
The Architecture Behind Open-Source LLMs

npx workos: An AI Agent That Writes Auth Directly Into Your Codebase (Sponsored)

npx workos launches an AI agent, powered by Claude, that reads your project, detects your framework, and writes a complete auth integration directly into your existing codebase. It’s not a template generator. It reads your code, understands your stack, and writes an integration that fits.
The WorkOS agent then typechecks and builds, feeding any errors back to itself to fix.
In December 2024, DeepSeek released V3 with the claim that they had trained a frontier-class model for $5.576 million. They used an attention mechanism called Multi-Head Latent Attention that slashed memory usage. An expert routing strategy avoided the usual performance penalty. Aggressive FP8 training cuts costs further.
Within months, Moonshot AI’s Kimi K2 team openly adopted DeepSeek’s architecture as their starting point, scaled it to a trillion parameters, invented a new optimizer to solve a training stability challenge that emerged at that scale, and competed with it across major benchmarks.
Then, in February 2026, Zhipu AI’s GLM-5 integrated DeepSeek’s sparse attention mechanism into their own design while contributing a novel reinforcement learning framework.
This is how the open-weight ecosystem actually works: teams build on each other’s innovations in public, and the pace of progress compounds. To understand why, you need to look at the architecture.
In this article, we will cover various open-source models and the engineering bets that define each one.
The Common Skeleton
Every major open-weight LLM released at the frontier in 2025 and 2026 uses a Mixture-of-Experts (MoE) transformer architecture.
See the diagram below that shows the concept of the MoE architecture:
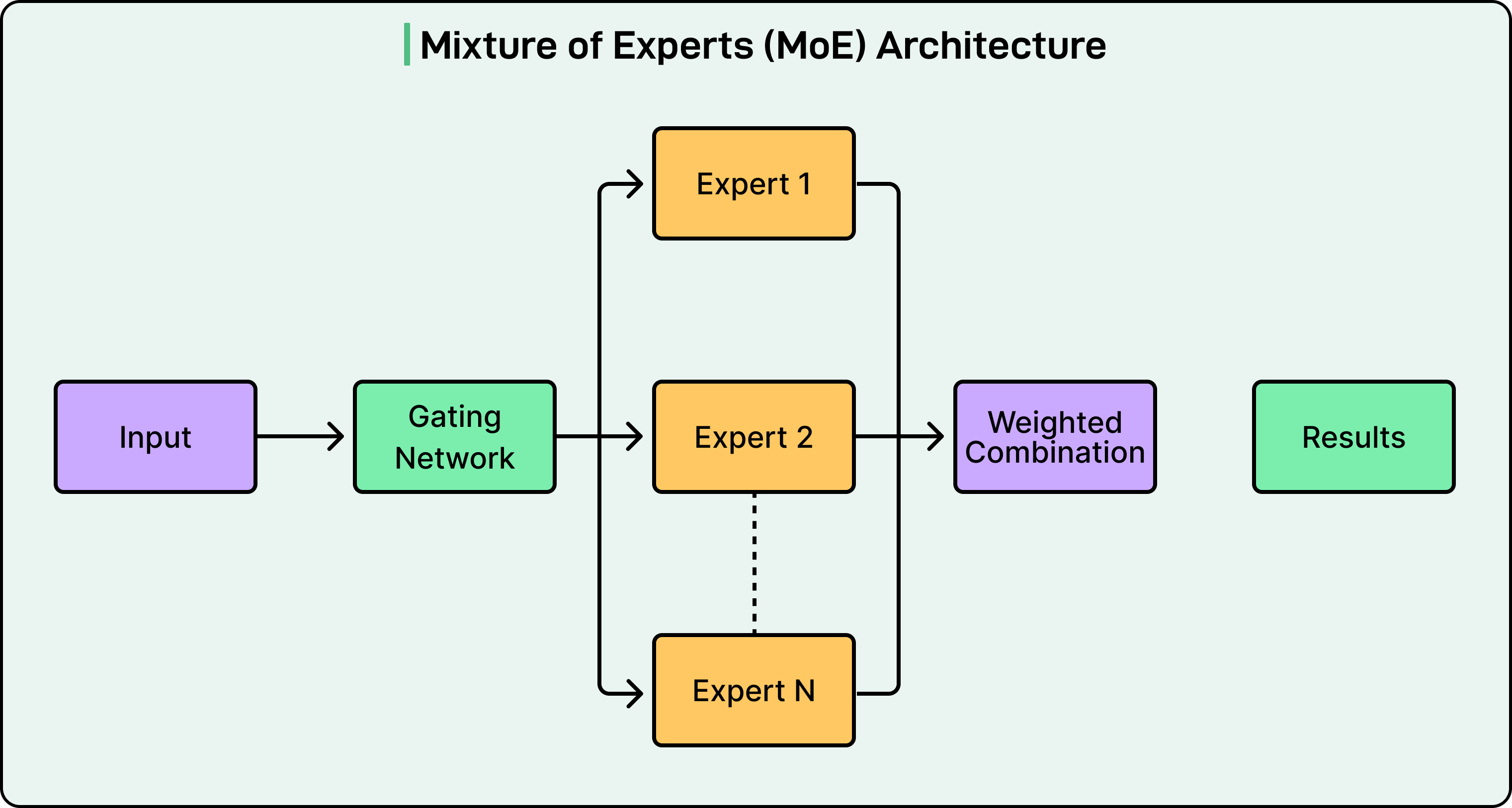
The reason is that dense transformers activate all parameters for every token. To make a denser model smarter, if you add more parameters, the computational cost scales linearly. With hundreds of billions of parameters, this becomes prohibitive.
MoE solves this by replacing the monolithic feed-forward layer in each transformer block with multiple smaller “expert” networks and a learned router that decides which experts handle each token. This result is a model that can, for example, store the knowledge of 671 billion parameters but only compute 37 billion per token.
This is why two numbers matter for every model:
Total parameters (memory footprint, knowledge capacity)
Active parameters (inference speed, per-token cost).
Think of a specialist hospital with 384 doctors on staff, but only 8 in the room for any given patient. You benefit from the knowledge of 384 specialists while only paying for 8 at a time. The triage nurse (the router) decides who gets called.
