
Proof of Human: How to Verify a Person Is Real and Unique

In the age of AI, proving you are a human has become increasingly hard.
The defenses websites have relied on for years are failing in predictable ways, and the failure shows up most visibly in moments like the one below.
A popular retailer drops a thousand pairs of a limited-edition shoe at noon. Within thirty seconds, the inventory is gone. The buyers turn out to be automated agents working for resellers. The real people who wanted the shoes get nothing.
The retailer almost certainly tried the standard defenses: rate limits by IP, CAPTCHA, phone verification, device fingerprinting. Each of them helps for a while and then stops working. The reason they all fail in the same way is worth pausing on.
Every one of those defenses relies on a proxy for what the retailer actually wants to verify. An IP address is a proxy for a different network. A phone number is a proxy for a different person. A device fingerprint is a proxy for a different device. Each proxy fails the moment adversaries learn to acquire many of them cheaply, and adversaries always do. Phone numbers can be bought in bulk. Fingerprints can be randomized. IPs can be rotated through residential proxy networks. None of these strategies binds the verification to a real, unique person.
Authentication systems do not solve this either. Single sign-on, face unlock, passkeys, OAuth tokens, all of them compare an incoming credential against a stored template and return yes or no. None of them answers the question that actually matters here: has this user already been verified somewhere else in the world?
The central question: How do you let a real, unique human be recognized across the internet, without ever knowing who they are?
For this article we spoke with the team behind World, including Tiago Sada and Lily Gordon at Tools for Humanity, on how they try to solve this problem.
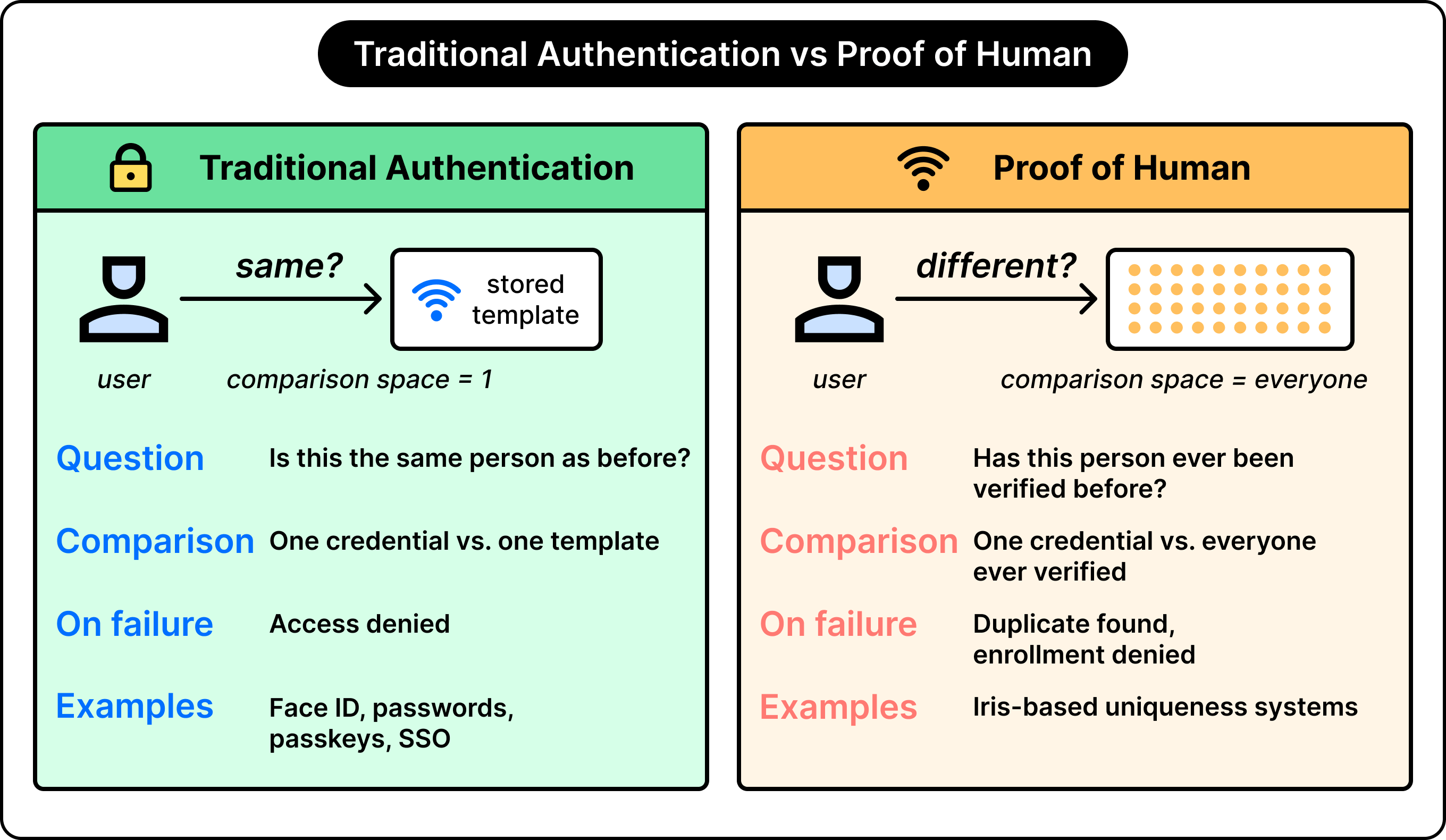
Five Pillars of a Proof-of-Human System
A working answer to the central question requires five distinct ingredients. We will look at each one in turn.
Uniqueness. Why is this a different identity problem than the ones we usually solve?
Anonymity. How can a credential be issued without anyone knowing the identity of the user?
Recovery. How does the system survive lost phones and reinstalled apps?
Verification. How does the holder present the credential without revealing more than necessary?
