
What’s Next in AI: Five Trends to Watch in 2026

Technical Guide: How to Orchestrate Langchain Agents for Production (Sponsored)

Building with LangChain agents is easy. Running them reliably in production is not. As agent workflows grow in complexity, you need visibility, fault tolerance, retries, scalability, and human oversight. Orkes Conductor provides a durable orchestration layer that manages multi agent workflows with state management, error handling, observability, and enterprise grade reliability. Instead of stitching together fragile logic, you can coordinate agents, tools, APIs, and human tasks through a resilient workflow engine built for scale. Learn how to move from experimental agents to production ready systems with structured orchestration.
2026 has already started strong. In January alone, Moonshot AI open-sourced Kimi K2.5, a trillion-parameter model built for multimodal agent workflows. Alibaba shipped Qwen3-Coder-Next, an efficient coding model designed for agentic coding. OpenAI launched a macOS app for its Codex coding assistant. These are recent moves in trends that have been building for months.
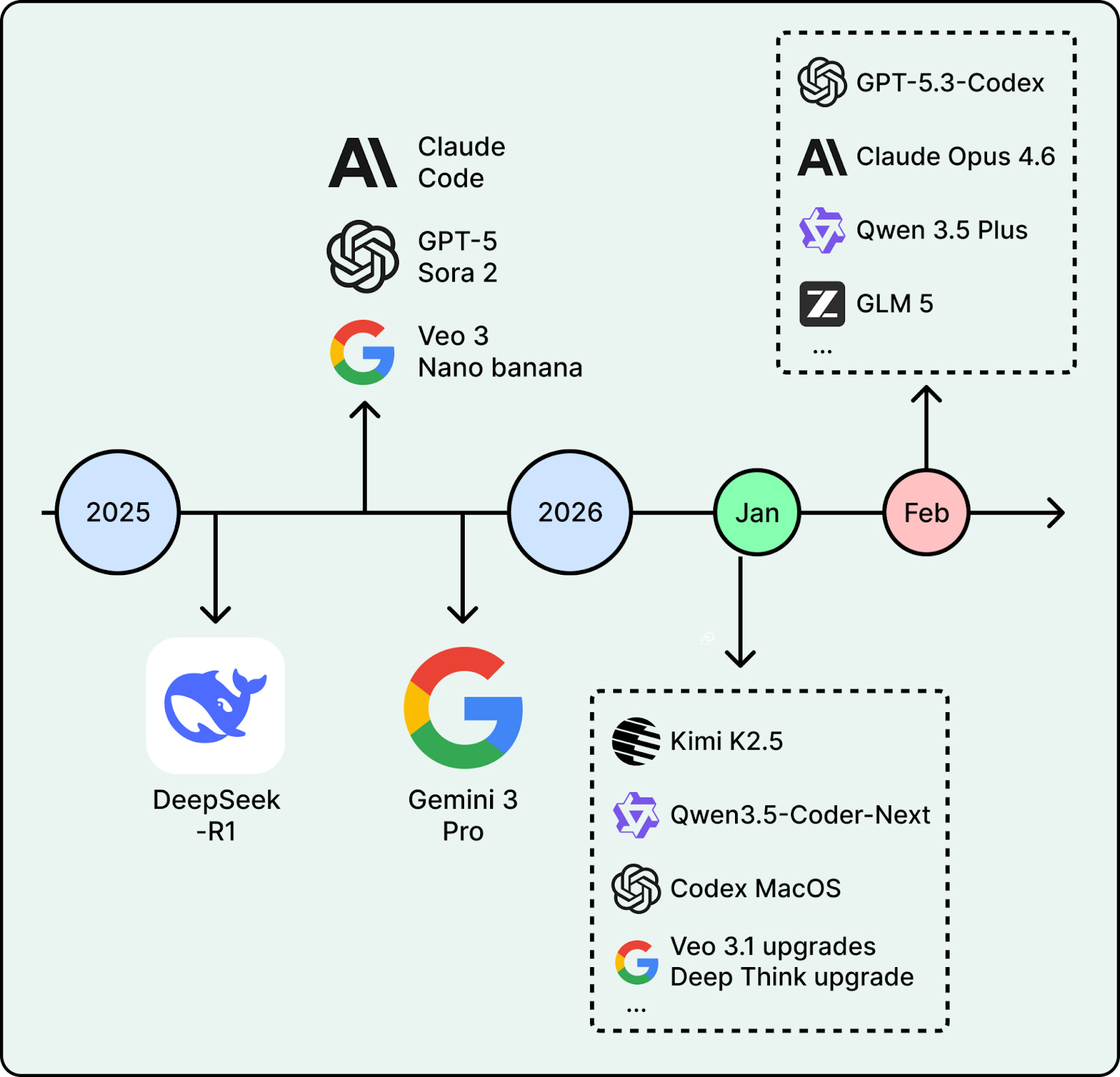
This article covers five key trends that will likely shape how teams build with AI this year.
1. Reasoning and RLVR
Early language models like GPT-4 generated answers directly. You asked a question, and the model started producing text token by token. This works for simple tasks, but it often fails on harder problems where the first attempt is wrong, like advanced math or multi-step logic.
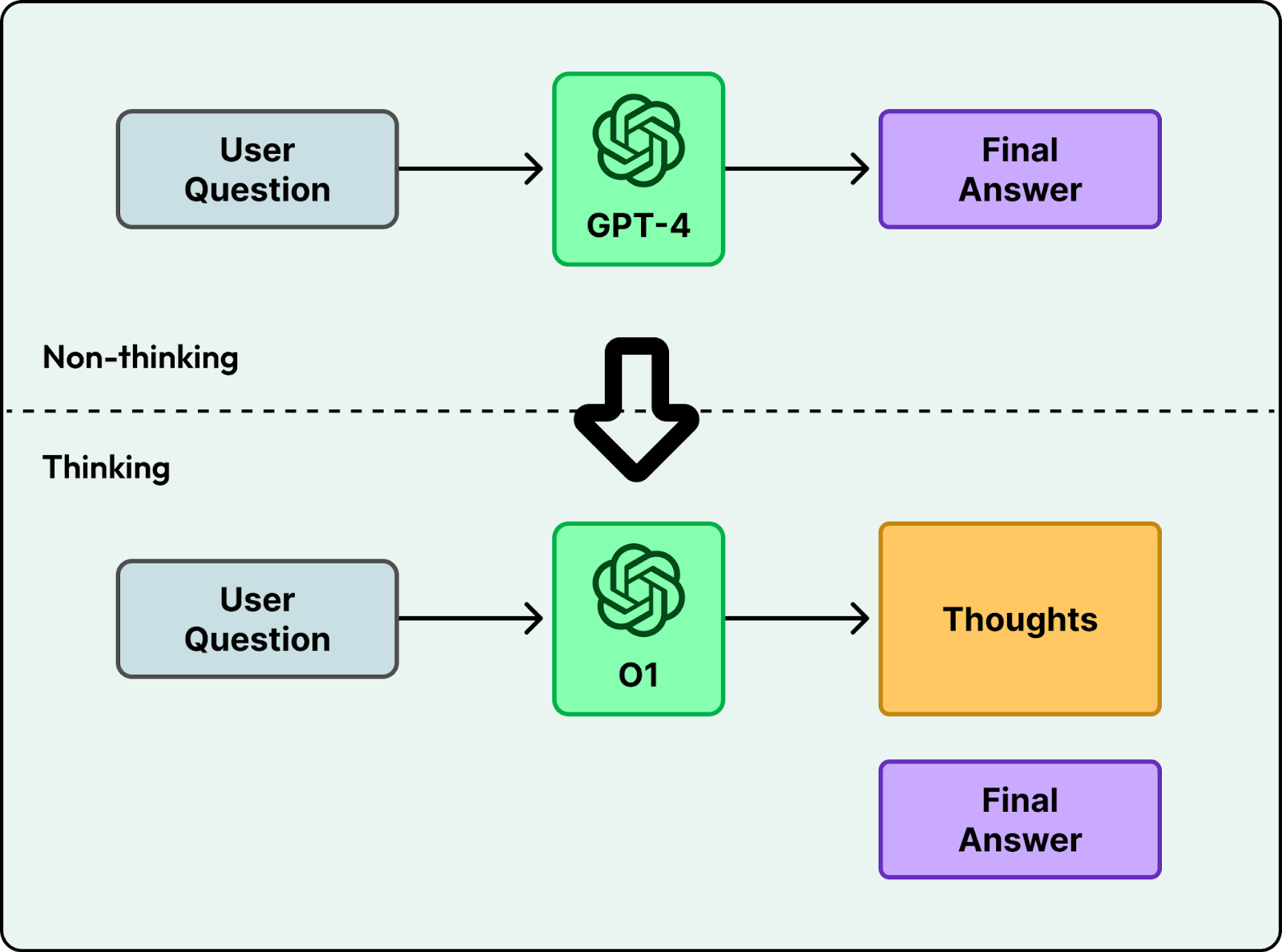
Newer models, starting with OpenAI’s o1, changed this by spending time “thinking” before answering. Instead of jumping straight to the final response, they generate intermediate steps and then produce the answer. The model spends more time and computing power, but it can solve much harder problems in logic and multi-step planning.
