
Nextdoor’s Database Evolution: A Scaling Ladder

New Year, New Metrics: Evaluating AI Search in the Agentic Era (Sponsored)

Most teams pick a search provider by running a few test queries and hoping for the best – a recipe for hallucinations and unpredictable failures. This technical guide from You.com gives you access to an exact framework to evaluate AI search and retrieval.
What you’ll get:
A four-phase framework for evaluating AI search
How to build a golden set of queries that predicts real-world performance
Metrics and code for measuring accuracy
Go from “looks good” to proven quality.
Nextdoor operates as a hyper-local social networking service that connects neighbors based on their geographic location.
The platform allows people to share local news, recommend local businesses, and organize neighborhood events. Since the platform relies on high-trust interactions within specific communities, the data must be both highly available and extremely accurate.
However, as the service scaled to millions of users across thousands of global neighborhoods, the underlying database architecture had to evolve from a simple setup into a sophisticated distributed system.
This engineering journey at Nextdoor highlights a fundamental rule of system design.
Every performance gain introduces a new requirement for data integrity. The team followed a predictable progression, moving from a single database instance to a complex hierarchy of connection poolers, read replicas, versioned caches, and background reconcilers. In this article, we will look at how the Nextdoor engineering team handled this evolution and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the Nextdoor Engineering Team. Please comment if you notice any inaccuracies.
The Limits of the “Big Box”
In the early days, Nextdoor relied on a single PostgreSQL instance to handle every post, comment, and neighborhood update.
For many growing platforms, this is the most logical starting point. It is simple to manage, and PostgreSQL provides a robust engine capable of handling significant workloads. However, as more neighbors joined and the volume of simultaneous interactions grew, the team hit a wall that was not related to the total amount of data stored, but more to do with the connection limit.
PostgreSQL uses a process-per-connection model. In other words, every time an application worker wants to talk to the database, the server creates a completely new process to handle that request. If an application has five thousand web workers trying to access the database at the same time, the server must manage five thousand separate processes. Each process consumes a dedicated slice of memory and CPU cycles just to exist.
Managing thousands of processes creates a massive overhead for the operating system. The server eventually spends more time switching between these processes than it does running the actual queries that power the neighborhood feed. This is often the point where vertical scaling, or buying a larger server with more cores, starts to show diminishing returns. The overhead of the “process-per-connection” model remains a bottleneck regardless of how much hardware is thrown at the problem.
To solve this, Nextdoor introduced a layer of middleware called PgBouncer. This is a connection pooler that sits between the application and the database. Instead of every application worker maintaining its own dedicated line to the database, they all talk to PgBouncer.
The Request Phase: A web worker requests a connection from PgBouncer to execute a quick query.
The Assignment Phase: PgBouncer assigns an idle connection from its pre-established pool rather than forcing the database to create a new process.
The Execution Phase: The query runs against the database using that shared connection.
The Release Phase: The worker finishes its task, and the connection returns to the pool immediately for the next worker to use.
This allows thousands of application workers to share a few hundred “warm” database connections. This effectively removed the connection bottleneck and allowed the primary database to focus entirely on data processing.
Dividing the Labor and the “Lag” Problem
Once connection management was stable, the next bottleneck appeared in the form of read traffic.
In a social network like Nextdoor, the ratio of people reading the feed compared to people writing a post is heavily skewed. For every one person who saves a new neighborhood update, hundreds of others might view it. A single database server must handle both the “Writes” and the “Reads” at the same time. This creates resource contention where heavy read queries can slow down the ability of the system to save new data.
The solution was to move to a Primary-Replica architecture. In this setup, one database server is designated as the Primary. It is the only server allowed to modify or change data. Several other servers, known as Read Replicas, maintain copies of the data from the Primary. All the “Read” traffic from the application is routed to these replicas, while only the “Write” traffic goes to the Primary.
