
Reddit's Architecture: The Evolutionary Journey

The comprehensive developer resource for B2B User Management (Sponsored)

Building an enterprise-ready, resilient B2B auth is one of the more complex tasks developers face these days. Today, even smaller startups are demanding security features like SSO that used to be the purview of the Fortune 500.
The latest guide from WorkOS covers the essentials of modern day user management for B2B apps — from 101 topics to more advanced concepts that include:
→ SSO, MFA, and sessions
→ Bot policies, org auth policies, and UI considerations
→ Identity linking, email verification, and just-in-time provisioning
This resource also presents an easier alternative for supporting user management.
Reddit's Architecture: The Evolutionary Journey
Reddit was founded in 2005 with the vision to become “the front page of the Internet”.
Over the years, it has evolved into one of the most popular social networks on the planet fostering tens of thousands of communities built around the passions and interests of its members. With over a billion monthly users, Reddit is where people come to participate in conversations on a vast array of topics.
Some interesting numbers that convey Reddit’s incredible popularity are as follows:
Reddit has 1.2 billion unique monthly visitors, turning it into a virtual town square.
Reddit’s monthly active user base has exploded by 366% since 2018, demonstrating the need for online communities.
In 2023 alone, an astonishing 469 million posts flooded Reddit’s servers resulting in 2.84 billion comments and interactions.
Reddit ranked as the 18th most visited website globally in 2023, raking in $804 million in revenue.
Looking at the stats, it’s no surprise that their recent IPO launch was a huge success, propelling Reddit to a valuation of around $6.4 billion.
While the monetary success might be attributed to the leadership team, it wouldn’t have been possible without the fascinating journey of architectural evolution that helped Reddit achieve such popularity.
In this post, we will go through this journey and look at some key architectural steps that have transformed Reddit.
The Early Days of Reddit
Reddit was originally written in Lisp but was rewritten in Python in December 2005.
Lisp was great but the main issue at the time was the lack of widely used and tested libraries. There was rarely more than one library choice for any task and the libraries were not properly documented.
Steve Huffman (one of the founders of Reddit) expressed this problem in his blog:
“Since we're building a site largely by standing on the shoulders of others, this made things a little tougher. There just aren't as many shoulders on which to stand.”
When it came to Python, they initially used a web framework named web.py that was developed by Swartz (another co-founder of Reddit). Later in 2009, Reddit started to use Pylons as its web framework.
The Core Components of Reddit’s Architecture
The below diagram shows the core components of Reddit’s high-level architecture.

