
How Slack Built a Distributed Cron Execution System for Scale

👋Goodbye low test coverage and slow QA cycles (Sponsored)

Bugs sneak out when less than 80% of user flows are tested before shipping. But getting that kind of coverage — and staying there — is hard and pricey for any sized team.
QA Wolf takes testing off your plate:
→ Get to 80% test coverage in just 4 months.
→ Stay bug-free with 24-hour maintenance and on-demand test creation.
→ Get unlimited parallel test runs
→ Zero Flakes guaranteed
QA Wolf has generated amazing results for companies like Salesloft, AutoTrader, Mailchimp, and Bubble.
🌟 Rated 4.5/5 on G2
Have you ever stretched a simple tool to its absolute limits before you upgraded?
We do it all the time. And so do the big companies that operate on a massive scale. This is because simple things can sometimes take you much further than you initially think. Of course, you may have to pay with some toil and tears.
This is exactly what Slack, a $28 billion company with 35+ million users, did for its cron execution workflow that handles critical functionalities. Instead of moving to some other new-age solutions, they rebuilt their cron execution system from the ground up to run jobs reliably at their scale.
In today’s post, we’ll look at how Slack architected a distributed cron execution system and the choices made in the overall design.
The Role of Cron Jobs at Slack
As you already know, Slack is one of the most popular platforms for team collaboration.
Due to its primary utility as a communication tool, Slack is super dependent on the right notification reaching the right person at the right time.
However, as the platform witnessed user and feature growth, Slack faced challenges in maintaining the reliability of its notification system, which largely depended on cron jobs.
For reference, cron jobs are used to automate repetitive tasks. You can configure a cron job to ensure that specific scripts or commands run at predefined intervals without manual intervention.
Cron jobs play a crucial role in Slack's notification system by making sure that messages and reminders reach users on time. A lot of the critical functionality at Slack relies on these cron scripts. For example,
Sending timely reminders to users.
Delivering email notifications to keep the users informed about important updates in the team.
Pushing message notifications to users so that they don’t miss critical conversations.
Performing regular database clean-ups to maintain system performance.
As Slack grew, there has been a massive growth in the number of cron scripts and the amount of data processed by these scripts. Ultimately, this caused a dip in the overall reliability of the execution environment.
The Issues with Cron Jobs
Some of the challenges and issues Slack faced with their original cron execution approach were as follows:
Maintainability Issues: Managing many cron scripts on a single node became cumbersome and error-prone as Slack’s functionalities expanded. Tasks like updating, troubleshooting, and monitoring the scripts required a lot of effort from the engineering team.
Cost-ineffective Vertical Scaling: As the number of cron scripts increased, Slack tried to vertically scale the node by adding more CPU and RAM. However, this approach quickly became cost-ineffective, as the hardware requirements grew disproportionately to the number of scripts.
Single Point of Failure: Relying on a single node to execute all cron jobs introduced a significant risk to Slack’s critical functionality. Any misconfigurations, hardware failures, or software issues on the node could bring down the entire notification system.
To solve these issues, Slack decided to build a brand new cron execution service that was more reliable and scalable than the original approach.
The High-Level Cron Execution Architecture
The below diagram shows the high-level cron execution architecture.
