
The $250 Million Paper

Build product instead of babysitting prod. (Sponsored)

Engineering teams at Coinbase, MSCI, and Zscaler have at least one thing in common: they use Resolve AI’s AI SRE to make MTTR 5x faster and increase dev productivity by up to 75%.
When it comes to production issues, the numbers hurt: 54% of significant outages exceed $100,000 lost. Downtime cost the Global 2000 ~$400 billion annually.
It’s why eng teams leverage our AI SRE to correlate code, infrastructure, and telemetry, and provide real-time root cause analysis, prescriptive remediation, and continuous learning.
Time to try an AI SRE? This guide covers:
The ROI of an AI SRE
Whether you should build or buy
How to assess AI SRE solutions
Recently, a twenty four year old researcher named Matt Deitke received a two hundred and fifty million dollar offer from Meta’s Superintelligence Lab. While the exact details behind this offer are not public, many people believe his work on multimodal models, especially the paper called Molmo, played a major role. Molmo stands out because it shows how to build a strong vision language model from the ground up without relying on any closed proprietary systems. This is rare in a landscape where most open models indirectly depend on private APIs for training data.
This article explains what Molmo is, why it matters, and how it solves a long-standing problem in vision language modeling. It also walks through the datasets, training methods, and architectural decisions that make Molmo unique.
The Core Problem Molmo Solves
Vision language models, or VLMs, are systems like GPT-4o or Google Gemini that can understand images and text together. We can ask them to describe a picture, identify objects, answer questions about a scene, or perform reasoning that requires both visual and textual understanding.
See the diagram below:
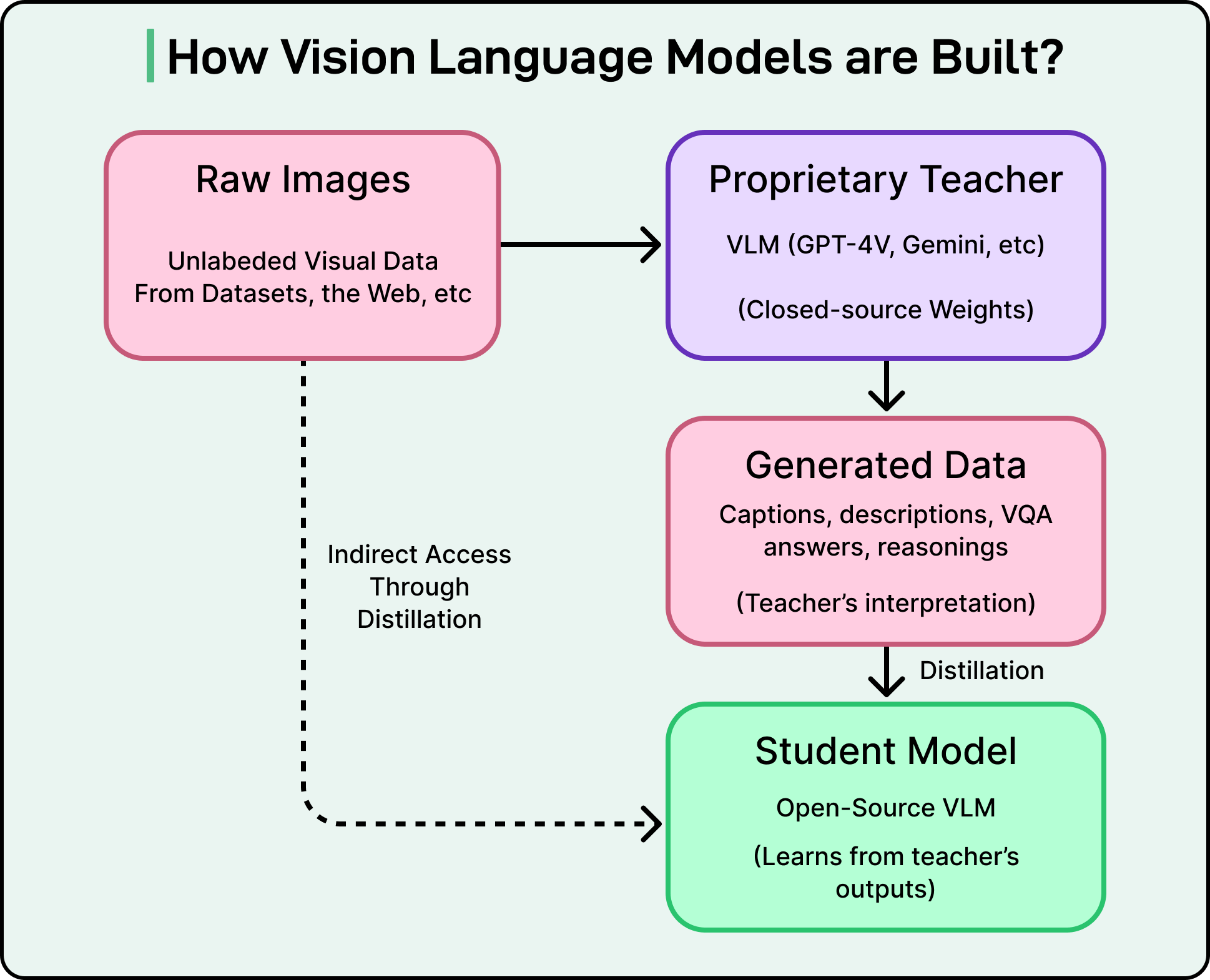
