
Token Spend Out of Control? The Case for Smarter Routing

Code review needed a new architecture. We open-sourced it. (Sponsored)

Code review broke when AI started writing the code.
AgentField just shipped a multi-agent code reviewer with dynamic meta-orchestration. The planner reads each PR first, then compiles a custom review strategy for it - security agents for auth changes, schema agents for migrations, behavioral agents for refactors. Configurable per team. Deploy it with one docker compose. Runs on open or closed models (Kimi, DeepSeek, Claude). Costs cents per review on open models - no per-seat licenses.
AgentField’s writeup: the four jobs of code review, which three stay load-bearing once AI writes the first draft, and why static pipelines fail.
LLM agents can burn millions of tokens on a single task. They put a model in a loop, resend the full context every step, and usually call the most expensive one available. Costs scale fast.
To understand how teams keep this under control in production, we sat down with Scott Breitenother and Sid Sijbrandij, co-founders of Kilo, an open-source coding agent that runs through a lot of these loops every day. The patterns they shared are not specific to coding, and most of them are not unique to Kilo either. Similar approaches show up in tools like Cursor, Cline, and Aider, and in shared infrastructure like OpenRouter and RouteLLM. If you build any agent that makes many model calls, the same ideas apply.
Why Running an LLM Agent Gets Expensive
A single request to a language model is usually cheap. An agent built on the same model is not. The difference is that an agent makes many calls instead of one, and it tends to send them to the most expensive models available. Both of these drive the cost up.
1. Frontier Models Cost a Lot Per Token
The most capable models are called frontier models. They sit at the leading edge of what is possible, and they cost the most per token. Below them is a range of cheaper models that give up some capability for a lower price, down to small models that are very cheap and still handle simple work well.
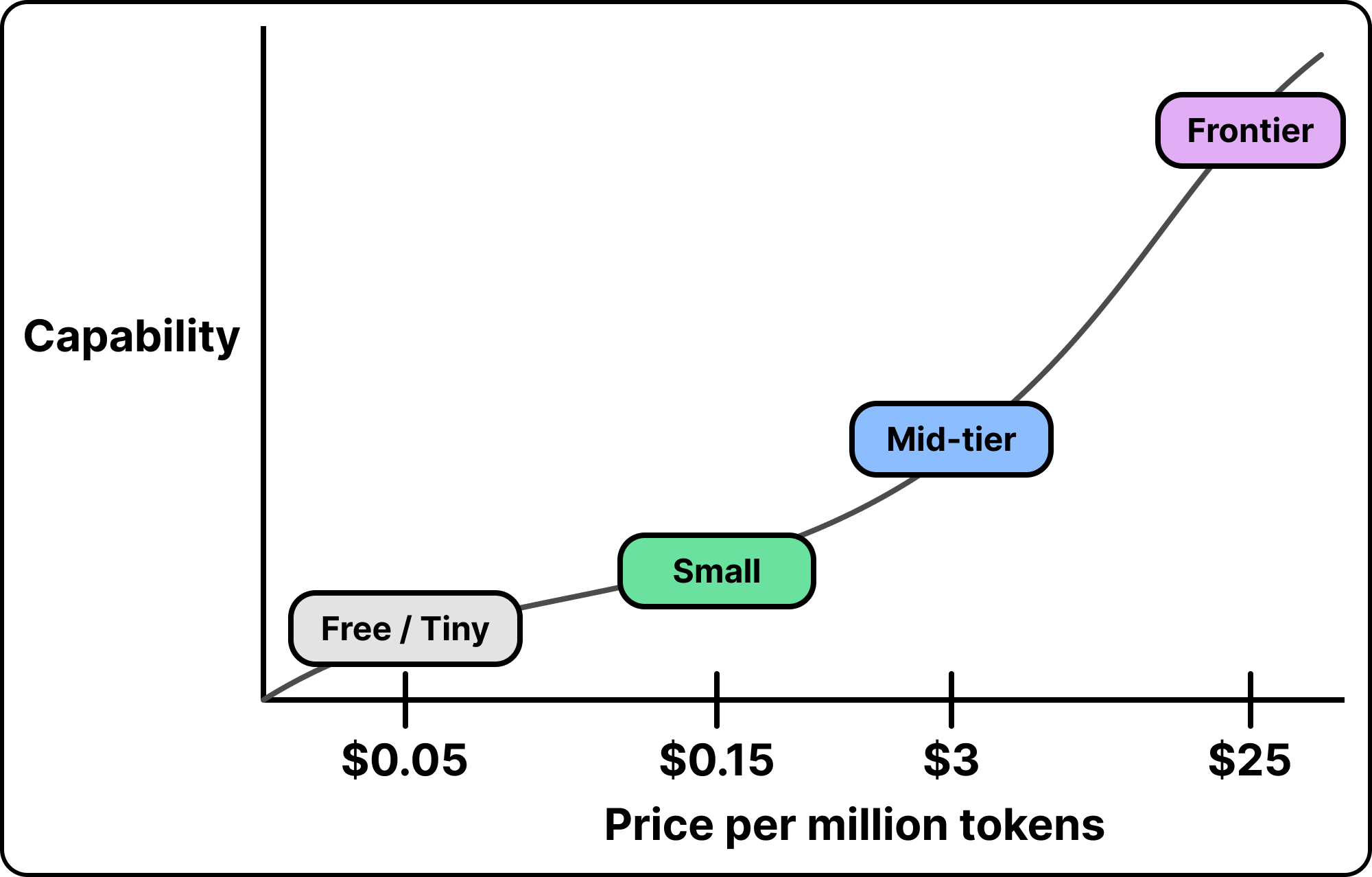
The gap across that ladder is large. The top model often costs more than ten times what a small one costs for the same work. Teams that use frontier models to power their applications pay frontier prices for everything, which makes the whole system expensive.
2. The Agent Loop Multiplies Every Call
Frontier models are expensive per token, but in a standard chatbot setting, the cost is manageable. For example, Claude Opus 4.7 costs $5 per million input tokens and $25 per million output tokens. A single question and answer is only a few thousand tokens, so it costs under two cents. At that rate, you can ask a lot of questions before the cost matters.
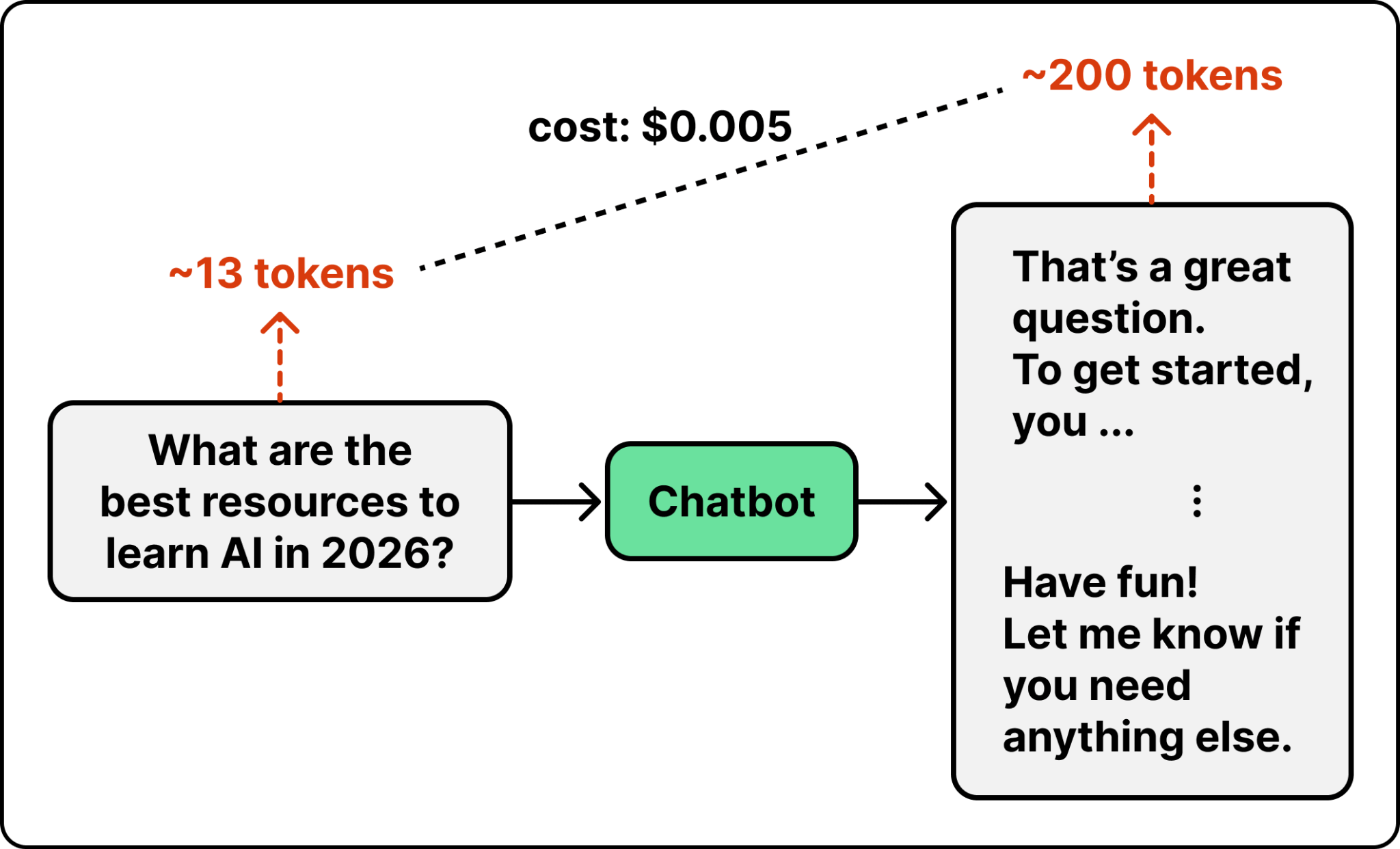
LLM agents are different. They do not produce an answer immediately. They run in a loop. The agent reads the task, takes an action like running a tool or reading a file, looks at the result, and decides what to do next. To see why this gets expensive, look at what each step sends to the LLM.
