
What Happens When a SQL is Executed?

Have you ever wondered how a simple SQL command unlocks database power? SQL, or Structured Query Language, is the backbone of modern data management. It allows efficient retrieval, manipulation, and management of information in relational databases.
Behind every query we run, there’s a complex sequence of processes. These transform our commands into actions performed by the database management system (DBMS). Mastering these processes lets us harness their full potential.
As developers, it’s crucial to understand the journey of a SQL statement. This journey takes us through the SQL parser, query optimizer, execution engine, and underlying storage engine. With this insight, we can:
Enhance query performance by understanding how data is stored, indexed, and accessed.
Choose effective indexing strategies, informed by our understanding of the DBMS architecture.
Improve resource management, from memory allocation to caching to query execution parallelism.
Diagnose and address performance bottlenecks effectively by identifying potential areas of contention, resource constraints, or inefficiencies within the system.
Join us as we explore MySQL. We will use it to demonstrate database architectures and how queries are processed.
SQL Standards
SQL standards are developed and maintained by international standards organizations, such as the International Organization for Standardization (ISO) and the American National Standards Institute (ANSI). These standards are shaped with contributions from industry experts and database vendors. Their goal is to ensure interoperability, portability, and consistency across various SQL implementations. This enables developers to write SQL code that can run on multiple database platforms.
The diagram below presents a brief history of SQL standards.
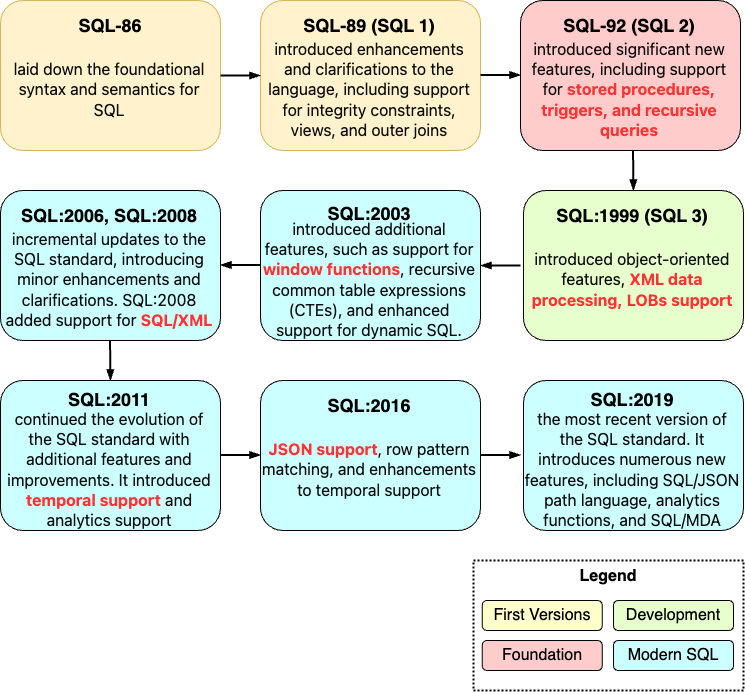
There are 4 stages in SQL standard development. It began with the early versions – SQL-86, SQL-89, and SQL-92- – which formed the foundation and introduced major keywords. SQL:1999 is often recognized as a pivotal point in modern SQL development. However, later standards have continued to introduce valuable features and improvements. These address ongoing challenges in data management and adapt to technological advancements.
Each SQL standard builds on the work of its predecessors, contributing to the ongoing evolution and refinement of the language.
SQL Statement
A SQL statement is a command interpreted and executed by the SQL engine. It is primarily considered a declarative language, focusing on specifying what data should be retrieved or manipulated rather than how to retrieve it.
SQL abstracts the implementation details of data retrieval and manipulation. Developers use SQL's high-level syntax to express their data requirements without worrying about low-level details such as disk I/O operations, data access paths, or index usage.
The portability of SQL across different database platforms is one of its key advantages. SQL queries written for one system often require minimal or no modifications to run on another, as long as they adhere to the SQL standards.
Consider the following example of SQL syntax. The SELECT statement retrieves specific data from one or more tables. It’s paired with the FROM clause, which specifies the tables involved in the query.
To incorporate data from multiple tables, the JOIN clause establishes relationships between them based on shared keys or conditions. The WHERE clause allows for the filtering of rows based on specified conditions, further refining the result set.
For aggregating data based on common attributes, the GROUP BY clause is employed. This facilitates summary statistics or grouping operations. Finally, the ORDER BY clause sorts the query results in a specified order based on columns.

SQL Execution (Query)
Let’s explore the lifecycle of a SQL statement in a relational database, using MySQL as an example.
Broadly speaking, MySQL is structured into two main tiers: the Server tier and the Storage Engine tier.
Server Tier: This tier includes connectors, query caches, analyzers, optimizers, and executors. It covers most of the core service functions of MySQL, including all built-in functions such as date, time, mathematical, and cryptographic functions. All cross-storage-engine functionalities, like stored procedures, triggers, and views, are implemented at this layer.
Storage Engine Tier: This layer is responsible for data storage and retrieval. Its pluggable architecture allows for the use of various storage engines, such as InnoDB, MyISAM, and Memory. InnoDB is the most popular and has been the default storage engine since MySQL version 5.5.5.
When executing a “create table” command, MySQL defaults to using InnoDB. However, users can specify another engine by including options like engine=memory for an in-memory engine or other supported engines according to their needs. Each storage engine offers different methods of accessing table data and supports different features.
The diagram below illustrates the high-level architecture of MySQL. Let's walk through it step by step.

