
What Actually Happens When You Press ‘Send’ to ChatGPT

Rivian Joins Streamfest 2025 — Hear Their Story (Sponsored)

Join us November 5–6 for Redpanda Streamfest, the two-day online event bringing together engineers and innovators shaping the future of streaming and AI. Hear from Rivian Sr. Staff Software Engineer, Connie Wang, as she shares insights from their experience comparing open-source Kafka and Redpanda in a production environment. It’s a candid look at how the two technologies compare where it counts — performance, reliability, and architectural simplicity. Plus, explore keynotes, hands-on tutorials, and real-world demos from innovators shaping the next generation of streaming systems. Don’t miss this opportunity to learn from the teams building the future of data infrastructure.
Disclaimer: The details in this post have been derived from the official documentation shared online by the OpenAI Engineering Team. All credit for the technical details goes to the OpenAI Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
ChatGPT is one of the most widely used applications built on top of large language models (LLMs).
Developed by OpenAI, it represents a major leap in how humans interact with artificial intelligence. Instead of using fixed commands or rigid search queries, conversations can happen naturally, in plain language, across a wide range of topics. This ease of interaction has made ChatGPT a familiar tool for millions of people, whether for learning, brainstorming, coding help, or everyday problem-solving.
Behind this simple interface lies a powerful set of technologies.
At the core is a transformer-based language model trained on vast amounts of text to predict the next word or token in a sequence. Over the past few years, these models have evolved from basic text generators into sophisticated systems that can reason, follow instructions, use tools, and personalize interactions. Advances in model size, training methods, serving infrastructure, and safety techniques have made it possible to deliver responses in real time to users around the world.
In this article, we will look closely at what actually happens when you press “Send” to ChatGPT. The journey begins with a secure request from the browser and continues through context preparation, tokenization, model inference, and streaming. We will explore how the system calls external tools when needed, applies multiple layers of safety, uses optional memory for personalization, and relies on performance optimizations to stay fast at scale.
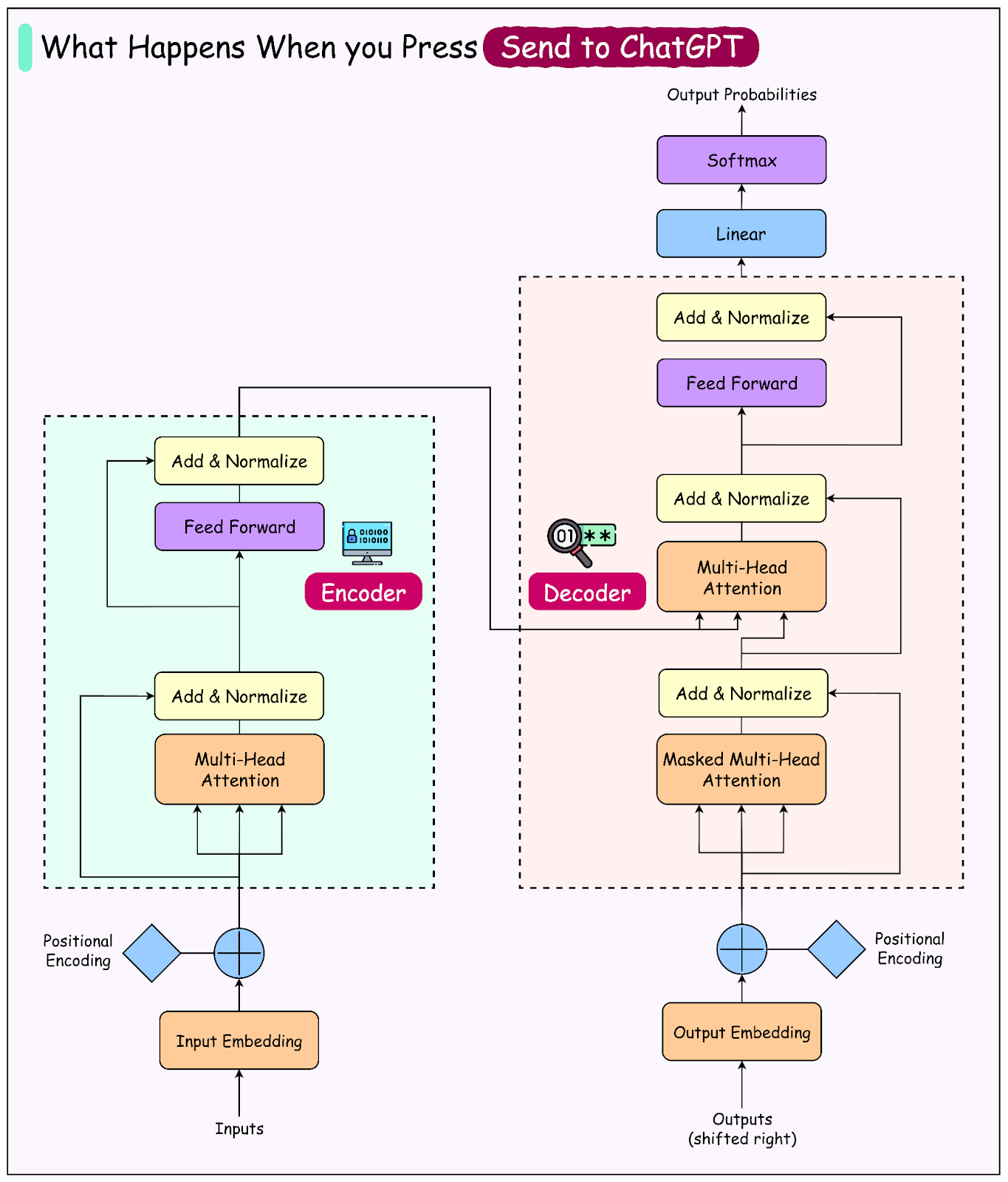
The Complete Journey
Pressing Send may feel like a simple action, but it triggers a carefully designed sequence behind the scenes.
At a high level, the path looks like this:
Step 1 (Sending the message): The typed text leaves the browser through a secure, encrypted connection and reaches OpenAI’s front door. This is where the request is authenticated and checked for basic validity.
