
EP11: New System Design YouTube channel

*BIG* announcement: we’ve launched a YouTube channel!
The first video is already live and we'll try to post new videos weekly.
Subscribe to our YouTube Channel: https://bit.ly/ByteByteGoVideos

Our goal is to explain complex systems in an easy-to-understand way. These videos will be short at first, and we intend to move to produce longer videos on how different systems work, soon.
We'll be covering a wide range of topics including:
🔹 What happens when you type a URL into your browser?
🔹 HTTPs illustrated
🔹 How to avoid double charge?
🔹 Why is Kafka fast?
🔹How to choose the right database?
🔹REST vs GraphQL
🔹Design Facebook newsfeed
🔹Design WhatsApp
🔹Design a URL shortener
🔹Design Robinhood (stock trading app)
🔹Design a proximity service
🔹Design a distributed scheduler
🔹Design Google Docs
🔹And much more…
If you're interested in seeing more, make sure to subscribe to our YouTube channel:
https://bit.ly/ByteByteGoVideos
How does Disney Hotstar capture 5 Billion Emojis during a tournament?
Dedeepya Bonthu wrote an excellent engineering blog that captures this nicely. Here is my understanding of how the system works.
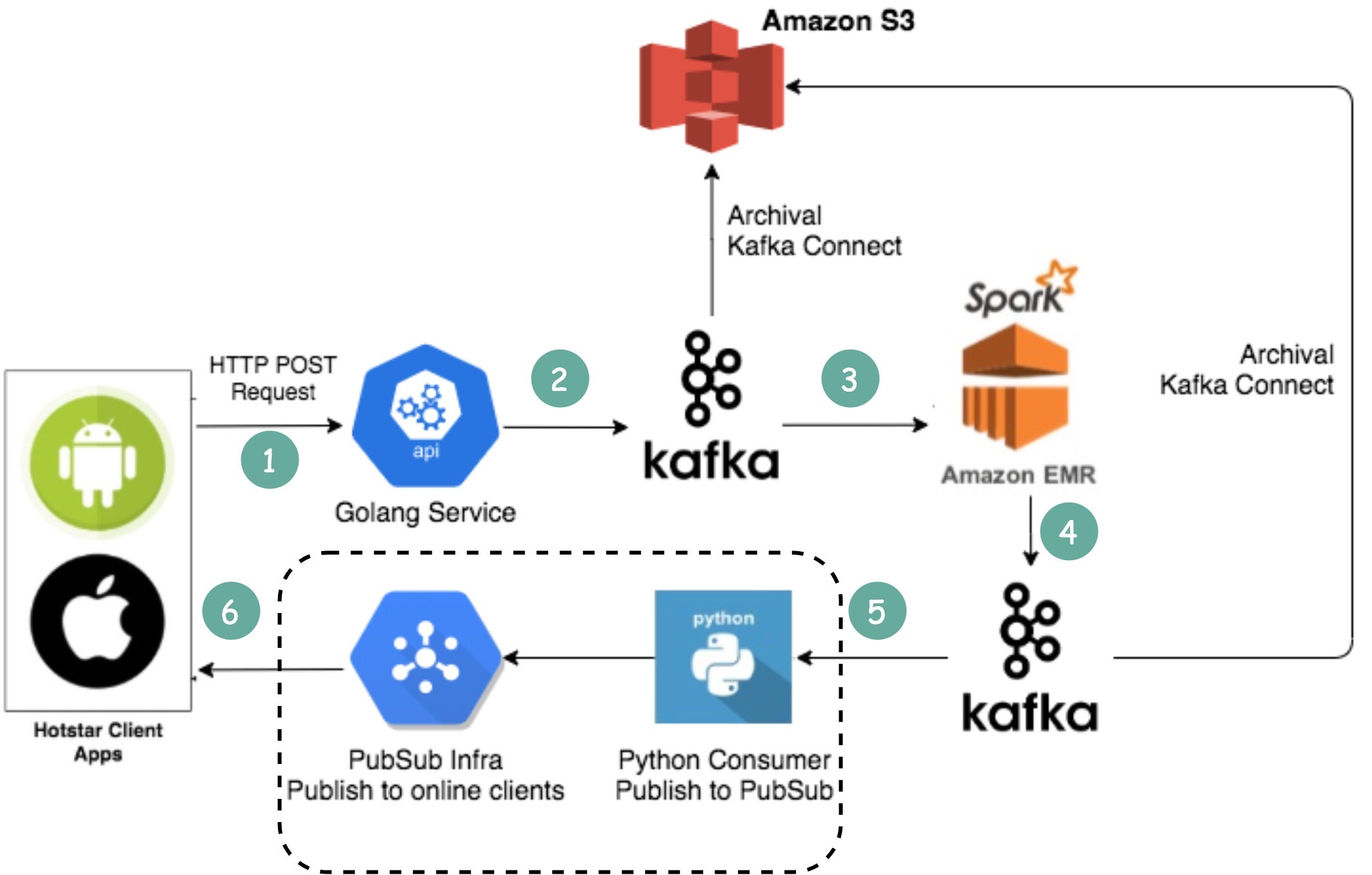
1. Clients send emojis through standard HTTP requests. You can think of Golang Service as a typical Web Server. Golang is chosen because it supports concurrency well. Threads in GoLang are lightweight.
