
From 0 to Millions: A Guide to Scaling Your App - Final Part

In part 3 of this series, we explored the modern application stack for early-stage startups, including a frontend hosting platform, a serverless API backend, and a serverless relational database tier. This powerful combination has taken us far beyond what we used to be able to do with a single server.

As traffic continues to scale, this modern stack will eventually reach its limits. In this final part of the series, we examine where this modern stack might start to fall apart, and explore strategies to evolve it to handle more traffic.
At a certain threshold, handling the scale and complexity of the application requires an entirely new approach. We discussed microservice architecture briefly earlier in the series. We will build on that with an exploration of how hyper-growth startups can gradually migrate to a microservice architecture by leveraging cloud native strategies.
Scaling Modern Startup Stack
As traffic continues to scale, the modern application stack will start to run into issues. Depending on the complexity of the application, the stack should be able to handle low hundreds of thousands of daily active users.
Monitoring and Observability
Well before we run into performance issues, we should have a robust operational monitoring and observability system in place. Otherwise, how would we know when the application starts to fall apart due to rising traffic load?
There are many observability solutions in the market. Building a robust system ourselves is no simple task. We strongly advise buying a solution. Many cloud providers have in-house offerings like AWS Cloud Operations that might be sufficient. Some SaaS offerings are powerful but expensive.

To get an early warning of any system-wide performance issue, we suggest monitoring these critical performance metrics. Keep in mind the list is not exhaustive.
For database:
Read and write request rate.
Query response time. Track p95 and median at the very least.
Database connections. Most databases have a connection limit. Track the number of connections to identify when to scale the database resources to handle increased traffic.
Lock contention. It measures the amount of time a database spends waiting for locks to be released. It helps identify when to optimize the database schema or queries to reduce contention.
Slow queries. It tracks the number of slow queries. It is an early sign of trouble when the rate starts to increase.
For the application tier, the serverless platform should provide these critical metrics:
Incoming request rate.
Response time. It measures the time it takes for an application to respond to a request. Track at least p95 and median.
Error rate. It tracks the percentage of requests that result in an error.
Network throughput. It measures the amount of network traffic the application is generating.
Now that we are armed with the data, let’s see where an application is likely to fall apart first.
Every application is different, but for most applications, the following sections discuss the areas that are likely to show the first signs of cracks.
Scaling the Serverless Database Tier
The first place that could break is the database tier. As traffic grows, the combined read and write traffic could start to overwhelm the serverless relational database. This limit could be quite high. As we discussed before, with a serverless database, the compute tier and the storage tier scale independently. The compute tier transparently scales vertically to a bigger instance as the load increases.
At some point, the metrics would start to deteriorate and it could start to overload the single serverless database. Fortunately, the playbook to scale the database tier is well-known, and it stays pretty much the same as in the early days.
In part 2 of this series, we discussed three strategies for scaling the database tier in the traditional application stack. These strategies are still applicable to the modern serverless stack.
Read Replicas
For a read-heavy application, we should consider migrating the read load to read replicas. With this method, we add a series of read replicas to the primary database to handle reads. We can have different replicas handle different kinds of read queries to spread the load.
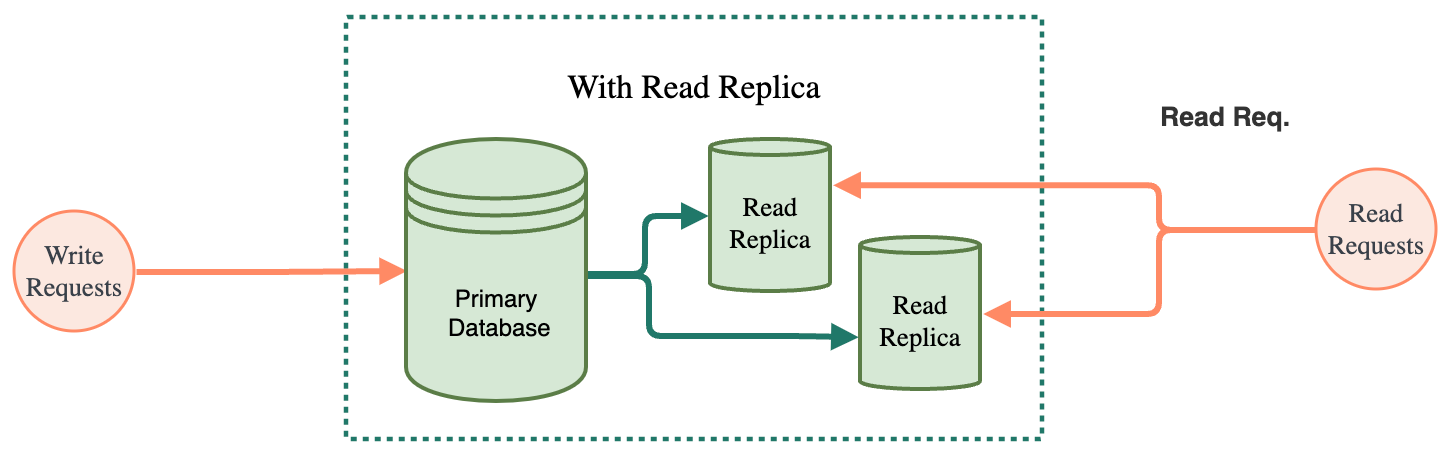
The drawback of this approach is replication lag. Replication lag refers to the time difference between when a write operation is performed on the primary database and when it is reflected in the read replica. When replication lag occurs, it can lead to stale or inconsistent data being returned to clients when they query the read replica.
Whether this slight inconsistency is acceptable is determined on a case-by-case basis, and it is a tradeoff for supporting an ever-increasing scale. For the small number of operations that cannot tolerate any lags, those reads can always be directed at the primary database.
Caching
Another approach to handle the ever-increasing read load is to add a caching layer to optimize the read operations.

