
The Evolution of LinkedIn’s Generative AI Tech Stack

Which LLM is best for your SLDC? (Sponsored)

Think the newest LLM is best for coding? Sonar put leading SOTA models to the test and unveiled insights on GPT-5, Claude Sonnet 4, and Llama 3 in their new expanded analysis. The results may surprise you.
Discover details on:
The shared strengths and flaws of LLMs
Coding archetypes for the leading LLMs
Hidden quality & security risks of using LLMs for code generation
How to select the best model for your needs
A “trust and verify” blueprint to integrate AI safely into your workflow
Download the report today or watch the on-demand webinar for insights to manage your AI coding strategy for scale, quality, and security.
The Evolution of LinkedIn’s Generative AI Tech Stack
Note: This article is written in collaboration with the engineering team of LinkedIn. Special thanks to Karthik Ramgopal, a Distinguished Engineer from the LinkedIn engineering team, for helping us understand the GenAI architecture at LinkedIn. All credit for the technical details and diagrams shared in this article goes to the LinkedIn Engineering Team.
Over the past two years, LinkedIn has undergone a rapid transformation in how it builds and ships AI-powered products.
What began with a handful of GenAI features, such as collaborative articles, AI-assisted Recruiter capabilities, and AI-powered insights for members and customers, has evolved into a comprehensive platform strategy that now involves multiple products. One of the most prominent examples of this shift is Hiring Assistant, LinkedIn’s first large-scale AI agent for recruiters, designed to help streamline candidate sourcing and engagement.
Behind these product launches was a clear motivation to scale GenAI use cases efficiently and responsibly across LinkedIn’s ecosystem.
Early GenAI experiments were valuable but siloed because each product team built its own scaffolding for prompts, model calls, and memory management. This fragmented approach made it difficult to maintain consistency, slowed iteration, and risked duplicating efforts. As adoption grew, the engineering organization recognized the need for a unified GenAI application stack that could serve as the foundation for all future AI-driven initiatives.
The goals of this platform were as follows:
Teams needed to move fast to capitalize on GenAI momentum.
Engineers across LinkedIn should be able to build GenAI features without reinventing basic infrastructure each time.
Trust, privacy, and safety guardrails had to be baked into the stack.
In this article, we look at how LinkedIn’s engineering teams met these goals while building the GenAI setup. We’ll explore how they transitioned from early feature experiments to a robust GenAI platform, and eventually to multi-agent systems capable of reasoning, planning, and collaborating at scale. Along the way, we’ll highlight architectural decisions, platform abstractions, developer tooling, and real insights from the team behind the stack.
Foundations of the GenAI Application Stack
Before LinkedIn could build sophisticated AI agents, it had to establish the right engineering foundations.
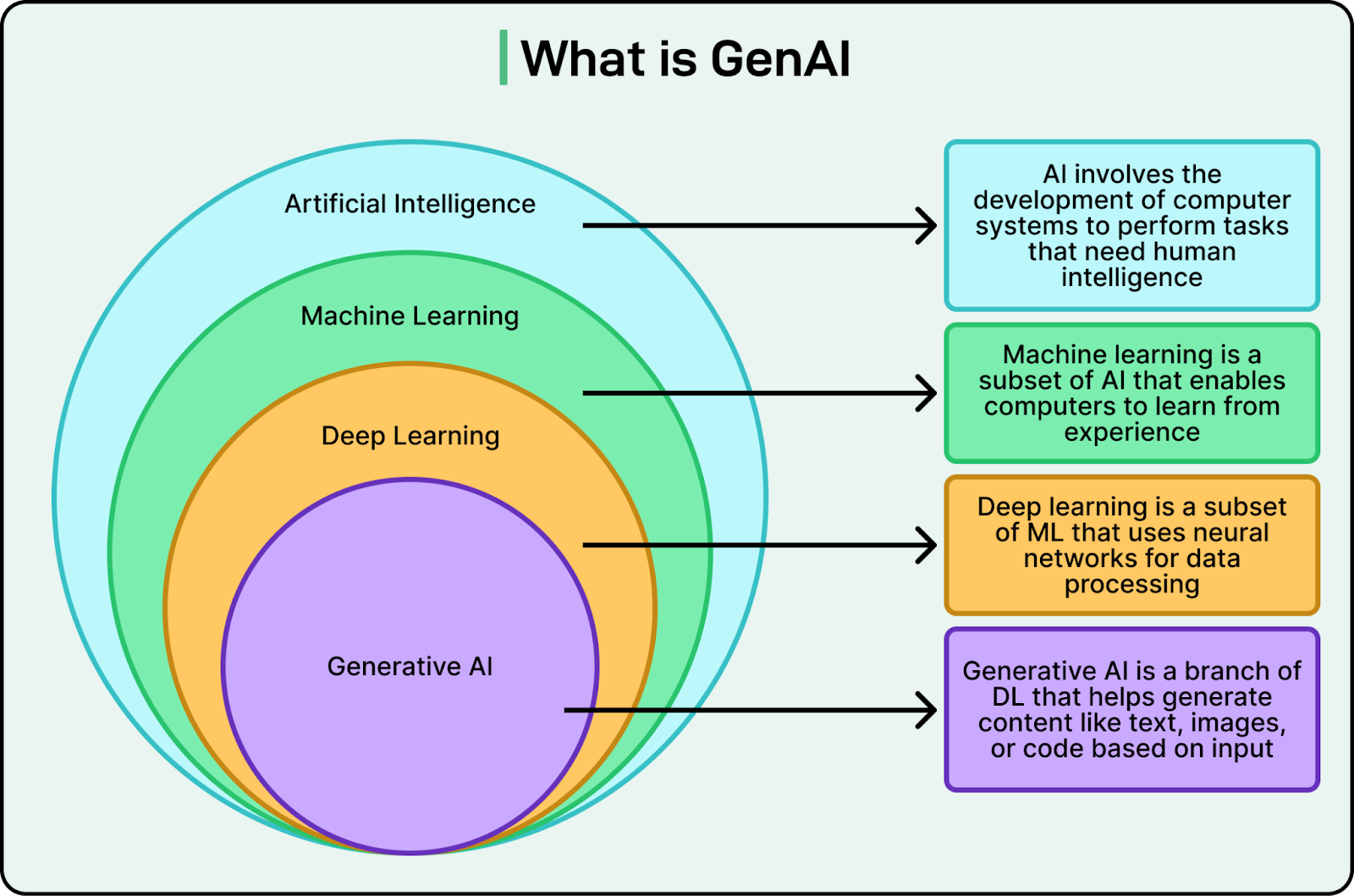
During 2023 and 2024, LinkedIn focused on creating a unified GenAI application stack that could support fast experimentation while remaining stable and scalable. GenAI is a branch of Deep Learning that helps generate content like text, images, or code based on input. The diagram below shows how it relates to other areas like AI and Machine Learning.