Delegation. What changes when the holder is an AI agent acting on a person’s behalf?
Pillar 1: Uniqueness
To see why uniqueness is structurally different from authentication, start with a system everyone already trusts: Face ID on a phone.
When the user sets up the phone, the camera captures a single facial template and stores it locally. From then on, every unlock attempt produces a fresh capture, which the phone compares against the stored template. The comparison space is exactly one. If the fresh capture matches the template within some tolerance, the phone unlocks. If not, the phone refuses. The system handles other faces by failing the match.
This is a one-to-one matching problem. The math is simple because the comparison is small. Even with a per-comparison error rate of one in a million, the phone unlocks reliably for its owner and refuses essentially every other face.
However, the example with the retailer wants a different guarantee. They want to verify, at checkout, that the buyer is different from every other person who has already bought those special edition shoes. The comparison is no longer against one template, but against the entire population of past buyers. If the system is meant to work at internet scale, the population is potentially every person on the planet.
This is a one-to-many matching problem, and the diagram below shows this comparison in the context of World ID. As you can notice, the math can get much more complex when the comparison space grows.
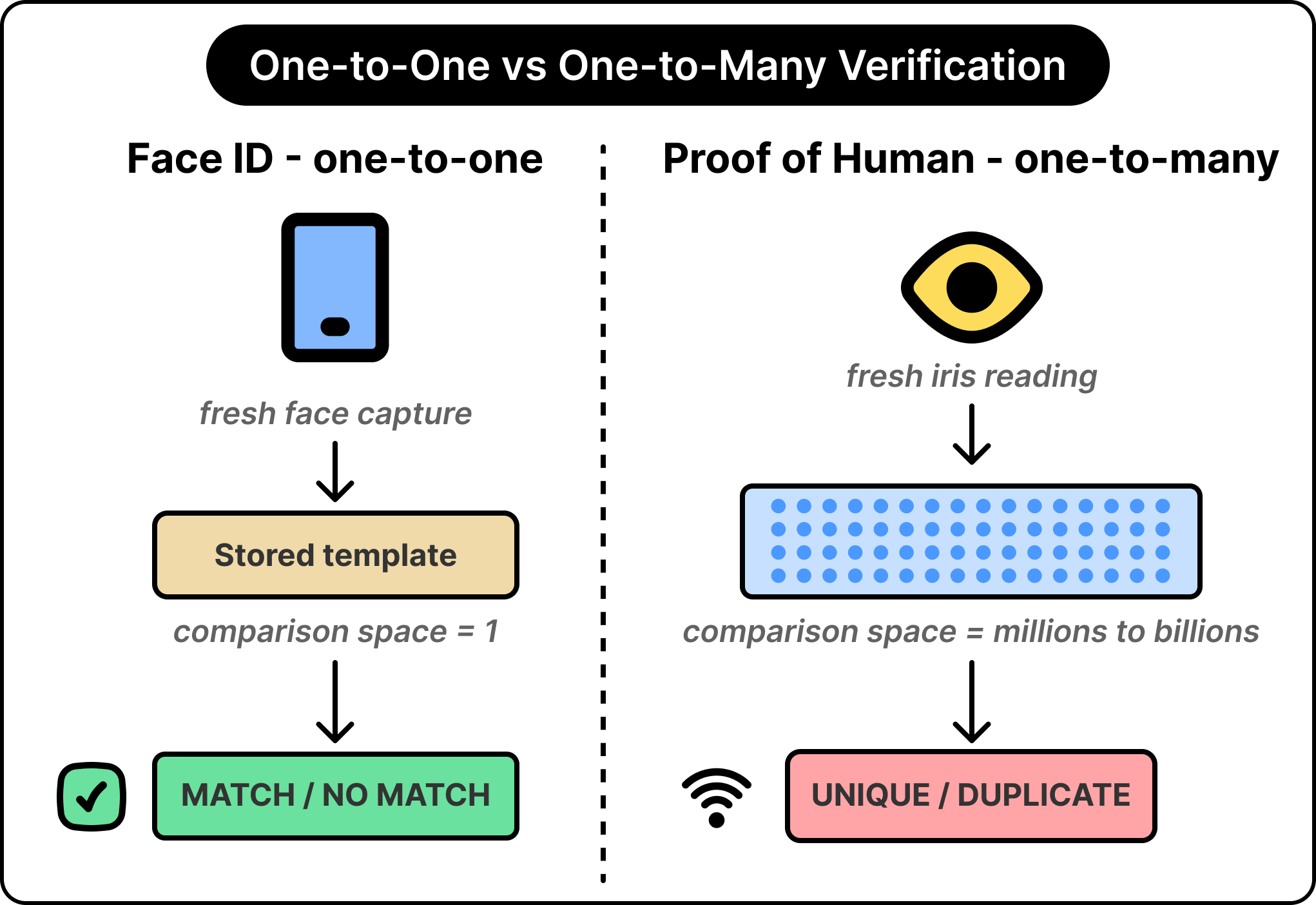
The probability of a false match scales roughly with the size of the comparison space. A per-comparison error rate of one in a million sounds excellent, but checked against a billion candidates, it produces roughly a thousand false matches per query. To make one-to-many uniqueness viable at a billion-person scale, the per-comparison error rate has to be on the order of one in a hundred billion or better. That requirement rules out most consumer-grade biometric methods straight away.
This type of system that answers the one-to-many question is what the World ID calls the proof of human. At present, there is no widely deployed equivalent of this category. We have a great deal of authentication infrastructure and very little uniqueness infrastructure.
Pillar 2: Anonymity
Once the goal is uniqueness at an internet scale, an apparent paradox emerges.
Checking whether someone is the same as anyone else usually requires recognizing them. If a system cannot identify a person, how can it tell whether it has seen that person before?