See the diagram below:
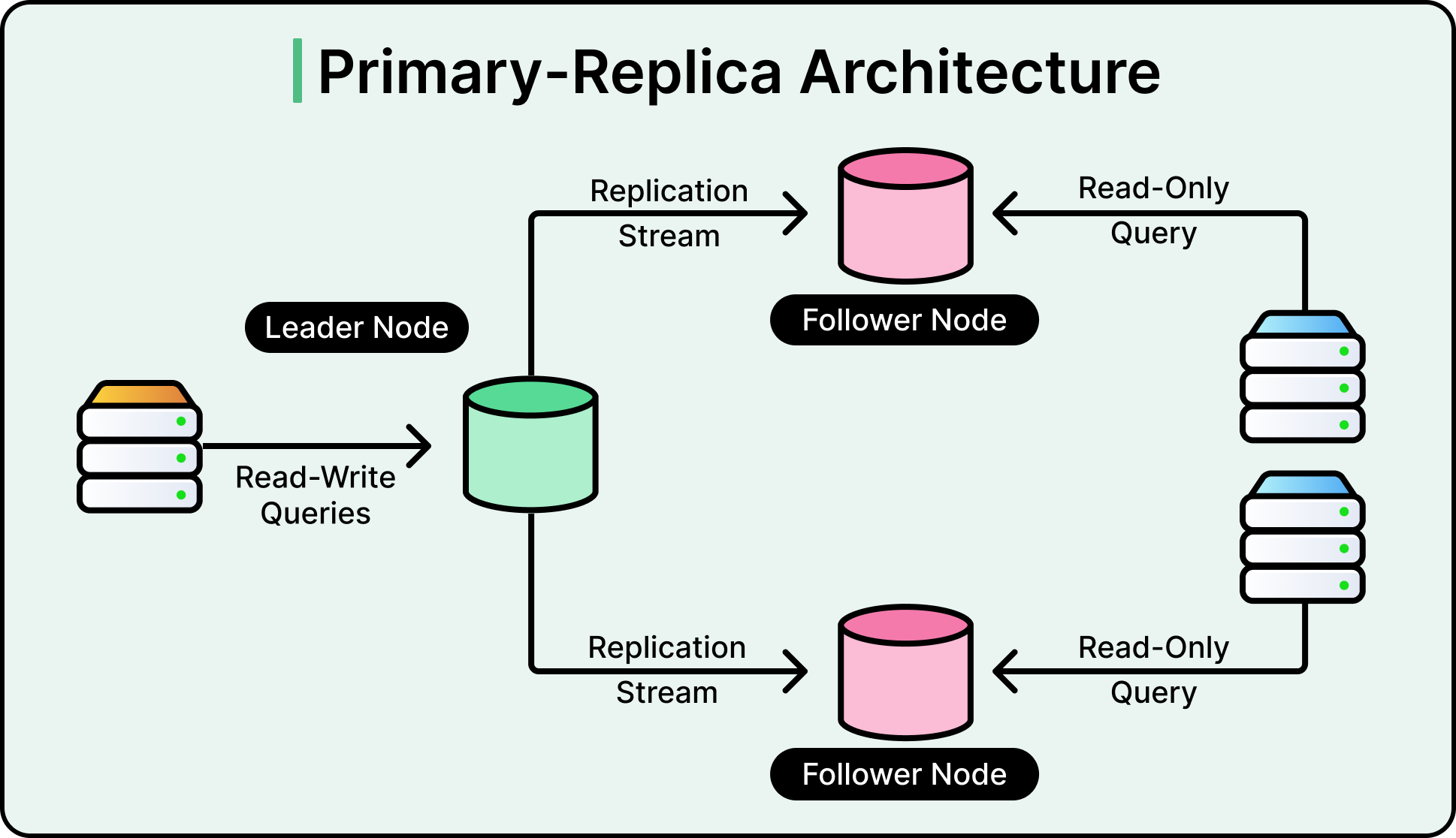
This separation of labor allows for massive horizontal scaling of reads. However, this introduces the challenge of Asynchronous Replication. The Primary database sends its changes to the replicas using a stream of logs. It takes time for a new post saved on the Primary to travel across the network and appear on the replicas. This delay is known as replication lag.