After o1, many teams focused on training reasoning models. By early 2026, most major AI labs had either released a reasoning model or added reasoning to its main product.
What is RLVR
A key method that made model training practical at scale was Reinforcement Learning with Verifiable Rewards (RLVR). Although first introduced by AI2’s Tülu 3, DeepSeek-R1 brought the approach to mainstream attention by applying it at scale. To understand how RLVR improves on previous methods, it helps to look at the standard training pipeline.
LLM training has two main stages: pre-training and post-training. During post-training, a Reinforcement Learning (RL) algorithm lets the model practice. The model generates responses, and the algorithm updates its weights so better responses become more likely over time.
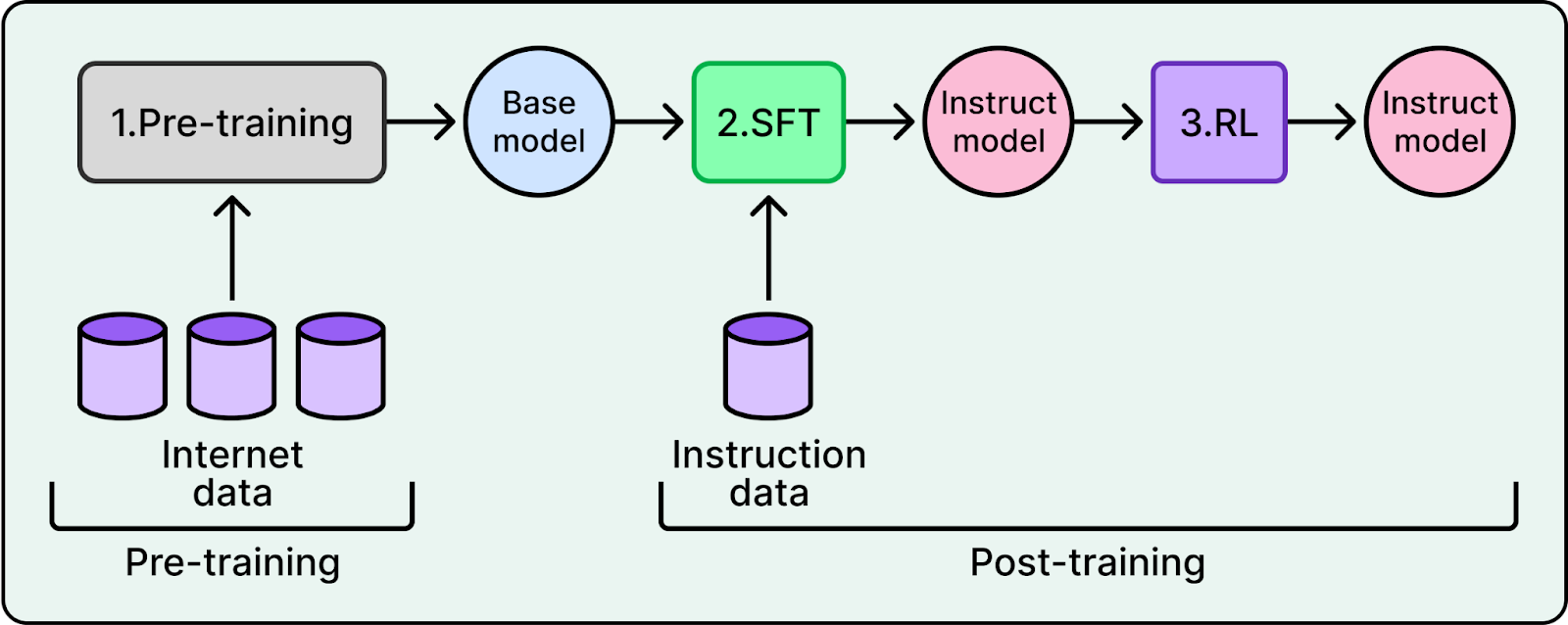
To decide which responses are better, AI labs traditionally trained a separate reward model as a proxy for human preferences. This involved collecting preference data from humans, training the reward model on that data, and using it to guide the LLM. This approach is known as Reinforcement Learning from Human Feedback (RLHF).
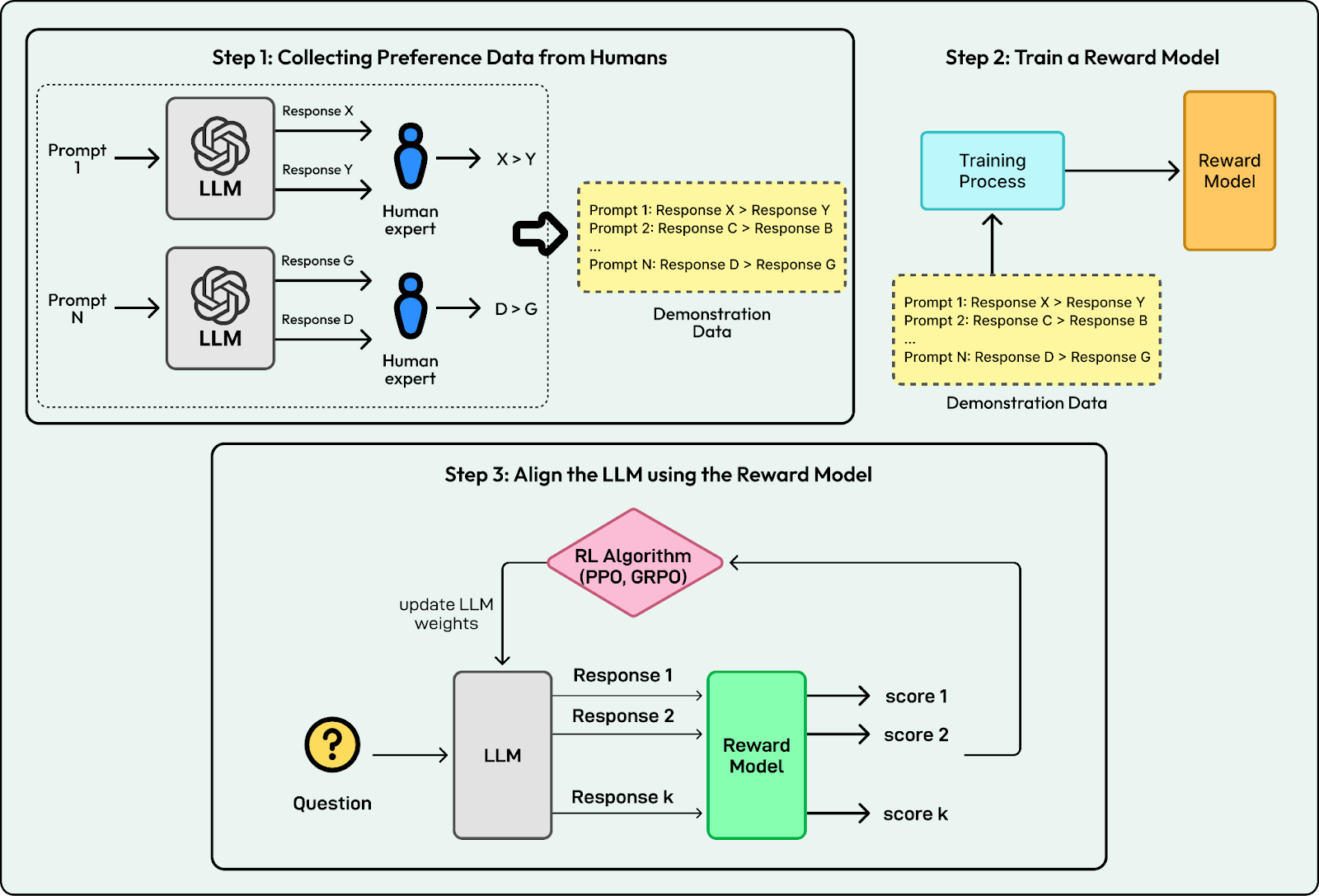
RLHF creates a bottleneck. It depends on humans labeling data, which is slow and expensive at large scale. It also gets harder when the task is complex, because people cannot reliably judge long reasoning traces.