That’s also why a trillion-parameter model and a 235-billion-parameter model cost roughly the same per query. For example, Kimi K2 activates 32 billion parameters per token, while Qwen3 activates 22 billion. In other words, you’re comparing the active counts, not the totals.
Granola MCP (Sponsored)

Take your meeting context to new places
If you’re already using Claude or ChatGPT for complex work, you know the drill: you feed it research docs, spreadsheets, project briefs... and then manually copy-paste meeting notes to give it the full picture.
What if your AI could just access your meeting context automatically?
Granola’s new Model Context Protocol (MCP) integration connects your meeting notes to your AI app of choice.
Ask Claude to review last week’s client meetings and update your CRM. Have ChatGPT extract tasks from multiple conversations and organize them in Linear. Turn meeting insights into automated workflows without missing a beat.
Perfect for engineers, PMs, and operators who want their AI to actually understand their work.
-> Try the MCP integration for free here or use the code BYTEBYTEGO
The Open Weight Reality
Almost every model marketed as “open source” is technically open weight. This means that the trained parameters are public, but the training data and often the full training code are not. In traditional software, however, “open source” means code is available, modifiable, and redistributable.
What does this mean in practice?
You can download, fine-tune, and commercially deploy all six of these models. However, you cannot see or audit their training data, and you cannot reproduce their training runs from scratch. For most engineering teams, the first part is what matters. But the distinction is worth knowing.
The license landscape also varies. DeepSeek V3 and GLM-5 use the MIT license. Qwen3 and Mistral Large 3 use Apache 2.0. Both are fully permissive for commercial use. Kimi K2 uses a modified MIT license. Llama 4 uses a custom community license that restricts usage for companies with over 700 million monthly users and prohibits using the model to train competing models.
Transparency also varies. Some teams publish detailed technical reports with architecture diagrams, ablation studies, and hyperparameters. Others provide weights and a blog post with less architectural detail. More transparency enables the “borrow and build” dynamic described above, which is part of why it works.
The Attention Bet
Every time a model generates a token, it needs to “remember” keys and values for all previous tokens in the conversation. This storage, called the KV-cache, grows linearly with sequence length and becomes a memory bottleneck for long contexts. Different models use three different strategies to deal with it.