1 - The Language and Framework Shift
When LinkedIn started shipping GenAI features, the engineering stack was fragmented.
Online production systems were almost entirely written in Java, while offline GenAI experimentation, including prompt engineering and model evaluation, was taking place in Python. This created constant friction. Engineers had to translate ideas from Python into Java to deploy them, which slowed experimentation and introduced inconsistencies.
To solve this, LinkedIn made a decisive shift to use Python as a first-class language for both offline and online GenAI development. There were three main reasons behind this move:
Ecosystem: Most open-source GenAI tools, frameworks, and model libraries evolve faster in Python.
Developer familiarity: AI engineers were already comfortable building and iterating in Python.
Avoiding duplication: A single language meant fewer translation steps and reduced maintenance overhead.
After internal discussions and some healthy debate, the team created prototypes that demonstrated Python’s velocity advantages. These early wins helped build confidence across the organization, even among teams that had spent years in the Java ecosystem.
However, moving to Python did not mean rewriting all infrastructure at once. Instead, LinkedIn focused on incremental steps, such as:
gRPC over Rest.li: LinkedIn was already planning to transition its RPC layer from Rest.li to gRPC. The GenAI stack aligned with this direction and prioritized gRPC support for Python clients.
REST proxy for storage: Instead of building a native Python client for Espresso (LinkedIn’s distributed document store), the team used an existing REST proxy. This simplified the work while still allowing GenAI apps to interact with data.
Partial request context implementation: The engineering team implemented only the parts of LinkedIn’s complex request-context system that GenAI applications actually needed, rather than porting the entire Java specification. This kept the scope manageable and allowed them to move faster.
To make Python a reliable choice for production systems, LinkedIn invested in developer tooling:
Building Python code natively rather than through legacy Java-based build systems.
Automating the process of importing and maintaining open-source Python libraries internally.
Staying up to date with newer Python language and runtime versions to avoid technical debt.
These steps ensured that Python development at LinkedIn felt natural and productive rather than forced.
Finally, LinkedIn adopted LangChain as its primary GenAI application framework. LangChain provided a structured way to build applications that use large language models, manage prompts, and call external tools.
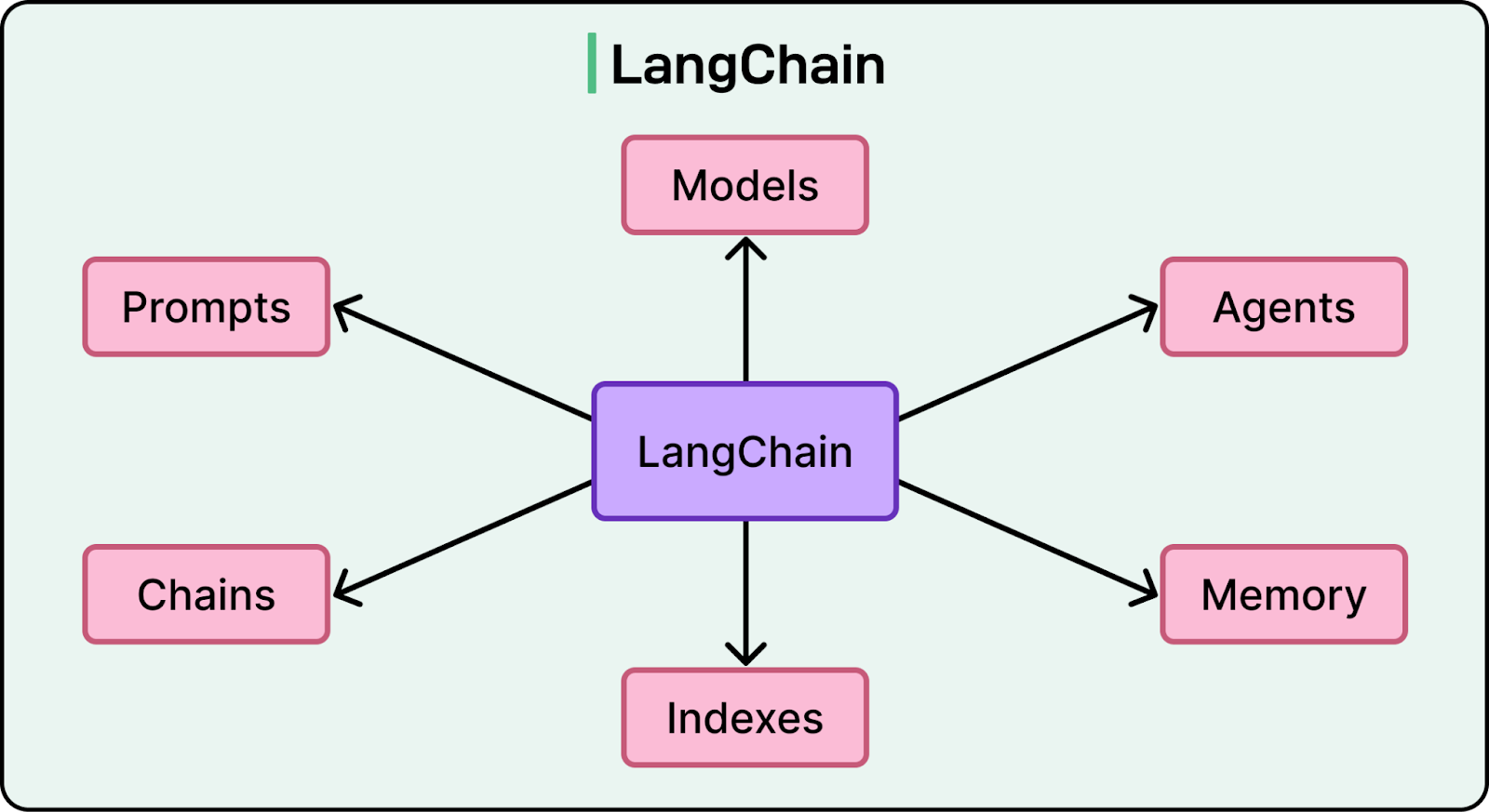
However, this choice was not made lightly. The team conducted a comparative evaluation of multiple frameworks, including AutoGen, LlamaIndex, CrewAI, and even the possibility of building an in-house solution.
