barking sound, a photo of a golden retriever, and the sentence “the dog is happy” all relate to the same underlying concept. The model doesn’t need separate systems for each modality. Instead, it processes everything through a single architecture that treats visual patches and audio segments just like text tokens.
The Three-Part Architecture: Building Blocks of Multimodal LLM
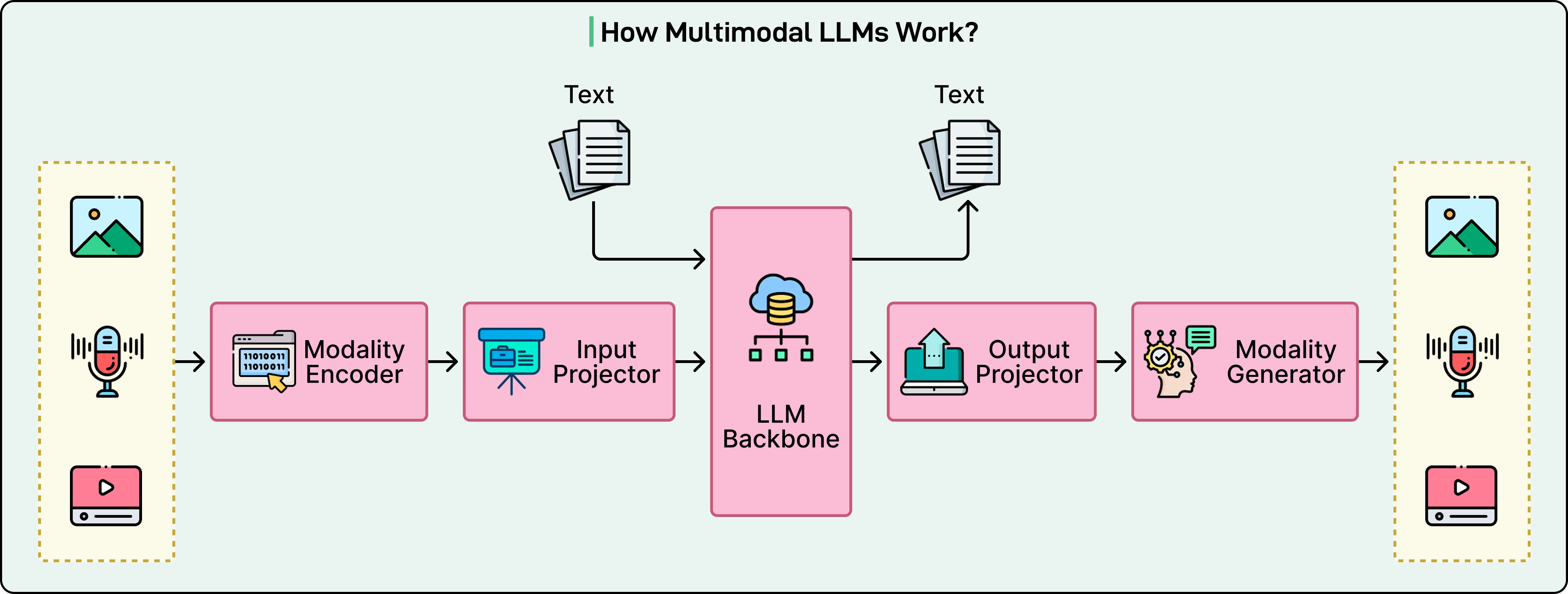
The diagram below shows the high-level view of a multimodal LLM works:
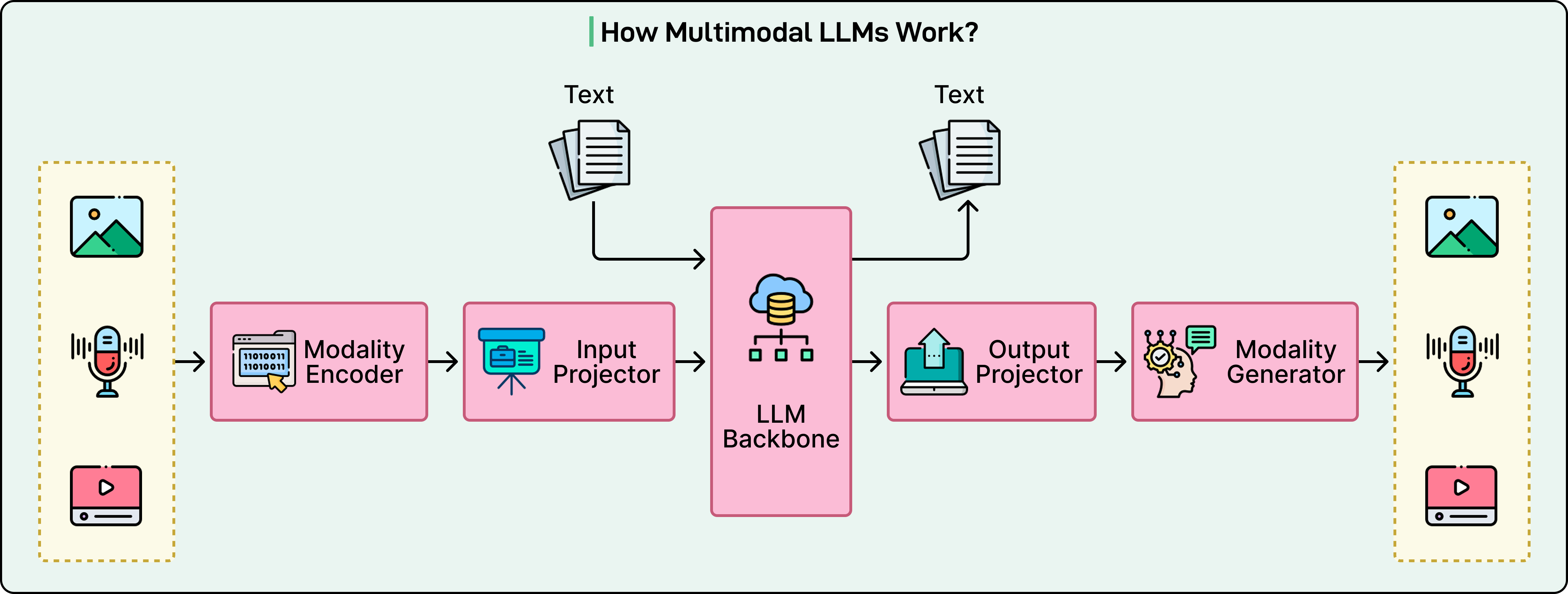
Modern multimodal LLMs consist of three essential components working together to process diverse inputs.
Modality-Specific Encoders
The first component handles the translation of raw sensory data into initial mathematical representations.
Vision Transformers process images by treating them like sentences, dividing photographs into small patches and processing each patch as if it were a word.
Audio encoders convert sound waves into spectrograms, which are visual-like representations showing how frequencies change over time.
These encoders are typically pre-trained on massive datasets to become highly skilled at their specific tasks.
Projection Layers: The Translator
The second component acts as a bridge. Even though both encoders produce vectors, these vectors exist in different mathematical spaces. In other words, the vision encoder’s representation of “cat” lives in a different geometric region than the language model’s representation of the word “cat.”
Projection layers align these different representations into the shared space where the language model operates. Often, these projectors are surprisingly simple, sometimes just a linear transformation or a small two-layer neural network. Despite their simplicity, they’re crucial for enabling the model to understand visual and auditory concepts.
Language Model Backbone
The third component is the core LLM, such as GPT or LLaMA.
This is the “brain” that does the actual reasoning and generates responses. It receives all inputs as sequences of tokens, whether those tokens originated from text, image patches, or audio segments.
The language model treats them identically, processing everything through the same transformer architecture that powers text-only models. This unified processing is what allows the model to reason across modalities as naturally as it handles pure text.