See the diagram below that shows the difference between synchronous and asynchronous replication:
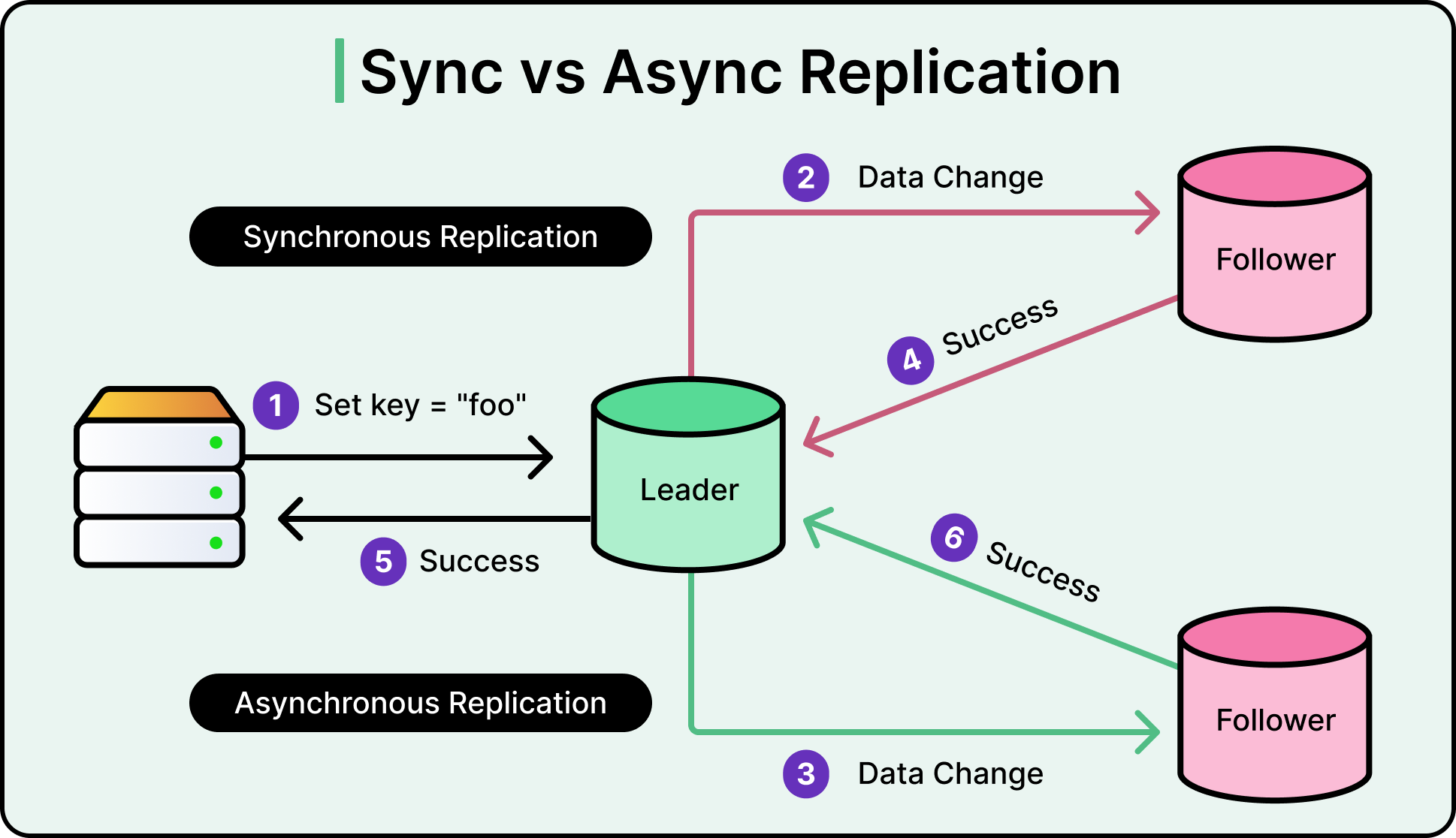
To solve the issue of a neighbor making a post and then seeing it disappear upon a refresh, Nextdoor uses Time-Based Dynamic Routing. This is a smart routing logic that ensures users always see the results of their own actions. Here’s how it works:
The Write Marker: When a user performs a write action, like posting a comment, the application notes the exact timestamp of that event.
The Protected Window: For a specific period of time after that write, often a few seconds, the system treats that specific user as sensitive
Dynamic Routing: During this window, all read requests from that user are dynamically routed to the Primary database instead of a replica.
The Handover: Once the time window expires and the system is confident the replicas have caught up with the Primary, the user’s traffic is routed back to the replicas to save resources.