The evaluation focused on several criteria such as ecosystem maturity, developer velocity, integration flexibility, production reliability, and the ability to keep up with the fast-moving GenAI landscape. LangChain stood out because it offered a strong ecosystem, active community support, low-level control, and solid abstractions for prompt and tool orchestration, all of which allowed LinkedIn to move quickly without being locked in.
To reduce long-term switching costs, LinkedIn intentionally kept its abstraction layer thin. They wrapped LangChain with internal logging, instrumentation, and storage infrastructure, producing a stable internal library shared across teams. This ensured that if a better framework emerged in the future, migration would be manageable.
2 - Prompt Management
In the earliest GenAI experiments, prompts were simply hardcoded strings in the application code. For example, a recruiter assistant might have a long text prompt written directly in a Java class. This worked for simple cases, but quickly became messy. Managing multiple versions, ensuring prompt quality, and enforcing responsible AI guidelines was difficult.
To address this, LinkedIn built a Prompt Source of Truth system.
Instead of scattering prompts across codebases, prompts were stored and managed centrally using the Jinja templating language. This allowed developers to write prompts with placeholders and expressions, which could be dynamically filled at runtime.
The Prompt Source of Truth introduced several benefits:
Version control: Developers could gradually ramp up new prompt versions to avoid sudden changes in user experience.
Modularization: Shared prompt fragments, such as responsible AI guardrails, could be reused across different applications.
Consistency: All GenAI applications followed the same structure, which reduced bugs and improved reliability.
As conversational interfaces became more common, LinkedIn aligned with the industry standard OpenAI Chat Completions API for handling multi-turn conversations. This made it easier to structure interactions between users and AI systems predictably.
3 - Skills
Prompts alone are not enough for complex applications. Many GenAI use cases require calling APIs or tools to retrieve data or perform actions. LinkedIn introduced a Skills abstraction to handle this in a structured way.
A Skill represents a capability that an LLM can use, such as searching for posts, viewing a member’s profile, or querying analytics systems. Initially, each team wrapped these APIs in custom code. As adoption grew, this led to duplication and version drift.
To fix this, LinkedIn created a skill registry. This is a central service where teams define their skills once, along with a schema and documentation. The build phase plugins can automatically register these skills so that GenAI applications can discover and use them at runtime through LangChain tools. This way, instead of application teams defining which skills they needed, downstream systems define the skills they provide, and applications can then discover and invoke them. This reduced duplication and made it easier to evolve APIs over time.
Skill registry also includes a governance layer to prevent uncontrolled sprawl. During build time, automated similarity checks flag potential duplicates or overlaps. These are then reviewed by human reviewers who act as gatekeepers before a skill is deployed. Skills are segmented by team or use case to maintain clarity and avoid fragmentation. This combination of automated checks and human oversight has been important for keeping the skill ecosystem healthy as it scales.
Apart from this, MCP and A2A have also become foundational protocols for enabling dynamic agent discovery and collaboration across diverse frameworks and distributed environments. MCP empowers agents to explore and interact with the world through tool-based interfaces, while A2A facilitates seamless teamwork among agents. With widespread support from leading model providers like Claude, OpenAI, and Azure, MCP makes it easier for companies to surface and activate their data via standardized interfaces. The team is incrementally adopting these open protocols, moving away from a proprietary skill registry, thereby paving the way for more intelligent, interoperable, and context-aware agent ecosystems.
4 - Memory
