
How McDonald Sells Millions of Burgers Per Day With Event-Driven Architecture

Cloud-scale monitoring with AWS and Datadog (Sponsored)
In this eBook, you’ll learn about the benefits of migrating workloads to AWS and how to get deep visibility into serverless and containerized applications with Datadog.
You’ll also learn how to:
Plan and track every stage of your migration to AWS
Monitor your entire serverless architecture in one place
Ensure your AWS container workloads are operating efficiently
Disclaimer: The details in this post have been derived from the McDonald’s Technical Blog. All credit for the technical details goes to the McDonald’s engineering team. The links to the original articles are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Over the years, McDonald’s has undergone a significant digital transformation to enhance customer experiences, strengthen its brand, and optimize overall operations.
At the core of this transformation is a robust technological infrastructure that unifies processes across various channels and touchpoints throughout their global operations.
The need for unified event processing emerged from McDonald's extensive digital ecosystem, where events are utilized across the technology stack. There were three key processing types:
Asynchronous operations
Transactional processing
Analytical data handling
The events were used across use cases such as mobile-order progress tracking and sending customers marketing communications (deals and promotions).
Coupled with the scale of McDonald’s operations, the system needed an architecture that could handle:
Global deployment requirements
Real-time event processing
Cross-channel integration
High-volume transaction processing
In this article, we’re going to look at McDonald’s journey of developing a unified platform enabling real-time, event-driven architectures.
Design Goals of the Platform
McDonald's unified event-driven platform was built with specific foundational principles to support its global operations and customer-facing services.
Each design goal was carefully considered to ensure the platform's robustness and efficiency. Let’s look at the goals in a little more detail.

Scalability
The platform needed the ability to auto-scale to accommodate demand.
For this purpose, they engineered it to handle growing event volumes through domain-based sharding across multiple MSK clusters. This approach enables horizontal scaling and efficient resource utilization as transaction volumes increase.
High Availability
The platform had to be capable enough to withstand failures in components.
System resilience is achieved through redundant components and failover mechanisms. The architecture includes a standby event store that maintains operation continuity when the primary MSK service experiences issues.
Performance
The goal was to deliver events in real time with the ability to handle highly concurrent workloads.
Real-time event delivery is facilitated through optimized processing paths and schema caching mechanisms. The system maintains low latency while handling high-throughput scenarios across different geographical regions.
Security
The data needed to adhere to data security guidelines.
The platform implements comprehensive security measures, including:
Authentication layers for external partner integrations
Secure event gateways
Adherence to strict data security protocols
Reliability
The platform must be dependable with controls to avoid losing any events.
Event loss prevention is achieved through:
Dead-letter topic management
Robust error-handling mechanisms
Reliable delivery guarantees
Automated recovery procedures
Consistency
The platform should maintain consistency around important patterns related to error handling, resiliency, schema evolution, and monitoring.
Standardization is maintained using:
Custom SDKs for different programming languages
Unified implementation patterns
Centralized schema registry
Consistent event contract management
Simplicity
The platform should reduce operational complexity so that teams can build on the platform with ease.
Operational complexity is minimized with:
Automated cluster management
Streamlined developer tools
Simplified administrative interfaces
Clear implementation patterns
The leading open source Notion alternative (Sponsored)

AppFlowy is the AI collaborative workspace where you achieve more without losing control of your data. It works offline and supports self-hosting. Own your data and embrace a smarter way to work. Get started for free!
Key Components of the Architecture
The diagram below shows the high-level architecture of McDonald’s event-driven architecture.