RLVR removes this bottleneck. It still uses reinforcement learning, but the reward comes from checking correctness instead of predicting what a human would prefer. In domains like math or coding, many tasks have answers that can be checked automatically. The system checks if the code runs or if the math solution matches the ground truth. If it does, the model gets a reward. No separate reward model is needed.
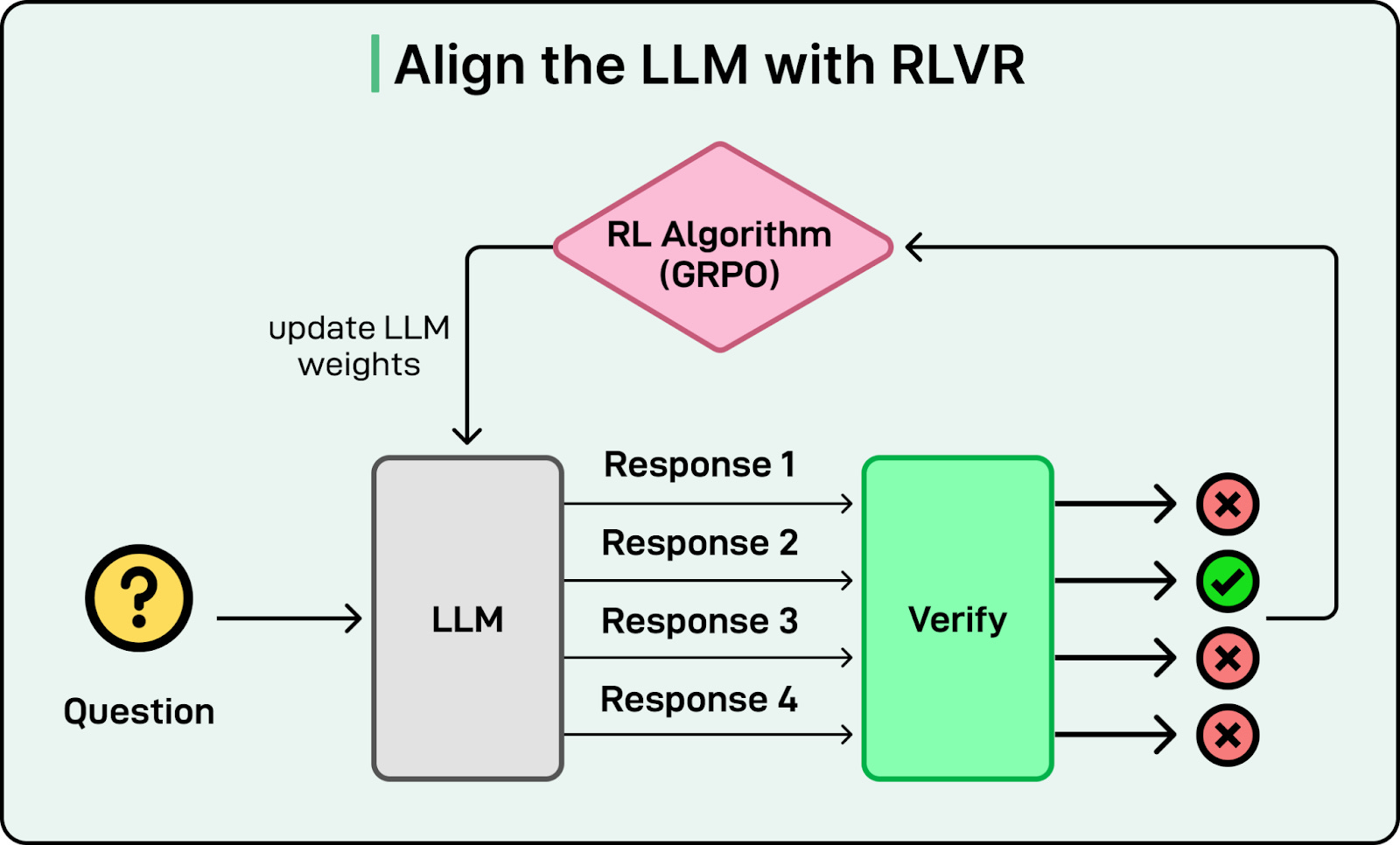
RLVR enables scalable training because correctness checks can run quickly and automatically. The model can practice on millions of problems with immediate feedback. DeepSeek-R1 showed that this approach could reach frontier-level reasoning, shifting the main bottleneck from human labeling to available compute.
What to watch in 2026?
Today, most major AI labs use reasoning in training, and many use RLVR. As a result, reasoning alone is no longer a differentiator. The focus has shifted to efficiency.
AI teams are now working on adaptive reasoning, where the model adjusts its effort based on how hard a prompt is. Instead of spending many tokens on a simple greeting, models reserve deep thinking for problems that actually need it. Gemini 3 is a concrete example. It supports a thinking_level control and uses dynamic thinking by default, so it can vary how much reasoning it applies across prompts. This focus on efficiency will make reasoning models practical for real-world use cases where speed and cost matter.
2. Agents & Tool Use
Early language models were good at generating text, but they could not take actions. If you asked a model to book a flight, it could describe the steps but could not use a booking system. And because it could not check the real world, it often guessed. If you asked “Is the restaurant open right now?”, it might answer from old information instead of checking live hours.
These limits led to the rise of AI agents. An agent combines an LLM with tools and runs it in a loop, allowing it to plan and act. Instead of directly generating the final answer, an agent can take a goal, break it into steps, run tools, and use the results to decide what to do next.