While Reddit has many moving parts and things have also evolved over the years, this diagram represents the overall scaffolding that supports Reddit.
The main components are as follows:
Content Delivery Network: Reddit uses a CDN from Fastly as a front for the application. The CDN handles a lot of decision logic at the edge to figure out how a particular request will be routed based on the domain and path.
Front-End Applications: Reddit started using jQuery in early 2009. Later on, they also started using Typescript to redesign their UI and moved to Node.js-based frameworks to embrace a modern web development approach.
The R2 Monolith: In the middle is the giant box known as r2. This is the original monolithic application built using Python and consists of functionalities like Search and entities such as Things and Listings. We will look at the architecture of R2 in more detail in the next section.
From an infrastructure point of view, Reddit decommissioned the last of its physical servers in 2009 and moved the entire website to AWS. They had been one of the early adopters of S3 and were using it to host thumbnails and store logs for quite some time.
However, in 2008, they decided to move batch processing to AWS EC2 to free up more machines to work as application servers. The system worked quite well and in 2009 they completely migrated to EC2.
R2 Deep Dive
As mentioned earlier, r2 is the core of Reddit.
It is a giant monolithic application and has its own internal architecture as shown below:
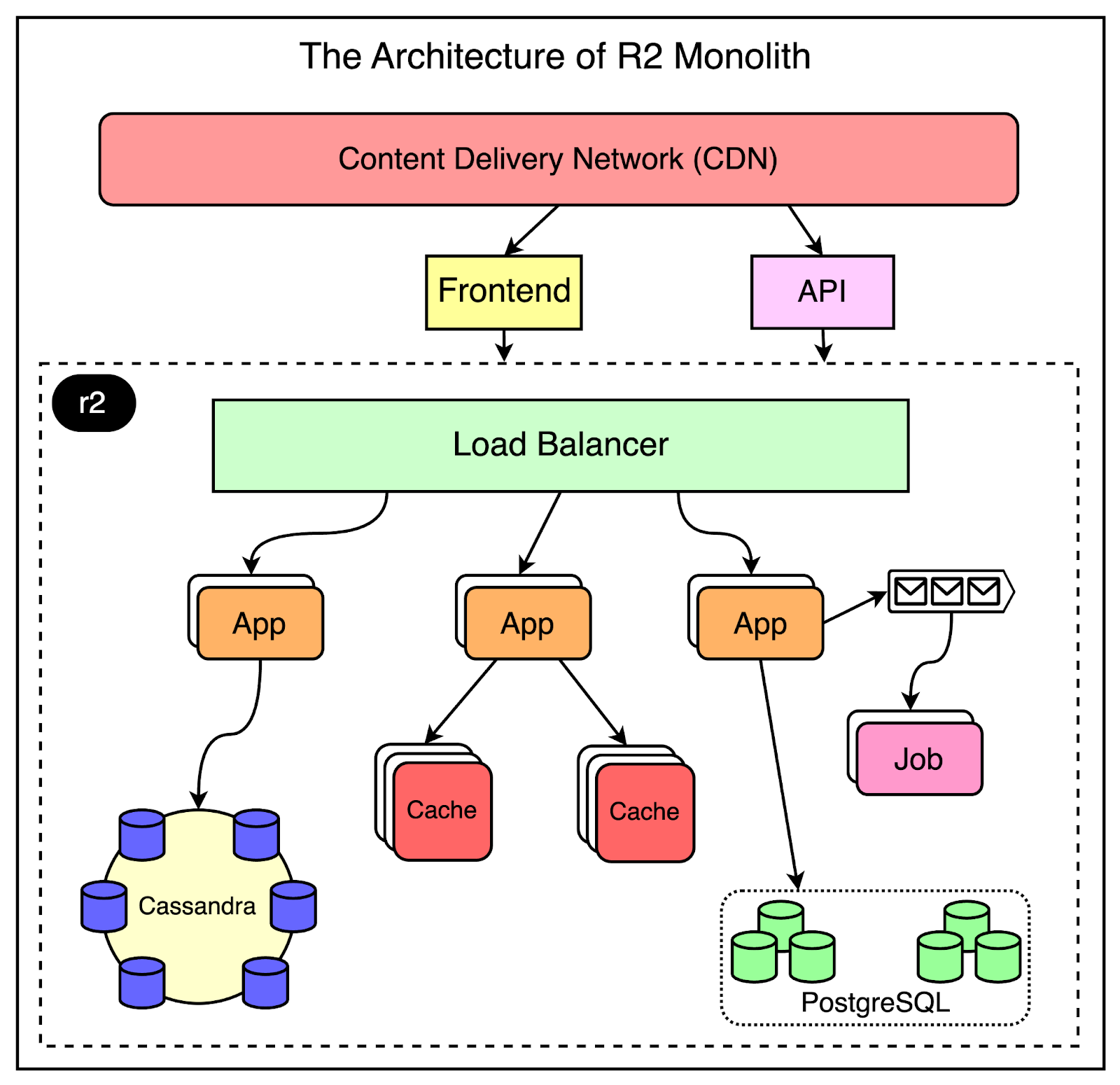
For scalability reasons, the same application code is deployed and run on multiple servers.
The load balancer sits in the front and performs the task of routing the request to the appropriate server pool. This makes it possible to route different request paths such as comments, the front page, or the user profile.
Expensive operations such as a user voting or submitting a link are deferred to an asynchronous job queue via Rabbit MQ. The messages are placed in the queue by the application servers and are handled by the job processors.
From a data storage point of view, Reddit relies on Postgres for its core data model. To reduce the load on the database, they place memcache clusters in front of Postgres. Also, they use Cassandra quite heavily for new features mainly because of its resiliency and availability properties.
Latest articles
If you’re not a paid subscriber, here’s what you missed.