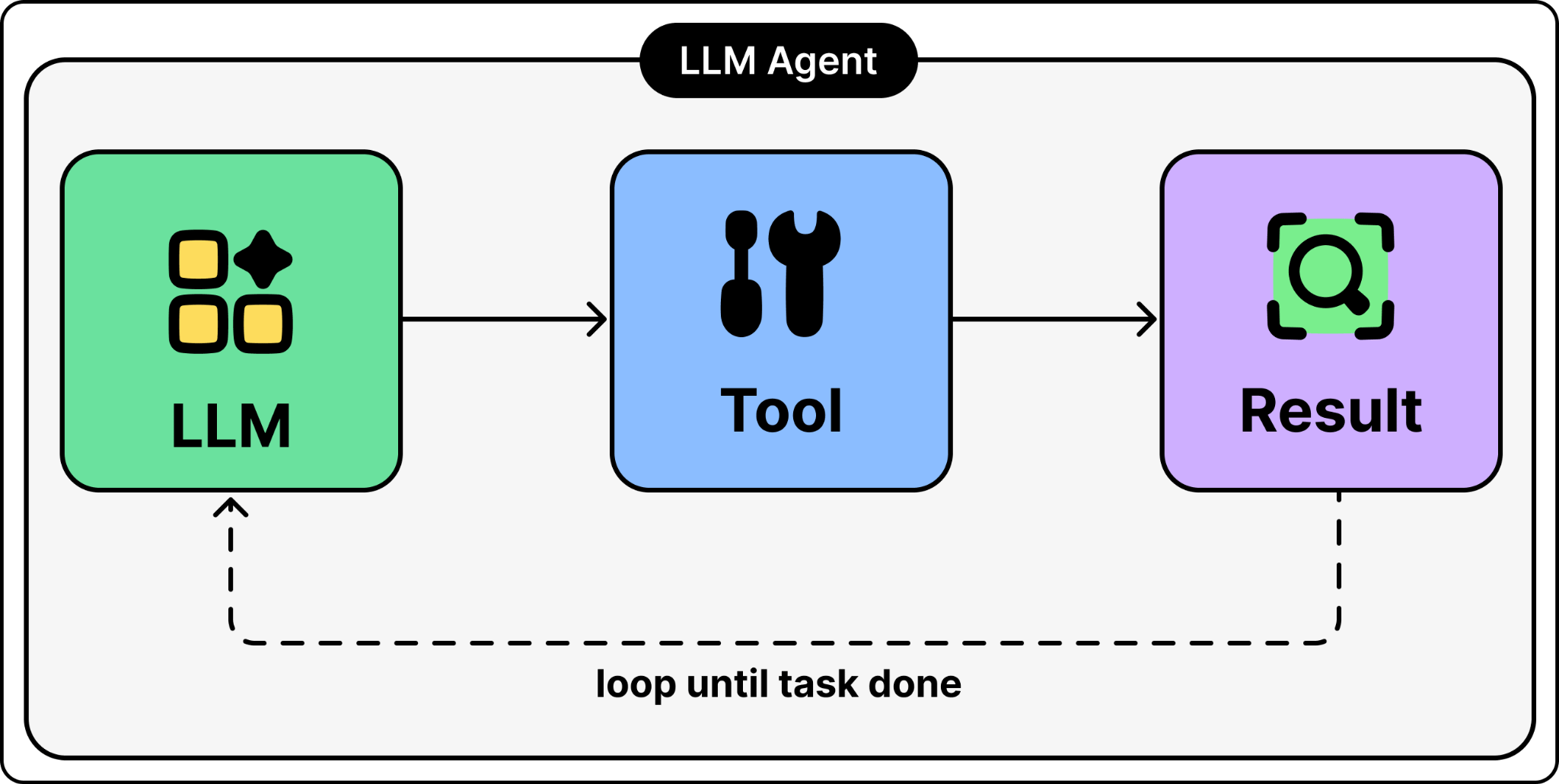
Since an LLM has no memory of its own, everything has to be bundled into the context on every step. That includes the instructions, the question, tool schemas, tool calls, tool results, and the LLM’s intermediate thinking. The agent resends all of it each turn, so the context grows as the loop runs, and each call to the LLM costs more than the last.
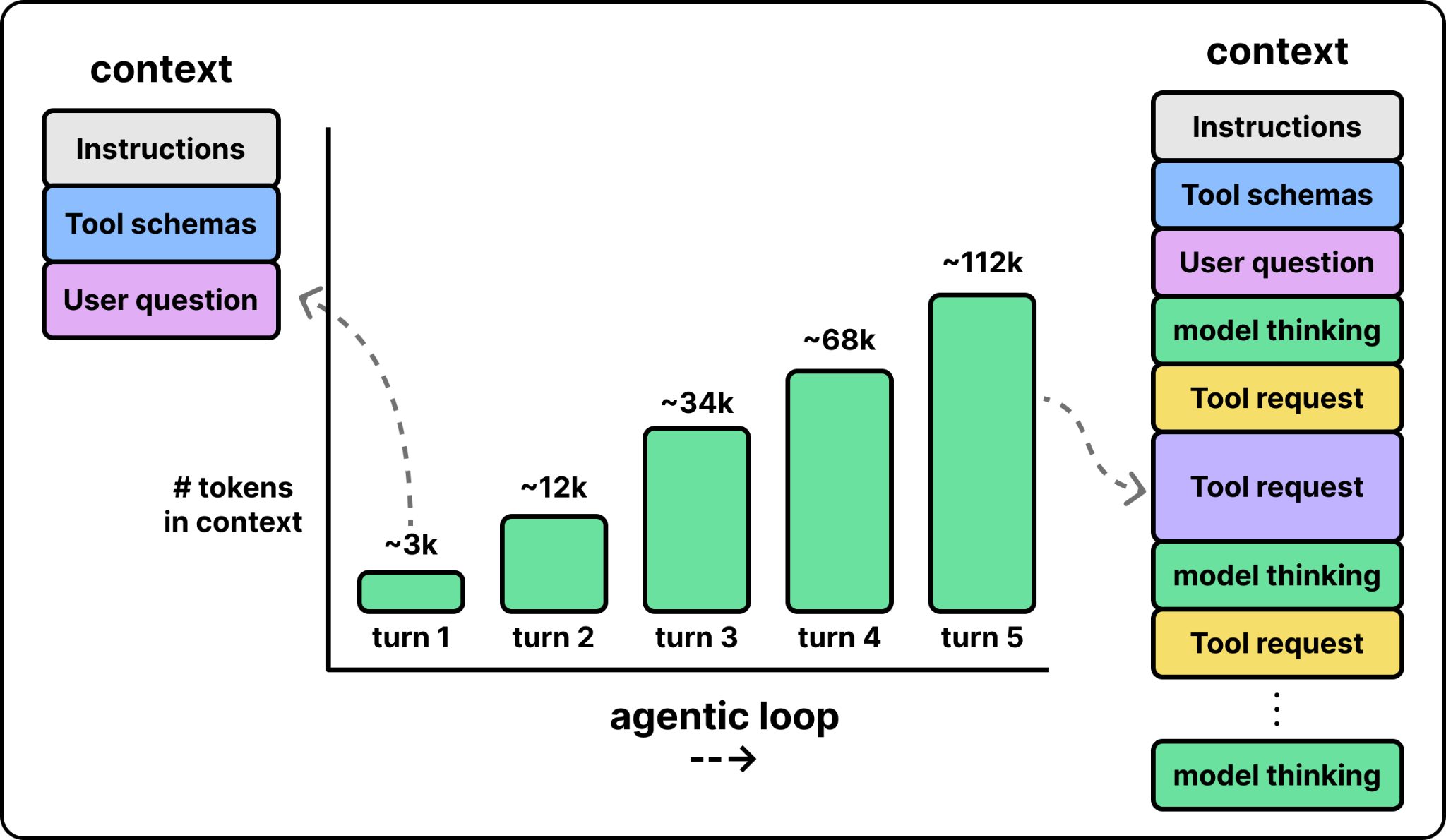
A session might start at a few thousand tokens. By the time the agent has read a dozen files and run a dozen tools, a single request near the end can carry well over a hundred thousand. As a result, agents can burn many times more tokens than a single chatbot question.