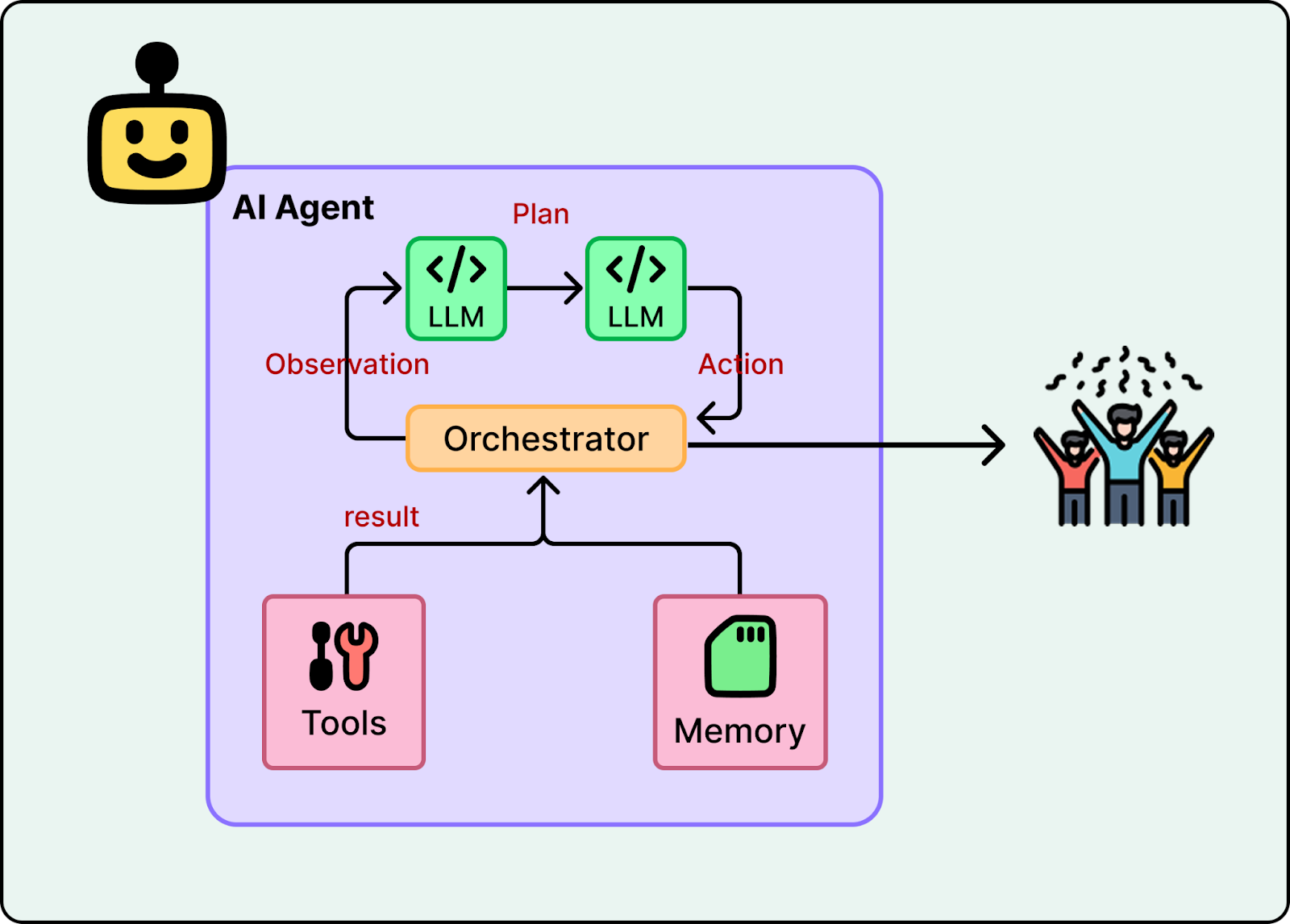
Most agents share the same structure. A language model interprets the request and picks the next step. Tools connect the model to external systems like search, calendars, files, or APIs. A loop runs actions, inspects results, and retries or changes course when something fails.
Why Agents Started to Work Recently
Agents are no longer experimental. They are shipping in real products. OpenAI’s ChatGPT agent can browse the web and complete tasks on your behalf. Anthropic’s Claude can use tools, write and run code, and work through multi-step problems.
Three developments made this possible. First, reasoning improved. Models got better at planning multi-step work, keeping track of intermediate results, and choosing the next action instead of jumping to a final answer.
Second, tool connections became easier. In the past, every tool integration was custom. Protocols like Anthropic’s Model Context Protocol (MCP) reduced the friction of connecting models to external systems. Adding a new tool now takes just a few lines of code.
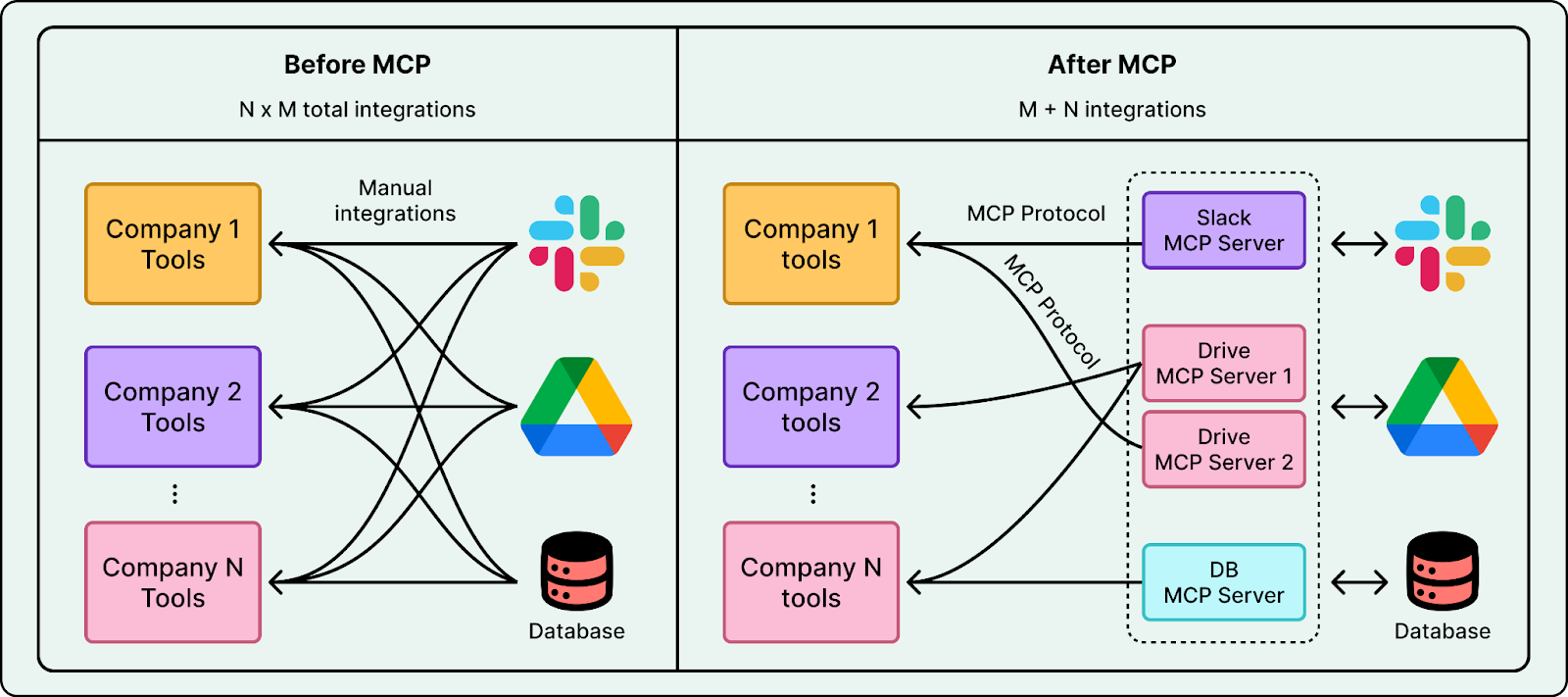
Third, frameworks like LangChain and LlamaIndex matured. They made it easier to build agents without starting from scratch. They provide ready-made components for tool use, multi-step flows, and logging. This lowered the barrier and let more teams experiment with agents.
from langchain_ollama import ChatOllama
from langchain.agents import create_agent
# Create an LLM instance
llm = ChatOllama(model=“gemma3:1b”)
# Create your tool list
tools = [get_weather, web_search]
# Create your agent
agent = create_agent(llm, tools)
# Call your agent using agent.invoke
agent.invoke({”messages”:
[{”role”: “user”, “content”: “Events in SF”}]
})What to watch in 2026?
Agents are good at short workflows, but they still struggle when tasks run long. Over dozens of steps, they can lose context and make mistakes that compound. They are also limited by default access. Many agents run in sandboxed environments and cannot see your email, files, or local apps unless you connect them.
A likely trend in 2026 is persistent agents that address both problems. These are always-on assistants designed to handle longer workflows over extended periods. Many will run locally, making it easier to connect with your files, apps, and system settings while keeping data under your control. OpenClaw is an early example of this shift toward personal agents that run on your own hardware.

More access also increases risk. When agents can read personal data and take actions, mistakes matter more. So a major focus in 2026 will be reliability and security. Reliability means staying on track, recovering from errors, and behaving predictably over long tasks. Security means protecting data, resisting prompt injection, and avoiding irreversible actions without explicit approval.
3. Coding
AI started helping software engineers with simple autocomplete. But the capability was limited. The model could only see the immediate area around your cursor, maybe a few lines before and after. It did not understand the full codebase, the project structure, or what you were trying to build.