Step 2 (Building the context): The system gathers everything the model needs to understand the request. This includes system instructions, any relevant conversation history, and the latest message. Only the useful parts are packed to keep things efficient.
Step 3 (Converting text to tokens): The text is broken down into small units called tokens. Models work with tokens rather than raw text, which allows them to process input systematically and within a defined limit.
Step 4 (Generating the answer): The prepared tokens reach model servers running on specialized hardware. The model predicts the next token repeatedly until the complete answer is formed.
Step 5 (Streaming back to the browser): As soon as the first tokens are generated, they are streamed back to the browser. The reply appears piece by piece, creating the familiar “typing” effect.
Step 6 (Optional actions and checks): If needed, tools can be called during generation, and safety checks are applied before the final response reaches the screen.
In the coming sections, we will look at the various steps in more detail.
Sending the Message
When a message is sent in ChatGPT, the first step is a secure handover.
The browser connects to OpenAI’s servers using HTTPS, which is the standard protocol for secure communication on the internet. HTTPS encrypts the message so that no one can read or alter it while it travels. Along with the text, information about the user’s session and authentication credentials is included. This allows the system to verify that the request is valid and to associate it with the correct account.
Once the request arrives, the platform begins preparing what the model will see. It collects several elements and arranges them in a structured way. These elements usually include system instructions that define how the assistant should behave, the relevant parts of the ongoing conversation, and the latest user message. The goal is to give the model a clear and complete picture without unnecessary clutter.
If certain product features are active, such as web browsing, file search, or code execution, small markers called feature flags are attached to the request. These let the assistant know which tools are available later in the conversation. By the end of this stage, the system has gathered everything needed to construct the model’s working view for the next step.
From Text to Tokens
Before the model can understand a message, the text must be converted into a format it can process efficiently. This is done through a step called tokenization. A token is a small chunk of text, often smaller than a word. For example, common words may become single tokens, while longer or less frequent words can be split into multiple tokens. This approach allows the model to handle text in a consistent and compact way.
Each model works with a fixed amount of tokens at a time, known as the context window. This is like the model’s working space. If the total number of tokens in a conversation grows too large, the oldest parts are trimmed or summarized so that new messages can fit. This is why long conversations may eventually lose some earlier details.