Redis is a popular in-memory cache for this purpose. Redis reduces the read load for a database by caching frequently accessed data in memory. This allows for faster access to the data since it is retrieved from the cache instead of the slower database. With fewer read operations performed on the database, Redis reduces the load on the database cluster and enhances its overall scalability. Managed Redis solutions are available through many cloud providers, reducing the burden of operating a caching tier on a day-to-day basis.
Database Sharding
Database sharding is a technique used to partition data across multiple database servers based on the values in one or more columns of a table. For example, a large user table can be divided based on user ID, resulting in multiple smaller tables stored on separate database servers. Each server handles a small subset of the rows that were previously managed by the single primary database, leading to improved query performance as each shard handles a smaller subset of data.

However, database sharding has a significant drawback as it adds complexity to both the application and database layers. Managing and maintaining an increasing number of database shards becomes more complex. Application developers need to implement sharding logic in the code to ensure that the correct database shard is accessed for a given query or transaction. While sharding improves query performance, it can also make it harder to perform cross-shard queries or join data from multiple shards. This limitation can restrict the types of queries that can be performed.
Despite these drawbacks, database sharding is a useful technique for improving the scalability and performance of a large database, particularly when vertical scaling is no longer feasible. It is essential to plan and implement sharding carefully to ensure that its benefits outweigh its added complexity and limitations.
Shifting Workload to NoSQL
Rather than sharding the database, another feasible solution is to migrate a subset of the data to NoSQL. NoSQL databases offer horizontal scalability and high write rates, but at the expense of schema flexibility in the data model. If there is a subset of data that does not rely on the relational model, migrating that subset to a NoSQL database could be an effective approach to scaling the application.

This approach reduces the read load on the relational database, allowing it to focus on more complex queries while the NoSQL database handles high-write workloads. It is important to carefully consider which subset of data is migrated, and the migration process should be planned and executed carefully to avoid data inconsistencies or loss.
