Rate Limiter For The Real World

In the previous article, we discussed the fundamentals of rate limiting and explored several popular rate limiting algorithms. We’ll continue by exploring how to build some real-world rate limiters.
There are many factors to consider when developing a rate limiter for the real world. For example, in many use cases, a rate limiter is in the most critical path of an application. It is important in those situations to think through all the failure scenarios and consider the performance implications of placing it in such a critical path.
Gathering Requirements and Key Considerations
Before diving headfirst into building our rate limiter, it is important to understand our goals. This starts with gathering requirements and considering key design factors. The requirements can vary based on the nature of our service and the use cases we’re trying to support.

First, we should consider the nature of our service. Is it a real-time, latency-sensitive application or an asynchronous job where accuracy and reliability are more important than real-time performance? This can also guide our decisions around how we handle rate limit violations. Should our system immediately reject any further requests, or should it queue them and process them as capacity becomes available?
Next, we should consider the behavior of our clients. What are their average and peak request rates? Are their usage patterns predictable, or will there be significant spikes in traffic? This analysis is useful for creating rate limiting rules that protect our system without hindering legitimate users.
Then, consider the scale and performance needs. We need to understand the volume of requests we anticipate and set the target latency of our system. Is the system serving millions of customers making billions of requests, or are we dealing with a smaller number? Is latency critical, or can we sacrifice some speed for enhanced reliability?
Our rate limiting policy also needs careful consideration. Are we limiting based on the number of requests per unit of time, size of requests, or some other criteria? Is the limit set per client, or shared across all clients? Are there different tiers of clients with different limits? Is the policy strict, or does it allow for bursting?
Some rate limiters will have persistence requirements. For a long rate limiting window, how do we persist the rate limit states like counters for long-term tracking? This requirement might be especially important in cases where latency is less critical than long-term accuracy, such as in an asynchronous job processing system.
Let’s consider some examples to better understand these points.
For a real-time service like a bidding platform where latency could be highly critical, we would need a rate limiter that doesn’t add significant latency to the overall request time. We will likely need to make a tradeoff between accuracy and resource consumption. A more precise rate limiter might use more memory and CPU, while a simpler one might allow occasional bursts of requests.
On the other hand, in an asynchronous job processing system that processes large batches of data analysis jobs, our rate limiter doesn’t need to enforce the limit in real-time, but must ensure that the total number of jobs submitted by each user doesn’t exceed the daily limit. In such cases, storing the rate limiting states durably, for instance in a database, might be crucial.