Tokenization happens on OpenAI’s servers, not in the browser. The process is model-specific, meaning each model has its own vocabulary and rules for how text is split. To ensure accuracy, the platform performs the official tokenization right before sending the input to the model.
Token counts also influence cost and speed. Longer inputs mean more tokens, which require more computation and increase processing time. Understanding tokens helps explain why concise messages often lead to faster and cheaper responses.
Transformers
At the heart of ChatGPT lies a type of neural network called a transformer.
The easiest way to think about it is as a very advanced autocomplete engine. It looks at a sequence of tokens and predicts the next one, then the next, and continues this process until the full response is formed. Each token is chosen based on everything the model has already seen, which is why the answers can feel coherent and well-structured.
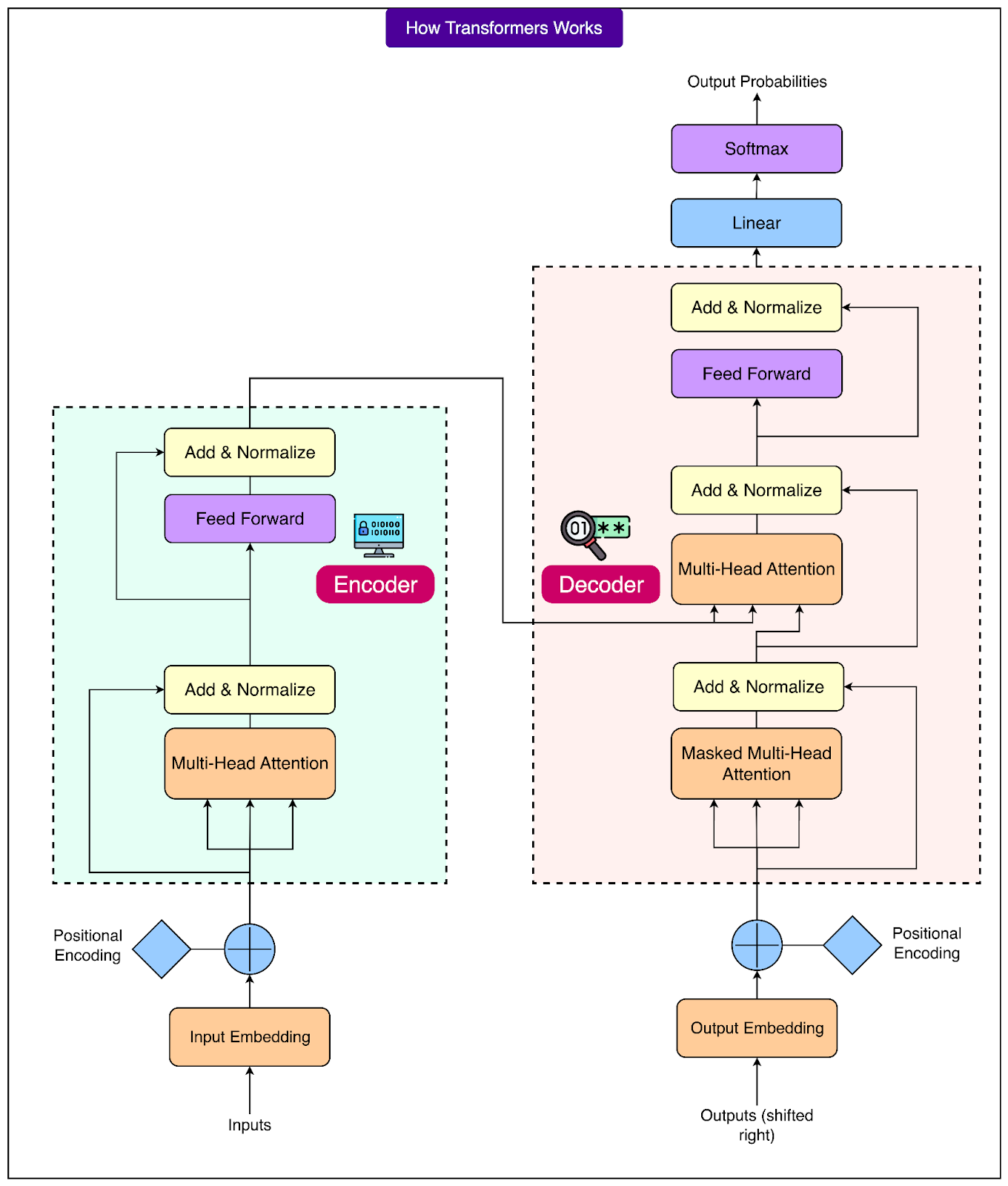
A key part of this process is something called self-attention. This mechanism allows the model to decide which parts of the input are most relevant for predicting the next token. For example, take the sentence: “The trophy didn’t fit in the suitcase because it was too small.” To figure out what “it” refers to, the model looks at all the surrounding words and focuses on the ones that provide the most clues. Self-attention is what enables this kind of reasoning across the entire sentence rather than just the previous word.
