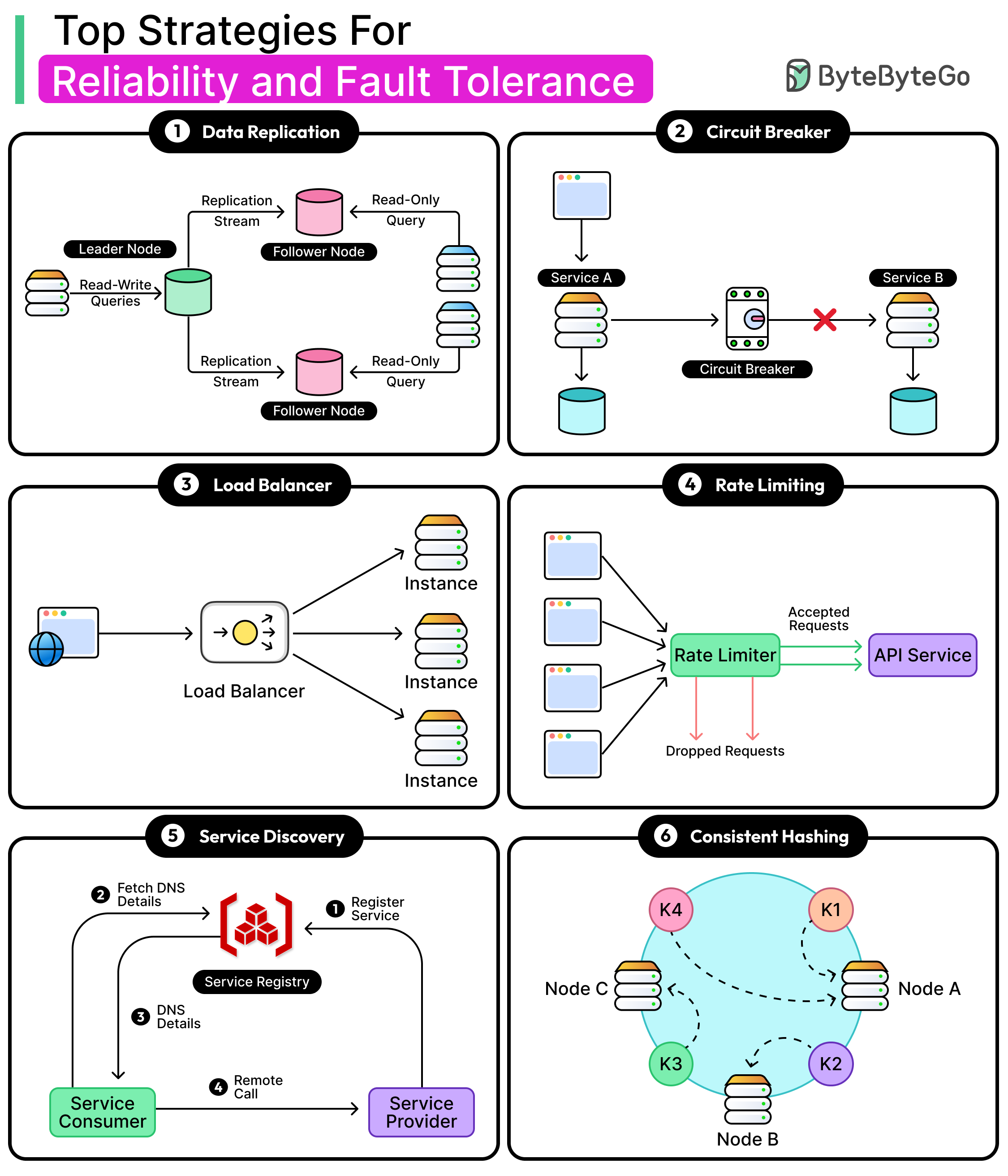
Top Strategies to Improve Reliability in Distributed Systems

Distributed systems fail all the time. There could be a node crashing, a network link going down, or a dependency timing out. It’s hard to predict when these things can happen.
The job of system design isn’t to eliminate these failures. It’s to build systems that absorb them, recover from them, and keep working through them. This is the reason why reliability becomes such an important system quality.
In a distributed setup, reliability doesn’t come from individual components. A highly available database, a fast API server, or a global load balancer on its own doesn’t guarantee uptime. Reliability emerges when all of these components interact in a way that tolerates failure, isolates blast radius, and maintains service guarantees under pressure.
There’s no single universal solution. What may work for a video streaming platform might not be suitable for a financial transaction system. However, some building blocks keep showing up again and again, irrespective of the domain. Here are a few examples:
Fault tolerance enables systems to remain functional even when components fail or behave inconsistently.
Load balancing distributes traffic evenly to avoid overloading any single node or region.
Rate limiting guards against abuse and overload by controlling the flow of incoming requests.
Service discovery enables services to locate each other dynamically in environments where nodes are added and removed frequently.Consistent hashing keeps distributed data placements stable and scalable under churn.
None of these solves reliability alone. But when combined thoughtfully, they form the foundation of resilient architecture. In this article, we will take a closer look at strategies that can help improve the reliability of a system.