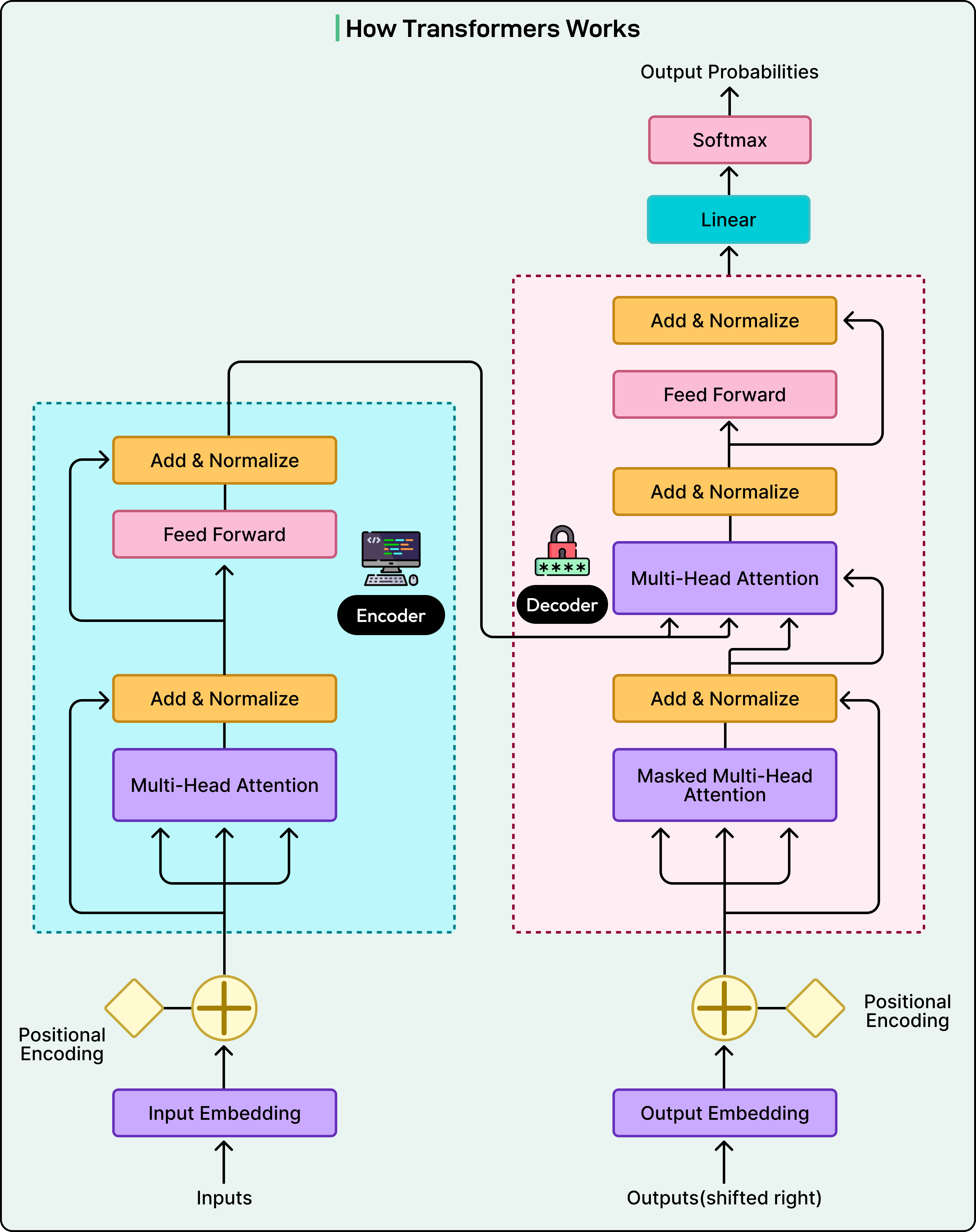
See the diagram below that shows the transformers architecture:
How Images Become Something an LLM Can Understand
The breakthrough that enabled modern multimodal vision came from a 2020 paper with a memorable title: “An Image is Worth 16x16 Words.” This paper introduced the idea of processing images exactly like sentences by treating small patches as tokens.
The process works through several steps:
First, the image gets divided into a grid of fixed-size patches, typically 16x16 pixels each.
A standard 224x224 pixel image becomes approximately 196 distinct patches, each representing a small square region.
Each patch is flattened from a 2D grid into a 1D vector of numbers representing pixel intensities.
Positional embeddings are added so the model knows where each patch came from in the original image.
These patch embeddings flow through transformer layers, where attention mechanisms allow patches to learn from each other.