Language models do not have memory between calls. If we want them to remember what happened in previous interactions, the functionality needs to be built.
LinkedIn approached this with two complementary systems: Conversational Memory and Experiential Memory.
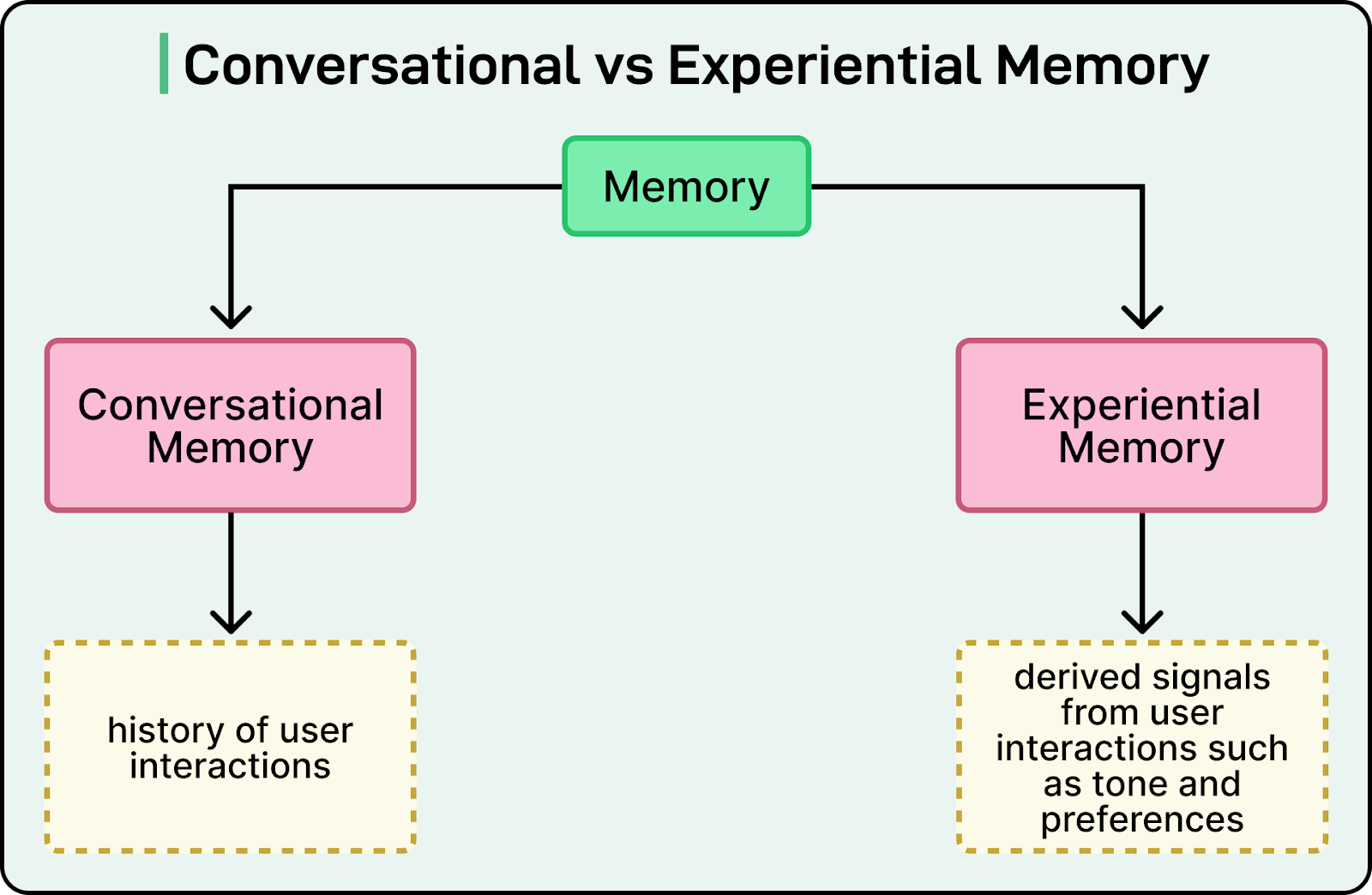
Conversational memory is the raw interaction history that allows agents to maintain context between turns. This memory stores the history of user interactions so that the model can maintain context across multiple turns. LinkedIn built this on top of its existing Messaging system, which already supports reliable message storage, retrieval, and synchronization across devices. On top of raw storage, they added semantic search and summarization so that only relevant pieces of history are fed back to the model. This was integrated with LangChain’s memory abstraction to make it easy for developers to use.
Experiential memory captures derived signals from user interactions. This could include preferred tone, default job locations, or notification channel preferences. For example, a recruiter might prefer a particular tone or notification channel. These insights are stored and reused to personalize future interactions. This type of memory is more structured and hierarchical, derived from user behavior over time.
For both types of memory, LinkedIn enforced strict privacy and policy governance around how it is stored and used to protect sensitive user-derived data.
In general, memory turned out to be one of the hardest parts of the stack to design. In hindsight, the team would have preferred a unified cognitive memory system from the start, rather than separate conversational and experiential layers, to speed up experimentation and reduce complexity.
5 - Model Inference and Fine-Tuning
Early GenAI applications at LinkedIn used models hosted through Azure OpenAI.
All traffic to these models flowed through a central GenAI proxy. This proxy enforced responsible AI checks, managed streaming responses for better user experience, and applied quota limits to ensure fair usage across teams.
As LinkedIn’s needs grew, the company invested in its own AI platform based on PyTorch, DeepSpeed, and vLLM. This platform allowed engineers to fine-tune open-source models like Llama for LinkedIn-specific tasks. In many cases, these fine-tuned models performed as well as or better than proprietary models but at lower cost and latency.
To make switching between external and internal models seamless, LinkedIn exposed all models through a single OpenAI-compatible API. This meant that application developers did not have to change their code when the underlying model changed. LinkedIn also gave members control over whether their data could be used for training, aligning with the company’s privacy commitments.
6 - Migration at Scale
Rolling out this new GenAI stack required migrating existing Java-based applications to the new Python-based framework.
LinkedIn followed an incremental migration strategy:
Start small with depth-first prototypes to identify gaps and fix them early.
Roll out breadth-first across larger applications once the approach is stable.
Use A/B testing to gradually ramp up traffic and catch issues early.
An important part of this migration was upskilling engineers. Many senior engineers were Java experts but new to Python. LinkedIn paired them with more experienced Python developers to accelerate learning and reduce risk. This pairing model helped the organization adopt the new stack without stalling product development.
From Assistants to AI Agents
By 2025, LinkedIn’s GenAI stack had matured enough to support more than just conversational assistants.
The platform evolved to handle AI agents. This step required new abstractions for defining agents, orchestrating their workflows, ensuring reliability and observability, and maintaining strong security and privacy guarantees.
Let’s look at the various aspects of the same in detail.
1 - What’s an Agent?
In LinkedIn’s platform, an agent is a modular component that can take a user’s intent, break it down into sub-tasks, decide which tools or skills to use, and then execute a plan to deliver results. Unlike simple assistants, which respond to a single query in isolation, agents are capable of multi-step reasoning and coordinated actions.
See the diagram below that shows the anatomy of a GenAI agent.