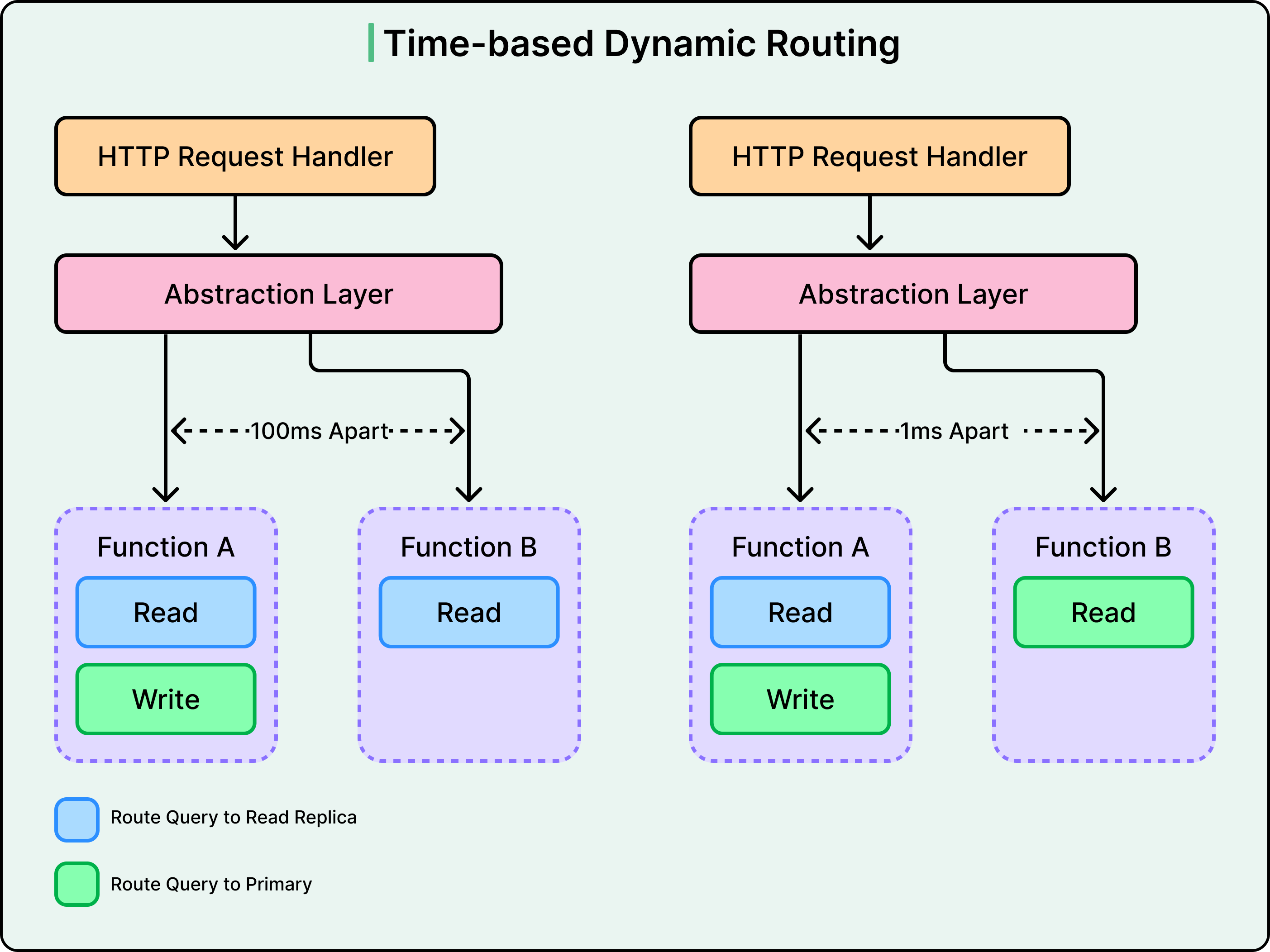
This ensures that while the general neighborhood sees eventually consistent data, the person who made the change always sees strongly consistent data.
Why writing code isn’t the hard part anymore (Sponsored)

Coding is no longer the bottleneck, it’s prod.
With the rise in AI coding tools, teams are shipping code faster than they can operate it. And production work still means jumping between fragmented tools, piecing together context from systems that don’t talk to each other, and relying on the few engineers who know how everything connects.
Leading teams like Salesforce, Coinbase, and Zscaler cut investigation time by over 80% with Resolve AI, using multi-agent investigation that works across code, infrastructure, and telemetry.
Learn how AI-native engineering teams are implementing AI in their production systems
The High-Speed Library
Even with multiple replicas, hitting a database for every single page load is an expensive operation.
Databases must read data from a disk or a large memory pool and often perform complex joins between different tables to assemble a single record. To provide the millisecond response times neighbors expect, Nextdoor implemented a caching layer using Valkey. This is an open-source high-performance data store that holds information in RAM for near-instant access.