The answer takes multiple steps.
Step 1: Find a biometric signal that scales
Most consumer biometrics fall short. For example, fingerprints have decent entropy but can be captured from surfaces. Face geometry varies less than people assume. The iris pattern of the human eye, by contrast, turns out to be one of the few biometric features with the entropy needed for billion-scale comparisons. Two unrelated humans have essentially no chance of producing matching iris patterns, even after accounting for camera noise and aging.
However, reading the iris reliably is the next challenge, and this is where hardware matters.
A standard phone camera can be replaced with a device that injects images directly into the camera pipeline, defeating any face check done in software. A printed iris image can fool an infrared camera that lacks depth detection. To get a reading that resists these attacks, the capture has to happen on hardware that controls the entire signal path from sensor to processing.
Tools for Humanity handles this using a purpose-built device called the Orb. The Orb uses multispectral imaging across infrared and visible wavelengths, runs several neural networks locally to verify liveness and detect masks, and deletes the original images before anything leaves the device. What gets transmitted is signed, encrypted material derived from the iris, not the iris itself.
Step 2: Check for duplicates without anyone seeing the data
That solves the first half of the problem. The second half is harder. The system needs to check whether anyone else in the world has the same reading, while no party (including the system operator) ever sees the reading itself.
The trick works like this:
Take the iris reading and split it into three pieces of statistically random noise.
Hand each piece to a different organization operating in a different legal jurisdiction.
Each party, looking only at its piece, can tell nothing about the underlying reading.
The parties can jointly compute answers like “does this reading match any reading we have already enrolled?” without any single party ever holding the whole reading.
The pieces are combined only in the abstract space of the computation, never reconstructed on any actual machine.
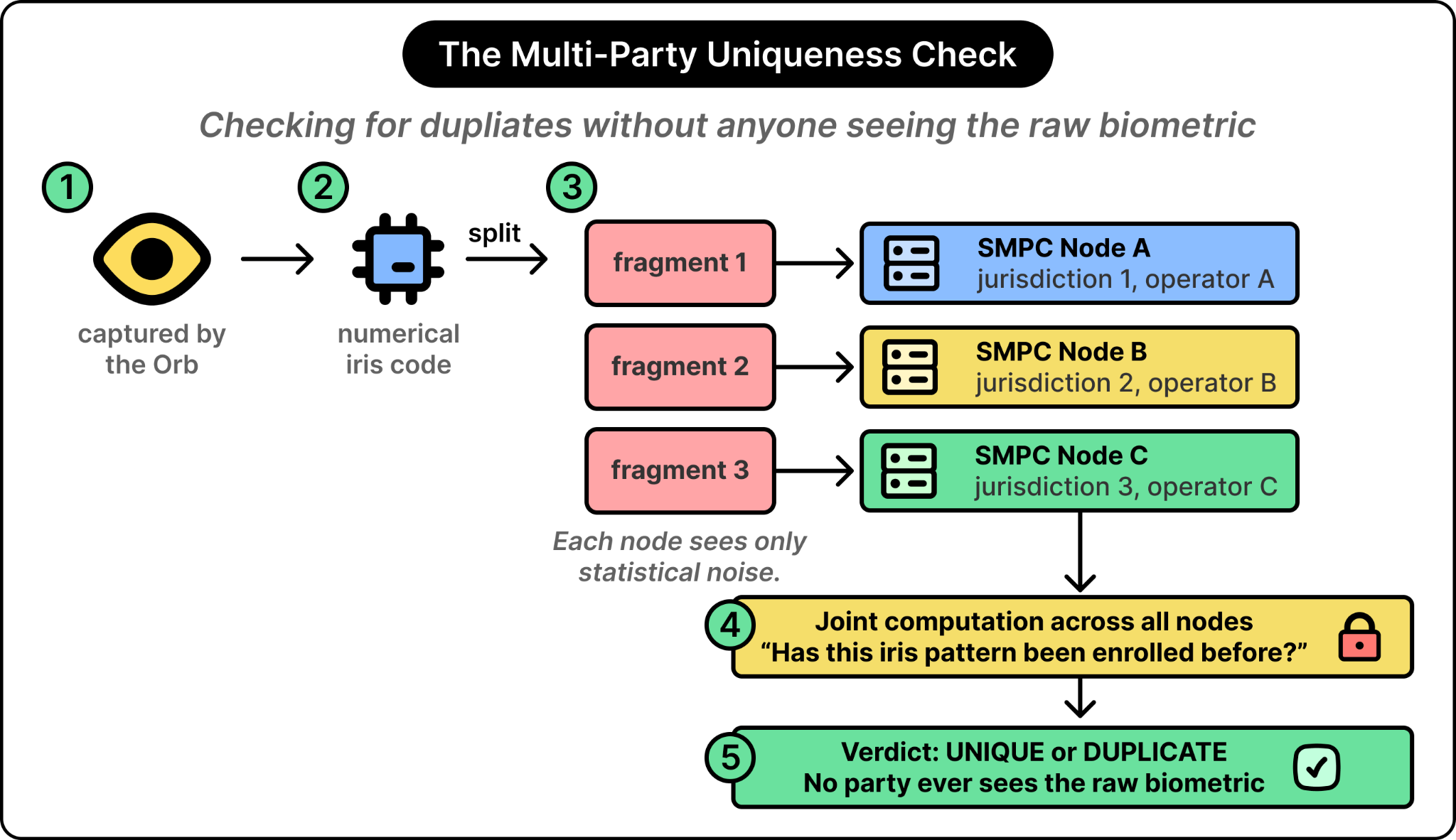
This is what cryptographers call secure multi-party computation, and the specific variant World uses is called anonymized multi-party computation (AMPC). The parties (referred to as SMPC nodes) are operated by independent organizations in different legal jurisdictions.