Rate Limiter Architecture
The main architectural question is: where should we place the rate limiter in our application stack?
This largely depends on the configuration of the application stack. Let’s examine this in more detail.
The location where we integrate our rate limiter into our application stack matters significantly. This decision will depend on the rate limiting requirements we gathered in the previous section.
In the case of typical web-based API-serving applications, we have several layers where rate limiters could potentially be placed.
CDN and Reverse Proxy
The outermost layer is the Content Delivery Network (CDN) which also functions as our application’s reverse proxy. Using a CDN to front an API service is becoming an increasingly prevalent design for production environments. For example, Cloudflare, a well-known CDN, offers some rate limiting features based on standard web request headers like IP address or other common HTTP headers.
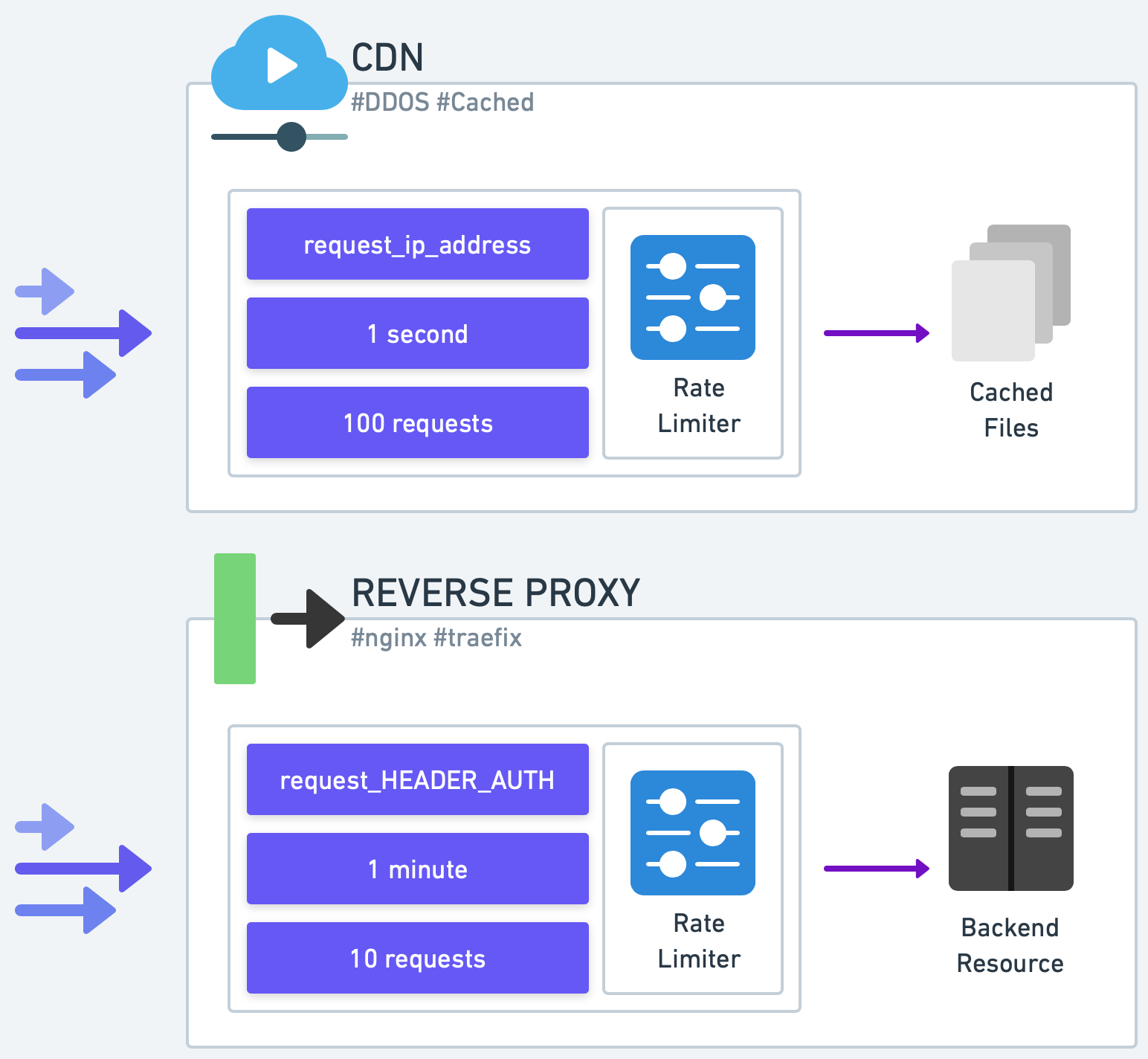
If a CDN is already a part of the application stack, it’s a good initial defense against basic abuse. More sophisticated rate limiters can be deployed closer to the application backend to address any remaining rate limiting needs.
Some production deployments maintain their own reverse proxy, rather than a CDN. Many of these reverse proxies offer rate limiting plugins. Nginx, for example, can limit connections, request rates, or bandwidth usage based on IP address or other variables such as HTTP headers. Traefik is another example of a reverse proxy, popular within the Kubernetes ecosystem, that comes with rate limiting capabilities.
If a reverse proxy supports the desired rate limiting algorithms, it is a suitable location for a basic rate limiter.
However, be aware that large-scale deployments usually involve a cluster of reverse proxy nodes to handle the large volume of requests. This results in rate limiting states distributed across multiple nodes. It can lead to inaccuracies unless the states are synchronized. We’ll discuss this complex distributed system issue in more detail later.
API Gateway
Moving deeper into the application stack, some deployments utilize an API Gateway to manage incoming traffic. This layer can host a basic rate limiter, provided the API Gateway supports it. This allows for control over individual routes and lets us apply different rate limiting rules for different endpoints.