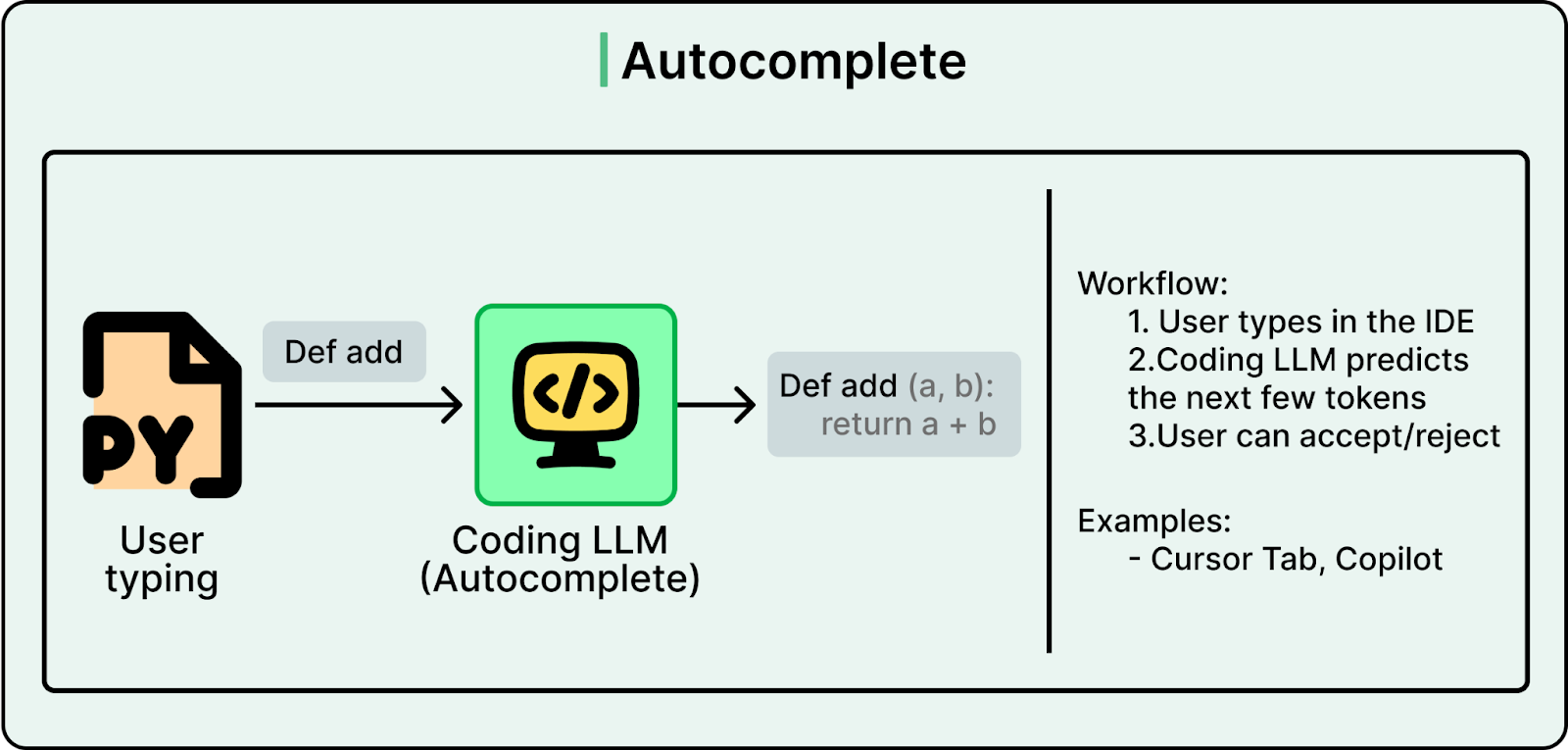
That changed when AI labs applied the agent approach to coding. Rather than relying on general-purpose models, they trained specialized LLMs through extensive fine-tuning on code repositories, documentation, and programming patterns. They also replaced generic tools with coding-specific ones like read_file, search_codebase, edit_file, run_terminal_command, and execute_tests.
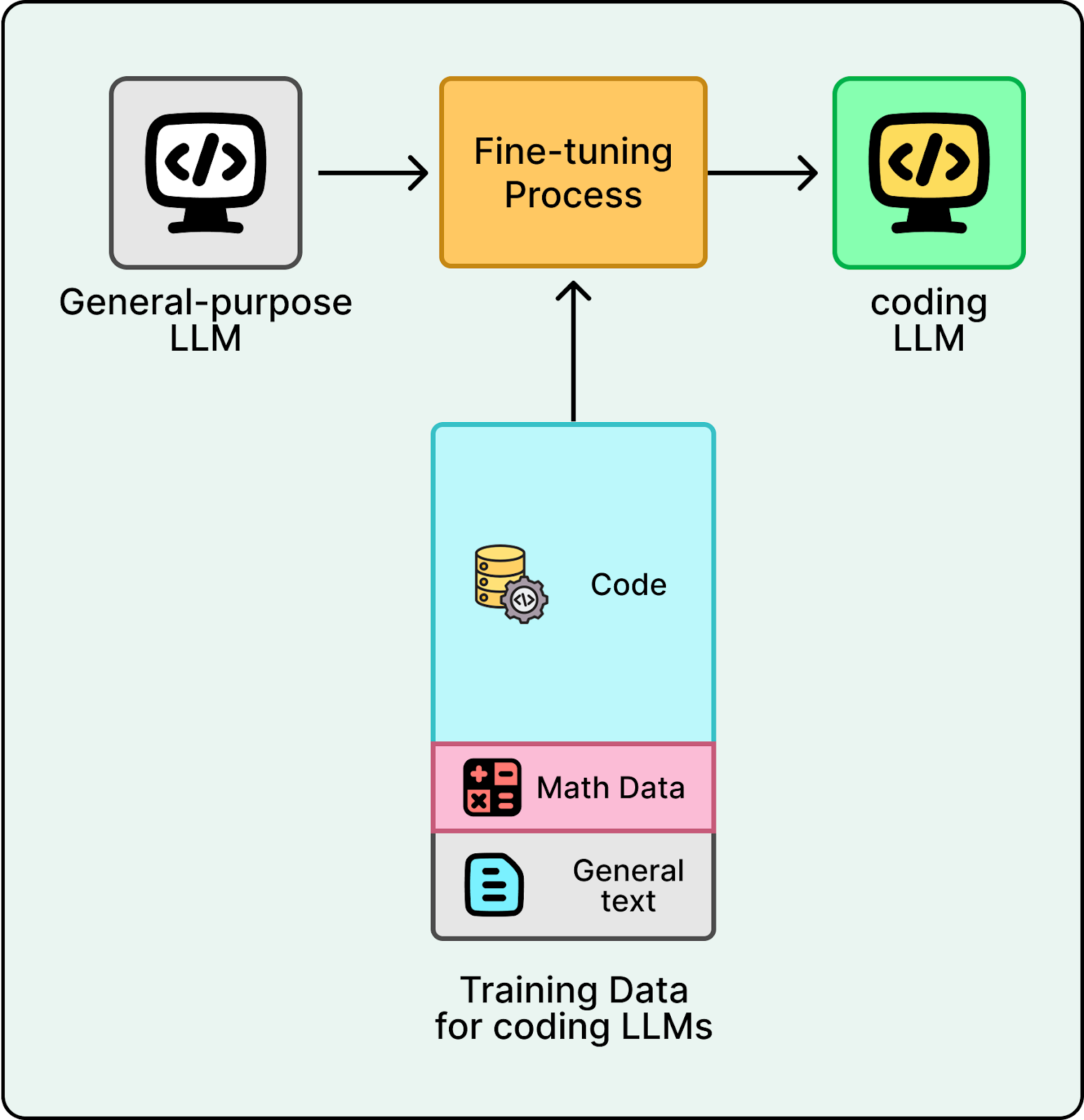
The result is a model that understands software engineering practices like project structure, dependencies, and debugging, and knows how to use its tools to complete tasks. When you give it a complex task, it decides which tools to call and in what order to finish the job.