See the diagram below that tries to conceptualize what each SMPC party actually sees:
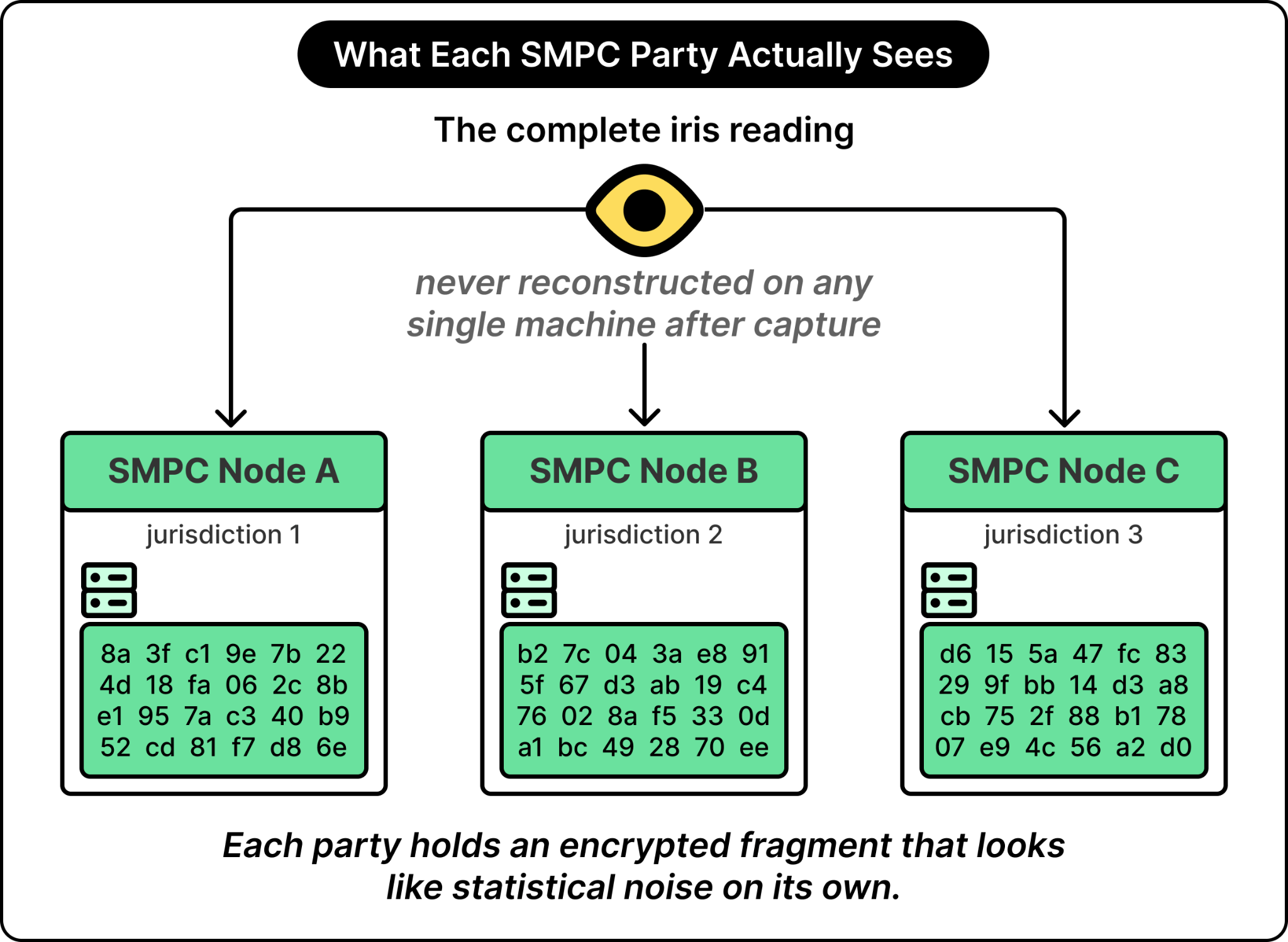
What emerges from this setup is the property that makes proof of human possible. The system can determine whether a given human has enrolled before, and no single party (including the main organization) ever sees the underlying biometric in usable form. The user is verified as unique without being identified.
Pillar 3: Recovery
A verified credential is only useful if the human carrying it can keep using it across years and across devices. In a normal life, phones get lost, and software gets reinstalled. Any system meant to anchor a lifelong property like “I am a verified unique human” has to handle the case where the holder loses access to everything they were using to prove it.
If the credential is a private key on a phone, losing the phone means losing the credential. The user would have to re-enroll. If the system is anchored in physical hardware verification, it means traveling back to a central location (in the case of World ID, that means the Orb). It would be a rather poor user experience for everyday loss, and impossible for some users in some regions.
The fix is to stop treating the credential as a single secret. Instead, treat the verified human as an abstract account in a public registry. The account does not hold the user’s biometric or any user secret directly. It holds a list of public keys (called Authenticators) that the user has authorized to act on the account’s behalf.
Think of an Authenticator as any piece of software or hardware that holds a private key on the user’s behalf. Here are some examples:
A common Authenticator could be the user’s phone with the wallet app installed.
A browser extension that holds a separate key could be another.
A hardware security token plugged in over USB is a third option.
When the user wants to verify on a service or app, the Authenticator is what actually produces the cryptographic proof and signs the verification request with its private key. The account in the public registry holds the matching public key, so anyone can confirm the signature without ever knowing the secret. Keys can be added, revoked, and rotated. The account itself persists.
For more context, the public registry stores one entry per verified human. Each entry contains the public keys of all currently authorized Authenticators, the designated Recovery agents for that account, and the rules under which those agents can act. The biometric reading itself is never stored in the registry. This ensures that reading the registry cannot reveal personal details about the verified humans.