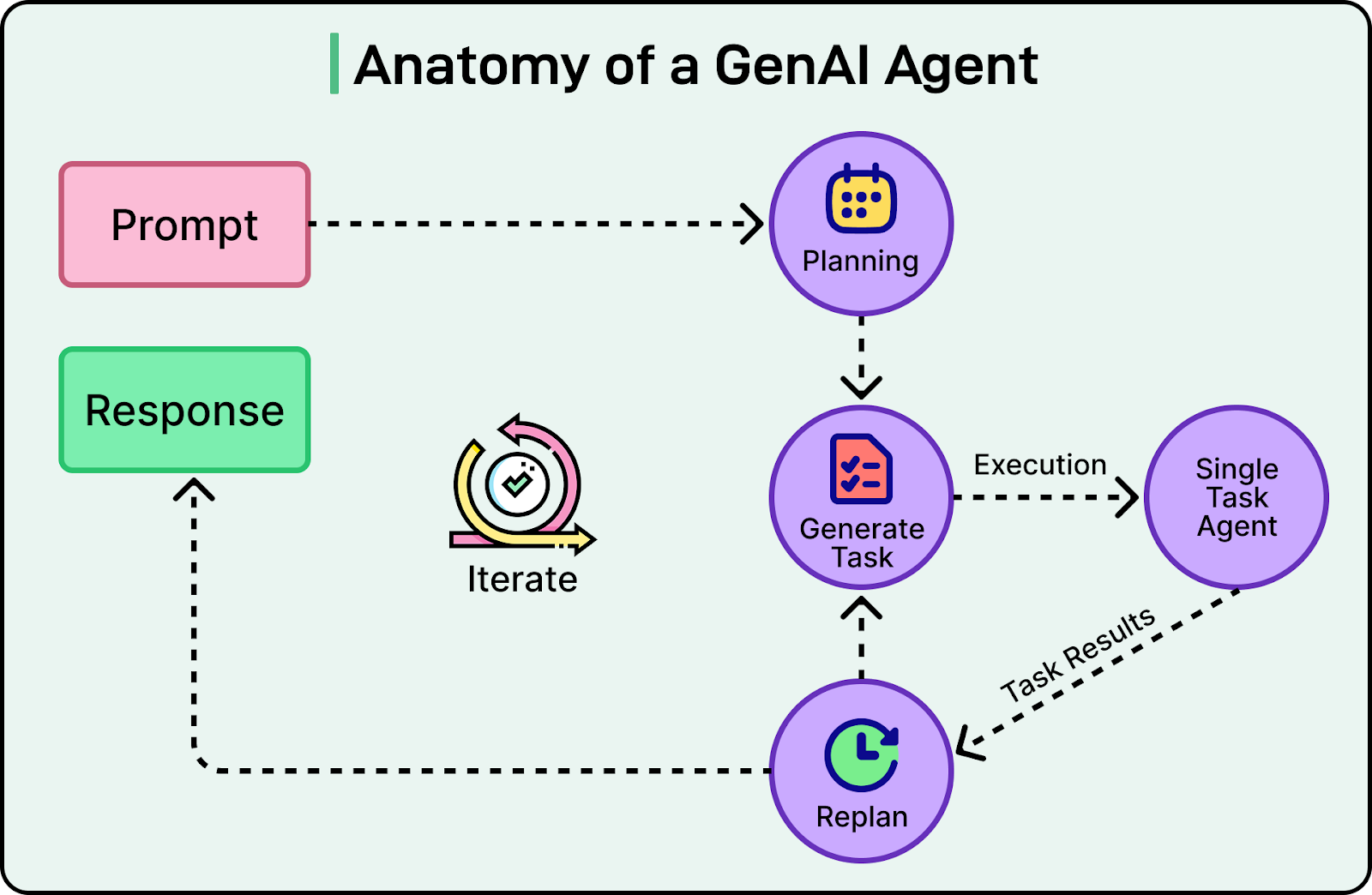
However, full autonomy is not always desirable. LinkedIn deliberately designed agents to work with human-in-the-loop (HITL) controls. At critical decision points, such as sending candidate outreach messages or modifying search filters, agents pause and request human approval. This approach allows the system to combine the efficiency of automation with the judgment and accountability of human users, which is especially important in professional contexts like recruiting.
2 - Discoverability of AI Agents
To make agents first-class citizens in LinkedIn’s architecture, the team introduced a gRPC service schema to define each agent’s contract. This schema describes the inputs the agent accepts, the outputs it produces, and any configuration parameters.
Once defined, agents are registered via a build plugin into an evolving agent registry. Other agents and applications can then discover and call these registered agents without needing to know implementation details.
3 - Orchestrating Multi-Agent Workflows
One of the most important decisions LinkedIn made was to use its existing Messaging infrastructure as the backbone for agent orchestration.
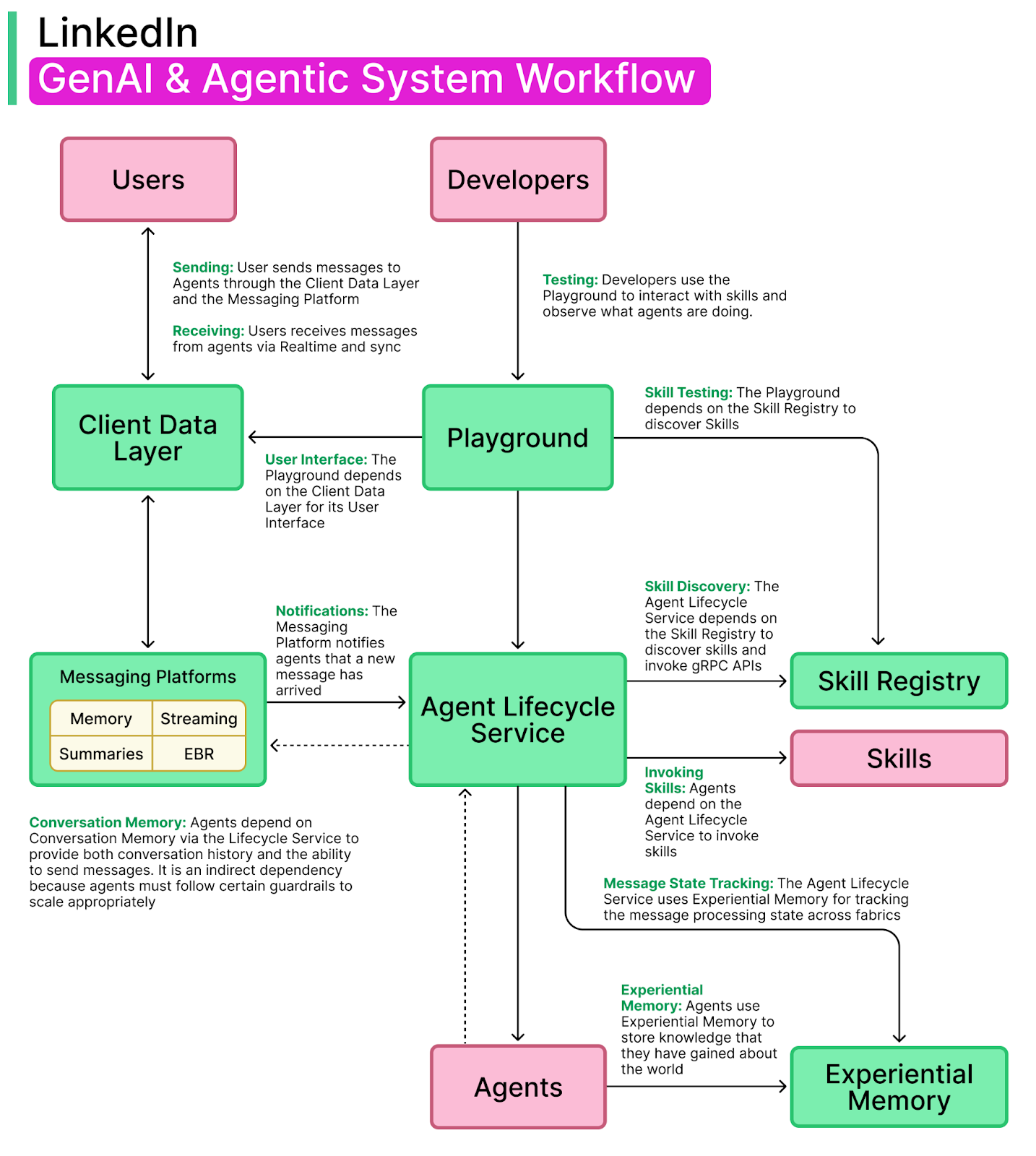
The diagram below shows how the various components of the platform relate to each other.