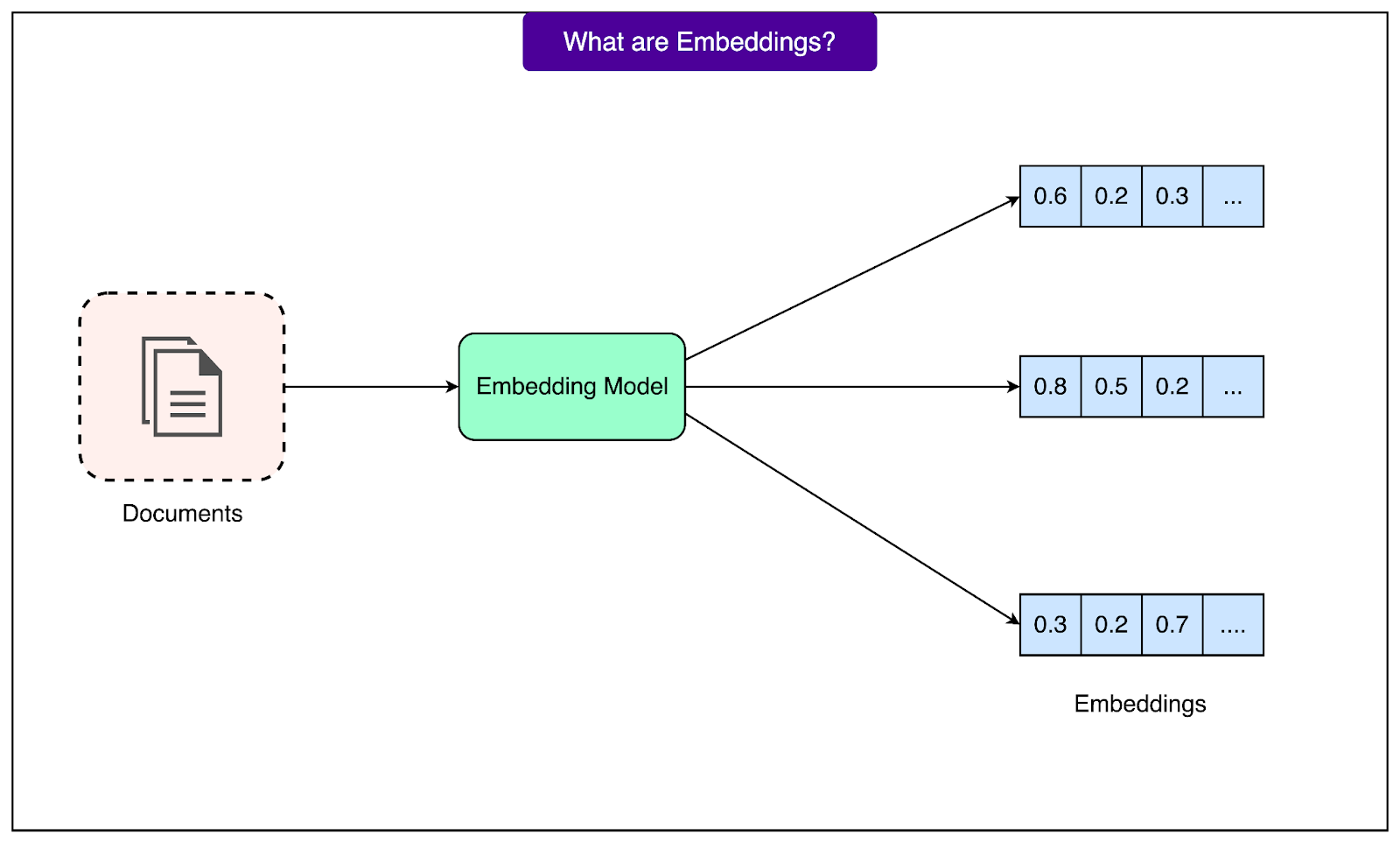
Before this can happen, tokens are turned into embeddings. An embedding is a set of numbers that represents the meaning of a token in a way the model can understand. Tokens with similar meanings are placed close to each other, which helps the model capture relationships between words like “cat” and “kitten.”