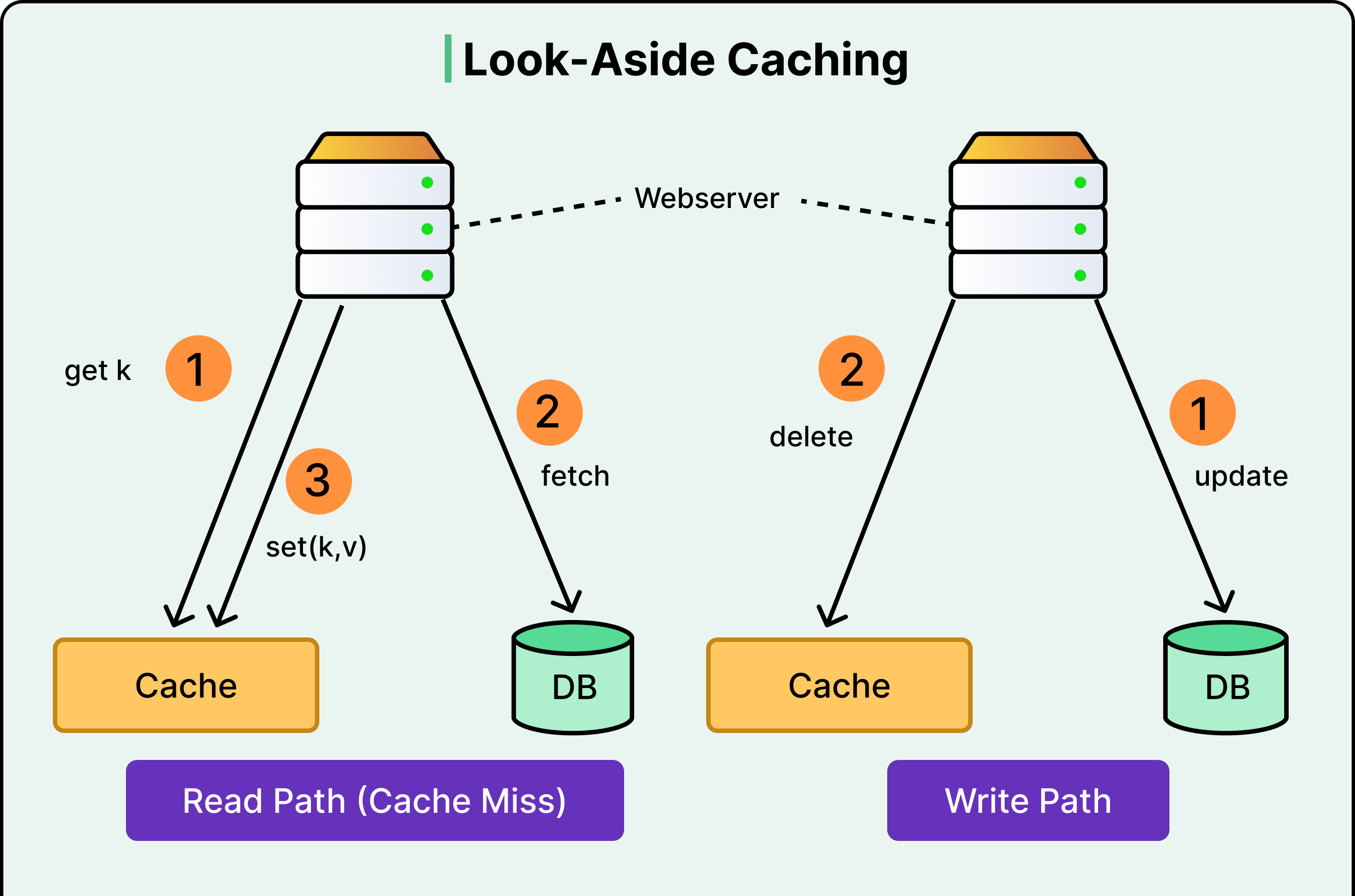
The team uses a Look-aside Cache pattern. When the application needs data, it follows a specific sequence:
The Cache Check: The application looks for the data in Valkey using a unique key.
The Cache Hit: If the data is found, it is returned instantly to the user without touching the database.
The Cache Miss: If the data is missing, the application queries the PostgreSQL database to find the truth.
The Population Step: The application takes the database result, saves a copy in Valkey for future requests, and then returns it to the user.