See the diagram below that shows this approach in the context of World ID’s solution:
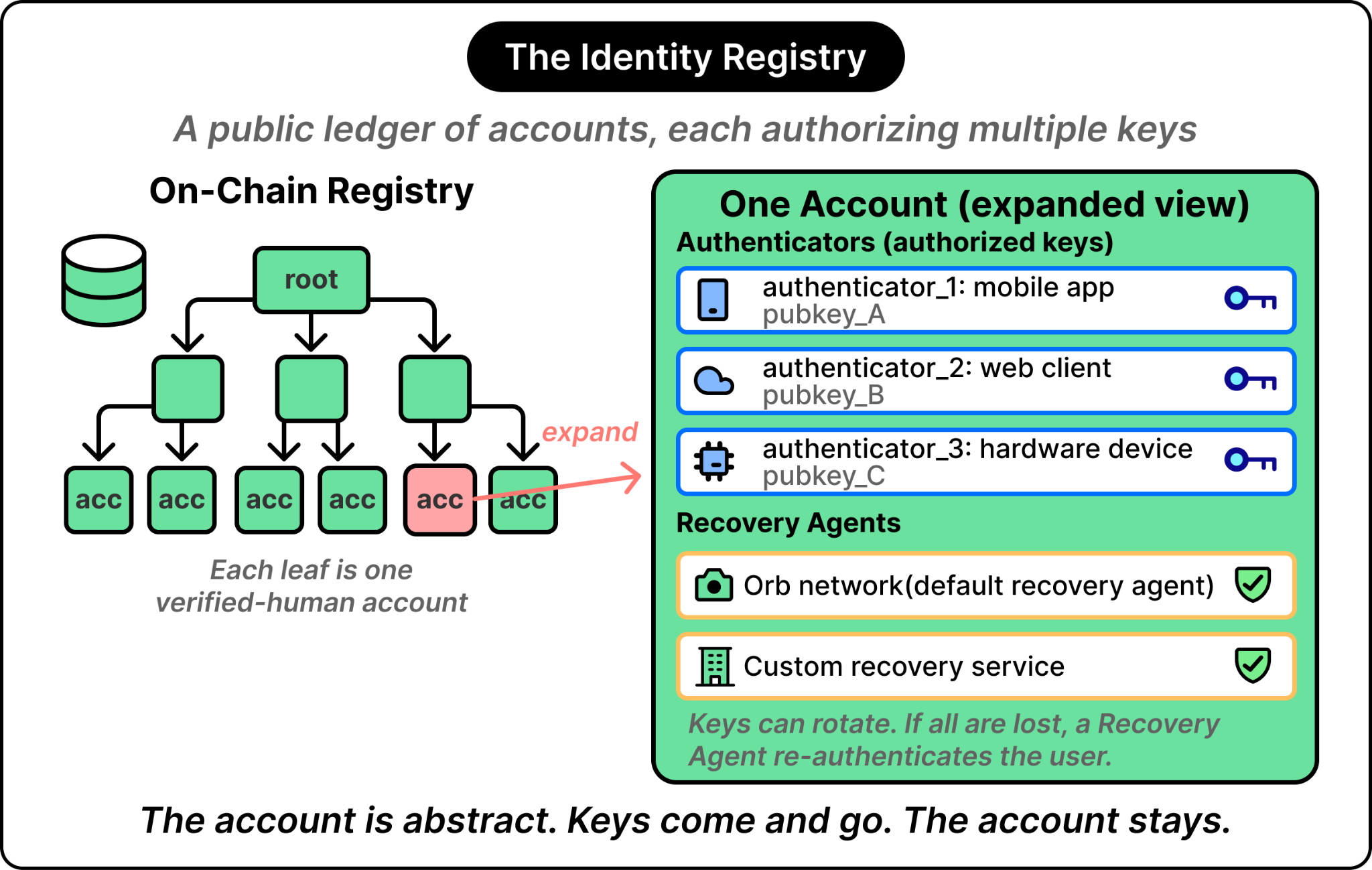
If the user loses all of their Authenticators, the account also designates one or more Recovery Agents, which are parties trusted to re-authenticate the human (typically by running them through a fresh biometric check) and let them register new keys.
In the current design of World ID, the Orb network serves as the default Recovery Agent. The on-chain registry that holds all of this is called the WorldIDRegistry.
What this might look like in practice is as follows: imagine the user’s phone is stolen on a trip. They get a new phone and install the wallet app fresh, but the app has no private keys yet. Rather than travel back to an Orb to start over, the user can initiate a recovery through one of the Recovery Agents they previously designated. The agent runs them through a fresh biometric check, typically through the Orb’s mobile face authentication. If the check passes, the agent submits a transaction to the registry that revokes the stolen phone’s key and registers the new phone’s key.
However, the open question here is governance. The Recovery Agents can themselves become a trust point, which would require some form of oversight.
Pillar 4: Verification
So far, we have a way to verify a human as unique, and a way for them to hold their credentials durably.
What we need next is a way to present that credential to a relying party (for example, a dating app, a shoe retailer, or any service that wants to enforce one-per-human) so the service can do its job while learning as little as possible about the user.
A relying party in this scenario needs three things at once:
Assurance that the request is backed by a real and verified unique human.
The ability to enforce its own one-per-human rule, which means recognizing repeat visits by the same human within its own context.
