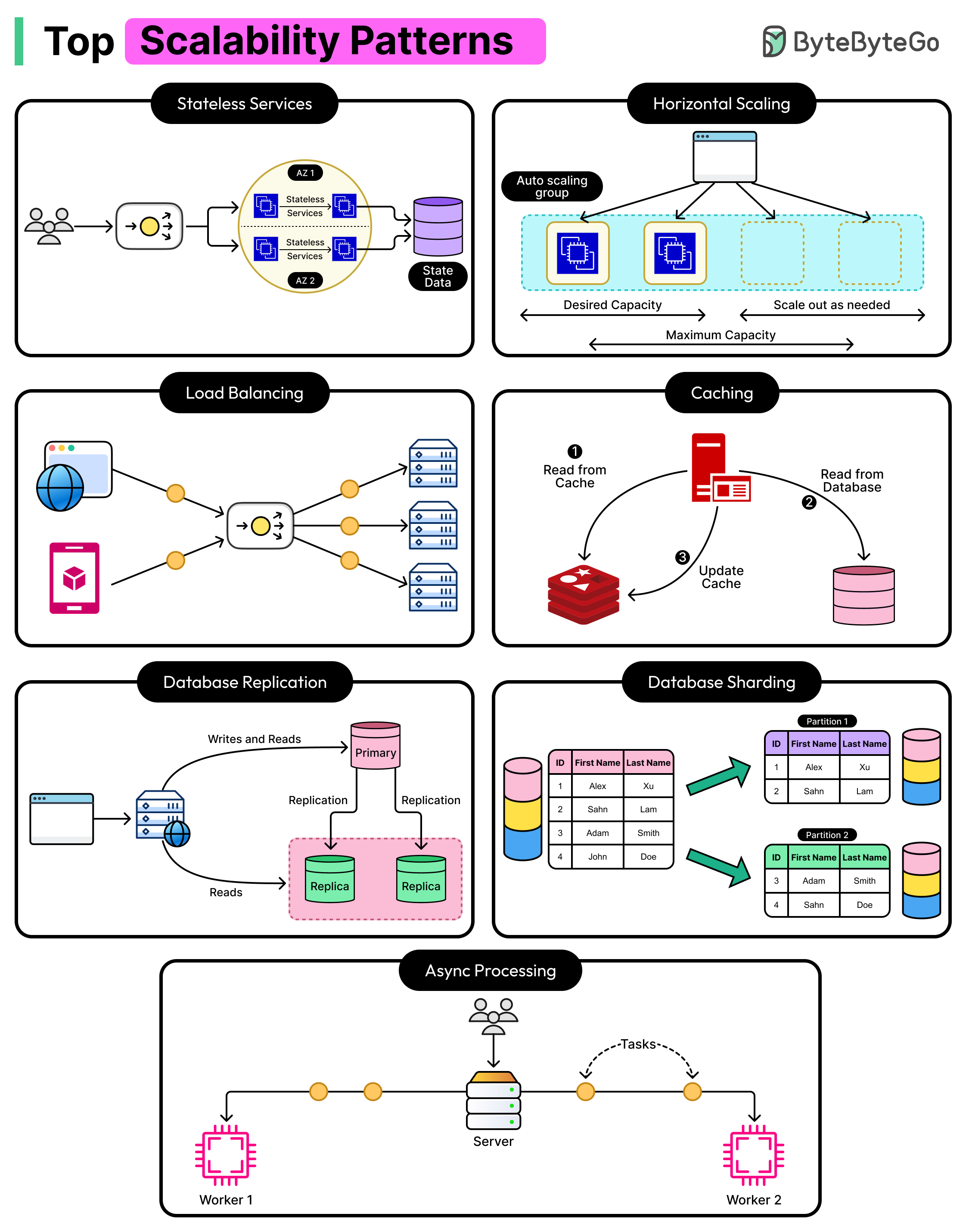
Scalability Patterns for Modern Distributed Systems

When we talk about scalability in system design, we’re talking about how well a system can handle growth.
A scalable system can serve more users, process more data, and handle higher traffic without slowing down or breaking. It means you can increase the system’s capacity and throughput by adding resources (like servers, databases, or storage) while keeping performance, reliability, and cost under control. Think of scalability as a measure of how gracefully a system grows. A small application running on one server might work fine for a few thousand users, but if a million users arrive tomorrow, it could start to fail under pressure.
A scalable design allows you to add more servers or split workloads efficiently so that the system continues to perform well, even as demand increases. There are two main ways to scale a system: vertical scaling and horizontal scaling. Here’s what they mean:
Vertical scaling (or scaling up) means upgrading a single machine by adding more CPU, memory, or storage to make it stronger. This is simple to do but has limits. Eventually, a single machine reaches a maximum capacity, and scaling further becomes expensive or impossible.
Horizontal scaling (or scaling out) means adding more machines to share the workload. Instead of one powerful server, we have many regular servers working together. This approach is more flexible and is the foundation of most modern large-scale systems like Google, Netflix, and Amazon.
However, scalability is not just about adding hardware. It’s about designing software and infrastructure that can make effective use of that hardware. Poorly written applications or tightly coupled systems may not scale even if you double or triple the number of servers.
When evaluating scalability, we also need to look beyond simple averages. Metrics like p95 and p99 latency show how the slowest 5% or 1% of requests perform. These tail latencies are what users actually feel during peak times, and they reveal where the system truly struggles under load.
Similarly, error budgets help teams balance reliability and innovation. They define how much failure is acceptable within a given time period. For example, a 99.9% uptime target still allows about 43 minutes of downtime per month. Understanding these numbers helps teams make practical trade-offs instead of chasing perfection at the cost of progress.
In this article, we will look at the top scalability patterns and their pros and cons.