Grouped-Query Attention (GQA) shares key-value pairs across groups of query heads. It’s the industry default, offering straightforward implementation and moderate memory savings. Qwen3 and Llama 4 both use GQA.
Multi-Head Latent Attention (MLA) compresses key-value pairs into a low-dimensional latent space before caching, then decompresses when needed. It was introduced in DeepSeek V2 and used in both DeepSeek V3 and Kimi K2. MLA saves more memory than GQA but adds computational overhead for the compress/decompress step.
Sparse Attention skips attending to all previous tokens and instead selects the most relevant ones. DeepSeek introduced DeepSeek Sparse Attention (DSA) in V3.2, and GLM-5 openly adopted DSA in its architecture. Since sparse attention optimizes the attention layers while MoE optimizes the feed-forward layers, the two techniques compound. Therefore, GLM-5 benefits from both.
See the diagram below that shows DeepSeek’s Multi-Head Latent Attention approach:
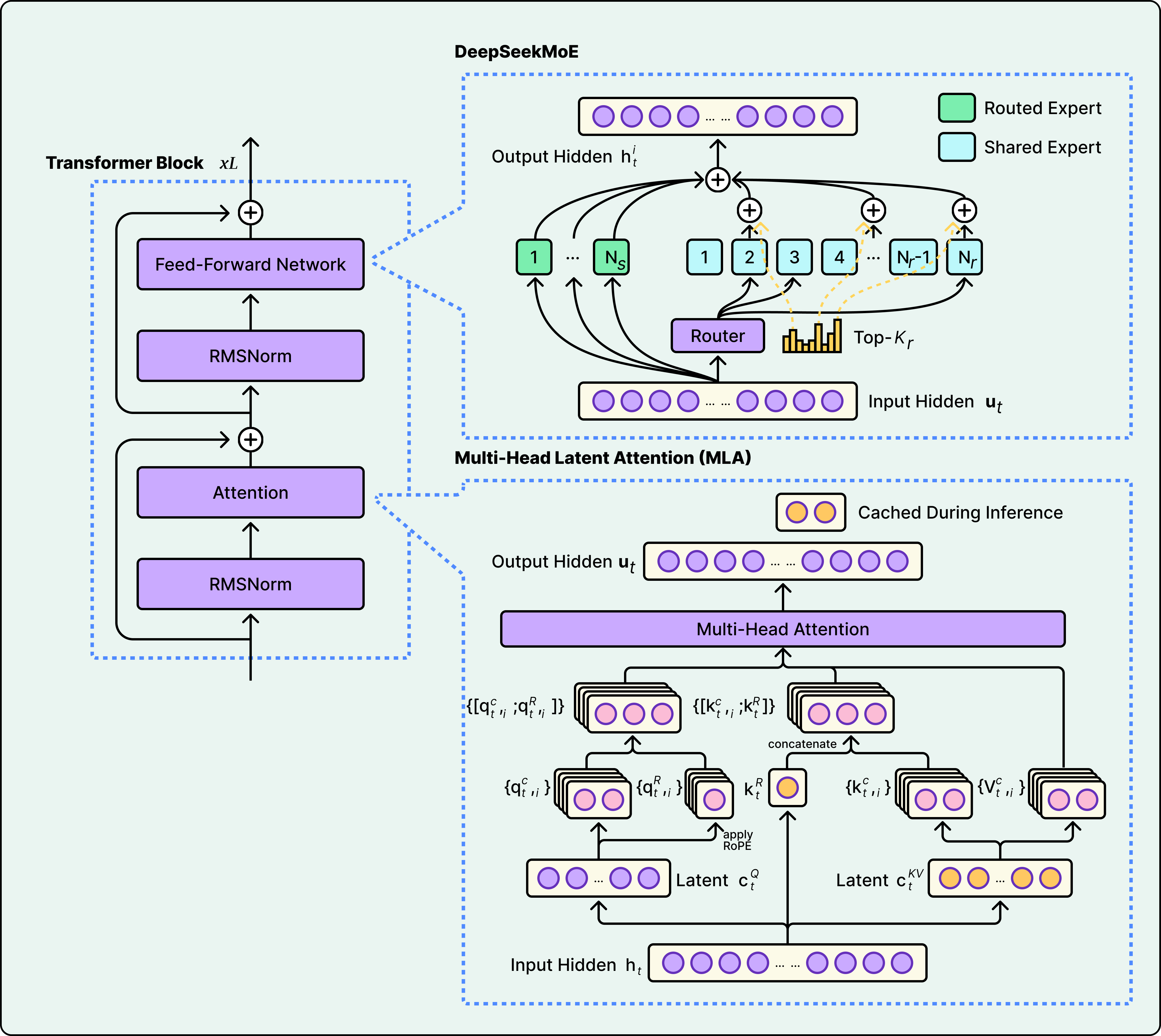
The tradeoff comes down to what matters most in your deployment. GQA is simpler and proven. MLA is more memory-efficient but more complex to engineer. Sparse attention reduces compute for long contexts but requires careful design to avoid missing important tokens. The strategy a model chooses depends on whether the bottleneck is memory, compute, or context length.