2. Since the write volume is very high, Kafka (message queue) is used as a buffer.
3. Emoji data are aggregated by a streaming processing service called Spark. It aggregates data every 2 seconds, which is configurable. There is a trade-off to be made based on the interval. A shorter interval means emojis are delivered to other clients faster but it also means more computing resources are needed.
4. Aggregated data is written to another Kafka.
5. The PubSub consumers pull aggregated emoji data from Kafka.
6. Emojis are delivered to other clients in real-time through the PubSub infrastructure.
The PubSub infrastructure is interesting. Hotstar considered the following protocols: Socketio, NATS, MQTT, and gRPC, and settled with MQTT. For those who are interested in the tradeoff discussion, see [2].
A similar design is adopted by LinkedIn which streams a million likes/sec [3].
Over to you: What are some of the off-the-shelf Pub-Sub services available? Is there anything you would do differently in this design?
Sources:
[1] Capturing A Billion Emo(j)i-ons: https://lnkd.in/e24qZK2s
[2] Building Pubsub for 50M concurrent socket connections: https://lnkd.in/eKHqFeef
[3] Streaming a Million Likes/Second: Real-Time Interactions on Live Video: https://lnkd.in/eUthHjv4
Internationalization
How do we design a system for internationalization?
The diagram below shows how we can internationalize a simple e-commerce website.
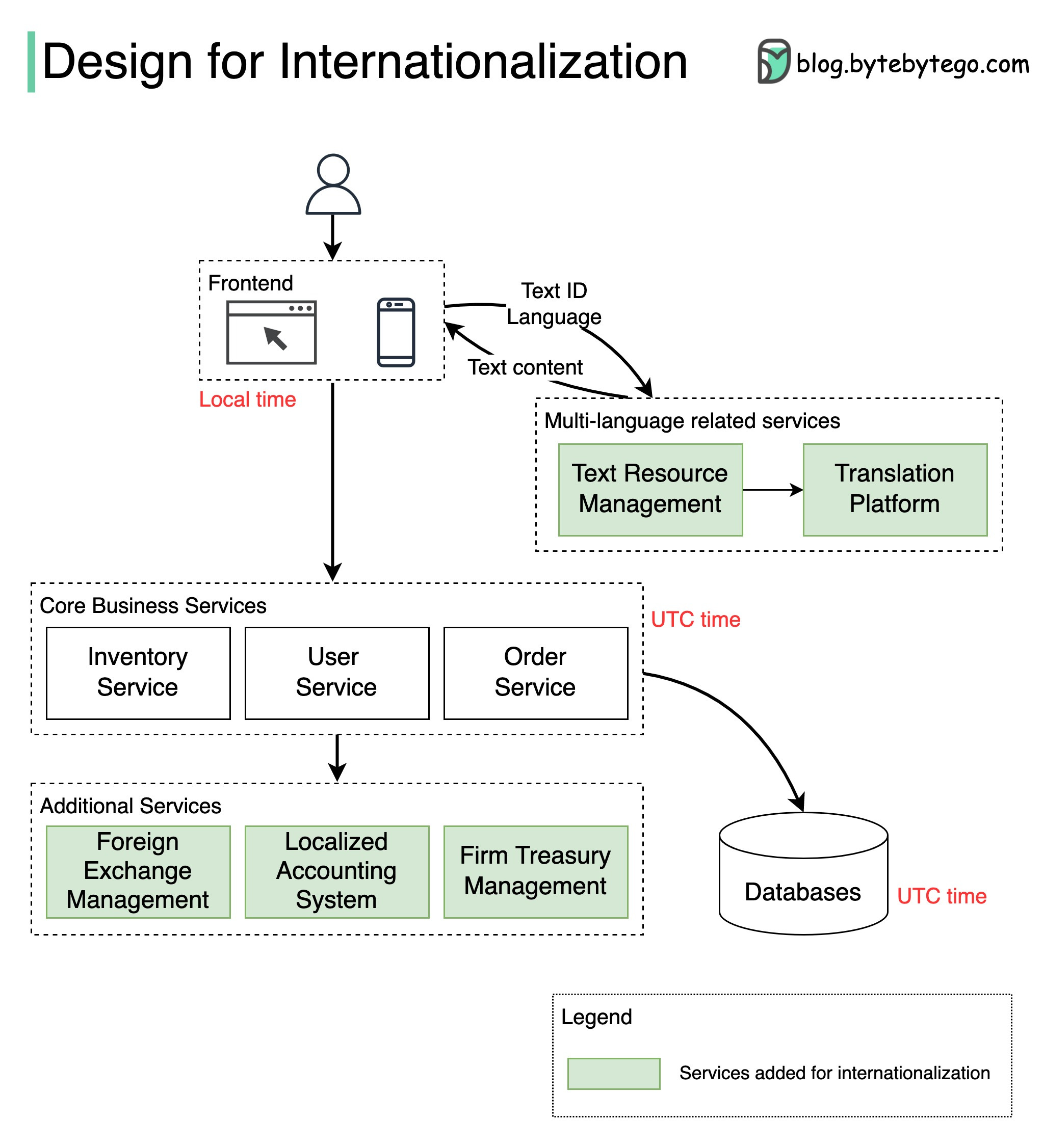
Different countries have differing cultures, values, and habits. When we design an application for international markets, we need to localize the application in several ways:
🔹 Language
1. Extract and maintain all texts in a separate system. For example:
- We shouldn’t put any prompts in the source code.
- We should avoid string concatenation in the code.
- We should remove text from graphics.
2. Use complete sentences and avoid dynamic text elements
3. Display business data such as currencies in different languages
🔹 Layout
1. Describe text length and reserve enough space around the text for different languages.
2. Plan for line wrap and truncation
3. Keep text labels short on buttons
4. Adjust the display for numerals, dates, timestamps, and addresses
🔹 Time zone
The time display should be segregated from timestamp storage.
Common practice is to use the UTC (Coordinated Universal Time) timestamp for the database and backend services and to use the local time zone for the frontend display.
🔹 Currency
We need to define the displayed currencies and settlement currency. We also need to design a foreign exchange service for quoting prices.
🔹 Company entity and accounting
Since we need to set up different entities for individual countries, and these entities follow different regulations and accounting standards, the system needs to support multiple bookkeeping methods. Company-level treasury management is often needed. We also need to extract business logic to account for different usage habits in different countries or regions.
Over to you: which tools have you used for managing multi-language texts? Which do you like best, and which would you not recommend to a friend?
How does the browser render a web page?
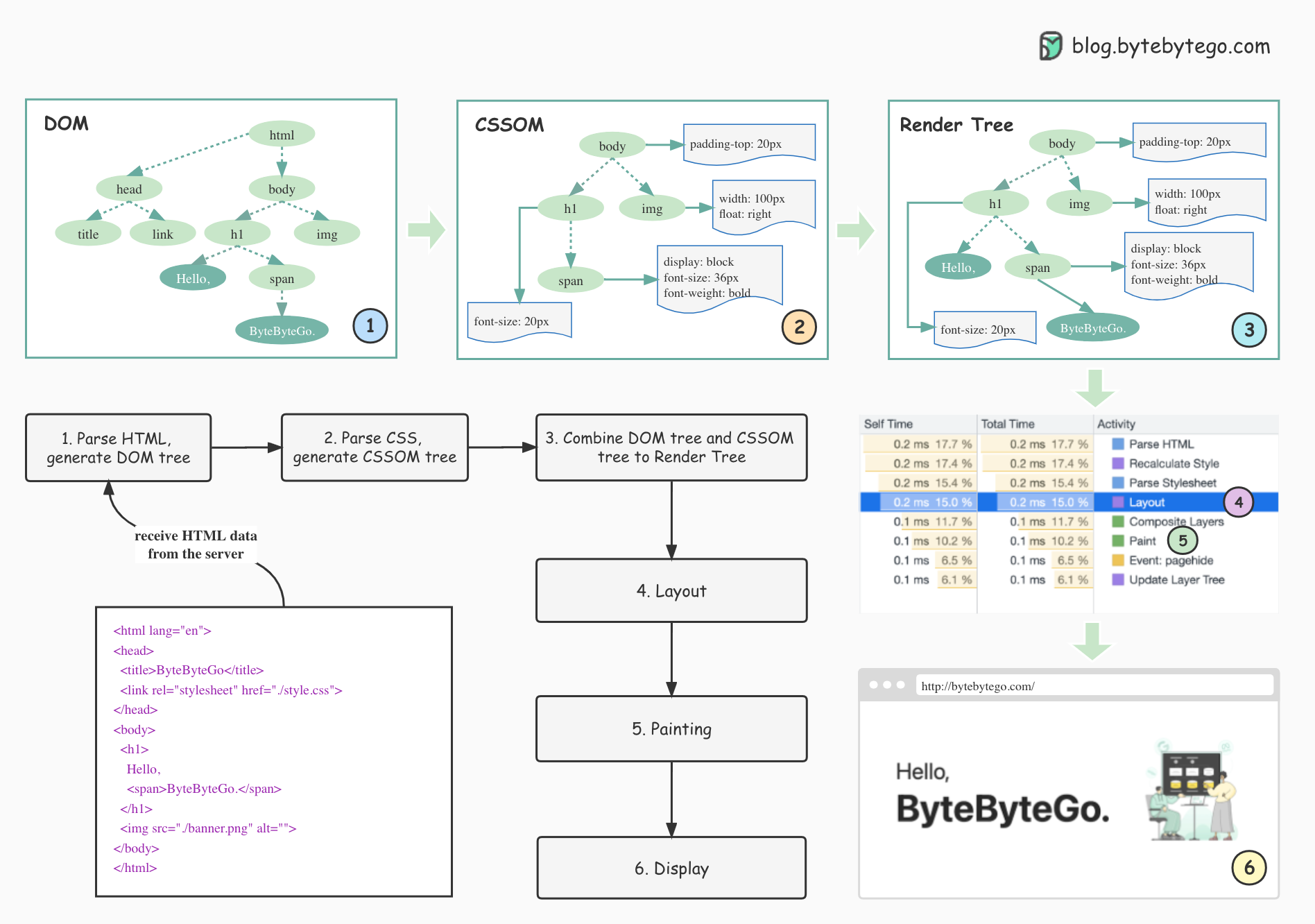
1. Parse HTML and generate Document Object Model (DOM) tree
When the browser receives the HTML data from the server, it immediately parses it and converts it into a DOM tree.
2. Parse CSS and generate CSSOM tree