To receive all the full articles and support ByteByteGo, consider subscribing:
The Expansion Phase
As Reddit has grown in popularity, its user base has skyrocketed. To keep the users engaged, Reddit has added a lot of new features. Also, the scale of the application and its complexity has gone up.
These changes have created a need to evolve the design in multiple areas. While design and architecture is an ever-changing process and small changes continue to occur daily, there have been concrete developments in several key areas.
Let’s look at them in more detail to understand the direction Reddit has taken when it comes to architecture.
GraphQL Federation with Golang Microservices
Reddit started its GraphQL journey in 2017. Within 4 years, the clients of the monolithic application had fully adopted GraphQL.
GraphQL is an API specification that allows clients to request only the data they want. This makes it a great choice for a multi-client system where each client has slightly different data needs.
In early 2021, they also started moving to GraphQL Federation with a few major goals:
Retiring the monolith
Improving concurrency
Encouraging separation of concerns
GraphQL Federation is a way to combine multiple smaller GraphQL APIs (also known as subgraphs) into a single, large GraphQL API (called the supergraph). The supergraph acts as a central point for client applications to send queries and receive data.
When a client sends a query to the supergraph, the supergraph figures out which subgraphs have the data needed to answer that query. It routes the relevant parts of the query to those subgraphs, collects the responses, and sends the combined response back to the client.
In 2022, the GraphQL team at Reddit added several new Go subgraphs for core Reddit entities like Subreddits and Comments. These subgraphs took over ownership of existing parts of the overall schema.
During the transition phase, the Python monolith and new Go subgraphs work together to fulfill queries. As more and more functionalities are extracted to individual Go subgraphs, the monolith can be eventually retired.
The below diagram shows this gradual transition.