The attention mechanism is where understanding emerges. A patch showing a dog’s ear learns it connects to nearby patches showing the dog’s face and body. Patches depicting a beach scene learn to associate with each other to represent the broader context of sand and water. By the final layer, these visual tokens carry rich contextual information. The model doesn’t just see “brown pixels” but understands “golden retriever sitting on beach.”
OpenAI CLIP
The second critical innovation was CLIP, developed by OpenAI. CLIP revolutionized how vision encoders are trained by changing the fundamental objective. Instead of training on labeled image categories, CLIP was trained on 400 million pairs of images and their text captions from the internet.
CLIP uses a contrastive learning approach. Given a batch of image-text pairs, it computes embeddings for all images and all text descriptions. The goal is to maximize the similarity between embeddings of correct image-text pairs while minimizing similarity between incorrect pairings. An image of a dog should produce a vector close to the caption “a dog in the park” but far from “a plate of pasta.”
How Audio Becomes Understandable
Audio presents unique challenges for language models.
Unlike text, which naturally divides into discrete words, or images, which can be divided into spatial patches, sound is continuous and temporal. For example, a 30-second audio clip sampled at 16,000 Hz contains 480,000 individual data points. Feeding this massive stream of numbers directly into a transformer is computationally impossible and inefficient. The solution requires converting audio into a more tractable representation.
The key innovation is transforming audio into spectrograms, which are essentially images of sound. The process involves several mathematical transformations:
The long audio signal gets sliced into tiny overlapping windows, typically 25 milliseconds each.
A Fast Fourier Transform extracts which frequencies are present in each window
These frequencies are mapped onto the mel scale, which matches human hearing sensitivity by giving more resolution to lower frequencies
The result is a 2D heat map where time runs along one axis, frequency along the other, and color intensity represents volume
This mel-spectrogram looks like an image to the AI model. For a 30-second clip, this might produce an 80x3,000 grid, which is essentially a visual representation of acoustic patterns that can be processed similarly to photographs.
Once audio is converted to a spectrogram, models can apply the same techniques used for vision. The Audio Spectrogram Transformer divides the spectrogram into patches, just as an image is divided. For example, models like Whisper, trained on 680,000 hours of multilingual audio, excel at this transformation.
The Training Process
The training process goes through different stages:
Stage 1: Feature Alignment
Training a multimodal LLM typically happens in two distinct stages.
The first stage focuses purely on alignment, teaching the model that visual and textual representations of the same concept should be similar. During this stage, both the pre-trained vision encoder and the pre-trained language model remain frozen. Only the projection layer’s weights get updated through training.
Stage 2: Visual Instruction Tuning
Alignment alone isn’t sufficient for practical use. A model might describe what’s in an image but fail at complex tasks like “Why does the person look sad?” or “Compare the two charts”.
Visual instruction tuning addresses this by training the model to follow sophisticated multimodal instructions.
During this stage, the projection layer continues training and the language model is also updated, often using parameter-efficient methods. The training data shifts to instruction-response datasets formatted as conversations.
An important innovation here was using GPT-4 to generate synthetic training data. Researchers fed GPT-4 textual descriptions of images and prompted it to create realistic conversations about those images. Training on this synthetic but high-quality data effectively distills GPT-4’s reasoning capabilities into the multimodal model, teaching it to engage in nuanced visual dialogue rather than just describing what it sees.
Conclusion
Multimodal LLMs achieve their remarkable capabilities through a unifying principle. By converting all inputs into sequences of embedding vectors that occupy a shared mathematical space, a single transformer architecture can reason across modalities as fluidly as it processes language alone.
The architectural innovations powering this capability represent genuine advances: Vision Transformers treating images as visual sentences, contrastive learning aligning modalities without explicit labels, and cross-attention enabling selective information retrieval across different data types.
The future points toward any-to-any models that can both understand and generate all modalities. In other words, a model that outputs text, generates images, and synthesizes speech in a single response.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
The embedding space insight is crucial. What helped me understand this better was realizing that tokenization for images is fundamentally different than text, yet they converge to the same semantic space. Makes you wonder how this will scale once we add more modalities.
Helpful