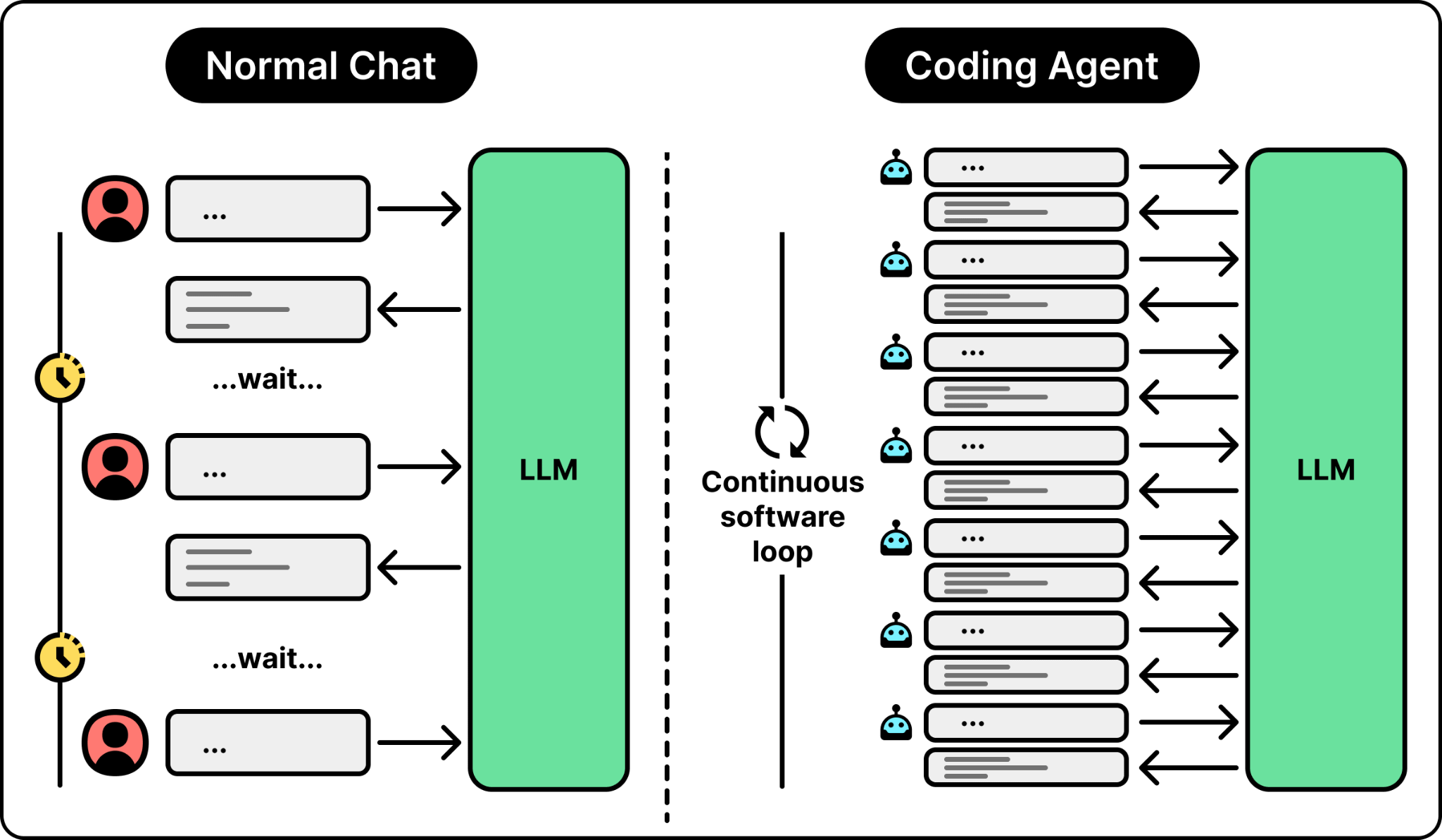
The growing context is only half of it. The other half is how often the agent calls the model. In a normal chat, it takes time for a person to type a question and effort to read the answer, so they only ask so much. An agent has no such brake. An agent that reviews every code change, comments on every commit, and writes a test for every function fires off requests as fast as the software allows.
Your AI pipeline passed every test. Then it hit production. (Sponsored)

Datadog’s free Developer Toolkit for the AI Era gives you four resources to close the gap, from catching flaky tests and CI bottlenecks before they block releases, to instrumenting every LLM call for quality, latency, and cost regressions.
You’ll learn how to:
Surface and eliminate CI pipeline failures before they block your AI delivery cycles.
Use feature flags to control AI rollouts and DORA metrics to measure exactly how your team is shipping.
Score LLM output quality and catch latency drift across every model call in production.
The Standard Approach: Route Requests to the Right Model
A growing context and an agent that runs without a human brake are both inherent to how agents work, so you cannot really send fewer tokens. What you can change is which model receives them, and that is what routing does. A router looks at each request, decides which model is good enough, and sends it there.
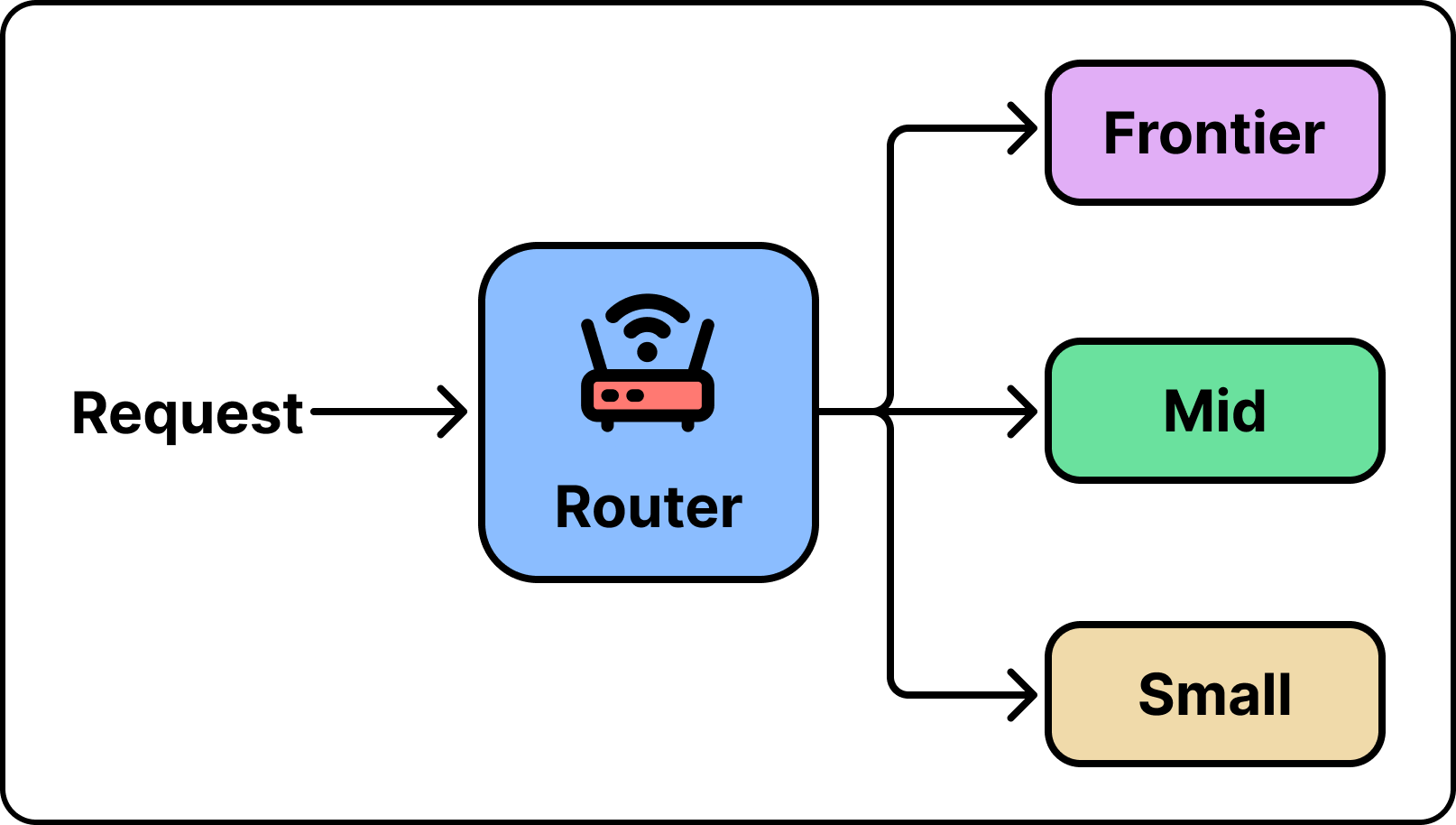
For example, think about the requests a coding agent sends while working on a task. A few are hard, like designing how a system should be structured. Most are simple, like renaming a variable or summarizing a file. The hard ones need a frontier model. The simple ones do not, but they cost the same if you send them there too. Routing saves money by sending each request to the cheapest model that can handle it, so you only pay for a frontier model when you actually need one.