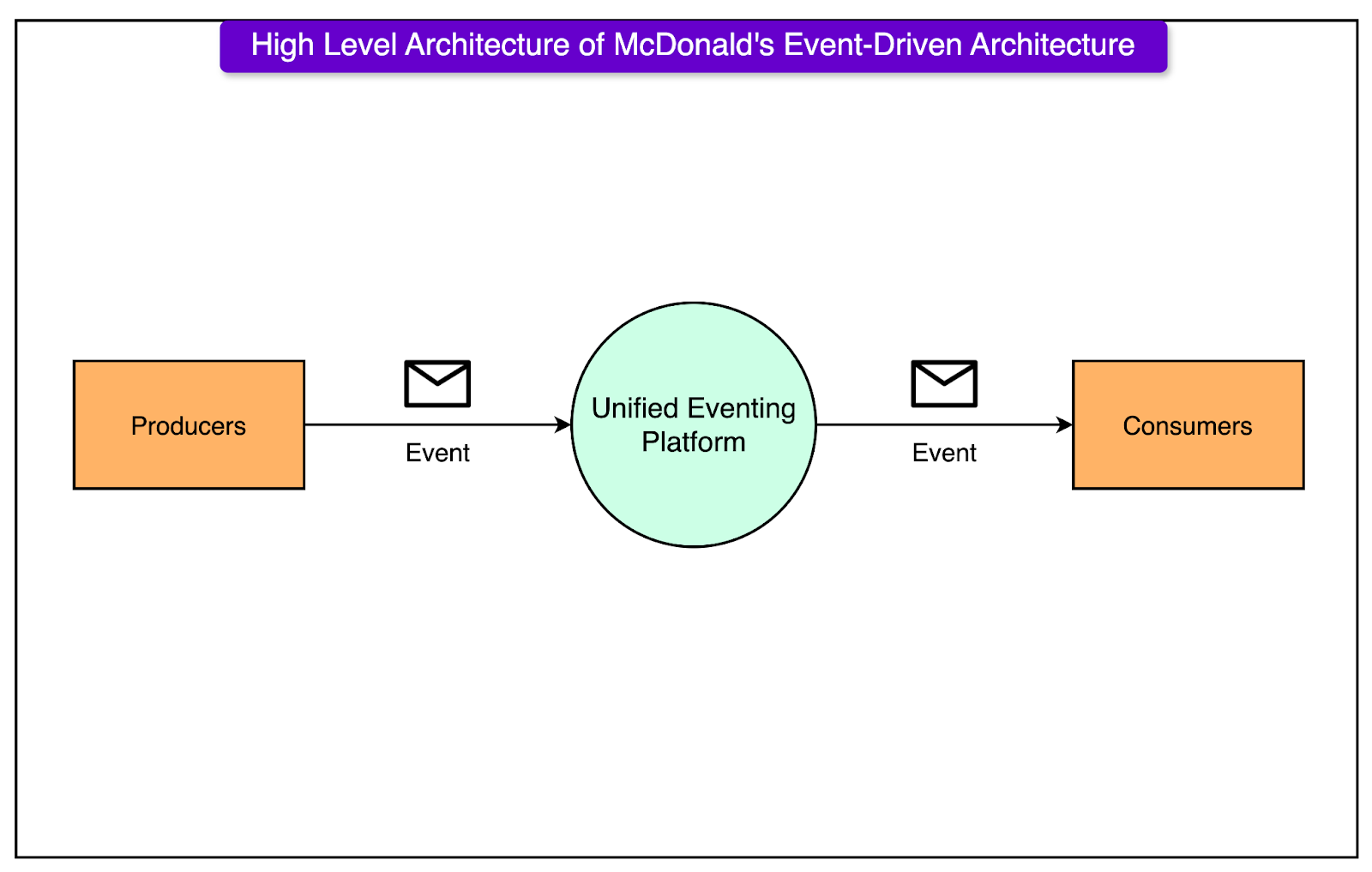
The key components of the architecture are as follows:
Event Broker
The core component of the platform is AWS Managed Streaming for Kafka (MSK), which handles:
Communication management between producers and consumers.
Topic organization and management.
Event distribution across the platform.
Schema Registry
A schema registry is a critical component that maintains data quality by storing all event schemas.
This enables schema validation for producers as well as consumers. It also allows the consumers to determine which schema to follow for message processing.
Standby Event Store
This component helps avoid the loss of messages if MSK is unavailable.
It performs the following functions:
Acts as a fallback mechanism when Kafka is unavailable.
Temporarily stores events that couldn't be published to Kafka.
Works with AWS Lambda function to retry publishing events to Kafka once it is available.
Custom SDKs
The McDonald’s engineering team built language-specific libraries for producers and consumers.
Here are the features supported by these SDKs:
Standardized interfaces for both producers and consumers.
Built-in schema validation capabilities.
Automated error handling and retry mechanisms.
Abstraction of complex platform operations.
Event Gateway
McDonald’s event-based architecture is required to support internally generated events and events produced by external partner applications.
The event gateway serves as an interface for external integrations by:
Providing HTTP endpoints for external partners.
Converting HTTP requests to Kafka events.