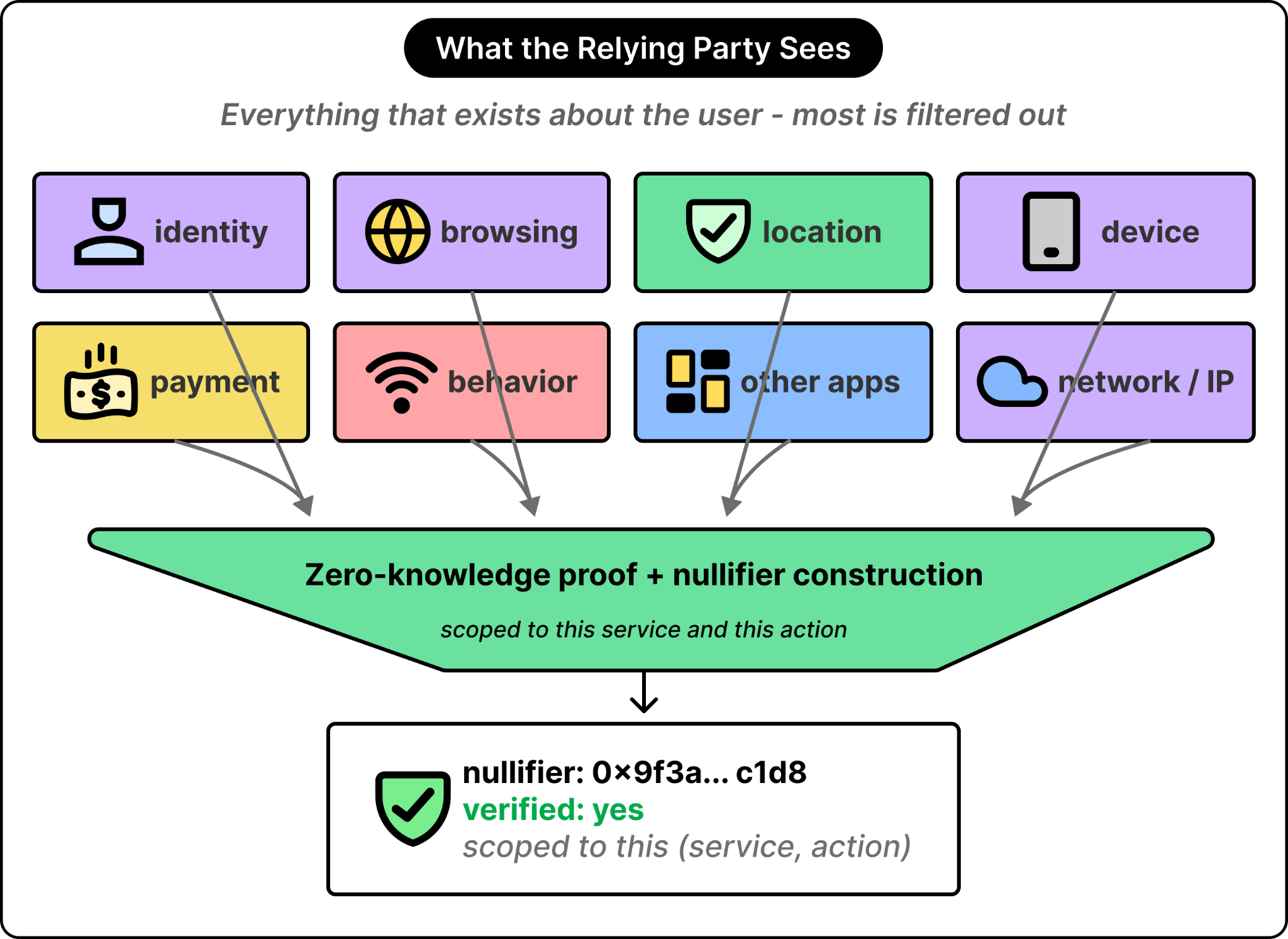
Confidence that what the user reveals is limited to the fact of being a verified, unique human, with identity, other activity, and behavior on other platforms staying private.
Satisfying all three at once is harder than it sounds. Standard identity tokens (an OAuth token, a JWT, a session cookie) tie recognition to identity. The relying party gets the ability to enforce policies, but pays for it with the user’s privacy.
The World ID handled this problem using a primitive called a nullifier. A nullifier is a number derived from three inputs combined together. The inputs are the user’s verified credentials, the relying party’s identifier, and a particular action. The same combination always produces the same number. Different combinations produce uncorrelated numbers. If the relying party sees the same nullifier again for the same action, they know it is the same human attempting the same thing twice. Nullifiers from the same user on a different action, or in a different service, are uncorrelated and cannot be linked back.
See the diagram below that shows what the relying party actually sees:
Generating a nullifier like this requires careful design. A user cannot generate it alone (they cannot be trusted to use the right inputs), and a single server cannot generate it either (the server would learn who the user is). It needs a distributed network of nodes, and here’s how they work:
The user sends a blinded version of their query
Each node computes on the blinded value while staying unaware of what the value represents
The user unblinds the result.
A threshold of nodes must cooperate. These nodes are called OPRF nodes (oblivious pseudorandom function).
One more piece is needed to complete the puzzle. If a user could reuse the same nullifier multiple times within one relying party context, an enterprising service could build a pseudonymous profile of the user’s repeated interactions. To prevent this, the design maintains an on-chain list of every nullifier that has been used, called the Oblivious Nullifier Pool. The user’s own software refuses to generate a proof for a nullifier already in the pool.
So, how is all this complexity handled from an application’s perspective?