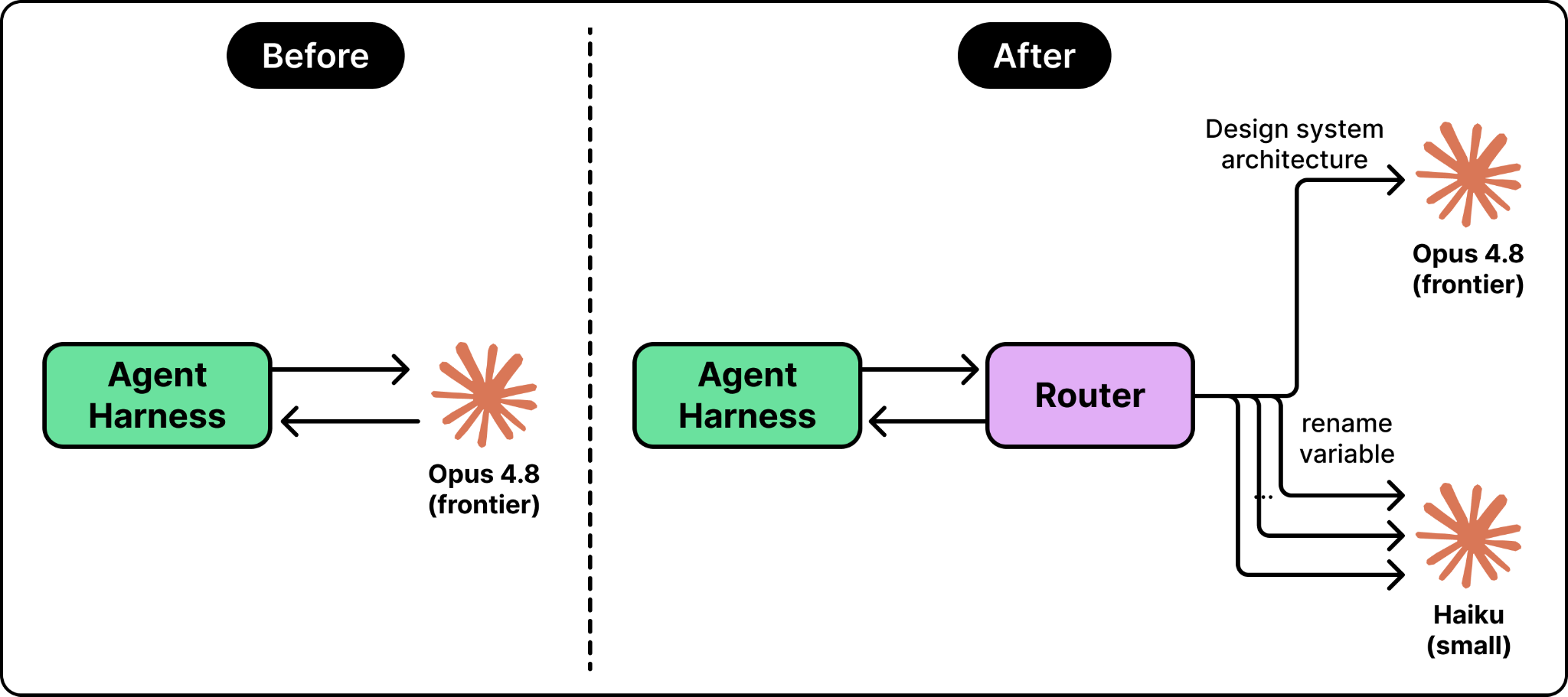
How a Router Works Under the Hood
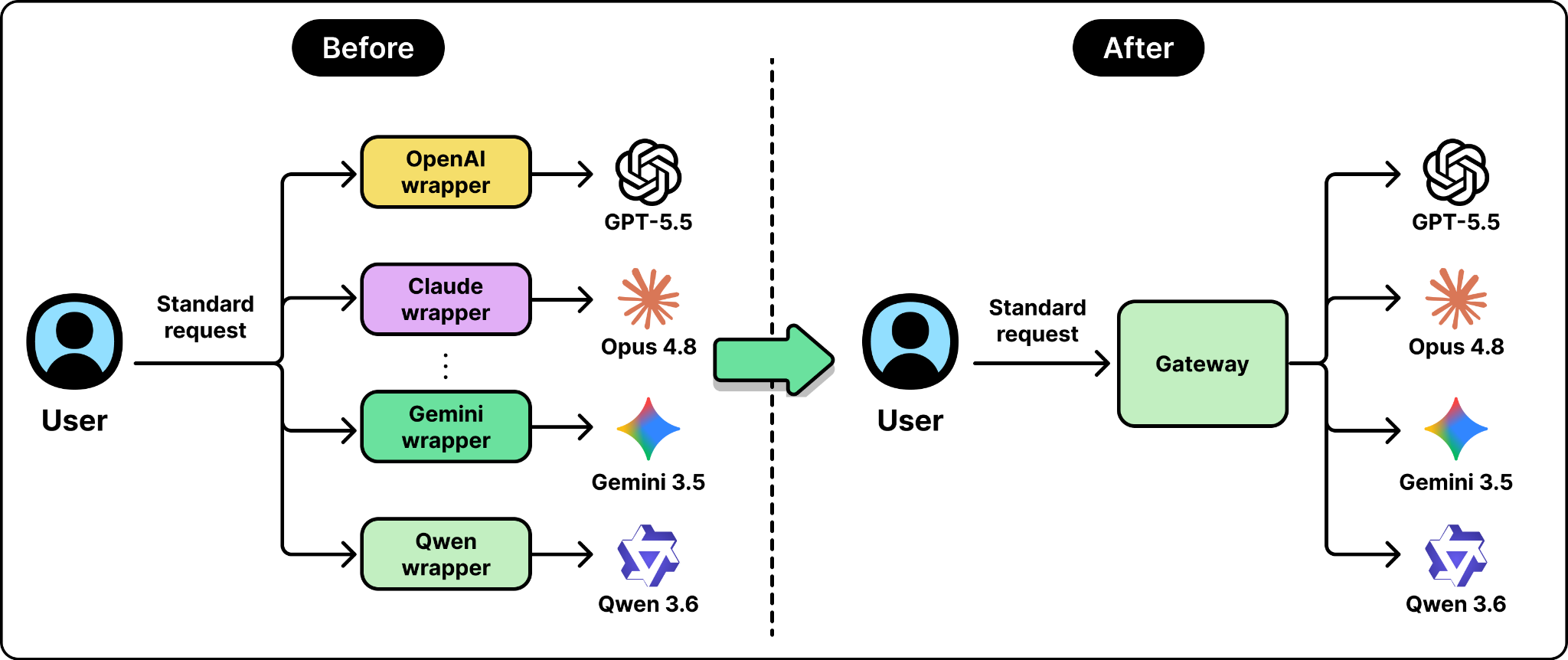
A router needs two things. It needs a way to send requests to many different models. It also needs to decide which model to use for each request. These are two separate problems, and keeping them separate makes the design cleaner.