One major requirement for Reddit was to handle the migration of functionality from the monolith to a new Go subgraph incrementally.
They want to ramp up traffic gradually to evaluate error rates and latencies while having the ability to switch back to the monolith in case of any issues.
Unfortunately, the GraphQL Federation specification doesn’t offer a way to support this gradual migration of traffic. Therefore, Reddit went for a Blue/Green subgraph deployment as shown below:
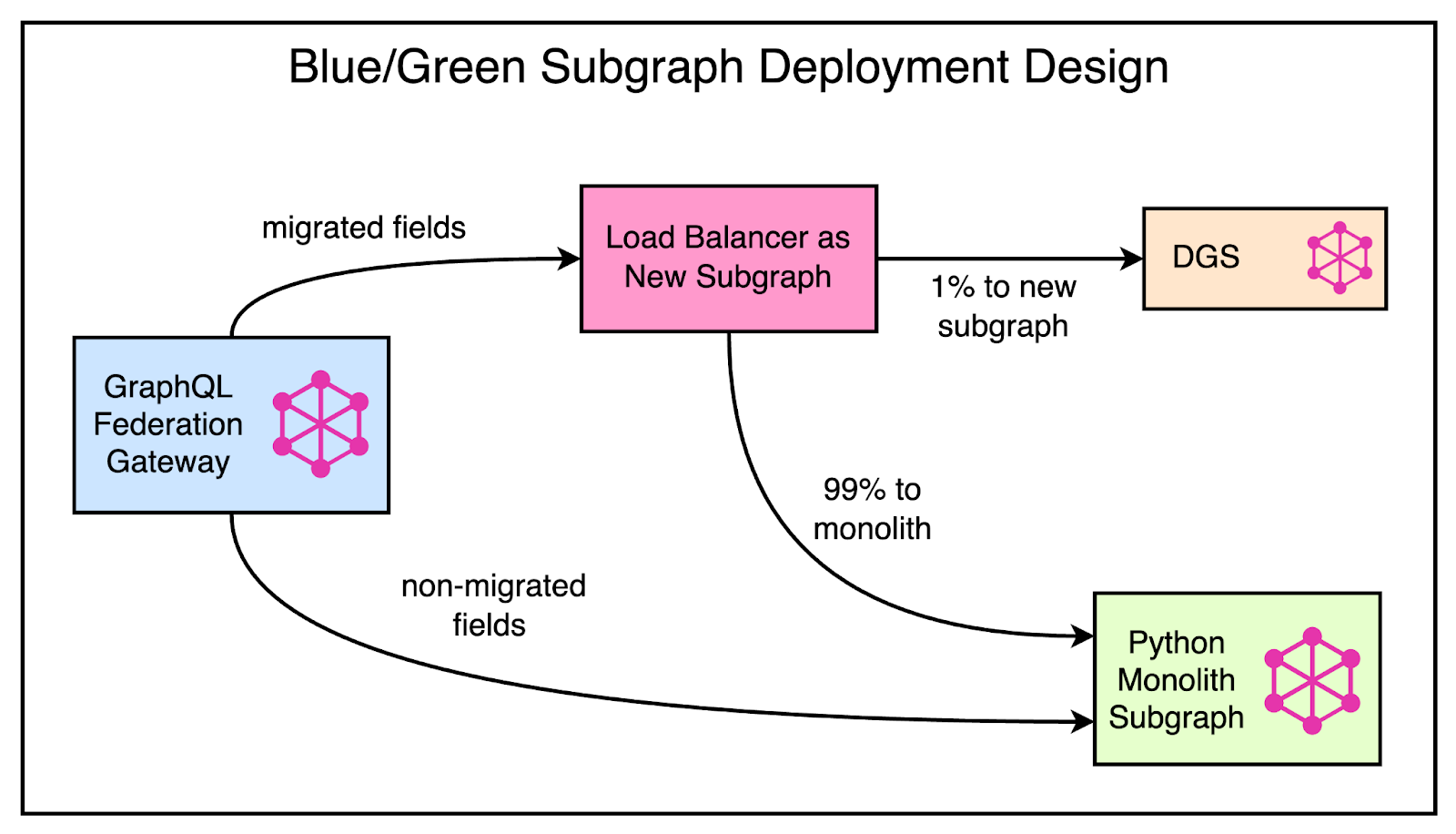
In this approach, the Python monolith and Go subgraph share ownership of the schema. A load balancer sits between the gateway and the subgraphs to send traffic to the new subgraph or the monolith based on a configuration.
With this setup, they could also control the percentage of traffic handled by the monolith or the new subgraph, resulting in better stability of Reddit during the migration journey.
As of the last update, the migration is still ongoing with minimal disruption to the Reddit experience.
Data Replication with CDC and Debezium
In the early stages, Reddit supported data replication for their databases using WAL segments created by the primary database.
WAL or write-ahead log is a file that records all changes made to a database before they are committed. It ensures that if there’s a failure during a write operation, the changes can be recovered from the log.
To prevent this replication from bogging down the primary database, Reddit used a special tool to continuously archive PostgreSQL WAL files to S3 from where the replica could read the data.
However, there were a few issues with this approach:
Since the daily snapshots ran at night, there were inconsistencies in the data during the day.
Frequent schema changes to databases caused issues with snapshotting the database and replication.
The primary and replica databases ran on EC2 instances, making the replication process fragile. There were multiple failure points such as a failing backup to S3 or the primary node going down.
To make data replication more reliable, Reddit decided to use a streaming Change Data Capture (CDC) solution using Debezium and Kafka Connect.
Debezium is an open-source project that provides a low-latency data streaming platform for CDC.
Whenever a row is added, deleted, or modified in Postgres, Debezium listens to these changes and writes them to a Kafka topic. A downstream connector reads from the Kafka topic and updates the destination table with the changes.
The below diagram shows this process.

Moving to CDC with Debezium has been a great move for Reddit since they can now perform real-time replication of data to multiple target systems.
Also, instead of bulky EC2 instances, the entire process can be managed by lightweight Debezium pods.
Managing Media Metadata at Scale
Reddit hosts billions of posts containing various media content such as images, videos, gifs, and embedded third-party media.
Over the years, users have been uploading media content at an accelerating pace. Therefore, media metadata became crucial for enhancing searchability and organization for these assets.
There were multiple challenges with Reddit’s old approach to managing media metadata:
The data was distributed and scattered across multiple systems.
There were inconsistent storage formats and varying query patterns for different asset types. In some cases, they were even querying S3 buckets for the metadata information which is extremely inefficient at Reddit scale.
No proper mechanism for auditing changes, analyzing content, and categorizing metadata.
To overcome these challenges, Reddit built a brand new media metadata store with some high-level requirements:
Move all existing media metadata from different systems under a common roof.
Support data retrieval at the scale of 100K read requests per second with less than 50 ms latency.
Support data creation and updates.
The choice of the data store was between Postgres and Cassandra. Reddit finally went with AWS Aurora Postgres due to the challenges with ad-hoc queries for debugging in Cassandra and the potential risk of some data not being denormalized and unsearchable.
The below diagram shows a simplified overview of Reddit’s media metadata storage system.