Implementing authentication and authorization layers.
Supporting Utilities
These are administrative tools that offer capabilities such as:
Management of dead-letter topics
Error handling for failed events
Administrative interfaces for event monitoring
Cluster management capabilities
Event Processing Flow
The event processing system at McDonald's follows a sophisticated flow that ensures data integrity and efficient processing.
The diagram below shows the overall processing flow.

Let’s look at it in more detail by dividing the flow in two major themes - event creation and event reception.
Event Creation and Sharing
The first step is to create a blueprint (schema) for each type of event and store it in a central library also known as the schema registry.
Apps that want to create events use a special tool (producer SDK) to do so.
When an app starts up, it saves a copy of the event blueprint for quick access.
The tool checks if the event matches the blueprint before sending it out.
If everything looks good, the event is sent to the main message board, which is the primary topic.
If there's a problem with the event or a fixable error, it's sent to a separate area (dead-letter topic) for that app.
If the message system (MSK) is down, the event is saved in a backup database (DynamoDB).
Event Reception
Apps that want to receive events use the consumer SDK. This SDK also checks if the received events match their blueprints.
When an event is successfully received, the application marks it as "read" and moves on to the next one.
Events in the problem area (dead-letter topic) can be fixed later and sent back to the main message board.
Events from partner companies ("Outer Events") come in through the event gateway as mentioned earlier.
Techniques for Key Challenges
The McDonald’s engineering team also used some interesting techniques to solve common challenges associated with the setup.
Let’s look at a few important ones:
Data Governance
Ensuring data accuracy is crucial when different systems share information. If the data is reliable, it makes designing and building these systems much simpler.
MSK and Schema Registry help maintain data integrity by enforcing "data contracts" between systems.