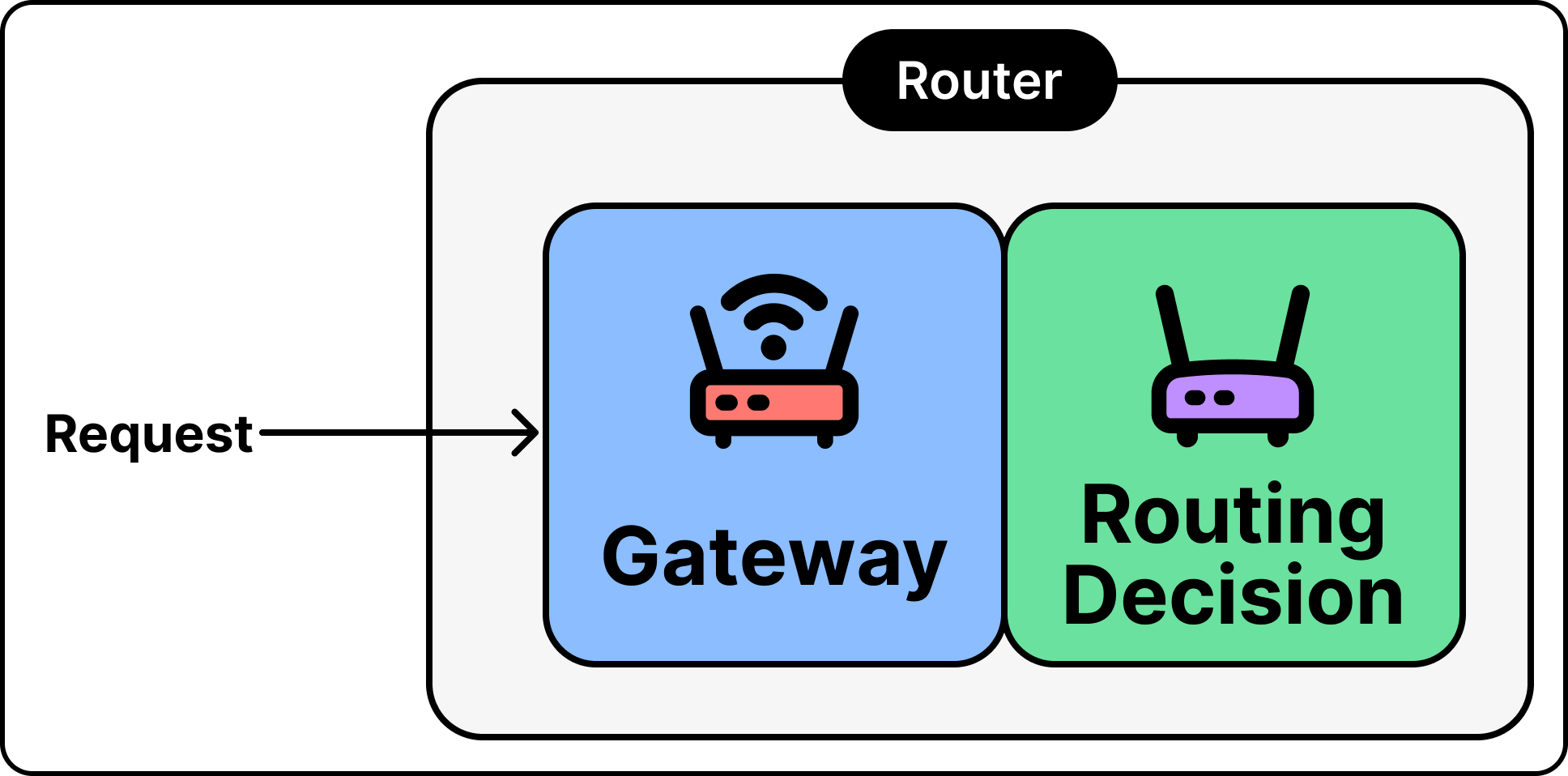
The first problem is the entry point. Normally each model provider has its own request format, so using several models means writing separate code for each. A single entry point gives you one standard request format, and the router translates that into whatever the chosen provider expects, sends it, and translates the response back. You write in one format. The router talks to all the providers for you. Without this, routing between models is not practical in the first place.
The second problem is the decision. Which model should a given request use? In practice, the decision is handled in two ways.
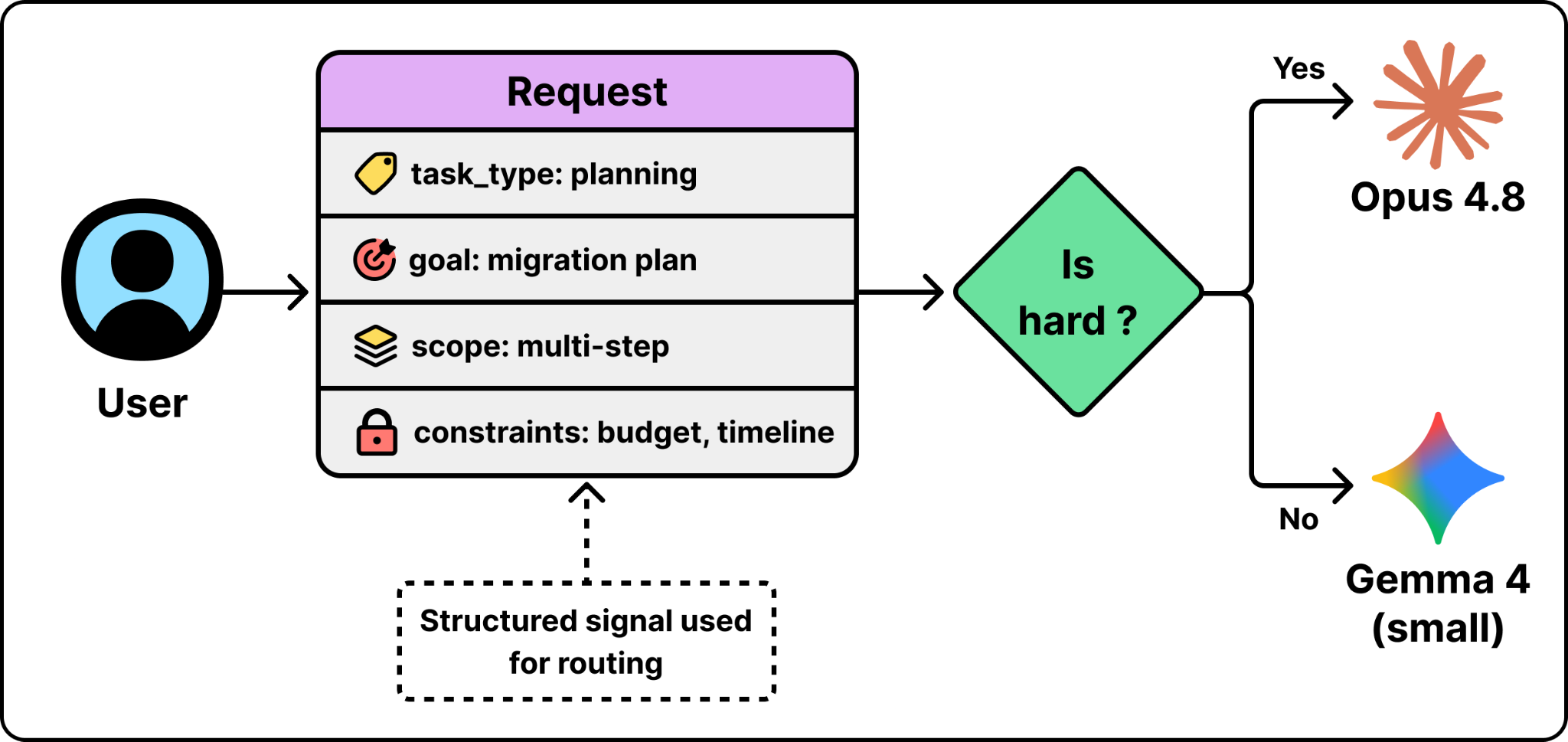
The first is to route on a signal you already have. If the system already knows what kind of work a request is, it can map that kind of work to a model. A request known to be a planning task maps to a strong reasoning model. A request known to be a simple edit maps to a cheap one. This is reliable and almost free to run, because the decision is just a lookup. The catch is that you need a trustworthy signal to begin with.