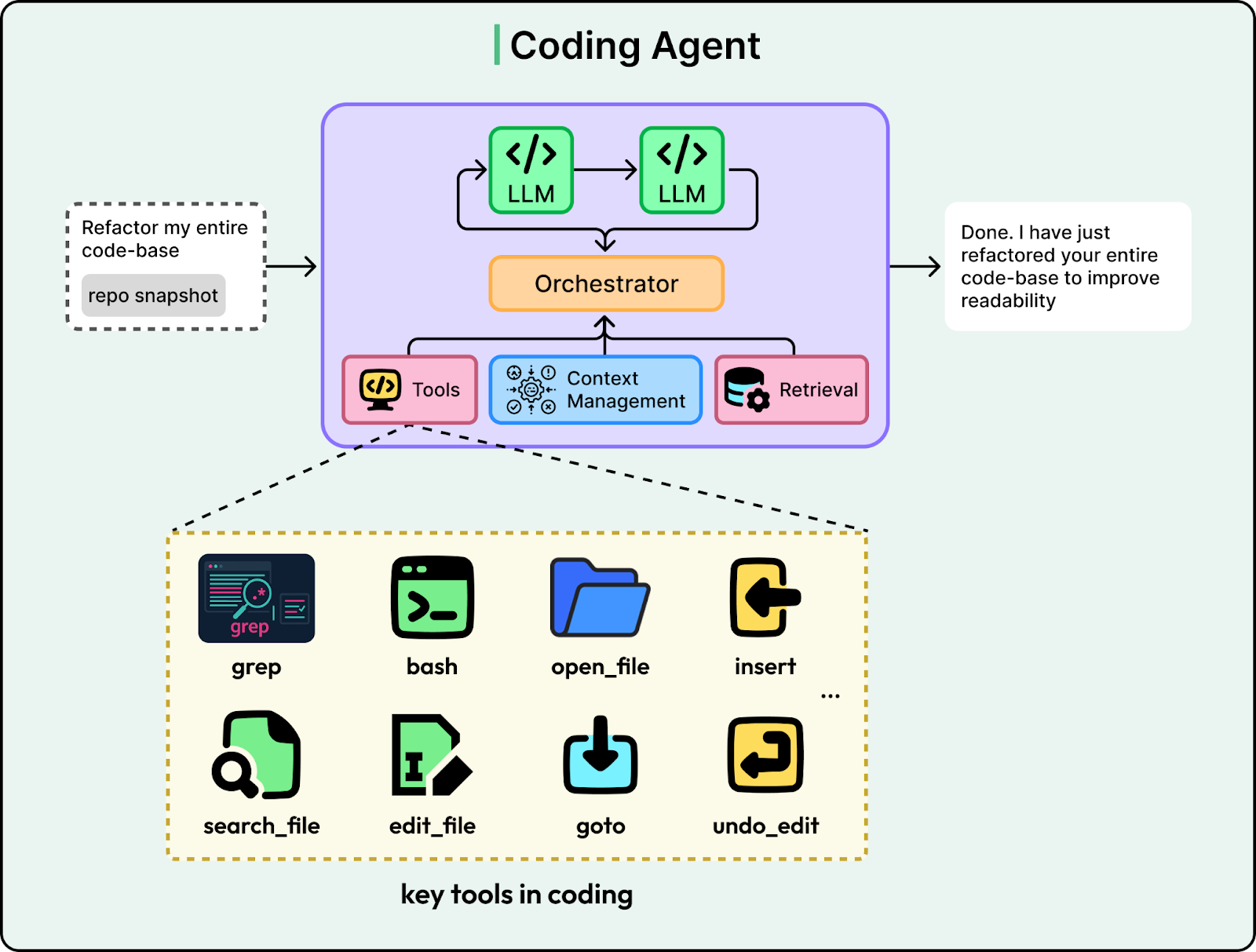
Powerful proprietary coding agents like Anthropic’s Claude Code and OpenAI’s Codex are driving this shift. They can read an entire repository and understand complex project structures. At the same time, open-source models have narrowed the gap. Qwen3-Coder-Next, an 80B-parameter model released in early 2026, reached performance close to top closed models while running locally on consumer hardware.
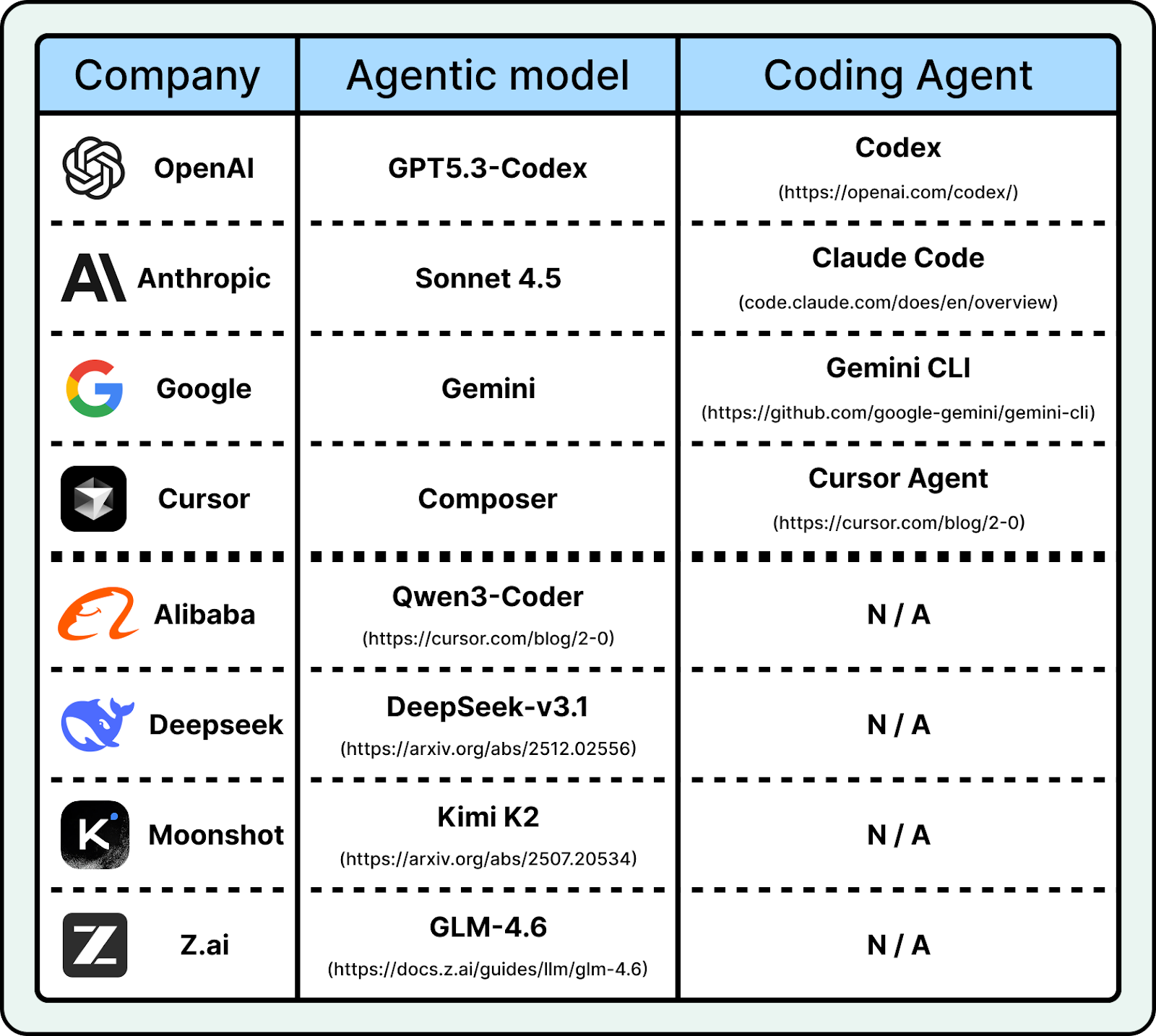
Coding agents are one of the most visible places where AI has already changed day-to-day work. Engineers can ask for repo-level fixes and improvements and get working patches much faster. These tools also lowered the barrier to entry. People with less coding experience can build working apps using services built on top of these agents, like Replit and Lovable.
What to watch in 2026?
The baseline for coding agents is no longer just writing code. It is managing software at scale. Three areas will likely see the most progress.
Deeper repository-level understanding. Current agents sometimes lose track of how files relate to each other in large codebases. Better tracking of dependencies, architecture, and cross-file context will let agents handle bigger and more complex projects reliably.
Security-aware coding. As agents write more production code, catching vulnerabilities before they ship becomes critical. Expect agents to build security scanning and automated test generation directly into their workflow, rather than treating them as separate steps.
Faster completions. Today’s agents can be slow on complex tasks, sometimes taking minutes to plan and execute a multi-file change. AI labs are actively working on reducing the time from request to working code, making agents practical for more real-time development work.