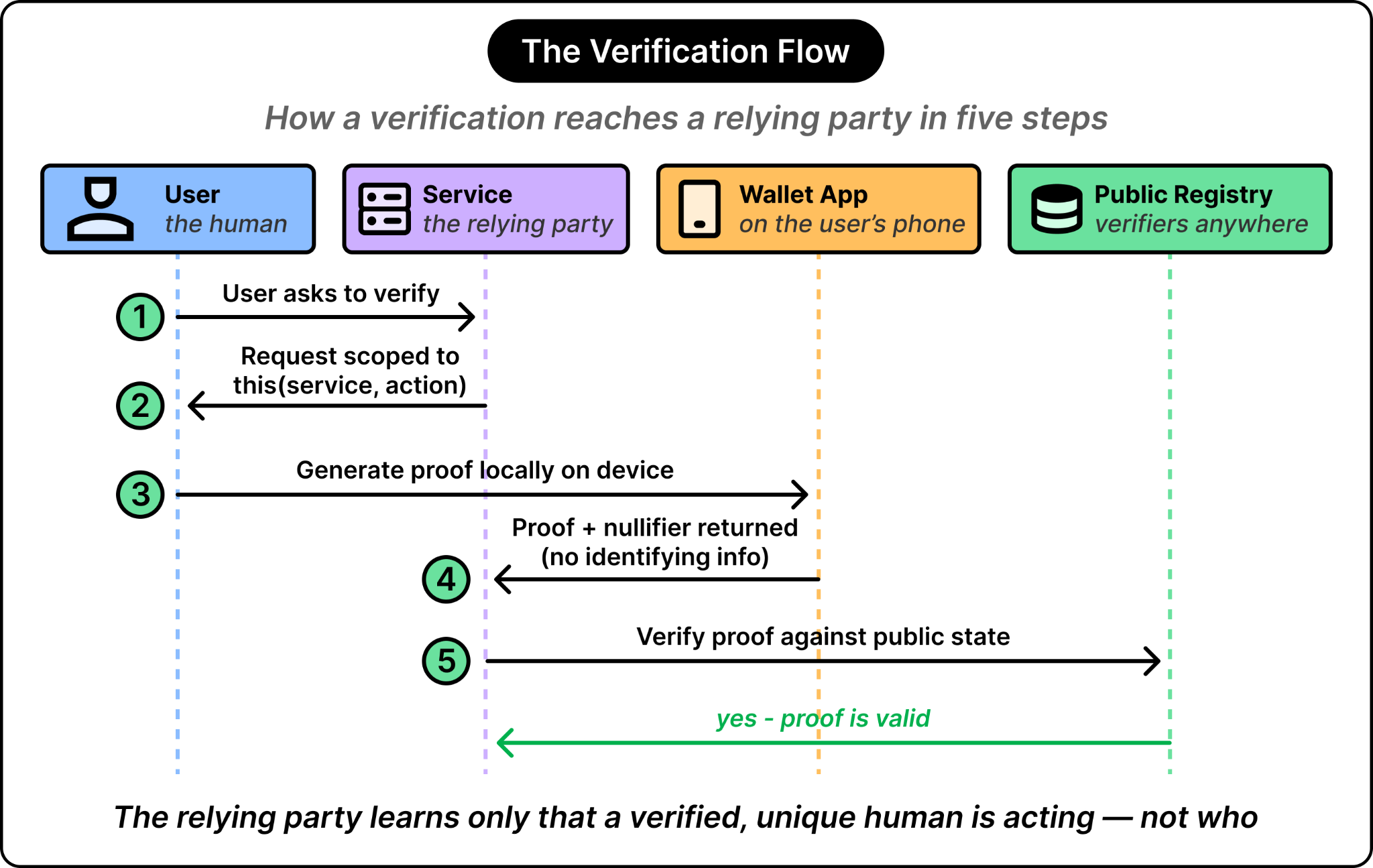
In the context of World ID, all of this gets bundled into two zero-knowledge proofs that the user presents to the relying party. An SDK named IDKIT wraps the flow for integrators.
See the diagram below that shows a simple IDKit Proof Flow:
Pillar 5: Delegation
Up to this point, we have assumed the human is the one acting. The user might open a dating app, buy sneakers from an online retailer, or sign a document. The design handles each case by binding one verifiable human to one proof.
The interesting question is what happens when the human is not the one acting. This is because people are now increasingly using AI agents to take actions on their behalf. For example:
An assistant books a flight.
An agent monitors product drops and buys when something matches.
A service fills out and submits forms for a user who would rather not.
The standard defense against agents is to block them as bots, but here the human wants the agent to act for them. Treating the agent as adversarial defeats the very automation the user is paying for.
The extension to the design for an ideal proof of human solution is to let the agent register against a real human’s credentials before it acts. When the agent later contacts a service, the service can verify that the agent is backed by a verified, unique human, while still learning nothing about which human. The agent’s activity counts against the human’s quota, so a single human cannot turn into many parallel agents to amplify their reach.