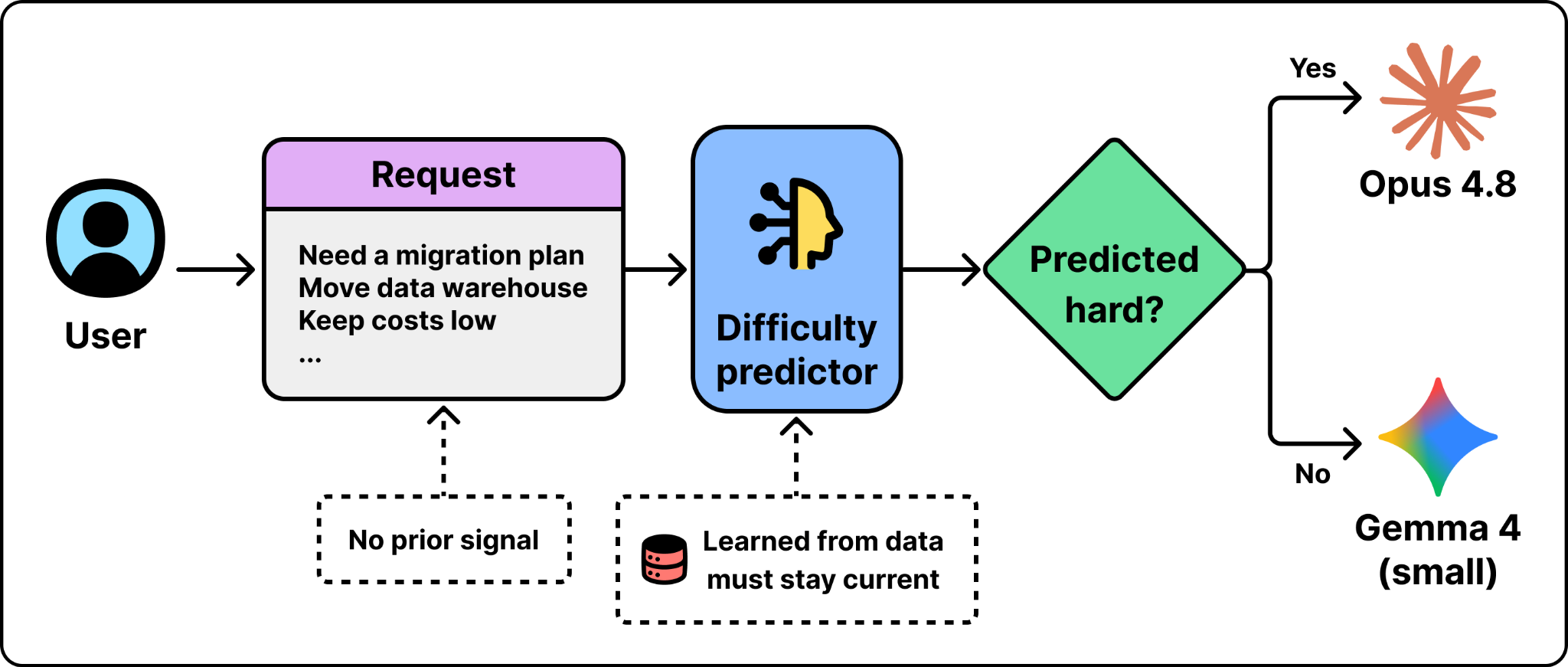
The second is to predict the right model from the request itself. The system reads the request, judges how hard it is, and picks the cheapest model likely to answer it well. This works even when you have no prior signal about the request. The cost is that the prediction has to be learned from data and kept current as models change. A wrong guess sends a hard request to a model that cannot handle it.
Most real systems use one entry point with one of these two decision methods on top. The entry point gives access to many models. The decision technique picks among them.
How Much Routing Actually Saves
Routing saves money because most requests do not need a frontier model, and cheap models have gotten good enough to handle them. The saving is the gap between the frontier price you would have paid and the cheaper price you actually paid, summed over every request that did not need the expensive model.
The effect of proper routing is quite noticeable. In a widely cited study from researchers at UC Berkeley and Anyscale, a router cut cost by about half while keeping 95% of a frontier model’s quality. It did this by sending only the hard requests to the frontier model and the rest to a cheaper one. More broadly, results across the field tend to land between forty and seventy percent cost savings, with little drop in quality on hard tasks.
Router cost saving (Source: Github)
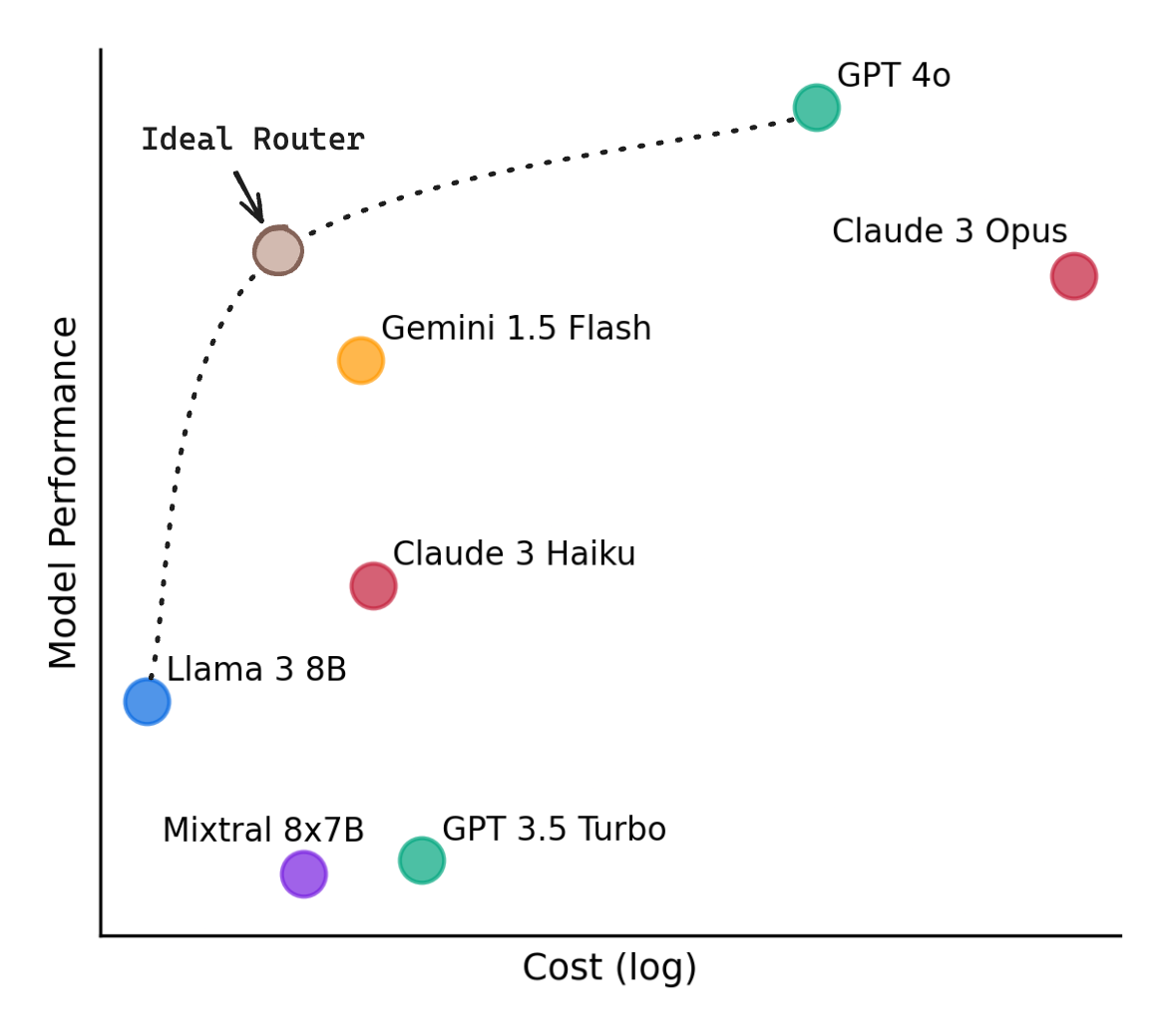
Those savings come with tradeoffs, though. The decision step adds a little delay to every request and becomes one more thing that can break. A wrong decision hurts quality by sending a hard request to a weak model. A predicting router needs data and upkeep to stay accurate. And switching between different model families inside one task can cause trouble, because the internal reasoning one model produces is not always readable by another. None of these kill the idea. They are why routing is an important but challenging problem to handle well.
A Case Study: How Kilo Routes Requests in Production
To make this concrete, it helps to look at one system that does it end-to-end. Kilo makes an open-source AI coding agent that drives a model in long loops to write and fix code, and across its user base that adds up to a very high request volume. To serve that volume without the cost running away, the Kilo team built its own routing layer, the Kilo Gateway, and runs all of its traffic through it. The numbers and design choices in the rest of this section come from that production system.