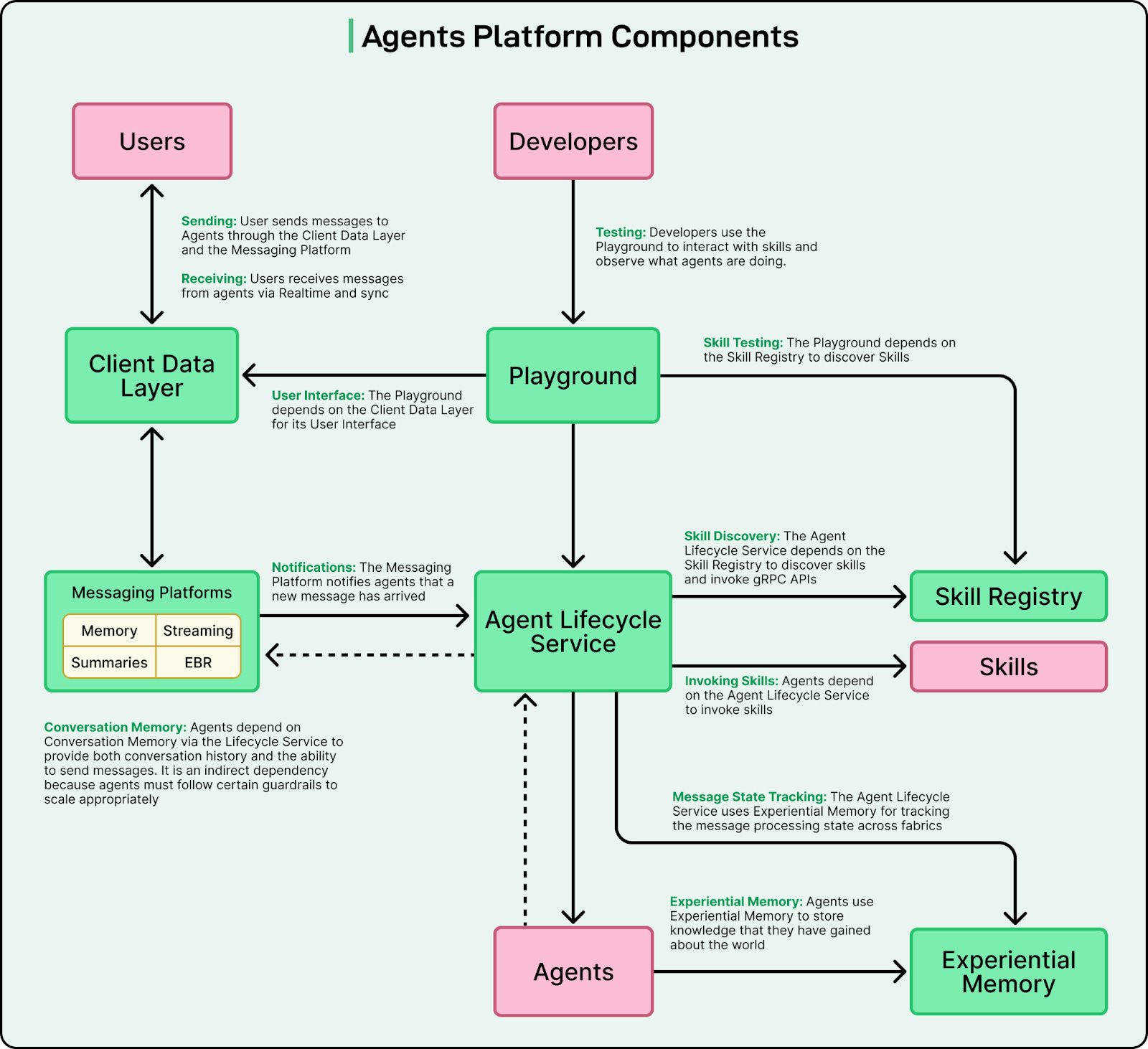
LinkedIn Messaging already provides FIFO (first-in, first-out) guarantees, automatic retries, history lookup, and parallel threads, all of which are essential for reliable multi-agent coordination. Instead of building a new orchestration system from scratch, the team built libraries that translate between messaging events and gRPC calls. This allows developers to write normal agent logic while the orchestration layer takes care of message passing and state tracking behind the scenes.
Agents can use different response modes depending on the task:
Single-chunk responses for quick, simple results.
Synchronous streaming for step-by-step updates.
Asynchronous streaming for tasks that take longer but still need periodic updates.
Using messaging as the orchestration backbone was both a pragmatic and strategic decision. It avoided reinventing reliable delivery mechanisms and made debugging easier since message history could be replayed when diagnosing failures.
On the client side, supporting agentic workflows required new capabilities. LinkedIn added libraries for push notifications, cross-device state synchronization, and incremental streaming. This allows users to start a task on one device, receive updates on another, and stay informed if an agent continues working in the background.