Many open weight VLMs exist today, but most of them rely on a training approach called distillation. In distillation, a smaller student model learns by imitating the outputs of a larger teacher model.
The general process looks like this:
The teacher sees an image.
It produces an output, such as “A black cat sitting on a red couch.”
Researchers collect these outputs.
The student is trained to reproduce the teacher’s answers.
Developers may generate millions of captions using a proprietary model like GPT 4 Vision, then use those captions as training data for an “open” model. This approach is fast and inexpensive because it avoids large-scale human labeling. However, it creates several serious problems.
The first problem is that the result is not truly open. If the student model was trained on labels from a private API, it cannot be recreated without that API. This creates permanent dependence.
The second problem is that the community does not learn how to build stronger models. Instead, it learns how to copy a closed model’s behavior. The foundational knowledge stays locked away.
The third problem is that performance becomes limited. A student model rarely surpasses its teacher, so the model inherits the teacher’s strengths and weaknesses.
This is similar to copying a classmate’s homework. It might work for the moment, but we do not gain the underlying skill, and if the classmate stops helping, we are stuck.
Molmo was designed to break this cycle. It is trained entirely on datasets that do not rely on existing VLMs. To make this possible, the authors also created PixMo, a suite of human-built datasets that form the foundation for Molmo’s training.
The PixMo Datasets
PixMo is a collection of seven datasets, all created without using any other vision language model. The goal of PixMo is to provide high-quality, VLM-free data that allows Molmo to be trained from scratch.
