Strong Consistency In Databases: Promises and Costs

If a database stores data on three servers in three different cities, and we write a new value, when exactly is that write “done”? Does it happen when the first server saves it? Or when all three have it? Or when two out of three confirm?
The answer to this question is quite important. Consider a simple bank transfer where we move $500 from savings to checking. We see the updated balance on our phone. But our partner, checking the same account from their laptop in another city, still sees the old balance. For a few seconds, the household has two different versions of the truth. For something similar to a like count on social media, that kind of temporary disagreement is harmless. For a bank balance, it’s a different story.
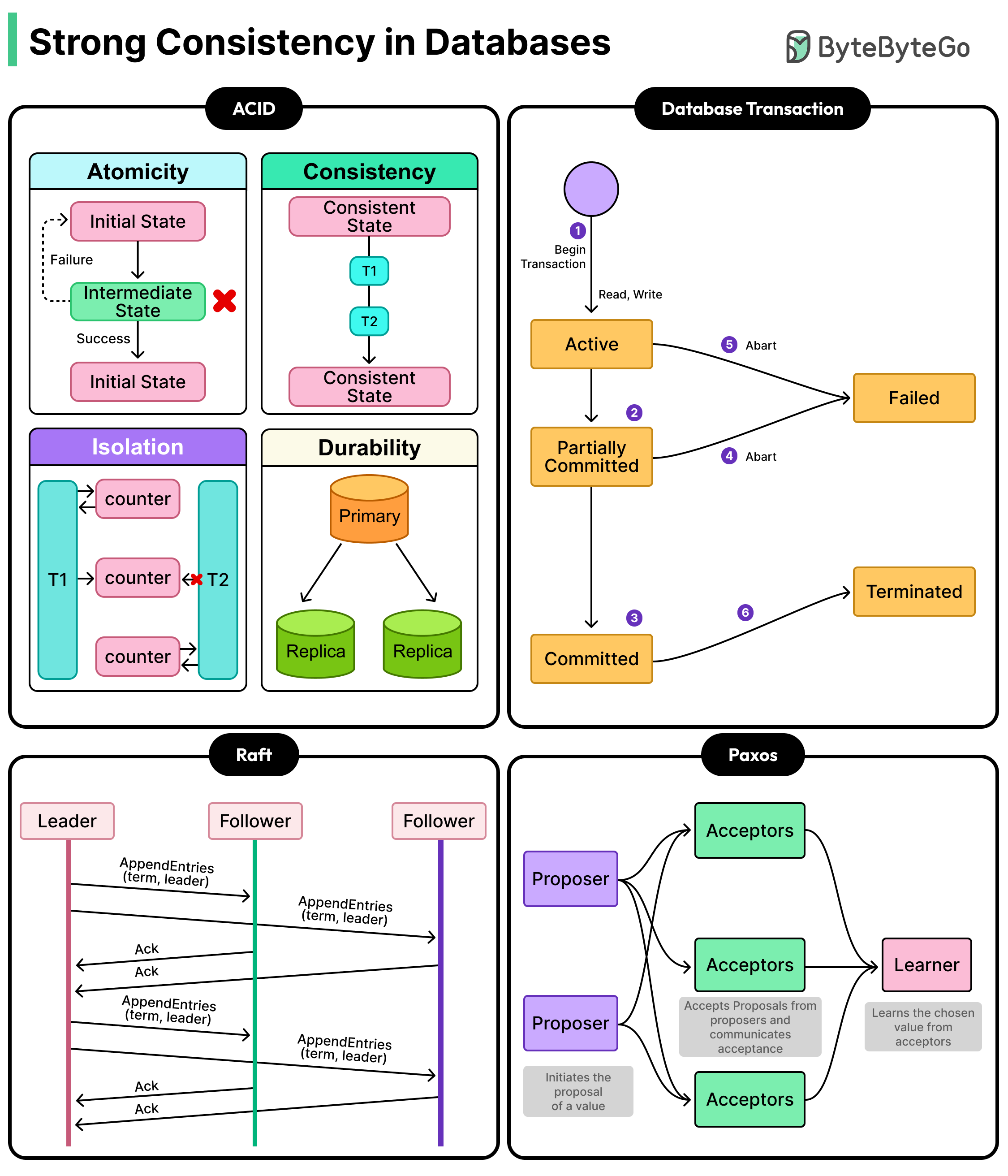
The guarantee that every reader sees the most recent write, no matter where or when they read, is what distributed systems engineers call strong consistency. It sounds straightforward. Making it work across machines, data centers, and continents is one of the hardest problems in distributed systems, because it requires those machines to coordinate, and coordination has a cost governed by physics.
In a previous article, we had looked at eventual consistency. In this article, we will look at what strong consistency actually means, how systems deliver it, and what it really costs.