There are also frontend API endpoints that handle UI specific decoration for both sync and async flows.
4 - Observability and Continuous Improvement
Building agentic systems made observability even more critical. Developers needed ways to trace multi-step reasoning, tool calls, and messaging interactions to debug and improve performance.
See the diagram below that shows the observability workflows for LinkedIn’s agentic systems.
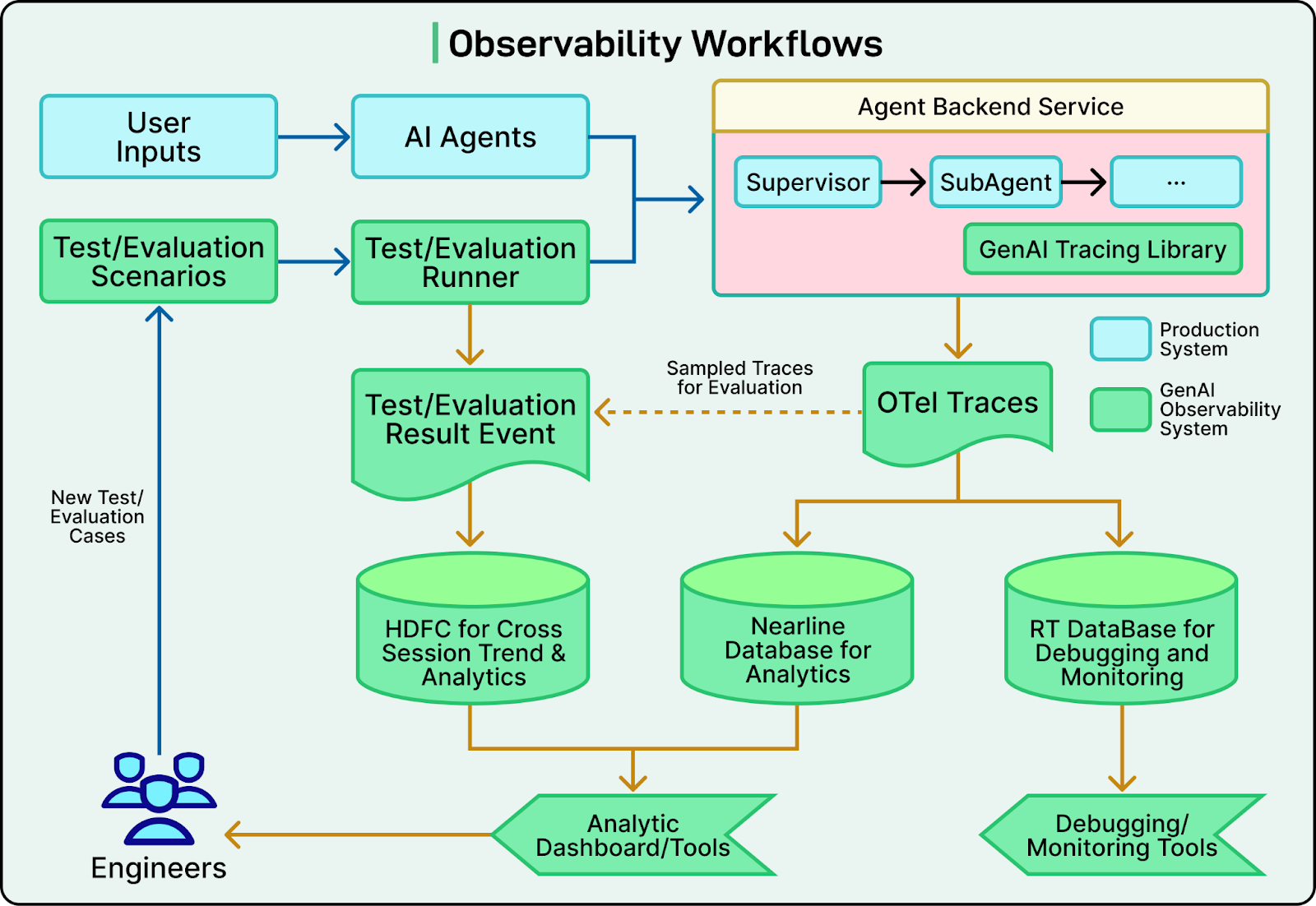
LinkedIn uses two complementary systems:
Pre-production (LangSmith): Engineers use LangSmith tracing integrated with LangChain and LangGraph to capture step-by-step execution of agents, including prompts, skill calls, and control flow. This allows them to debug logic before deployment.
Production (OpenTelemetry or OTel): In production, agents emit OpenTelemetry spans that record execution data in a privacy-safe way. These spans are correlated across services to reconstruct end-to-end workflows. Traces are stored and fed into evaluation datasets used for offline regression tests and prompt tuning.
5 - Developer Tooling: Playground
To make agent development faster and safer, LinkedIn expanded its internal Playground.
The Playground lets developers prototype agents and skills quickly without deploying to production. They can inspect memory contents, test identity and authorization rules, and view real-time traces of execution.
This environment acts as a low-friction sandbox that encourages experimentation while maintaining platform consistency.
6 - Emerging Patterns
As more teams started building agents, LinkedIn observed several consistent design patterns:
User experience is becoming more chat-native, with explainable reasoning steps and clear points where users can intervene or approve.
Background agents handle long-running or resource-intensive tasks during off-peak hours, improving efficiency.
Context engineering combines retrieval-augmented generation (RAG), knowledge graphs, and memory to give agents richer situational awareness.
LinkedIn adopted LangGraph for defining complex control flows, extending it with custom providers that integrate tightly with messaging and memory systems.
These patterns are gradually shaping a shared architectural language across teams.
7 - Platform Guardrails and Interoperability
As agent complexity grew, security and privacy became even more critical.
LinkedIn enforces strict siloing between three layers: the Client Data Layer, Conversational and Experiential Memory, and the Agent Lifecycle Service. Interactions between these layers are governed by policy-driven interfaces, strong authentication and authorization, and auditable access to ensure responsible data use.
The platform supports both synchronous and asynchronous invocation paths. Synchronous calls provide lower latency for interactive experiences, while asynchronous paths are better for longer tasks that may not require immediate user feedback.