The Gateway
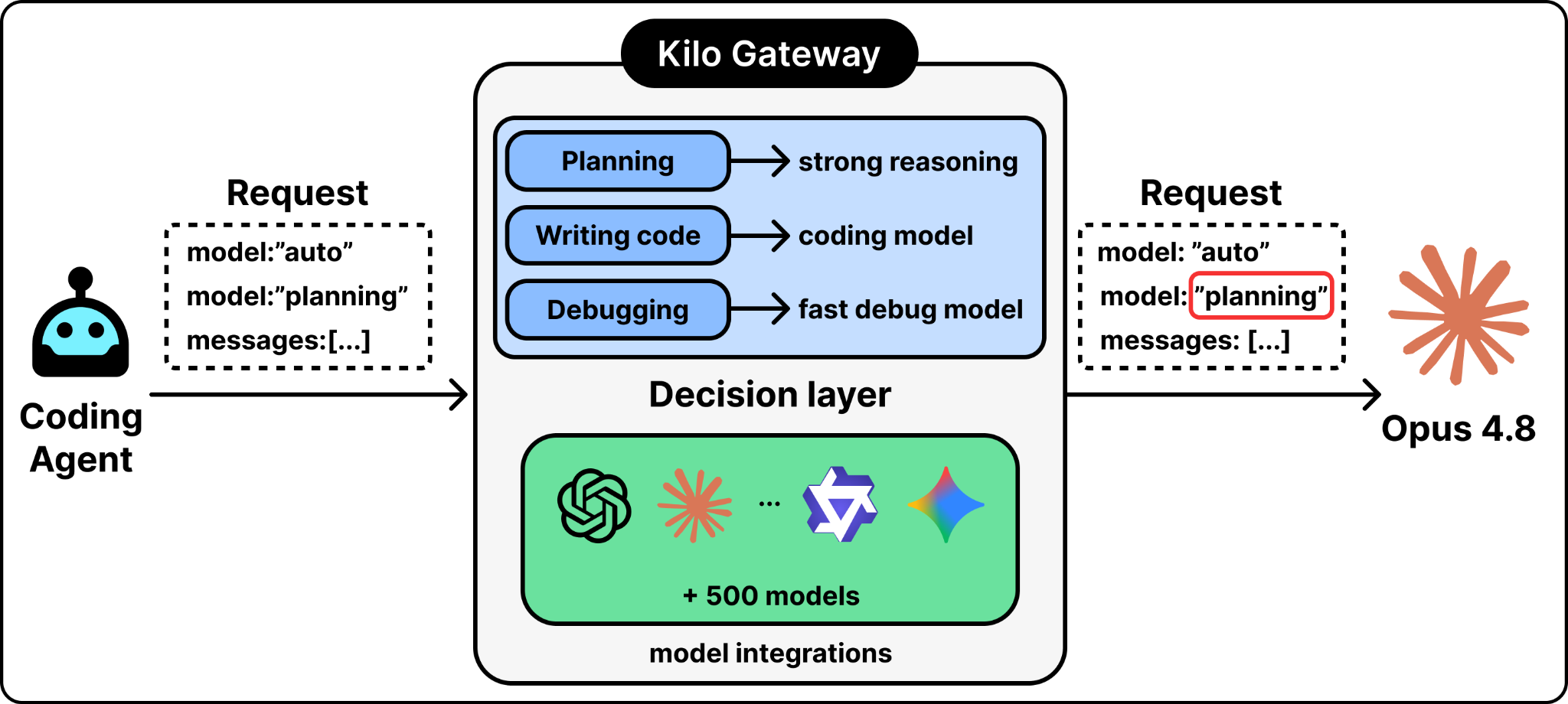
Kilo Gateway is the entry point described earlier. It puts one consistent way of making requests in front of more than five hundred models, so switching from one to another is a one-line change. It speaks the same request format most code is already written for, so existing code works by pointing it at the Gateway. It also lets a team use its own provider accounts and pay only for the routing, not a markup on the models.
The decision layer is the interesting part. Kilo uses the first method: it routes on a signal it already has. Its coding agent always knows what it is doing right now, because it works in distinct modes like planning, writing code, or debugging. The agent sends that mode with each request. The Gateway reads the mode and maps it to a model. The mode is a trustworthy signal of how hard the work is, so the system gets most of the benefit of routing without having to guess difficulty from the request text.
The routing is organized into tiers a user can pick from. A top tier sends demanding modes like planning and debugging to the strongest model, and sends routine modes like code editing to a capable but cheaper one. A balanced tier sends everything to an economical model. A free tier maps to no-cost models. A separate internal tier quietly handles background chores, like writing commit messages, with tiny models so they never burn expensive capacity.
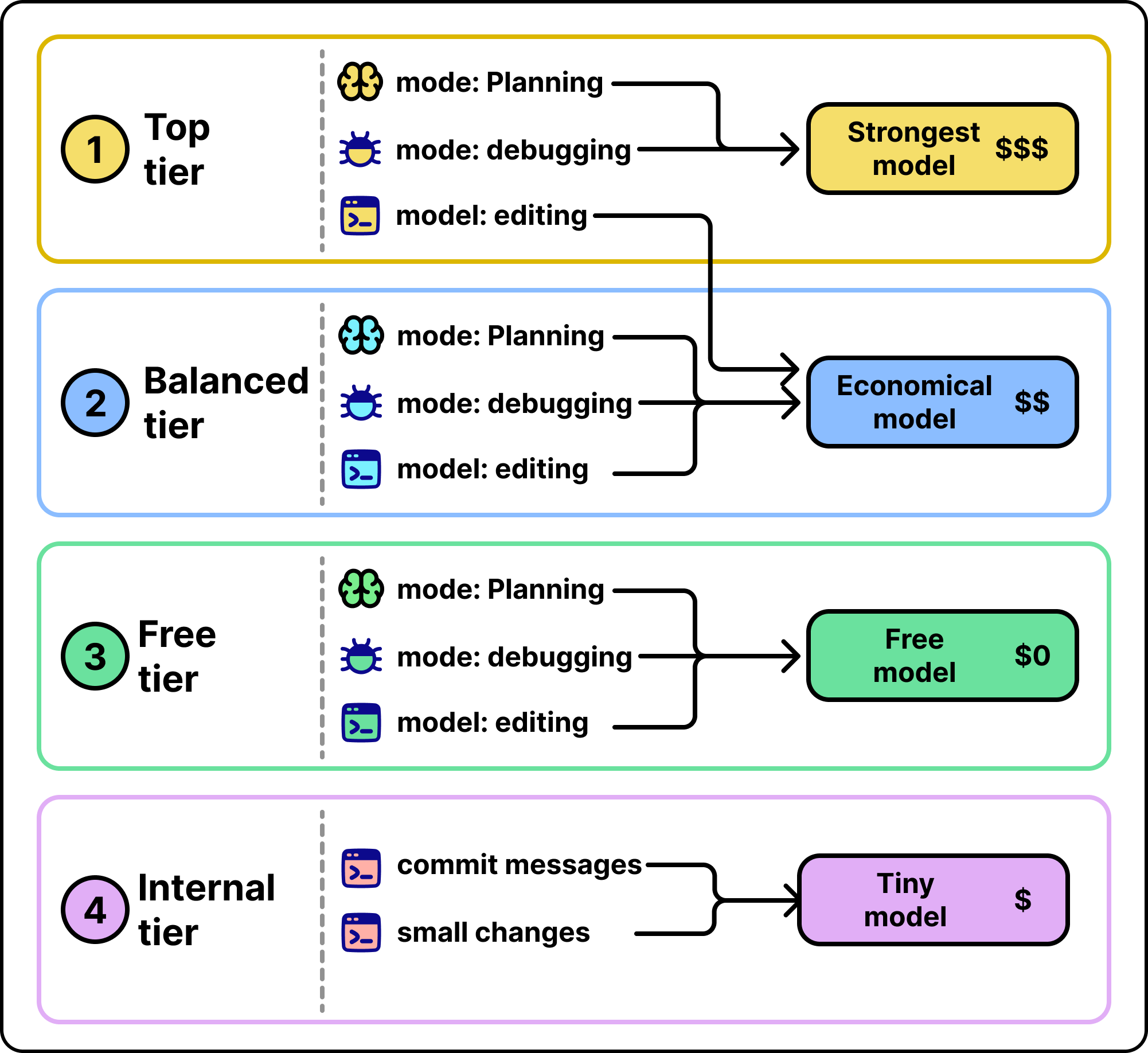
One design choice explains how the system stays current. The map from a mode to a specific model does not live in the software on your machine. It is served from Kilo’s own systems and refreshed often. So the underlying models can be swapped as prices and quality change, while the tier you picked stays the same.
This flexibility has one cost worth understanding. A tier can change models between the turns of a single task, for example moving from one provider’s model to another’s as the mode shifts. The problem is that reasoning models produce internal thinking in their own format, and one provider’s model cannot read the thinking another model wrote. So when the tier switches families mid-task, Kilo has to drop that intermediate reasoning before the next call. The agent keeps working, but it loses some of the context it built up, which can cost a little quality on the next step.
What Kilo’s Production Numbers Show
Kilo published figures from its own production traffic over the first quarter of 2026. These are the company’s internal numbers from paid usage, not independently verified, but they are useful because they come from a real workload rather than a benchmark.