As you can see, there’s just a simple service interfacing with the database, handling reads and writes through APIs.
Though the design was not complicated, the challenge lay in transferring several terabytes of data from various sources to the new database while ensuring that the system continued to operate correctly.
The migration process consisted of multiple steps:
Enable dual writes into the metadata APIs from clients of media metadata.
Backfill data from older databases to the new metadata store.
Enable dual reads on media metadata from the service clients.
Monitor data comparison for every read request and fix any data issues.
Ramp up read traffic to the new metadata store.
Check out the below diagram that shows this setup in more detail.

After the migration was successful, Reddit adopted some scaling strategies for the media metadata store.
Table partitioning using range-based partitioning.
Serving reads from a denormalized JSONB field in Postgres.
Ultimately, they achieved an impressive read latency of 2.6 ms at p50, 4.7 ms at p90, and 17 ms at p99. Also, the data store was generally more available and 50% faster than the previous data system.
Just-in-time Image Optimization
Within the media space, Reddit also serves billions of images per day.
Users upload images for their posts, comments, and profiles. Since these images are consumed on different types of devices, they need to be available in several resolutions and formats. Therefore, Reddit transforms these images for different use cases such as post previews, thumbnails, and so on.
Since 2015, Reddit has relied on third-party vendors to perform just-in-time image optimization. Image handling wasn’t their core competency and therefore, this approach served them well over the years.
However, with an increasing user base and traffic, they decided to move this functionality in-house to manage costs and control the end-to-end user experience.
The below diagram shows the high-level architecture for image optimization setup.

They built two backend services for transforming the images:
The Gif2Vid service resizes and transcodes GIFs to MP4s on-the-fly. Though users love the GIF format, it’s an inefficient choice for animated assets due to its larger file sizes and higher computational resource demands.
The image optimizer service deals with all other image types. It uses govips which is a wrapper around the libvips image manipulation library. The service handles the majority of cache-miss traffic and handles image transformations like blurring, cropping, resizing, overlaying images, and format conversions.
Overall, moving the image optimization in-house was quite successful:
Costs for Gif2Vid conversion were reduced to a mere 0.9% of the original cost.
The p99 cache-miss latency for encoding animated GIFs was down from 20s to 4s.
The bytes served for static images were down by approximately 20%.
Real-Time Protection for Users at Reddit’s Scale
A critical functionality for Reddit is moderating content that violates the policies of the platform. This is essential to keep Reddit safe as a website for the billions of users who see it as a community.
In 2016, they developed a rules engine named Rule-Executor-V1 (REV1) to curb policy-violating content on the site in real time. REV1 enabled the safety team to create rules that would automatically take action based on activities like users posting new content or leaving comments.
For reference, a rule is just a Lua script that is triggered on specific configured events. In practice, this can be a simple piece of code shown below:
In this example, the rule checks whether a post’s text body matches a string “some bad text”. If yes, it performs an asynchronous action on the user by publishing an action to an output Kafka topic.
However, REV1 needed some major improvements:
It ran on a legacy infrastructure of raw EC2 instances. This wasn’t in line with all modern services on Reddit that were running on Kubernetes.
Each rule ran as a separate process in a REV1 node and required vertical scaling as more rules were launched. Beyond a certain point, vertical scaling became expensive and unsustainable.
REV1 used Python 2.7 which was deprecated.
Rules weren’t version-controlled and it was difficult to understand the history of changes.
Lack of staging environment to test out the rules in a sandboxed manner.
In 2021, the Safety Engineering team within Reddit developed a new streaming infrastructure called Snooron. It was built on top of Flink Stateful Functions to modernize REV1’s architecture. The new system was known as REV2.
The below diagram shows both REV1 and REV2.