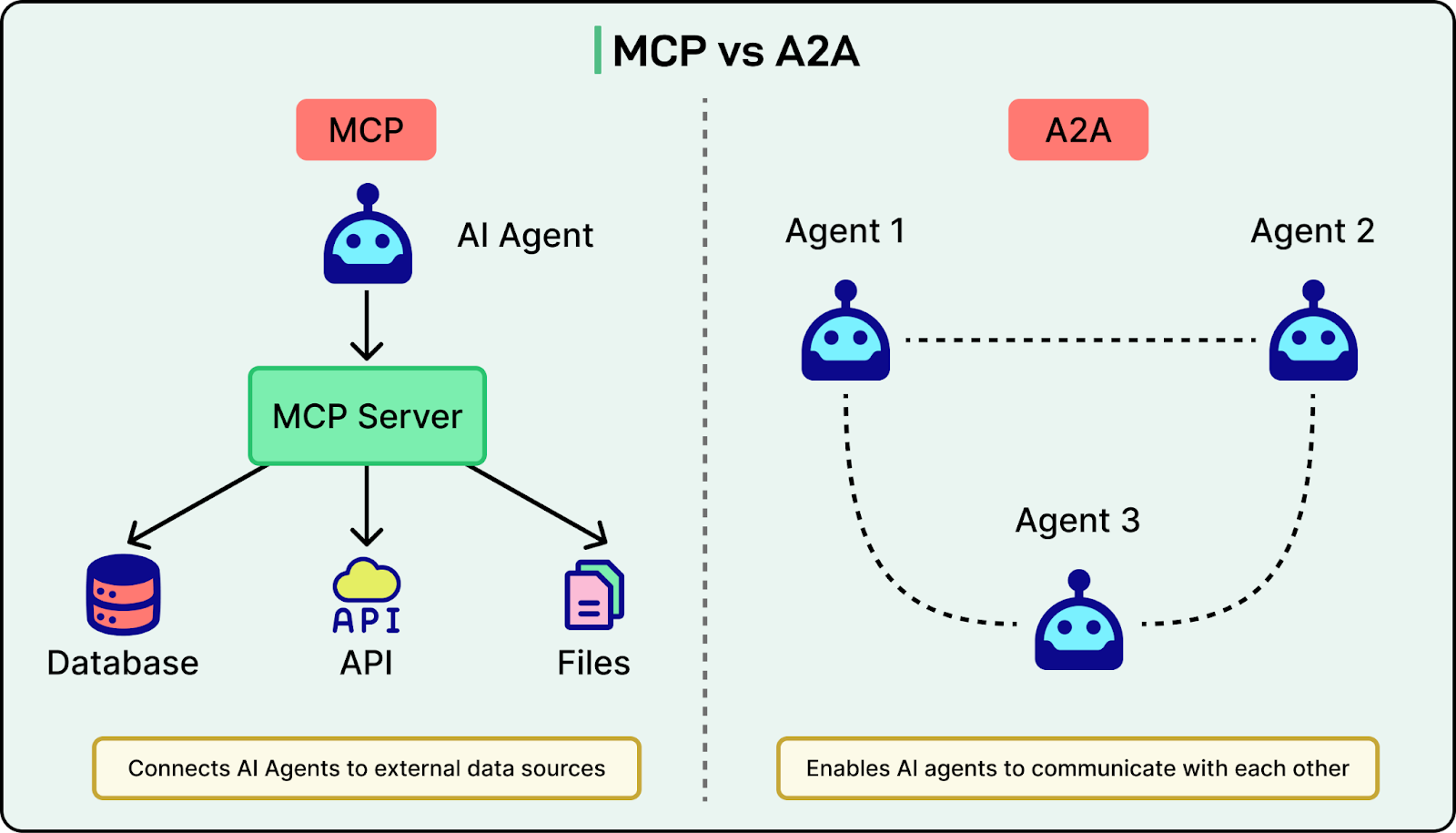
LinkedIn is also moving incrementally toward open protocols such as Model Context Protocol (MCP) for tool discovery and Agent-to-Agent (A2A) protocols for agent collaboration. MCP support is already partial, but A2A is still being experimentally evaluated.
See the diagram below that shows the difference between MCP and A2A on a high level:
Conclusion
LinkedIn’s journey from scattered GenAI experiments to a mature, agent-oriented platform offers valuable lessons for any engineering organization looking to scale AI. Rather than chasing flashy features, LinkedIn focused on foundational engineering decisions that made it possible to move fast without losing control.
Several practical lessons stand out from their experience:
Standardizing prompt management, skill registries, and memory infrastructure created leverage for every product team that followed.
By keeping LangChain and LangGraph for agents and model APIs loosely coupled, LinkedIn retained the ability to switch frameworks and models as the landscape evolved.
Leveraging LinkedIn Messaging for agent orchestration avoided reinventing reliable delivery and made debugging multi-agent workflows tractable.
LangSmith tracing during development and OpenTelemetry spans in production created complementary views that help engineers debug non-deterministic LLM behavior effectively.
Skill registry similarity checks and human review kept the ecosystem organized without slowing developers down.
Strict siloing of client data, memory, and lifecycle services ensured that scaling AI did not come at the expense of privacy and trust requirements.
These principles gave LinkedIn the confidence to move from simple assistants to full agentic systems.
A good example is Hiring Assistant, which applies agentic workflows to repetitive, context-heavy recruiter tasks. By automating candidate sourcing and outreach, the team has seen qualitative evidence of surfacing higher-quality candidates while allowing recruiters to focus on judgment and relationship building.
Also, one key takeaway from speaking to the LinkedIn engineering team was that AI does not replace engineers, but augments them. The most impactful contributors will be those who combine technical depth with strong leadership and communication skills. Building agentic systems is as much about coordinating people, teams, and strategy as it is about orchestrating LLMs, APIs, and solid systems engineering at scale.
References:
Minh - strongly agree that ByteByteGo is a top-notch tech NL with its consistent high quality and timeliness!
And if you read experiences of people posting jobs on LinkedIn, it seems that it's not able to handle applicants using genAI to craft unreal CVs and applying in thousands for each job posting.