4. Open-Weight Models
For the first few years of the LLM era, the most capable models were closed. If you wanted top performance, you used APIs from labs like OpenAI, Anthropic, or Google. You could not access the weights, run models locally, or fine-tune them. Open-weight models existed but they lagged behind.
That gap did not last long. It narrowed faster than most people expected in two phases: a defining DeepSeek moment, followed by rapid momentum.
DeepSeek Moment
In January 2025, DeepSeek released DeepSeek-R1 and open-sourced its weights, code, and training approach. The reasoning model matched or exceeded closed competitors on key benchmarks. It showed that frontier-level reasoning did not require a proprietary API. People started calling similar breakthroughs a “DeepSeek moment.”
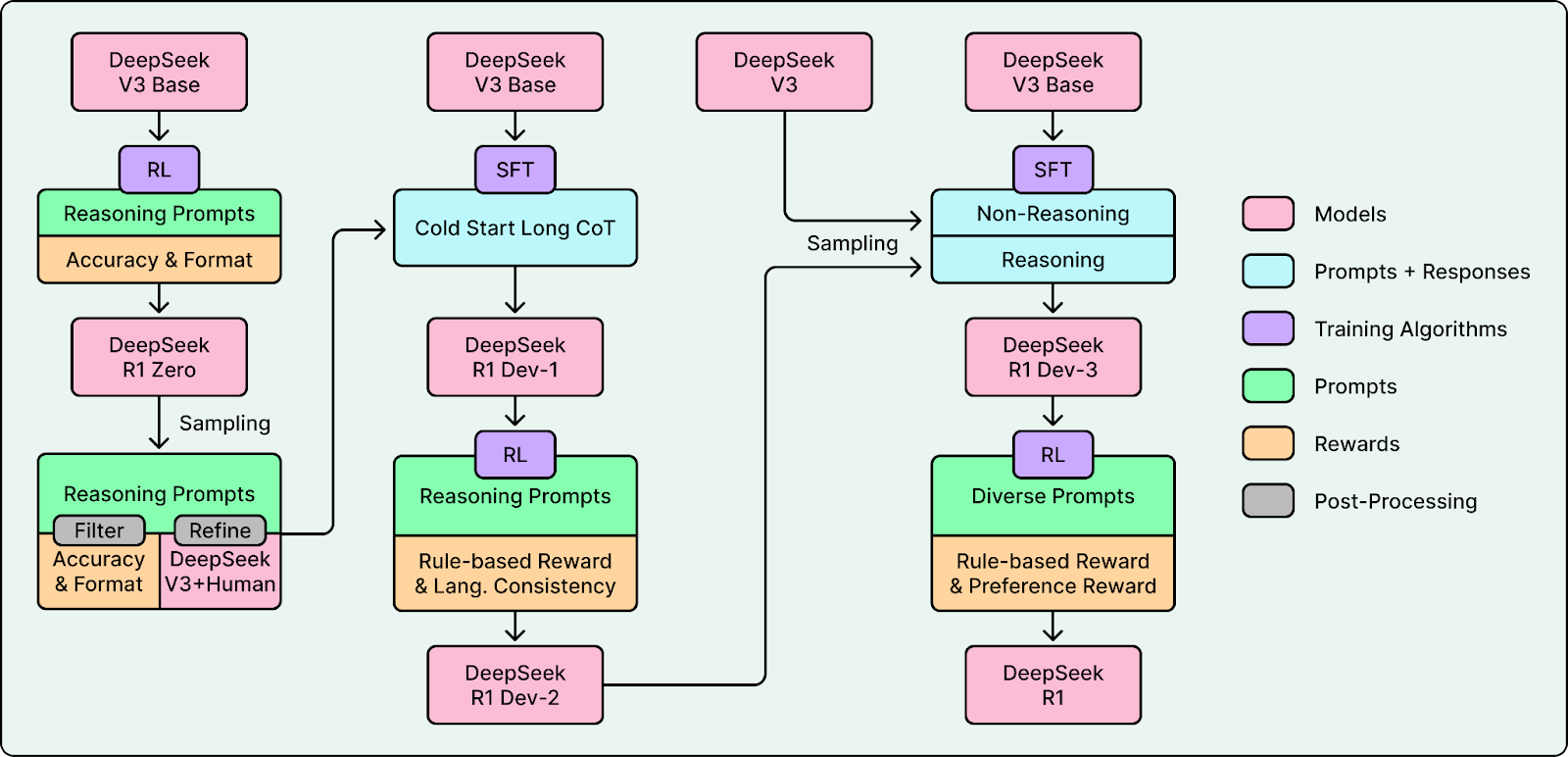
A key reason R1 stood out was its training approach. Before this, many chatbots leaned heavily on RLHF during post-training, the approach popularized by early ChatGPT. DeepSeek leaned heavily on RLVR, which scales better on verifiable tasks like math and coding. That made it easier to train reasoning ability with much less human labeling.
Rapid Momentum
After that, more labs released full weights and training details. Alibaba’s Qwen family became a major base for open development. GLM from Z.ai pushed multilingual and multimodal capability into the open ecosystem. Moonshot’s Kimi family shipped strong agentic and tool-use features. With this momentum, more teams entered and the open-weight ecosystem got much stronger.
In August 2025, OpenAI released gpt-oss, its first open-weight models since GPT-2. The release included 120B and 20B parameter models under the Apache 2.0 license. Mistral, Meta, and the Allen Institute also shipped competitive releases.

With detailed technical reports and working recipes, techniques spread quickly. Teams replicated results, improved them, and shipped variants. Today, open-weight models are close to top closed models on many standard benchmarks.
What to watch in 2026
In 2026, open-weight releases are no longer surprising. The next wave of progress will focus less on scale and more on efficiency, practical deployment, and agent capabilities.
Architectural Efficiency. Architectures are getting more efficient, often using sparse MoE designs plus long context so only a small part of the model is active per token. Qwen3-Coder-Next is one example, with an ultra-sparse setup and a 256k native context window.
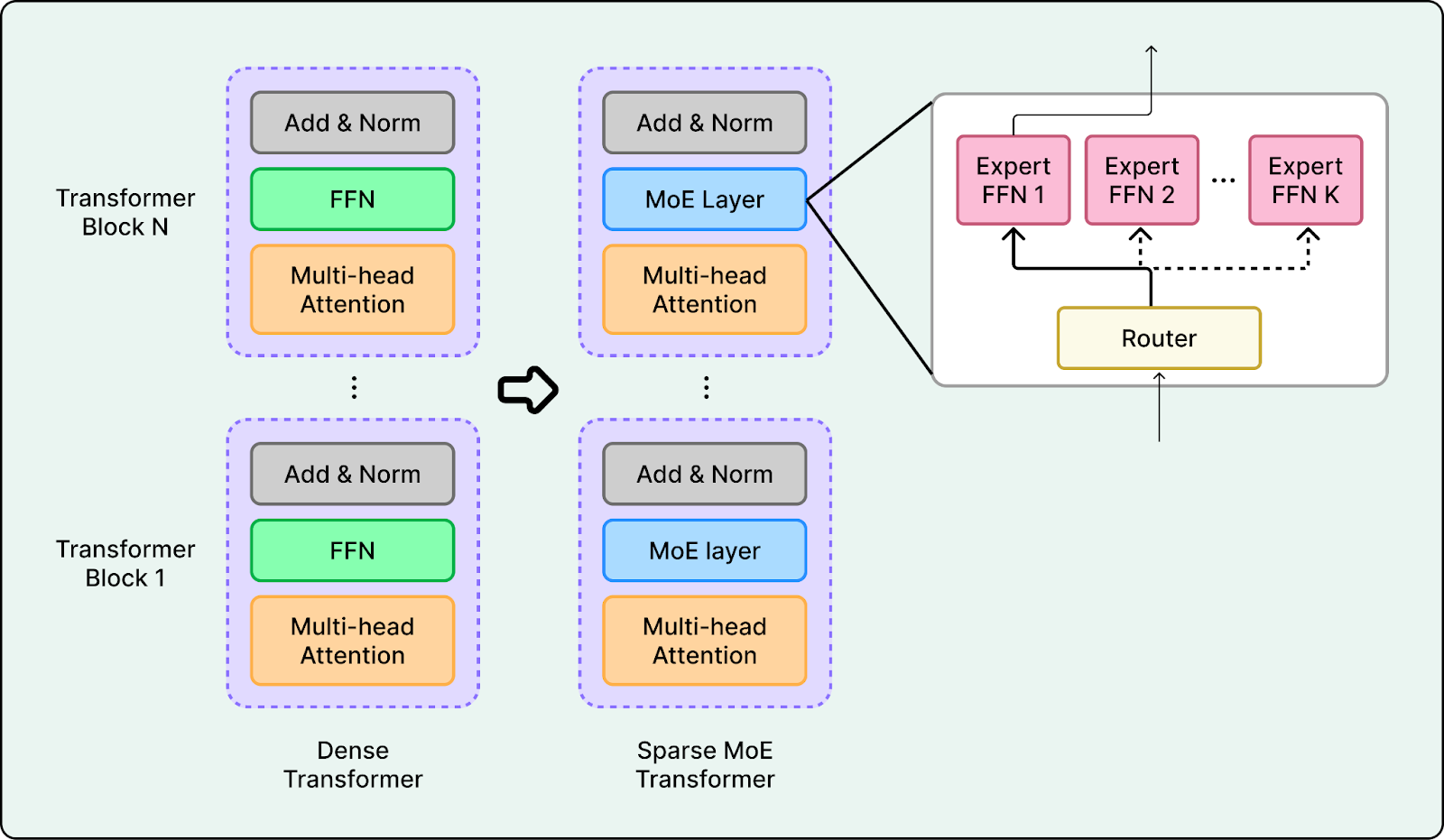
Agent Readiness. Open-weight models are being trained for agent use, not just chat. Tool use, structured outputs, and long-context reasoning are designed in from the start. As agents become central to how AI delivers value, agent-ready open-weight models will power more autonomous workflows.