Efficiency is vital when managing a cache at this scale. RAM is much more expensive than disk storage, so the data must be as small as possible.
Nextdoor uses a binary serialization format called MessagePack. In other words, instead of storing data as a bulky text format like JSON, they convert it into a highly compressed binary format that is much faster for the computer to parse.
MessagePack is particularly useful for Nextdoor because it supports schema evolution. If the engineering team adds a new field to a neighbor’s profile, the older cached data can still be read without crashing the application. For even larger pieces of data, they use Zstd compression. By combining these two tools, Nextdoor reduces the memory footprint of its cache servers.
Versioning and Atomic Updates
Caching can create a serious problem when it starts lying in particular scenarios. For example, if the database is updated but the cache is not refreshed, users can see old, incorrect information. Most simple caching strategies rely on a “Time to Live” or TTL. This is a timer that tells the cache to delete an entry after a few minutes. For a real-time social network, waiting several minutes for a post to update is not an acceptable solution.
Nextdoor built a sophisticated versioning engine to ensure the cache stays up to date. They added a special column called system_version to their database tables and used PostgreSQL Triggers to manage this number. For reference, a trigger is a small script that runs automatically inside the database whenever a row is touched. Every time a post is updated, the trigger increments the version number. This ensures that the database remains the ultimate source of truth regarding which version of a post is the newest.
When the application tries to update the cache, it does not just overwrite the old data. It uses a Lua script executed inside Valkey. This script performs an atomic Compare and set operation that works as follows:
The Metadata Fetch: The script retrieves the version number currently stored in the cache entry.
The Version Comparison: It compares the version to the version number of the new update being sent by the application.
The Conditional Write: If the new version is strictly greater than the cached version, the update is saved.
The Rejection: If the cached version is already equal to or higher than the new update, the script rejects the change entirely.