A schema is like a blueprint that defines what information should be present in each message and in what format. It specifies the required and optional data fields and their types (e.g., text, number, date). Every message is checked against this blueprint in real time. If a message doesn't match the schema, it's sent to a separate area to be fixed.
Here's how schemas work:
When a system starts, it saves a list of known schemas for quick reference.
Schemas can be updated to include more fields or change data types.
When a system sends a message, it includes a version number to indicate which schema was used.
The receiving system uses this version number to process the message with the correct schema.
This approach handles messages with different schemas without interruption and allows easy updates and rollbacks.
See the diagram below for reference:
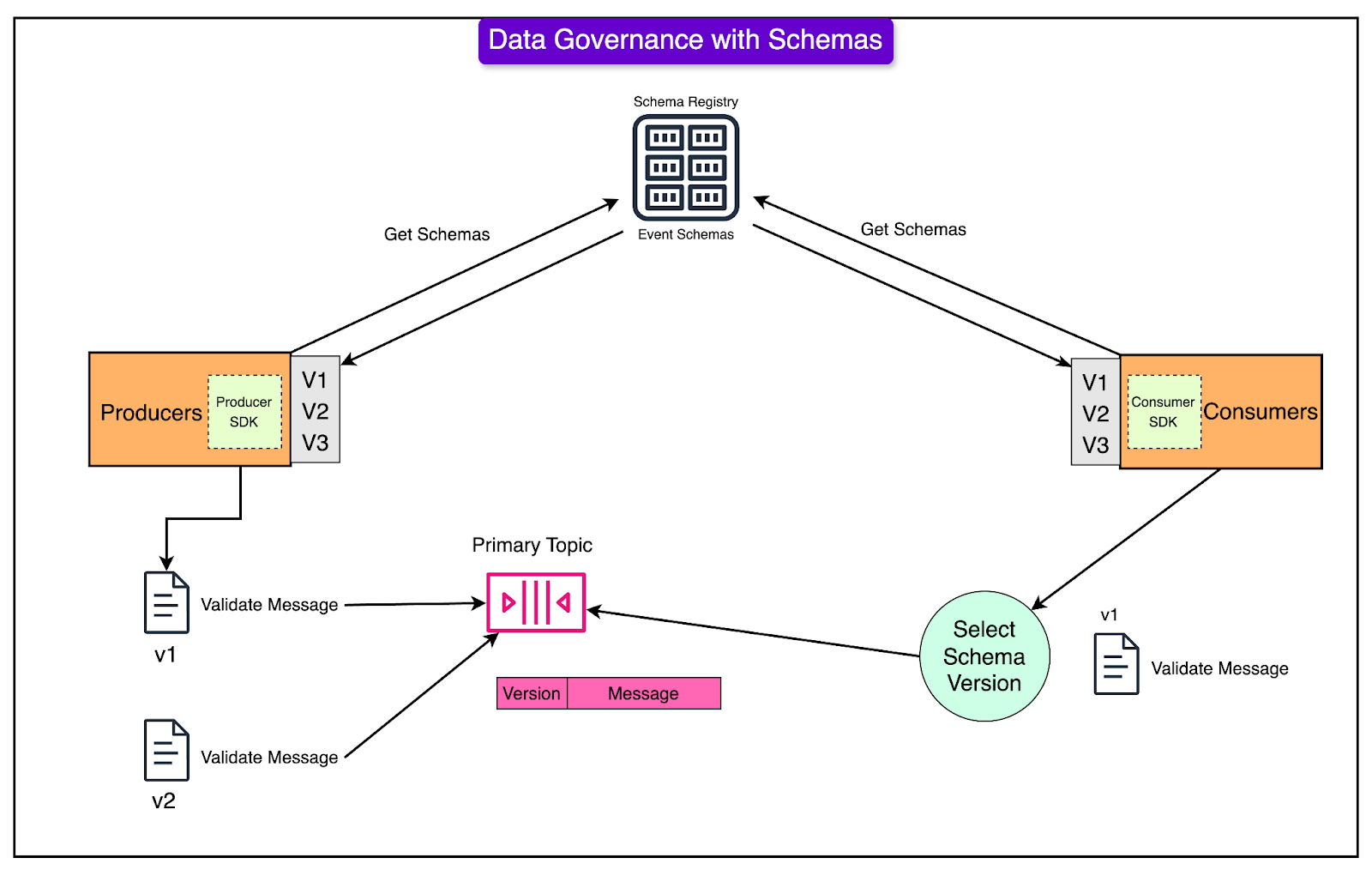
Using a schema registry to validate data contracts ensures that the information flowing between systems is accurate and consistent. This saves time and effort in designing and operating the systems that rely on this data, especially for analytics purposes.
Cluster Autoscaling
MSK is a messaging system that helps different parts of an application communicate with each other. It uses brokers to store and manage the messages.
As the amount of data grows, MSK automatically increases the storage space for each broker. However, they needed a way to add more brokers to the system when the existing ones got overloaded.
To solve this problem, they created an Autoscaler function. See the diagram below:
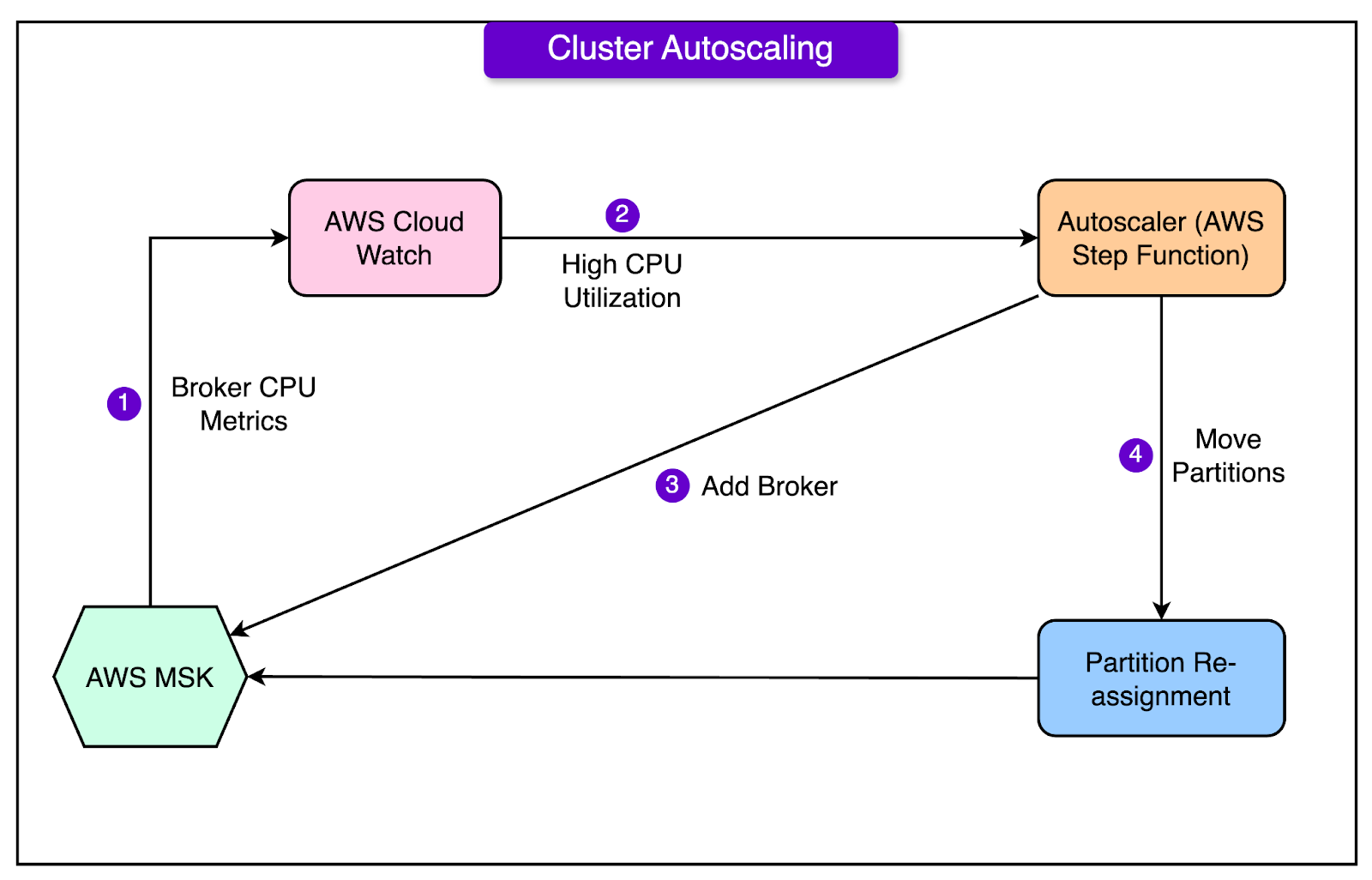
Think of this function as a watchdog that keeps an eye on how hard each broker is working. When a broker's workload (measured by CPU utilization) goes above a certain level, the Autoscaler function kicks in and does two things:
It adds a new broker to the MSK system to help handle the increased workload.
It triggers a lambda function to redistribute the data evenly across all the brokers, including the new one.
This way, the MSK system can automatically adapt to handle more data and traffic without the need to add brokers or move data around manually.
Domain-Based Sharding
To ensure that the messaging system can handle a lot of data and minimize the risk of failures, they divide events into separate groups based on their domain.