Easier deployment. Lower barriers to running these models are emerging through new inference formats and compression techniques. Hardware vendors are also stepping up with direct support for open-weight models at launch, treating them as first-class deployment targets.
5. Multi-Modal Models
Most early chatbots were text-in, text-out. Even as they improved, they stayed text-centric. Images, audio, and video were often handled by separate systems. Early image generators could produce striking visuals, but results were inconsistent and hard to control.
This changed in two ways: chatbots became natively multimodal, and generation models improved dramatically.
Natively Multi-Modal Chatbots
The era of text-only models ended as leading models became natively multimodal. Gemini 3 and ChatGPT-5 can handle text and images in a single system, and their products also support richer media interactions. On the open-weight side, Qwen2.5-VL shows similar vision-language capability with strong visual understanding across modalities.
This unified approach enables more natural interactions and new use cases. For example, you can upload a diagram, ask questions about specific elements, and get answers that reference visual details, all within one conversation.
Image and Video Generation
Image and video generation also improved, moving from demos to real tools. OpenAI’s Sora 2 showed video generation at a level that forced the industry to take it seriously. Google’s Veo 3.1, released in October 2025 and updated in January 2026, pushed video generation with richer audio and stronger editing controls like object insertion. Nano Banana Pro (Gemini 3 Pro Image), launched in November 2025, improved image generation and editing, especially text rendering and control.
What to watch in 2026?
Two trends will likely define the next phase of multimodal progress: physical AI and world models.
Physical AI
Physical AI like robots are moving from research into real deployments. CES 2026 featured a wave of humanoid robot demos across many companies. Boston Dynamics unveiled its electric Atlas and announced a partnership with Google DeepMind to integrate Gemini Robotics models. Tesla has also said it plans to ramp Optimus, targeting very high production over time.

These systems combine vision-language understanding, reinforcement learning, and planning. As Jensen Huang put it around CES 2026, “The ChatGPT moment for robotics is here,” pointing to physical AI models that can understand the real world and plan actions.
World Models
The video generation systems described above are learning something deeper than how to produce realistic pixels. They are building basic models of how the physical world works, systems that can simulate physics, predict outcomes, and reason about the real world.
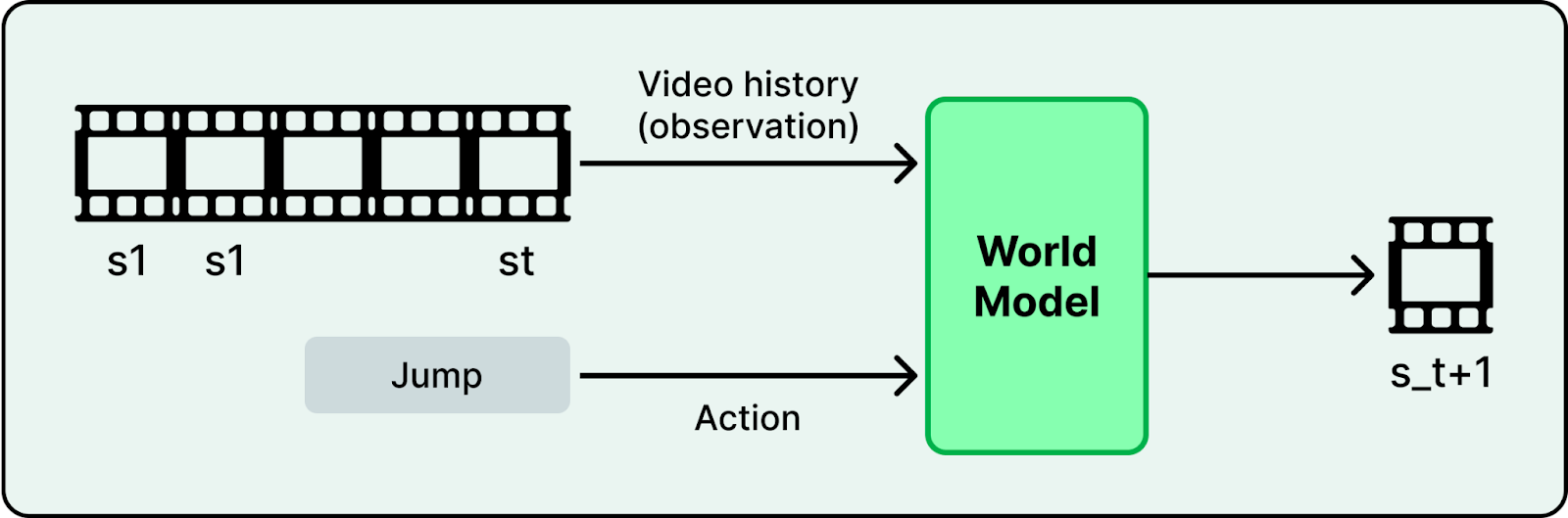
In November 2025, Yann LeCun left Meta to launch AMI Labs, raising €500M to build AI systems that understand physics rather than just predicting text. Google DeepMind released Genie 3, the first real-time interactive world model generating persistent 3D environments. NVIDIA’s Cosmos Predict 2.5, trained on 200 million curated video clips, unifies text-to-world, image-to-world, and video-to-world generation for training robots and autonomous vehicles in simulated environments.

Training better world models will likely continue through 2026. If models can simulate environments reliably, they become a foundation for training robots, autonomous vehicles, and other systems that must operate in the physical world. Video generation, robotics, and simulation are starting to converge into one direction. 2026 will show whether that convergence accelerates or stalls.
Looking Forward
2026 will not be defined by a single breakthrough. It will be shaped by capabilities that now exist together and reinforce each other. These capabilities are already combining to enable new workflows, from autonomous code refactoring to robots learning tasks through simulated environments. It will be an interesting year to watch.
OpenClaw (and their ilk) is the last thing I'm excited about tracking; it feels a bit like the crypto / NFT bubble where madness in disguise of genius forced tons of people to walk out of their basements and buy a mac mini for the first time in their lives. It's so funny that it's not.
The other stuff? Yeah. Excited.
Great synthesis of where things stand! One trend I'd add to the list: the commoditization of the model layer itself.
You touch on it implicitly throughout (RLVR spreading, open-weight models closing the gap, reasoning becoming table stakes) but I think the takeaway deserves to be stated more directly: by end of 2026, the model won't be the moat. The race is already shifting to distribution, data access, and workflow integration.