The Sparsity Bet
The six models range from 16 to 384 experts, reflecting a fundamental disagreement about how far sparsity should be pushed.
At a fixed compute budget, increasing the number of experts can improve both training and validation loss. However, the report also notes that this gain comes with increased infrastructure complexity. More total experts means more total parameters stored in memory, and Kimi K2’s trillion parameters require a multi-GPU cluster regardless of how few fire per token. By contrast, Llama 4 Scout’s 109 billion total parameters can fit on a single high-memory server.
Two other design choices stand out:
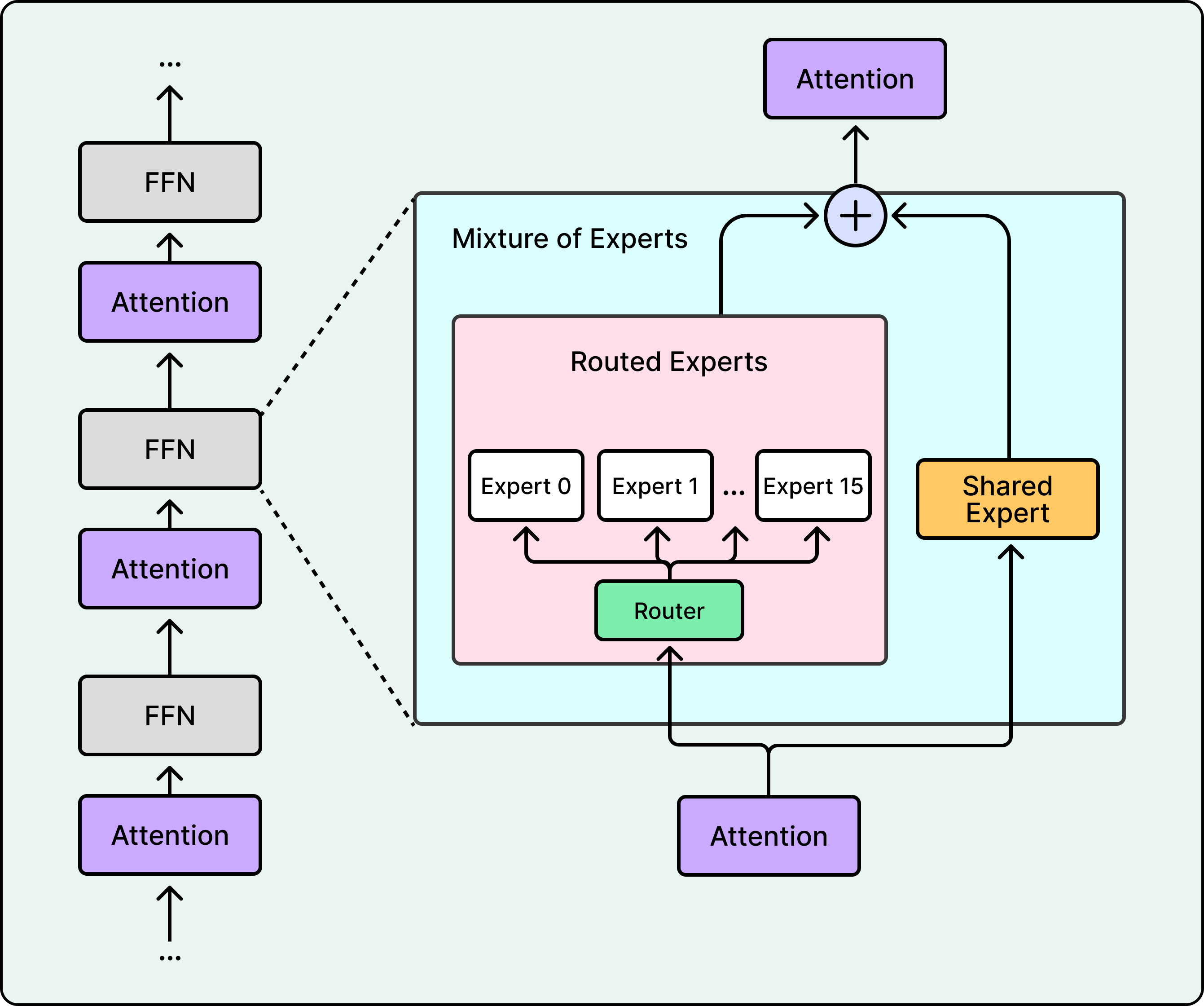
First, the shared expert question. DeepSeek V3, Llama 4, and Kimi K2 include a shared expert that processes every token, providing a baseline capability floor. Qwen3’s technical report notes that, unlike their earlier Qwen2.5-MoE, they dropped the shared expert, but doesn’t disclose why. There is no consensus in the field on whether shared experts are worth the compute cost.