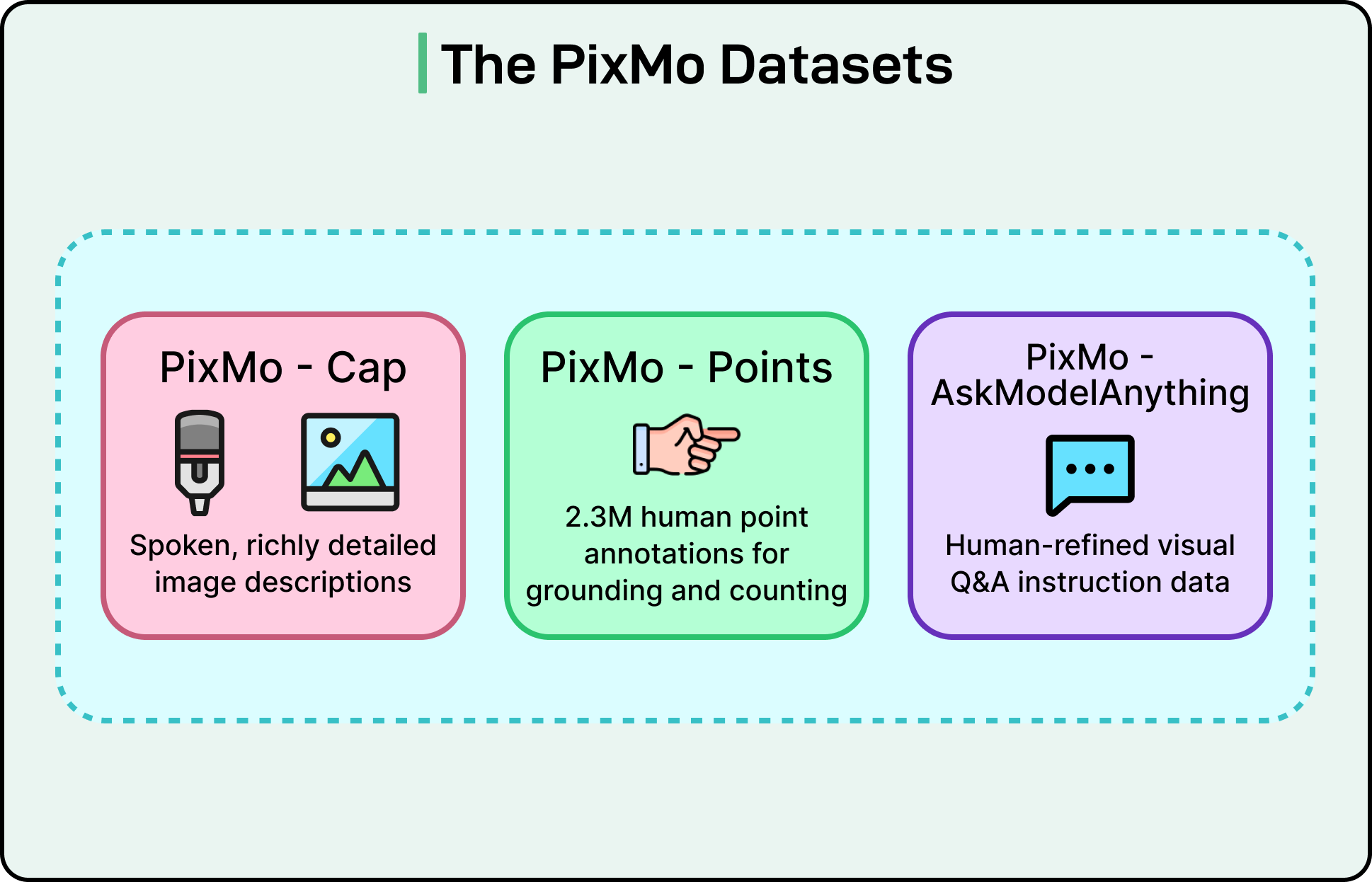
There are three main components of PixMo datasets:
PixMo Cap: Dense Captions
For pre-training, Molmo needed rich descriptions of images. Typing long captions is slow and tiring, so the researchers used a simple but powerful idea. They asked annotators to speak about each image for sixty to ninety seconds instead of typing.
People naturally describe more when speaking. The resulting captions averaged one hundred and ninety-six words. This is far more detailed than typical datasets like COCO, where captions average around eleven words. The audio was then transcribed, producing a massive dataset of high-quality text. The audio recordings also serve as proof that real humans generated the descriptions.
These long captions include observations about lighting, background blur, object relationships, subtle visual cues, and even artistic style. This gives Molmo a deeper understanding of images than what short captions can provide.
PixMo Points: Pointing and Grounding
PixMo Points may be the most innovative dataset in the project. The team collected more than two point three million point annotations.