This prevents “race conditions.” Imagine two different servers trying to update the same post at the same time. Without this logic, an older update could arrive a millisecond later and overwrite a newer update. This would leave the cache permanently out of sync with the database. By using Lua, the entire process of checking the version and updating the data happens as a single, unbreakable step that cannot be interrupted.
CDC and Reconciliation
Even with versioning and Lua scripts, errors can occur.
A network partition might prevent a cache update from reaching Valkey, or an application process might crash before it can finish the population step. Nextdoor needed a final safety net to catch these discrepancies. They implemented Change Data Capture, also known as CDC, using a tool called Debezium.
See the diagram below:
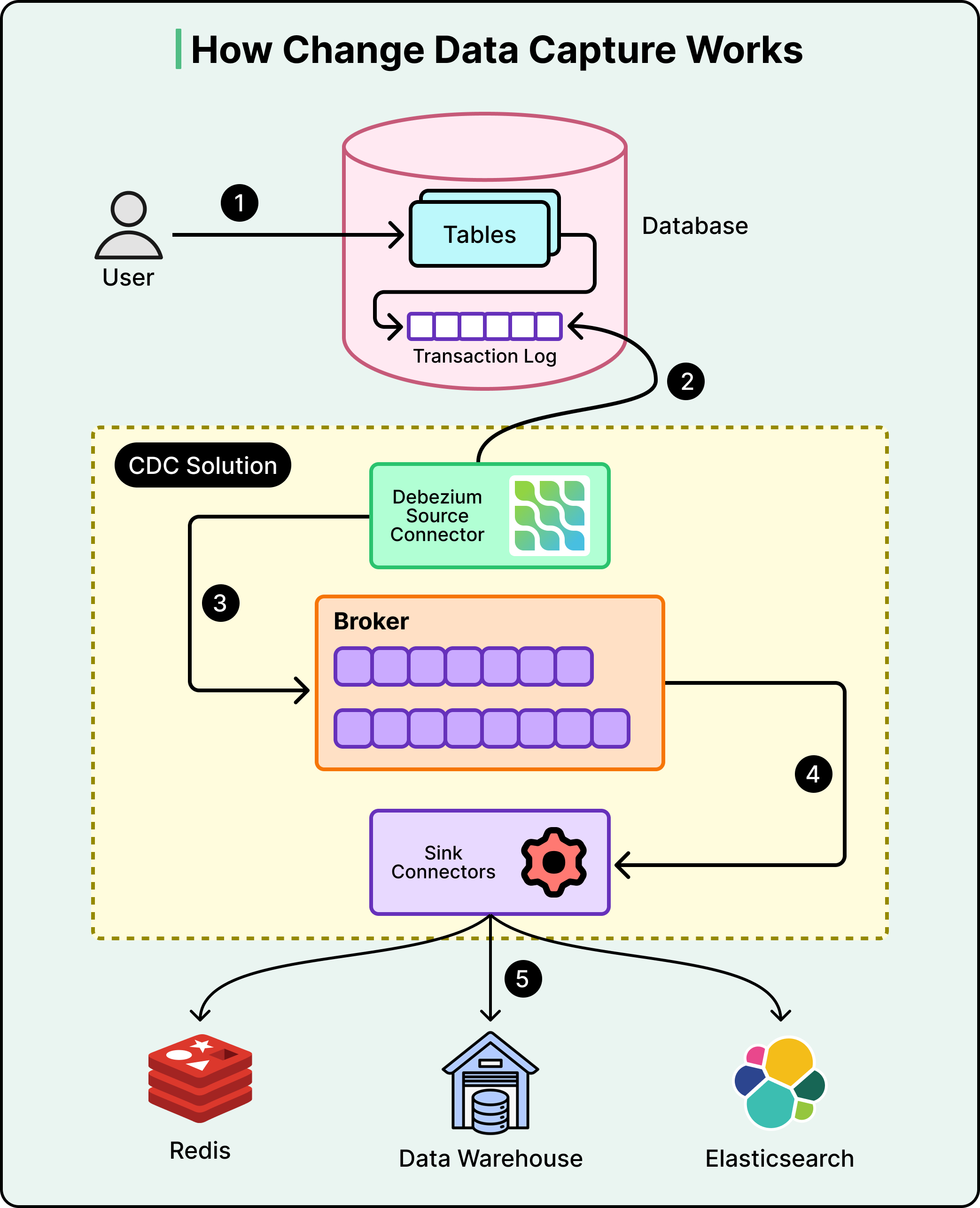
CDC works by “listening” to the internal logs of the PostgreSQL database. Specifically, it watches the Write-Ahead Log, where every single change is recorded before it is committed. Every time a change happens in the database, Debezium captures that event and turns it into a message in a data stream. A background service known as the Reconciler watches this stream.
The reconciliation flow provides a “self-healing” mechanism for the entire setup:
The Database Update: A user updates their neighborhood bio in the Primary PostgreSQL database.
The Log Capture: Debezium detects the new log entry and publishes a change event message.
The Reconciler Action: The background service receives this message and identifies which cache key needs to be corrected.
The Invalidation: The service tells the cache to delete the old entry. The next time a neighbor requests that bio, the application will experience a “Cache Miss” and fetch the perfectly fresh data from the database.
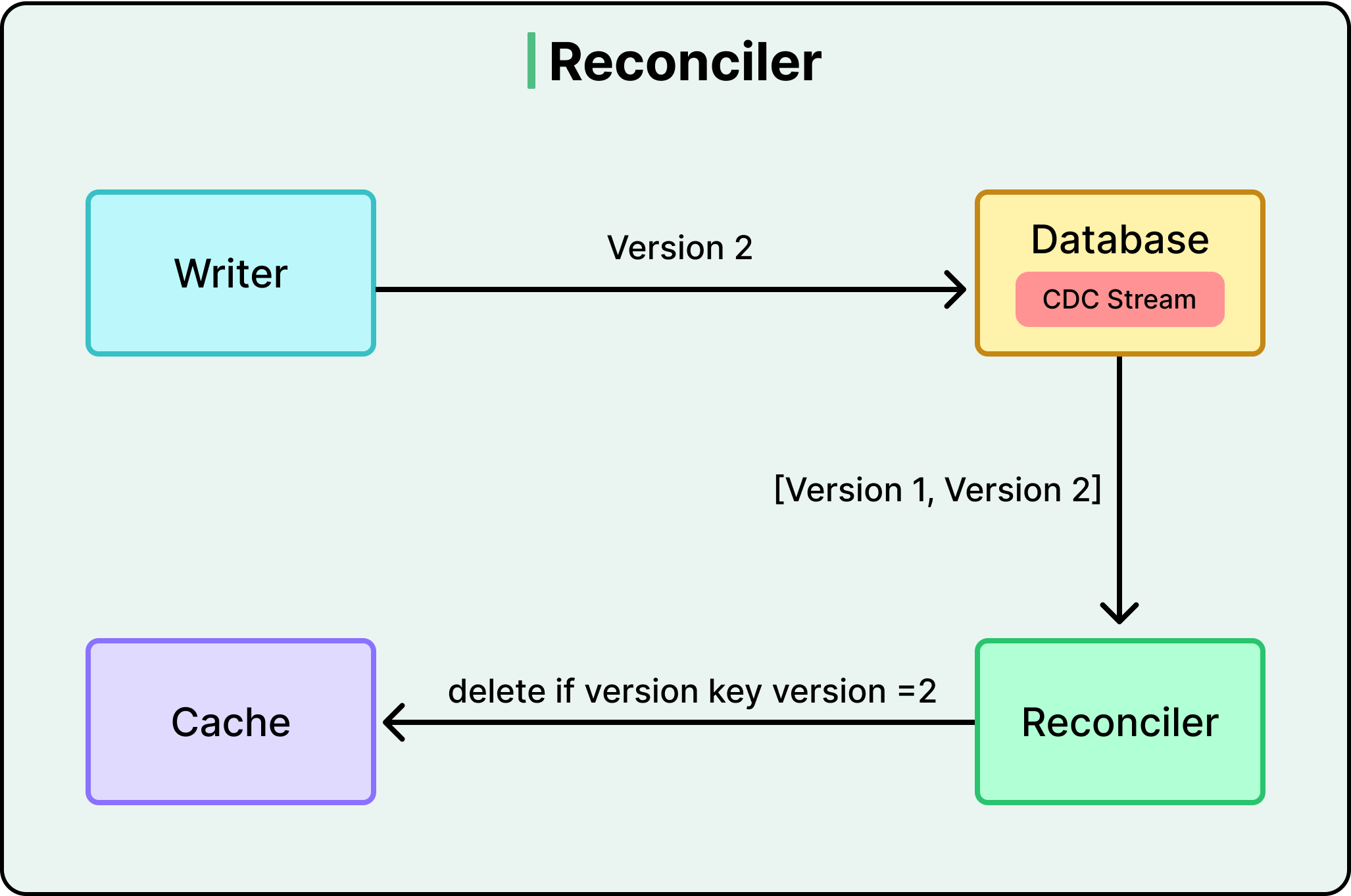
This process provides eventual consistency. While the primary cache update might fail for a fraction of a second, the CDC Reconciler will eventually detect the change and fix the cache. It acts like a detective that constantly audits the system to ensure the fast truth in the cache matches the real truth in the database.
Sharding
There comes a point where even the most optimized single Primary database cannot handle the volume of incoming writes. When a platform processes billions of rows, the hardware itself reaches physical limits. This is when Nextdoor moves to the final rung of the ladder. This rung is Sharding.