Second, Llama 4 takes a unique approach. Rather than making every layer MoE, Llama 4 alternates between dense and MoE layers, and routes each token to only 1 expert (plus the shared) rather than 8. This means fewer active experts per token, but each expert is larger.
See the diagram below that shows Llama’s approach:
The Training Bet
Architecture determines capacity, but training determines what a model actually does with it.
Pre-training, where the model learns by predicting the next token across trillions of tokens, gives the model its base knowledge. The scale varies (14.8 trillion tokens for DeepSeek V3, up to 36 trillion for Qwen3), but the approach is similar. Post-training is where models diverge, and it’s now the primary differentiator.
Reinforcement learning with verifiable rewards checks whether the model’s output is objectively correct.
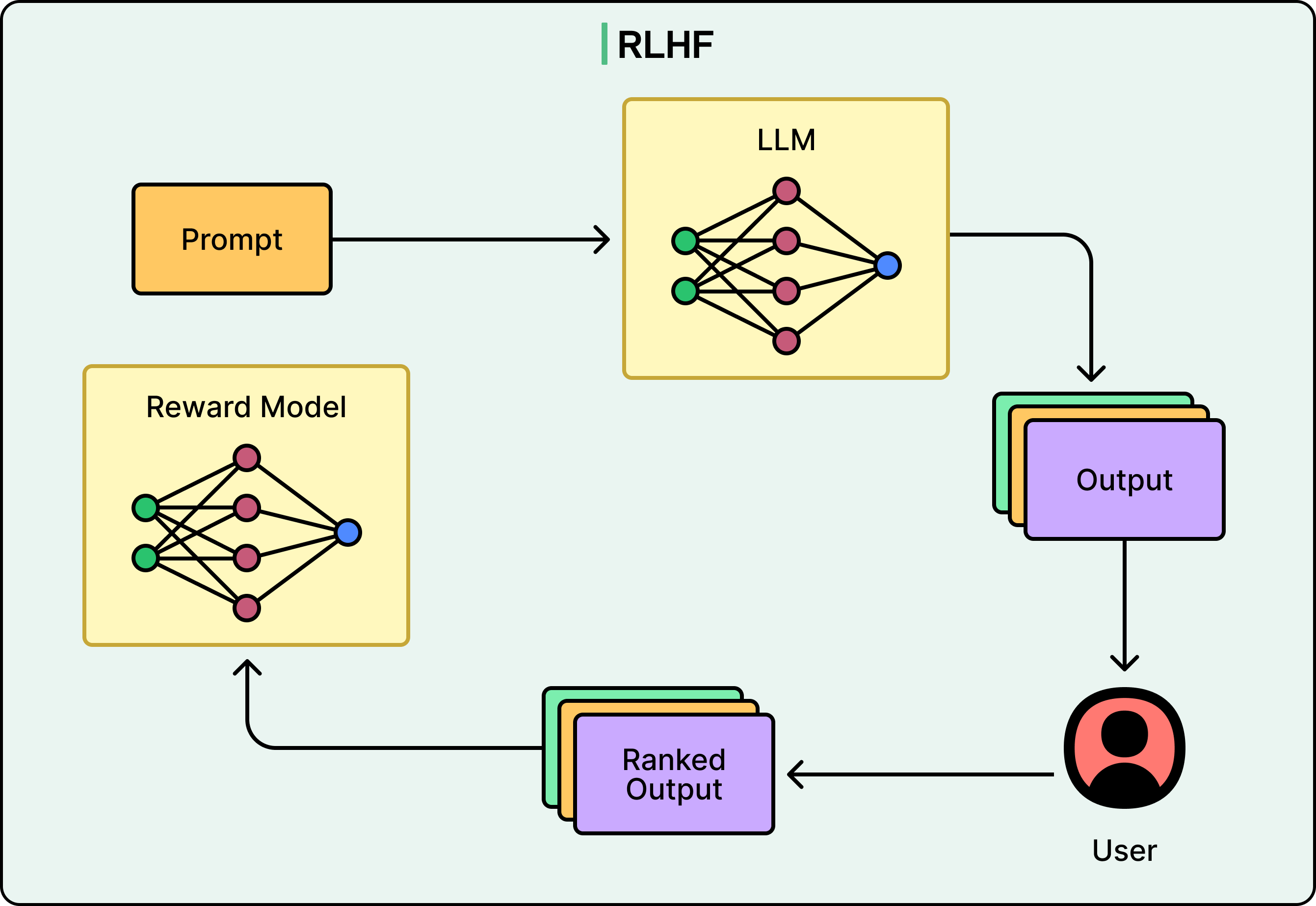
Did the code compile? Is the math answer right? The model is rewarded for correct outputs and penalized for wrong ones. This was the breakthrough behind DeepSeek R1, and elements of it were distilled into DeepSeek V3.
Distillation from a larger teacher trains a massive model and uses its outputs to teach smaller ones. Llama 4 co-distilled from Behemoth, a 2-trillion-parameter teacher model, during pre-training itself. Qwen3 distills from its flagship down to smaller models in the family.
See the diagram below that shows Qwen’s post-training flow:
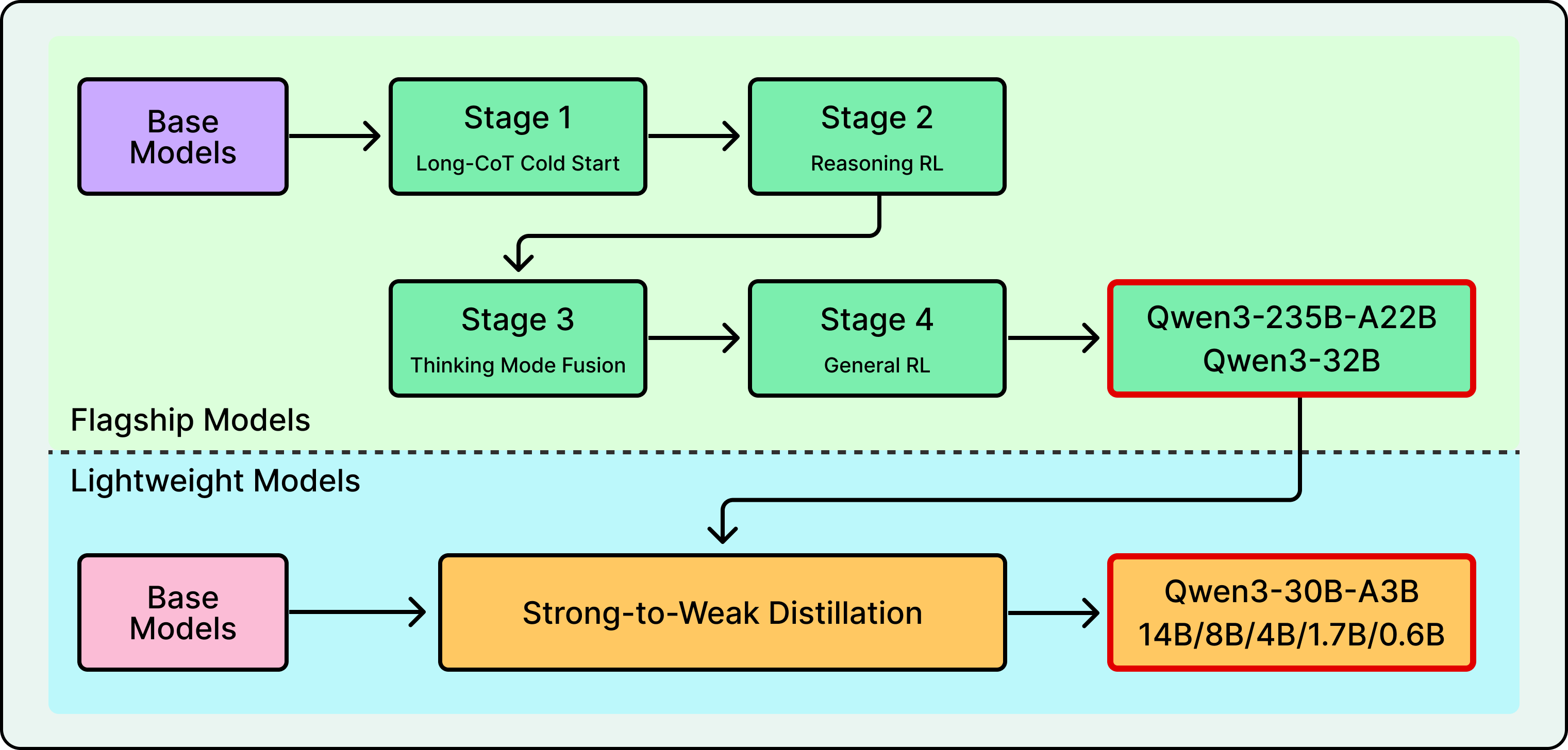