Each annotation is simply a click on a specific pixel in the image. Since pointing is faster than drawing bounding boxes or segmentation masks, the dataset could scale very quickly.
The point annotations teach Molmo three important abilities:
Pointing to objects.
Counting objects by pointing to each one.
Providing visual explanations by showing where ethe vidence is located.
This dataset helps the model connect language to precise spatial areas, making it better at grounding its understanding in the image.
PixMo AskModelAnything: Instruction Following
This dataset provides pairs of questions and answers about images. It was created through a human-supervised process.
The steps are:
A human annotator writes a question about the image.
A language-only LLM produces a draft answer based on OCR text and the dense caption.
The annotator reviews the answer.
The annotator may accept it, reject it, or ask for a revised version.
Since the LLM only sees text and never sees the image itself, the dataset remains VLM-free. Every answer is human-approved.
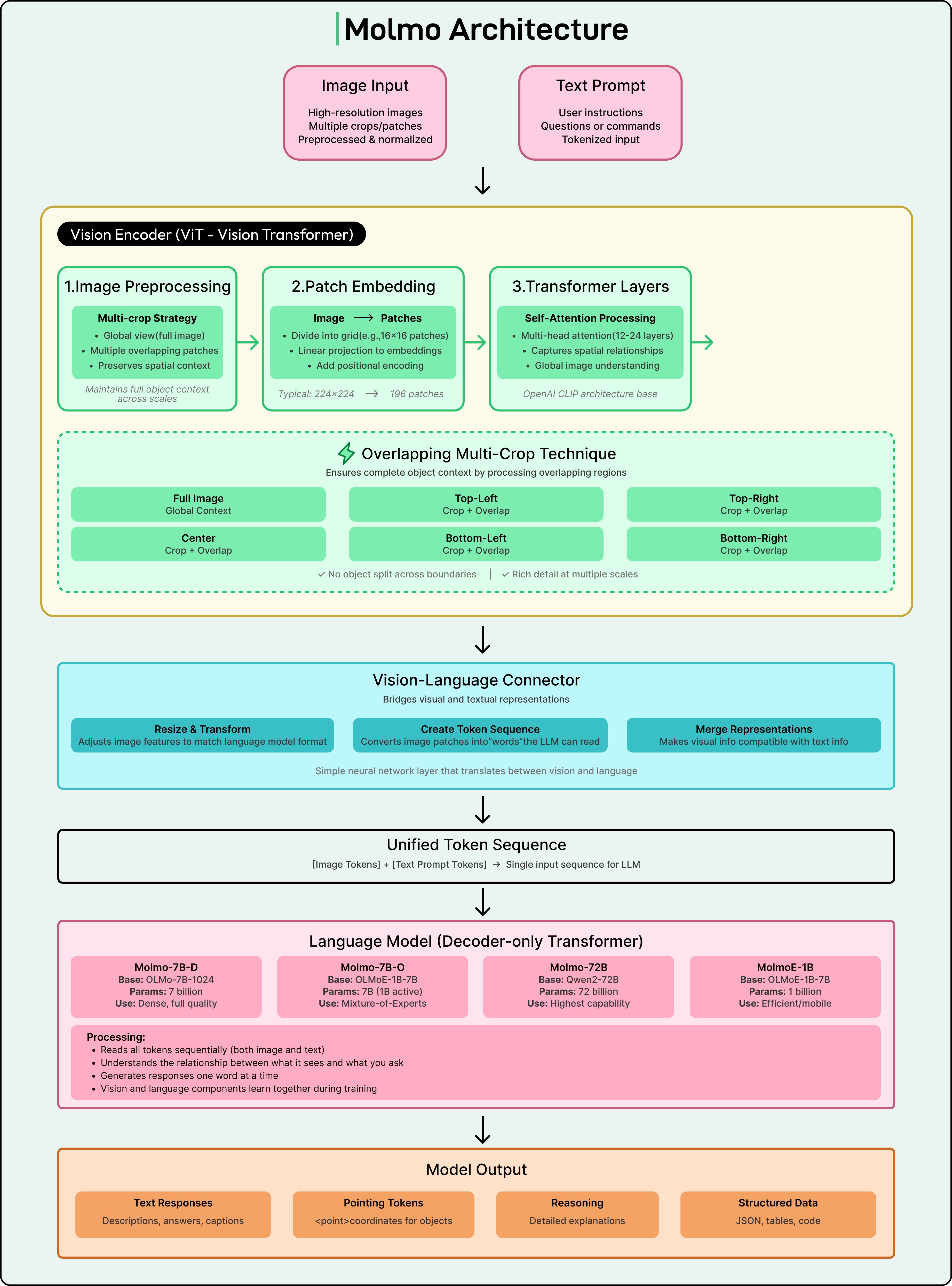
Molmo Architecture and Training
Molmo uses the common structure seen in most vision language models.