The styles (CSS files) are loaded and parsed to the CSSOM (CSS Object Model).
3. Combine DOM tree and CSSOM tree to construct the Render Tree
With the DOM and CSSOM, a rendering tree will be created. The render tree maps all DOM structures except invisible elements (such as <head> or tags with display:none; ). In other words, the render tree is a visual representation of the DOM.
4. Layout
The content in each element of the rendering tree will be calculated to get the geometric information (position, size), which is called layout.
5. Painting
After the layout is complete, the rendering tree is transformed into the actual content on the screen. This step is called painting. The browser gets the absolute pixels of the content.
6. Display
Finally, the browser sends the absolute pixels to the GPU, and displays them on the page.
Popular interview question: what’s the difference between Inner, Left, Right, and Full join?
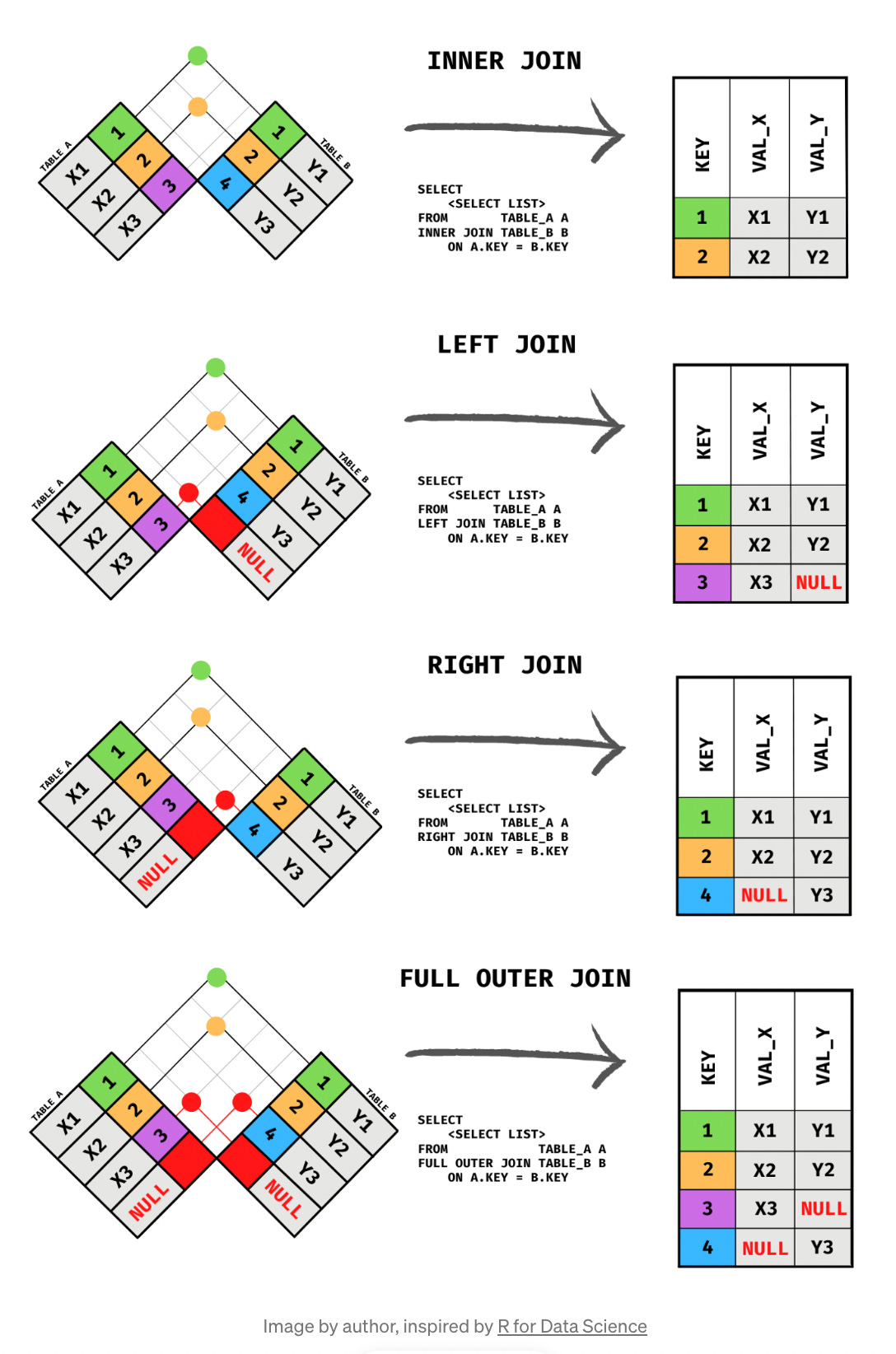
The diagram below illustrates how different types of joins work.
(INNER) JOIN: returns only matching rows between both tables.
LEFT (OUTER) JOIN: returns all matching rows, and non-matching rows from the left table.
RIGHT (OUTER) JOIN: returns all the matching rows, and non-matching rows from the right table.
FULL (OUTER) JOIN: returns all the rows from both left and right tables, including non-matching rows.
HTTP error handling
How do we properly deal with HTTP errors on the browser side? And how do you handle them correctly on the server side when the client side is at fault?

From the browser's point of view, the easiest thing to do is to try again and hope the error just goes away. This is a good idea in a distributed network, but we also have to be very careful not to make things worse. Here’s two general rules:
1. For 4XX http error code, do not retry.
2. For 5XX http error code, try again carefully.
So which things should we do carefully in the browser? We definitely should not overwhelm the server with retried requests. An algorithm named exponential backoff might be able to help. It controls two things:
1. The latency between two retries. The latency will increase exponentially.
2. The number of retries is usually capped.
Will all browsers handle their retry logic in a graceful way? Most likely not. So the server has to take care of its own safety. A common way to control the flow of HTTP requests is to set up a flow control gateway in front of the server. This provides two useful tools:
1. Rate limiter, which limits how often a request can be made. It has two slightly different choices; the token bucket and the leaky bucket.
2. Circuit breaker. This will stop the HTTP flow immediately when the error threshold is exceeded. After a set amount of time, it will only let a limited amount of HTTP traffic through. If everything works well, it will slowly let all HTTP traffic through.
We should be able to handle intermittent errors effectively with exponential backoff in the browser and with a flow control gateway on the server side. Any remaining issues are real errors that need to be fixed carefully.
Over to you: Both token bucket and leaky bucket can be used for rate limiting. How do you know which one to pick?
Other things we made:
Our bestselling book “System Design Interview - An Insider’s Guide” is available in both paperback and digital format.
Paperback edition: https://geni.us/XxCd
Digital edition: https://bit.ly/3lg41jK
New System Design YouTube channel: https://bit.ly/ByteByteGoVideos