Synthetic agentic data involves building simulated environments loaded with real tools like APIs, shells, and databases, then rewarding the model for completing tasks in those environments. For example, Kimi K2’s technical report describes a large-scale pipeline that systematically generates tool-use demonstrations across simulated and real-world environments.
Novel RL infrastructure can be a contribution in itself. GLM-5 developed “Slime,” a new asynchronous reinforcement learning framework that improves training throughput for post-training, enabling more iterations within the same compute budget.
Training stability also deserves attention here. At this scale, a single training crash can waste days of GPU time. To counter this, Kimi K2 developed the MuonClip optimizer specifically to prevent exploding attention logits, enabling them to train on 15.5 trillion tokens without a single loss spike. DeepSeek V3 similarly reported zero irrecoverable loss spikes across its entire training run. These engineering contributions may prove more reusable than any particular architectural choice.
Conclusion
Architectures are converging. Everyone is building MoE transformers. Training approaches are diverging, with teams placing different bets on reinforcement learning, distillation, synthetic data, and new optimizers.
The specific models covered here will be overtaken in months. However, the framework for evaluating them likely won’t change.
Important questions would still be about active parameter count and not just the total. Also, what attention tradeoff did they make, and does it match the context-length needs? How many experts fire per token, and can the infrastructure handle the total? How was it post-trained, and does that approach align with your use case? What does the license actually permit?