Transformers also need to know the order of tokens. This is handled by positional information, which labels tokens with their positions in the sequence (first, second, third, and so on). This ensures that the model treats “the cat chased the dog” differently from “the dog chased the cat.”
There are two distinct phases in how transformers are used.
During training, the model learns these patterns by analyzing massive amounts of text over weeks on large clusters of GPUs.
Once training is complete, inference is what happens during a chat session. Inference is fast, usually taking only milliseconds per token, which allows the model to generate text as the conversation happens.
This separation explains why the model can feel both knowledgeable and quick in producing answers.
Streaming the Reply
When a response begins to appear in the chat, it is not sent back all at once. Instead, the platform uses a technique called streaming. Once the model starts generating tokens, the server sends these tokens in small chunks as soon as they are ready. The browser then displays each chunk immediately, which creates the familiar effect of the text appearing gradually on the screen.
This streaming approach makes the interaction feel fast, even though the full response may still be in progress. While the model is working on the later parts of the answer, the first few sentences are already visible. This is more efficient than waiting for the entire answer to be generated before sending anything back.
During a response, the assistant may decide to call a tool, such as browsing the web or running code. In these situations, the visible stream can pause for a moment while the tool finishes its work. Once the result returns, the model continues generating tokens, and the streaming resumes smoothly from where it left off.
OpenAI describes this behavior as sending “chunked responses.” Each chunk represents a small piece of the model’s output, streamed in sequence over the same connection, until the entire reply is complete. This method is central to why ChatGPT replies feel quick and conversational rather than delayed and static.
Tool Calling
Sometimes a response requires more than just the model’s existing knowledge. In such cases, ChatGPT can call tools to gather fresh information or perform specific actions. This happens through a structured process. The model generates a special message that includes the name of the tool to be used and any required input details in a machine-readable format. The platform then runs the tool, collects the result, and passes that result back to the model. Once the information is available, the model continues writing the response using the new data.
A simple example makes this clearer. Suppose the question is “What’s the weather in San Francisco?” The model recognizes that it does not have real-time weather data. Instead of guessing, it prepares a tool call to a weather service with “San Francisco” as the input. The platform executes the tool, retrieves the current weather information, and sends it back. The model then incorporates this result into the final reply, such as “The current temperature in San Francisco is 22°C with clear skies.”
This mechanism allows ChatGPT to extend its abilities beyond what was learned during training. It can search the web, run calculations, analyze files, or interact with other systems, depending on which tools are available in that conversation.
There is also something called the Model Context Protocol (MCP), which is an open and vendor-neutral way for AI systems to interact with external tools. ChatGPT itself uses OpenAI’s native tool-calling framework, but the idea behind both is similar: structured communication between the model and external systems to fetch information or take action when needed.
Safety Guardrails
Safety in ChatGPT is not handled by a single filter. It is built through several layers that work together at different points in the request and response process.
The first layer acts on incoming prompts. When a message reaches the platform, it can be scanned for categories of content that may break usage policies. This step happens before the model sees the message. If the input clearly violates certain rules, the system can block the request early or modify how the model handles it.
The second layer is part of the model itself. During training, the model is aligned to avoid producing outputs that fall into restricted categories. This alignment shapes how the model responds to sensitive or risky prompts. It may refuse to answer, give a caution, or redirect the conversation in a safer direction. These behaviors are not random. They reflect policy choices made during alignment and reinforcement.