See the diagram below that shows how World ID implements this using AgentKit:
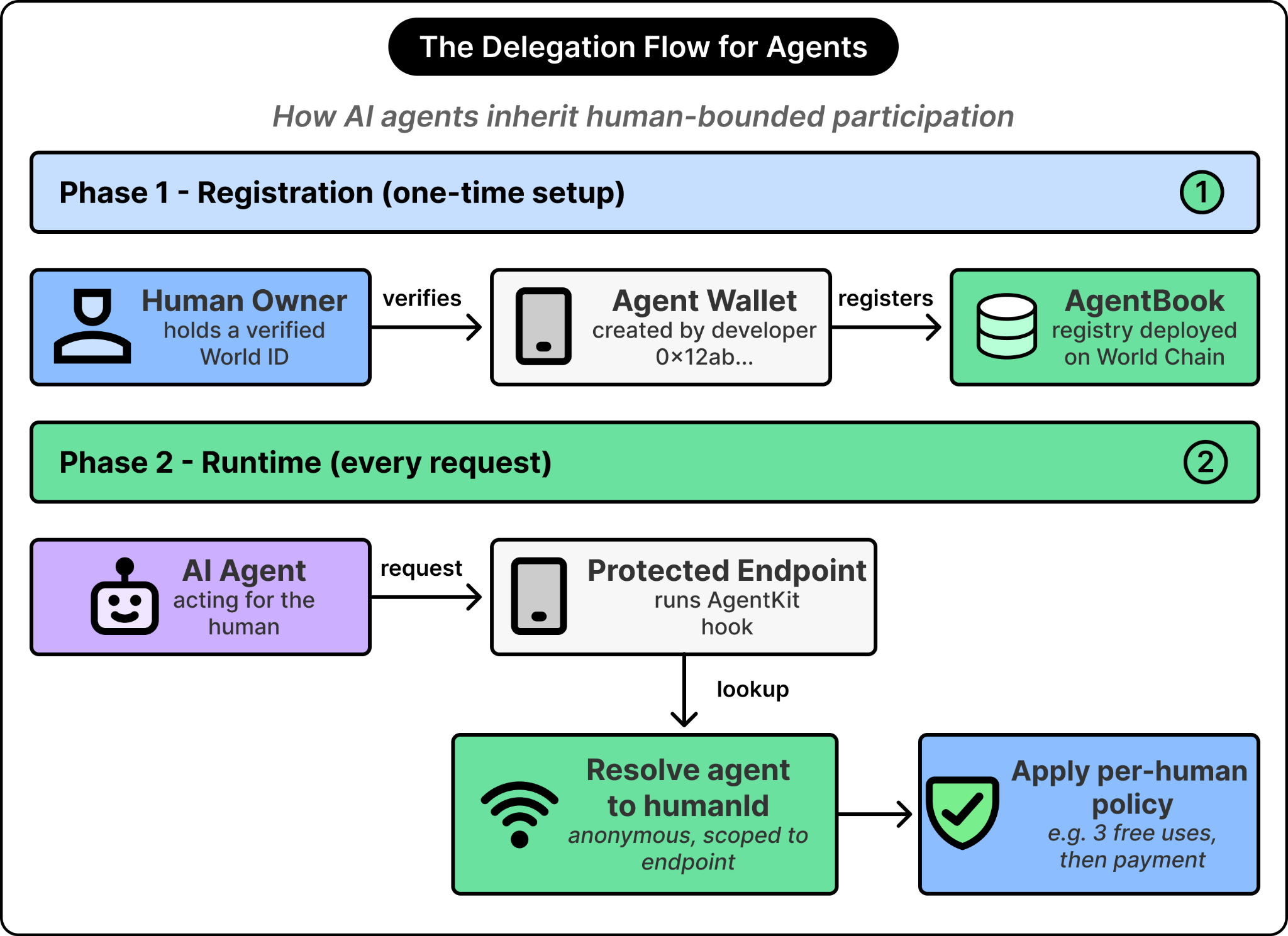
In World’s implementation, the agent registers its wallet address in a registry called AgentBook (deployed on the World Chain blockchain), tying the agent to the human’s World ID through a verification flow in the user’s wallet app. A service or application that wants to admit human-backed agents installs the SDK called AgentKit, which by default allows three uses per human per service before normal payment takes over.
A few new use cases become possible:
A startup can offer a free trial that bots cannot farm at scale, because each trial use is bound to a verified human.
A retailer can enforce one pair per human on a limited drop, even when agents do the buying.
A merchant can require human backing for transactions where chargeback fraud is a concern.
What remains open is how this scales. At present, the volume of agent traffic is quite small compared with what AI agents will likely produce in the coming years. Whether the per-human cap stays meaningful when one human represents many concurrent agents is a question worth looking into.
Conclusion
Taken together, the five pillars (uniqueness, anonymity, recovery, verification, and delegation) form a working blueprint for proof of human in principle. Whether any particular implementation, World ID included, becomes the way the larger question gets answered at internet scale remains to be seen.
A few specific questions are worth tracking as the design meets larger-scale reality:
Hardware decentralization. The longer-term plan calls for multiple independent manufacturers of devices like the Orb, distributed across jurisdictions and cross-checking each other through security deposits. The architectural properties depend on this transition actually happening.
Unlinkability under adversarial pressure. The cryptography looks sound on paper. The harder test is what happens when relying parties, governments, or other large actors try to extract more from the system than the design intends. Whether the unlinkability properties hold in practice at scale is something the community will only learn over time.
Delegation at agent scale. Most agent traffic today still flows through traditional authorization systems. As agents take on more autonomous activity, the per-human cap will be tested in ways the existing deployment has not yet seen. New abuse patterns will almost certainly emerge.
The bootstrap problem. Proof of human becomes useful at scale, and reaching scale requires apps to require it, which in turn requires users to have it. How any such system navigates that loop, and what happens if a meaningful fraction of the internet starts to require proof of human, is far from clear today.
The point of this article was not to argue for any particular product, but to surface the techniques. Once you can see the shape of the problem, one-to-many matching, secret-shared biometrics, scoped nullifiers, account-style key rotation, delegated quotas, the headlines about “verify you are human” start to look less mysterious. They are attempts to solve a specific class of problems that the rest of the identity stack has so far left alone.
References and Further Reading
Great framework idea. Where proof of human is tough today is in agentic contexts. If an agent inherits a valid device credential then they have proven they’re human without being human.
Although you did touch on this. It doesn’t really matter if an agent is human. Are they authorized and are they using a system appropriately. I should be able to delegate work to a personal agent and not have that shut down all the time because I’m not viewing ads.
When I write software today, I am adding agentic interfaces so they don’t have to fake being human. They can have appropriate access through and appropriate interface.
It will be interesting to see where this topic goes for sure.
PS. I’ve worked with “big shoe companies” that have this problem. They have a couple of other detection vectors nobody has figured out yet. I’m not able to say what they are but they’re pretty simple and have a lot of bot makers fooled.
Doesn't the human uniqueness check using iris example require trusting the hardware or client to some extent, and rely on an adversary not being able to reverse engineer it and/or steal keys.
If you can generate the same fake iris random value in a reproducible way and present it to the server, then your fake client or fake hardware can pretend to be one of many different fake people on demand.