References:
The part about the "Death of Open Source" licenses really hits home when you're trying to scale a microservice that relies on heavy image processing. We’ve been debating internally whether to self-host a background removal model or just stick with an API, and the maintenance overhead for a custom GPU cluster is usually what kills the "free" aspect of open source. I’ve been using https://bestphotos.ai/background-remover for some of our production testing lately specifically because the latency is lower than what we were getting with our own self-hosted Torch instances. It’s a classic architectural trade-off: do you want full control over the source code, or do you actually want a system that scales without a dedicated DevOps team babysitting it 24/7? Curious if anyone here has found a middle ground that doesn't involve the restrictive AGPL licenses mentioned in the piece.
Interesting how this differs from what I saw at the Mistral hackathon last week - their architecture pitch was heavy on MoE efficiency gains, but the actual feel in practice lagged behind the spec sheet.
The gap between architectural novelty and real model behavior is wider than benchmark scores suggest. DeepSeek training for $5.5M while Kimi K2 activates 32B params per token from 1T total - these numbers tell a compelling story about diverging bets.
I wrote about running Mistral head-to-head against other models at the EU hackathon (https://thoughts.jock.pl/p/mistral-ai-honest-review-eu-hackathon-2026) - the architectural gap shows up exactly where the paper predicts it would.