Amazon API Gateway is an example of this. It handles rate limiting at scale. We don’t need to worry about managing rate limiting states across nodes, as would be required with our own cluster of reverse proxy servers. A potential downside is that the rate limiting control might not be as fine-grained as we would like.
Application Framework and Middleware
If our rate limiting needs require more fine-grained identification of the resource to limit, we may need to place the rate limiter closer to the application logic. For example, if user specific attributes like subscription type need limiting, we’ll need to implement the rate limiter at this level.
In some cases, the application framework might provide rate limiting functionality via middleware or a plugin. Like in previous cases, if these functions meet our needs, this would be a suitable place for rate limiting.
This method allows for rate limiting integration within our application code as middleware. It offers customization for different use-cases and enhances visibility, but it also adds complexity to our application code and could affect performance.
Application
Finally, if necessary, we could incorporate rate limiting logic directly in the application code. In some instances, the rate limiting requirements are so specific that this is the only feasible option.
This offers the highest degree of control and visibility but introduces complexity and potential tight coupling between the rate limiting and business logic.
Like before, when operating at scale, all issues related to sharing rate limiting states across application nodes are relevant.
Rate Limiting States
Another significant architectural decision is where to store rate limiting states, such as counters. For a low-scale, simple rate limiter, keeping the states entirely in the rate limiter’s memory might be sufficient.
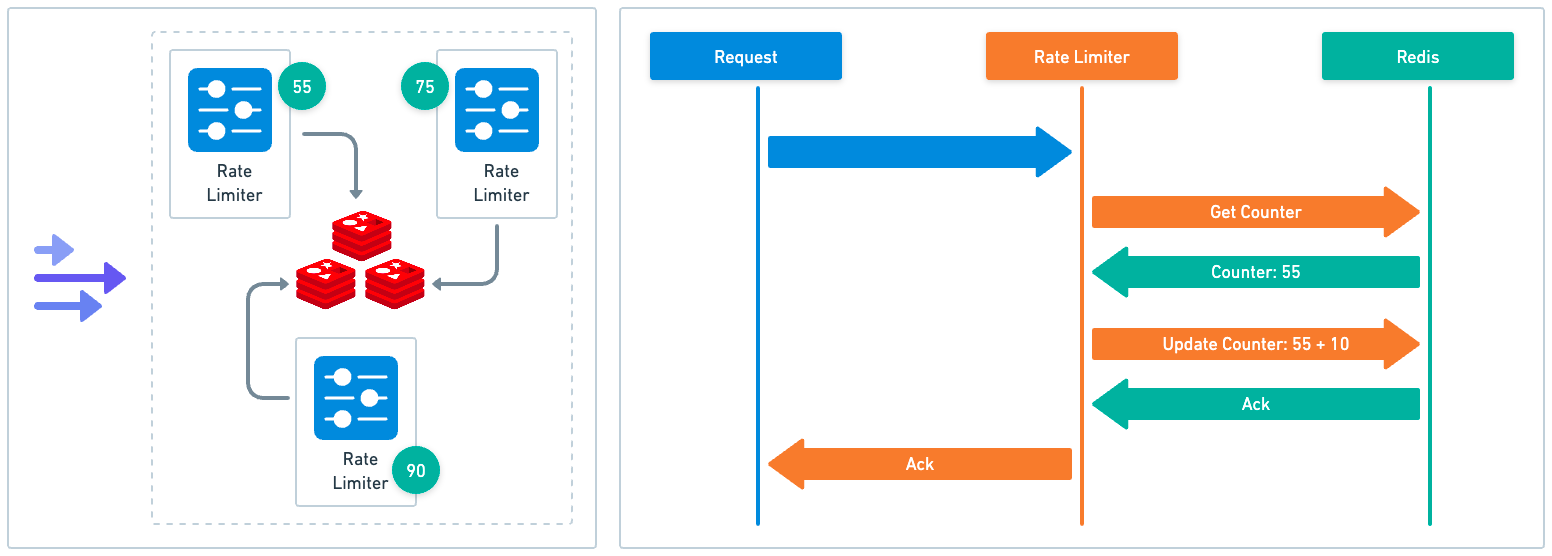
However, this is likely the exception rather than the rule. In most production environments, regardless of the rate limiter’s location in the application stack, there will likely be multiple rate limiter instances to handle the load, with rate limiting states distributed across nodes.

We’ve frequently referred to this as a challenge. Let’s dive into some specifics to illustrate this point.
When rate limiters are distributed across a system, it presents a problem as each instance may not have a complete view of all incoming requests. This can lead to inaccurate rate limiting.
For example, let’s assume we have a cluster of reverse proxies, each running its own rate limiter instance. Any of these proxies could handle an incoming request. This leads to distributed and isolated rate limiting states. A user might potentially exceed their rate limit if their requests are handled by multiple proxies.
In some cases, the inaccuracies might be acceptable. Referring back to our initial discussion on requirements, if our objective is to provide a basic level of protection, a simple solution allowing each instance to maintain its own states might be adequate.
However, if maintaining accurate rate limiting is a core requirement - for example, if we want to ensure fair usage of resources across all users or we have to adhere to strict rate limit policies for compliance reasons - we will need to consider more sophisticated strategies.
Centralized State Storage
One such strategy is centralized state storage. Here, instead of each rate limiter instance managing its own states, all instances interact with a central storage system to read and update states. This method does, however, come with many tradeoffs.