Some of the key differences between REV1 and REV2 are as follows:
In REV1, all configuration of rules was done via a web interface. With REV2, the configuration primarily happens through code. However, there are UI utilities to make the process simpler.
In REV1, they use Zookeeper as a store for rules. With REV2, rules are stored in Github for better version control and are also persisted to S3 for backup and periodic updates.
In REV1, each rule had its own process that would load the latest code when triggered. However, this caused performance issues when too many rules were running at the same time. REV2 follows a different approach that uses Flink Stateful Functions for handling the stream of events and a separate Baseplate application that executes the Lua code.
In REV1, the actions triggered by rules were handled by the main R2 application. However, REV2 works differently. When a rule is triggered, it sends out structured Protobuf actions to multiple action topics. A new application called the Safety Actioning Worker, built using Flink Statefun, receives and processes these instructions to carry out the actions.
Reddit’s Feed Architecture
Feeds are the backbone of social media and community-based websites.
Millions of people use Reddit’s feeds every day and it’s a critical component of the website’s overall usability. There were some key goals when it came to developing the feed architecture:
The architecture should support a high development velocity and support scalability. Since many teams integrate with the feeds, they need to have the ability to understand, build, and test them quickly.
TTI (Time to Interactive) and scroll performance should be satisfactory since they are critical to user engagement and the overall Reddit experience.
Feeds should be consistent across different platforms such as iOS, Android, and the website.
To support these goals, Reddit built an entirely new, server-driven feeds platform. Some major changes were made in the backend architecture for feeds.
Earlier, each post was represented by a Post object that contained all the information a post may have. It was like sending the kitchen sink over the wire and with new post types, the Post object got quite big over time.
This was also a burden on the client. Each client app contained a bunch of cumbersome logic to determine what should be shown on the UI. Most of the time, this logic was out of sync across platforms.
With the changes to the architecture, they moved away from the big object and instead sent only the description of the exact UI elements the client will render. The backend controlled the type of elements and their order. This approach is also known as Server-Driven UI.
For example, the post unit is represented by a generic Group object that contains an array of Cell objects. The below image shows the change in response structure for the Announcement item and the first post in the feed.

Reddit’s Move from Thrift to gRPC
In the initial days, Reddit had adopted Thrift to build its microservices.
Thrift enables developers to define a common interface (or API) that enables different services to communicate with each other, even if they are written in different programming languages. Thrift takes the language-independent interface and generates code bindings for each specific language.
This way, developers can make API calls from their code using syntax that looks natural for their programming language, without having to worry about the underlying cross-language communication details.
Over the years, the engineering teams at Reddit built hundreds of Thrift-based microservices, and though it served them quite well, Reddit’s growing needs made it costly to continue using Thrift.
gRPC came on the scene in 2016 and achieved significant adoption within the Cloud-native ecosystem.
Some of the advantages of gRPC are as follows:
It provided native support for HTTP2 as a transport protocol
There was native support for gRPC in several service mesh technologies such as Istio and Linkerd
Public cloud providers also support gRPC-native load balancers
While gRPC had several benefits, the cost of switching was non-trivial. However, it was a one-time cost whereas building feature parity in Thrift would have been an ongoing maintenance activity.
Reddit decided to make the transition to gRPC. The below diagram shows the design they used to start the migration process:

The main component is the Transitional Shim. Its job is to act as a bridge between the new gRPC protocol and the existing Thrift-based services.
When a gRPC request comes in, the shim converts it into an equivalent Thrift message format and passes it on to the existing code just like native Thrift. When the service returns a response object, the shim converts it back into the gRPC format.
There are three main parts to this design:
The interface definition language (IDL) converter that translates the Thrift service definitions into the corresponding gRPC interface. This component also takes care of adapting framework idioms and differences as appropriate.
A code-generated gRPC servicer that handles the message conversions for incoming and outgoing messages between Thrift and gRPC.
A pluggable module for the services to support both Thrift and gRPC.
This design allowed Reddit to gradually transition to gRPC by reusing its existing Thrift-based service code while controlling the costs and effort required for the migration.
Conclusion
Reddit’s architectural journey has been one of continual evolution, driven by its meteoric growth and changing needs over the years. What began as a monolithic Lisp application was rewritten in Python, but this monolithic approach couldn’t keep pace as Reddit’s popularity exploded.
The company went on an ambitious transition to a service-based architecture. Each new feature and issue they faced prompted a change in the overall design in various areas such as user protection, media metadata management, communication channels, data replication, API management, and so on.
In this post, we’ve attempted to capture the evolution of Reddit’s architecture from the early days to the latest changes based on the available information.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com.