Each group has its own dedicated MSK cluster. This is like having separate mailrooms for different departments in a large company. The domain of an event determines which cluster and topic it belongs to. For example, events related to user profiles might go to one cluster, while events related to product orders might go to another.
Applications that need to receive events can choose to get them from any of these domain-based topics. This improves flexibility and helps distribute the workload across the system.
To make sure the platform is always available and can serve users globally, it is set up to work across multiple regions. In each region, there is a high-availability configuration. This means that if one part of the system goes down, another part can take over seamlessly, ensuring uninterrupted service.
Conclusion
McDonald's event-driven architecture demonstrates a successful implementation of a large-scale, global event processing platform. The system effectively handles diverse use cases from mobile order tracking to marketing communications while maintaining high reliability and performance.
Key success factors include the robust implementation of AWS MSK, effective schema management, and comprehensive error-handling mechanisms. The architecture's domain-based sharding approach and auto-scaling capabilities have proven crucial for handling growing event volumes.
Some best practices established through this implementation include:
A standardized SDK usage across different programming languages.
Centralized schema management.
Robust error handling with dead-letter topics.
Performance optimization through schema caching.
Looking ahead, McDonald's platform is positioned to evolve with planned enhancements including:
Formal event specification support.
Transition to serverless MSK.
Implementation of partition autoscaling.
Enhanced developer tooling and experience.
These improvements will further strengthen the platform's capabilities while maintaining its core design principles of scalability, reliability, and simplicity.
References:
Great Article about Event-Driven-Architecture give a broader aspect how all things a play role into
a big picture
any reason to use MSK? it seems like challenging to operate it. migrated to the cloud without changing the existing architecture, or tried to avoid the pay-per-use pricing of SQS, even though it's inexpensive, for handling a large volume of events?