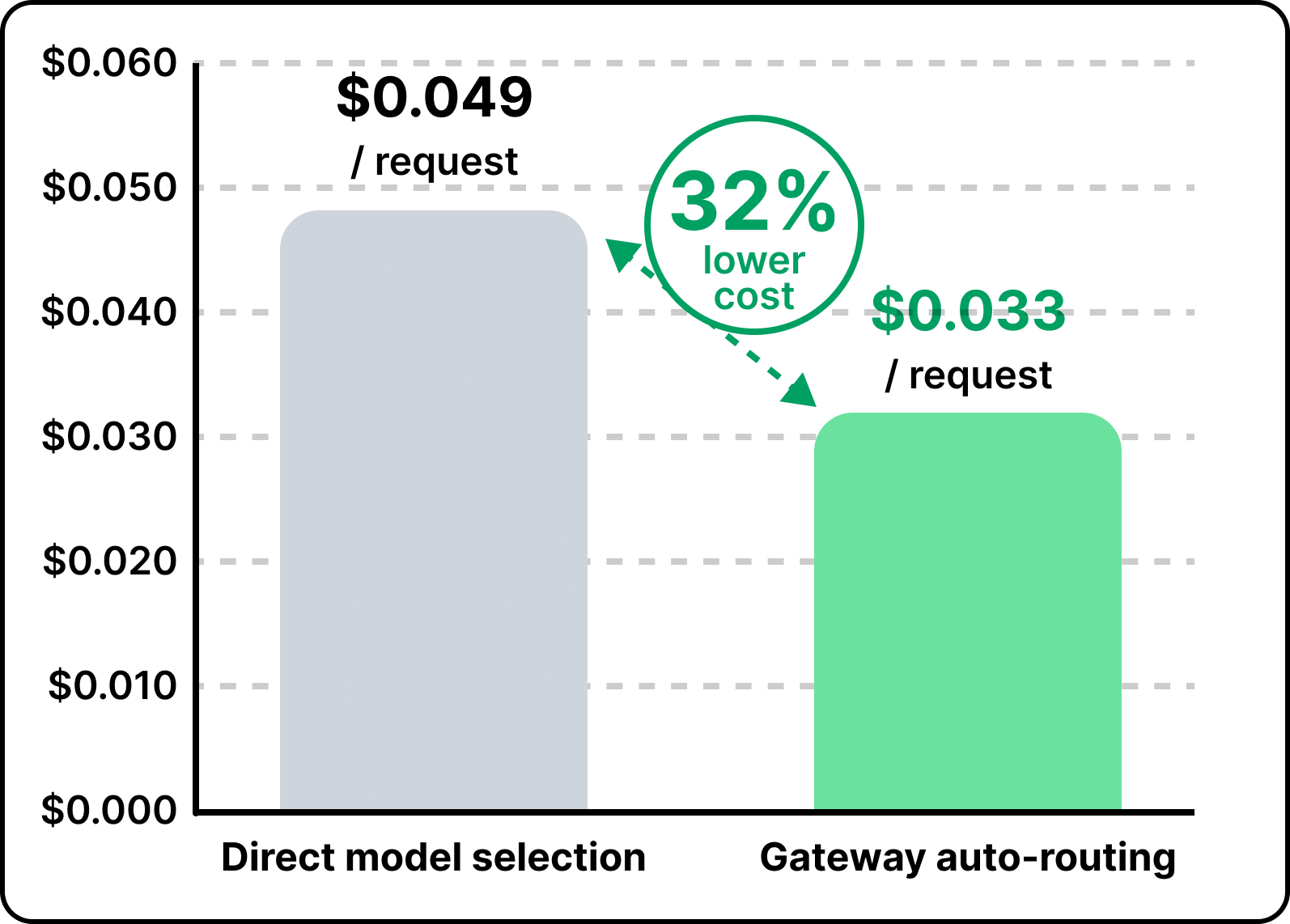
When the team let the Gateway route on its own instead of having users pick a model by hand, the average cost per request dropped by about a third. Kilo found that 80 to 90% of requests do not need frontier models. Across millions of requests, routing those jobs to cheaper models adds up to real savings.
The bigger surprise was how much the choice of tier shaped the cost. For the same coding work, running on the cheaper balanced tier cost over ten times less per request than running on the top tier, and that gap showed up across every kind of work the team measured. The smallest background tasks, handled by tiny models, came in at a fraction of a cent. Most of the savings turned out to come not from anything clever, but from simply keeping routine work off the most expensive model.
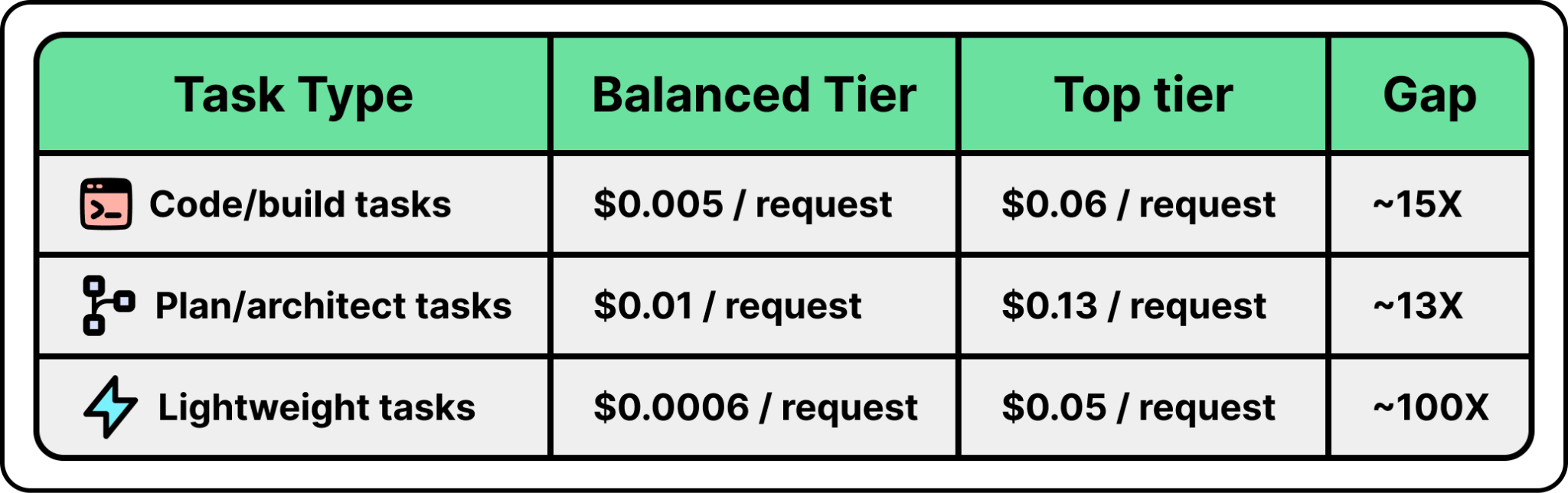
To put a number on what that is worth, the team estimated that forcing its routine traffic onto top-tier models for the quarter would have cost about eighty-seven thousand dollars more. That is roughly what getting routing wrong would have cost them on a real workload.
The Kilo team also shared a useful finding about caching. Caching, where the system saves repeated context so you do not pay for it twice, is usually seen as the main way to cut the bill. Kilo found that even with cache reuse above eighty percent on many features, total spend stayed high, because there were so many requests and the part of each context that could not be cached was still large. Caching clearly helps, but it does not solve the volume problem by itself. Routing works on a different part of the cost, which is why teams tend to use both together.
Lessons for Any Team Running Agents at Scale
Kilo’s numbers point to a few lessons that apply to any team running agents at scale, whichever router or models they use.
Set a budget and treat AI spend like any other infrastructure cost. It is tempting to just switch to a cheaper model and reduce the per-token rate. But a lower rate usually leads to more usage, since work that was too expensive before now looks affordable. So the total bill often climbs even as each request gets cheaper.
Pick a monthly budget for the whole workload and treat it as fixed. Then the goal is not the lowest price per request, but the most useful work you can fit inside that budget.
Measure before you optimize. Cost is driven by tokens per request, which is mostly a function of context size, not by which part of the product the request came from. Two requests can both be tagged “chat” while one carries a thousand tokens and the other a hundred thousand.
So log the token count of every request, and tag each one with the task type and the feature that sent it. Then add the tokens up per group. The groups that dominate your token total, not the ones that send the most requests, are where your spend actually is, and where routing pays off most.
Route on the strongest signal you already have. If your system already knows the task type, like whether a request is planning or a simple edit, route on that directly. It is a static lookup from task type to model: cheap to run, predictable, and easy to debug when a route looks wrong. Only fall back to inferring difficulty from the request text when you have no such signal, since that means running a separate classifier you have to train, evaluate, and keep current as models change.
Either way, the router can only help if there is a real spread of models behind it. Give it access to the full range, from frontier models down to small cheap ones, so it has a meaningfully cheaper option to pick whenever the work allows.
Conclusion
Today, routing still takes manual work. You have to choose a tier, set up the signal it routes on, and decide which tasks are safe to send to a cheaper model. It works, but it is something you have to stay on top of.
This will get easier. Routers are starting to make these choices on their own. Instead of being told the task type, a router will read the request, judge how hard it is, and pick the model itself. Over time it will get more precise, choosing a model for each step of a task rather than for the whole task. The goal is for routing to fade into the background, the way load balancing did. You set a budget and a quality bar, and the system handles the rest.
This matters more every year, because agents keep getting more capable. They run longer, act on their own, and send more tokens with no one watching. As that grows, picking the right model stops being a way to save a little money and becomes what decides whether running an agent is affordable at all. The main takeaway is this: routing is no longer a cost optimization. It is becoming part of what makes ambitious agents possible.
The caching finding surprised me: 80%+ reuse and the bill still stays high, when most of us treat caching as the main lever. The point that lands hardest is "route on a signal you already have": most teams know whether a call is planning vs. a simple edit but they just never pass that down to the router.
Curious how you handle the quality hit when a tier swaps model families mid-task and has to drop the intermediate reasoning... do you tend to re-plan or just eat the context loss?
Very detailed and to identify how to go about this chaotic landscape of choice for your build.