Sharding is the process of breaking a single, massive table into smaller pieces and spreading them across entirely different database clusters. Nextdoor typically shards data by a unique identifier such as a Neighborhood ID.
The Cluster Split: All data for Neighborhoods 1 through 500 might live on Cluster A, while Neighborhoods 501 through 1,000 live on Cluster B.
The Shard Key: The application uses the neighborhood_id to know exactly which database cluster to talk to for any given request.
Sharding allows for much greater scaling because we can keep adding more clusters based on growth. However, it comes at a high cost in complexity. Once we shard a database, we can no longer easily perform a “Join” between data on two different shards.
Conclusion
The journey of Nextdoor’s database shows that great engineering is rarely about choosing the most complex tool first. It is about a disciplined progression.
They started with a single server and added connection pooling when the lines got too long. They added replicas when the read traffic became too heavy. Finally, they built a world-class versioned caching system to provide the speed neighbors expect without sacrificing the accuracy they require.
The takeaway is that complexity must be earned. Each layer of the scaling ladder solves one problem while introducing a new challenge in data consistency. By building robust safety nets such as versioning and reconciliation, the Nextdoor engineering team ensured that its system could grow without losing the trust of the communities it serves.
References:
“Dynamic Routing: During this window, all read requests from that user are dynamically routed to the Primary database instead of a replica.”
I wonder how is that managed, it creates a strong coupling between the request, the database connection and the user performing an action.
What’s interesting is how every solution here creates a new kind of fragility. You solve for speed, and now you’re managing consistency. You solve for scale, and now you’re managing truth across layers.
At a certain point the system isn’t just storing data, it’s constantly negotiating what the “latest version of reality” actually is. And the more layers you add, the more that reality depends on everything working together at once.
That’s the quiet tradeoff with scale. It gets stronger and more delicate at the same time.