The third layer works on outgoing responses. Even after the model generates tokens, the platform can apply additional checks. These can detect and prevent disallowed content from reaching the user. If a response violates rules at this stage, it may be blocked or rewritten.
Refusals or changes to responses are usually the result of these safety systems doing their job, not technical errors. This multi-step approach allows the system to manage a wide range of scenarios more reliably than any single check could.
Memory and Personalization
ChatGPT includes an optional Memory feature that allows it to remember certain useful details between conversations.
This can include personal preferences, ongoing projects, or other information that helps keep future interactions consistent. For example, it can remember that someone is learning a particular programming language or prefers shorter explanations. Memory is not automatically created for everything. Users can explicitly ask ChatGPT to remember or forget specific details. All stored memories can be viewed, edited, disabled, or completely cleared at any time from the settings.
When a new message is sent, the platform retrieves only the memory snippets that are relevant to the current conversation. These snippets are added to the prompt before it is given to the model. This gives the model helpful context so it can personalize the response without overwhelming it with unrelated information. The retrieval process happens quickly and is handled entirely on the server side.
Performance Tricks
Behind the smooth chat experience, several optimizations are working quietly to keep the system fast and scalable.
These techniques do not alter the words being sent or received. Instead, they make the service more efficient and help maintain good performance even when many people are using it at the same time.
One important technique is batching. Many incoming requests can be grouped when they are compatible. These groups are then processed in a single pass on the GPU hardware. Since modern models rely heavily on GPU computation, batching allows the system to use this hardware more effectively. It improves overall throughput without slowing down individual responses, which is essential when serving millions of users simultaneously.
Another useful method is prompt and state caching. Large parts of a conversation, such as the system instructions or earlier turns, often remain unchanged from one request to the next. Instead of recomputing these parts every time, the platform stores the internal model state for reuse. By reusing cached results, the system reduces both latency and computational cost. This is especially beneficial for long conversations or repeated prompts.
Finally, streaming plays a direct role in how responsive the chat feels. The model starts sending tokens as soon as they are generated, rather than waiting for the entire response to finish. This hides the remaining computation time and gives the impression of a continuous, quick reply, even for longer answers.
These performance techniques work together to keep the service responsive and cost-efficient. While they operate entirely in the background, their impact is noticeable in the smooth, real-time feel of ChatGPT conversations.
Conclusion
Pressing Send in ChatGPT sets off a carefully structured chain of events that combines secure communication, language processing, model inference, and real-time delivery. A message travels through encrypted channels, is prepared with context and feature flags, and is converted into tokens that the model understands. The transformer model then predicts tokens step by step, while the system streams those tokens back to the browser as they are generated. This is why replies appear quickly and feel interactive rather than delayed.
Along the way, safety systems work at multiple stages to keep conversations within guidelines, and optional memory features allow personalization when enabled. Tool calling extends the assistant’s abilities by bringing in fresh data or running specific actions. Behind the scenes, batching, caching, and streaming optimizations ensure that performance remains strong even when millions of users are active. The service runs on a globally distributed infrastructure, supported by data controls and residency options for different user needs.
Understanding these steps removes much of the mystery behind ChatGPT’s behavior. It turns what can seem like an instant, magical response into a clear process with many coordinated parts. This foundation helps build both technical intuition and realistic expectations about how large language model systems operate in practice.
References:
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are, what you do, and how I can improve ByteByteGo
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
I thought GPT5 and the other models used in ChatGPT are decoder only model, I see the diagram has a encoder/decoder. Also, during inferencing tokenization, prefill and decoding are the three main phases. It would have been great if the blog covered those concepts. I somehow felt that the steps mentioned here may not be exactly what chatgpt does when a request is sent to it, but I would like to get myself corrected if my observation is incorrect.
ChatGPT dropped a new product called Agent Builder last week and I couldn’t wait to jump on the bandwagon and play around with it.
I tested it out by wrapping my API endpoint inside a custom MCP server, then hooked it up as a custom server in ChatGPT’s new Agent Builder, right inside the drag-and-drop canvas.
While connecting my own custom MCP server, I ran into a few little gotchas that you’ll definitely want to know about if you’re planning to build one yourself.
https://xianli.substack.com/p/how-i-connected-a-custom-mcp-server