A Vision Transformer acts as the vision encoder. A large language model handles reasoning and text generation. A connector module aligns visual and language features so both parts can work together.
Although this architecture is standard, Molmo’s training pipeline contains several smart engineering decisions.
One important idea is the overlapping multi-crop strategy. High-resolution images are too large to be processed at once, so they are split into smaller square crops. This can accidentally cut important objects in half. Molmo solves this by letting the crops overlap so that any object on the border of one crop appears fully in another. This helps the model see complete objects more consistently.
Another improvement comes from the quality of PixMo Cap. Many VLMs need a long connector training stage using noisy web data. Molmo does not need this stage because the PixMo Cap dataset is strong enough to train directly. This makes training simpler and reduces noise.
The authors also designed an efficient method for images with multiple questions. Instead of feeding the same image through the model again and again, they encode the image once and then process all questions in a single masked sequence. This reduces training time by more than half.
Molmo also uses text-only dropout during pre-training. Sometimes the model does not get to see the text tokens, so it must rely more heavily on visual information. This prevents it from predicting the next token simply through language patterns and strengthens true visual understanding.
Each of these choices supports the others and increases the value obtained from the dataset.
Molmo’s Advantages
The key advantages provided by Molmo are as follows:
Strong understanding of superior data
The spoken word captions in PixMo Cap give Molmo a richer base of visual knowledge.
Instead of learning from short captions like “A brown dog catching a frisbee,” Molmo sees long descriptions that mention lighting conditions, camera angle, background blur, object texture, emotional cues, and implied motion. This leads to deeper and more detailed visual representations.
New reasoning abilities through pointing
The PixMo Points dataset unlocks new forms of reasoning.
For example, when asked “How many cars are in this image?” many VLMs simply guess a number. Molmo performs a step-by-step process. It points to each car one by one and then gives the final count. This makes the reasoning visible and easy to verify. It also makes errors easier to fix and opens the door to future systems that require pixel-level instructions, such as robots.
Better synergy between data and training
Molmo’s success comes from a combination of high-quality data and a training pipeline built to maximize that data.
Overlapping crops help preserve detail. Efficient batching uses more instruction data in less time. Text-only dropout forces the model to learn from the image. High-quality captions reduce the need for noisy training stages.
These elements reinforce one another and create a cleaner, more effective approach to multimodal training.
Conclusion
The Molmo and PixMo project shows that it is possible to build a powerful vision language model without copying proprietary systems.
It demonstrates that high-quality human data can outperform synthetic data produced by closed models. It also highlights how thoughtful dataset design can simplify training and improve results at the same time.
This first principles approach may be one reason why the work attracted strong interest from a major AI lab. It offers a way for the research community to build strong, reproducible, and truly open multimodal models.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
“Instead of learning from short captions like “A brown dog catching a frisbee,” Molmo sees long descriptions that mention lighting conditions, camera angle, background blur, object texture, emotional cues, and implied motion. This leads to deeper and more detailed visual representations.”
Thanks for putting this in an easy to understand way. This made a lot of sense.
Vn