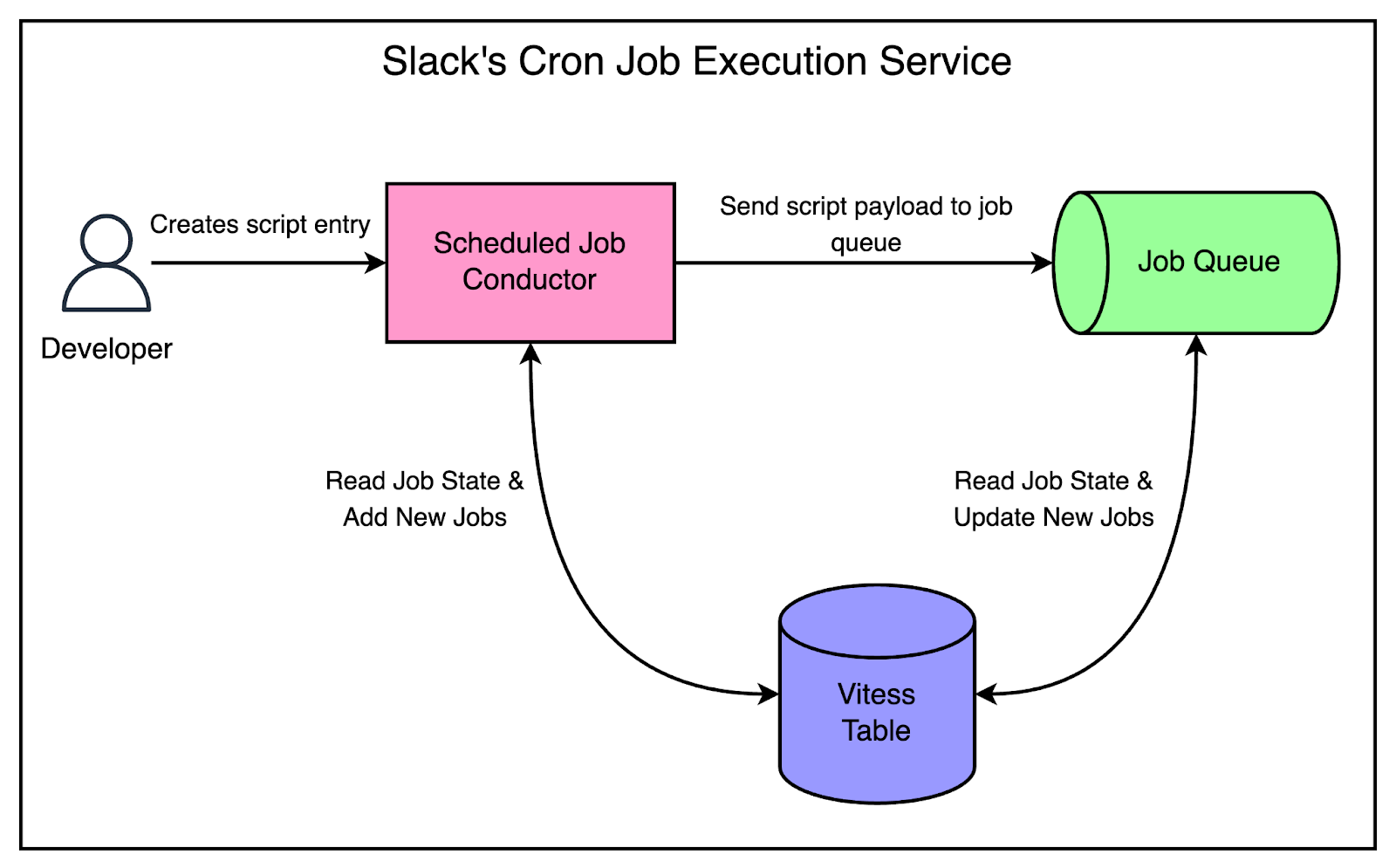
There are 3 main components in this design. Let’s look at each of them in more detail.
Scheduled Job Conductor
Slack developed a new execution service. It was written in Go and deployed on Bedrock.
Bedrock is Slack’s in-house platform that wraps around Kubernetes, providing an additional abstraction layer and functionality for Slack’s specific needs. It builds upon Kubernetes and adds some key features such as:
Simplified deployment
Custom resource definitions specific to Slack’s infrastructure
Enhanced monitoring and logging
Integration with Slack’s infrastructure
The new service mimics the behavior of cron by utilizing a Go-based cron library while benefiting from the scalability and reliability provided by Kubernetes.
The below diagram shows how the Scheduled Job Conductor works in practice.
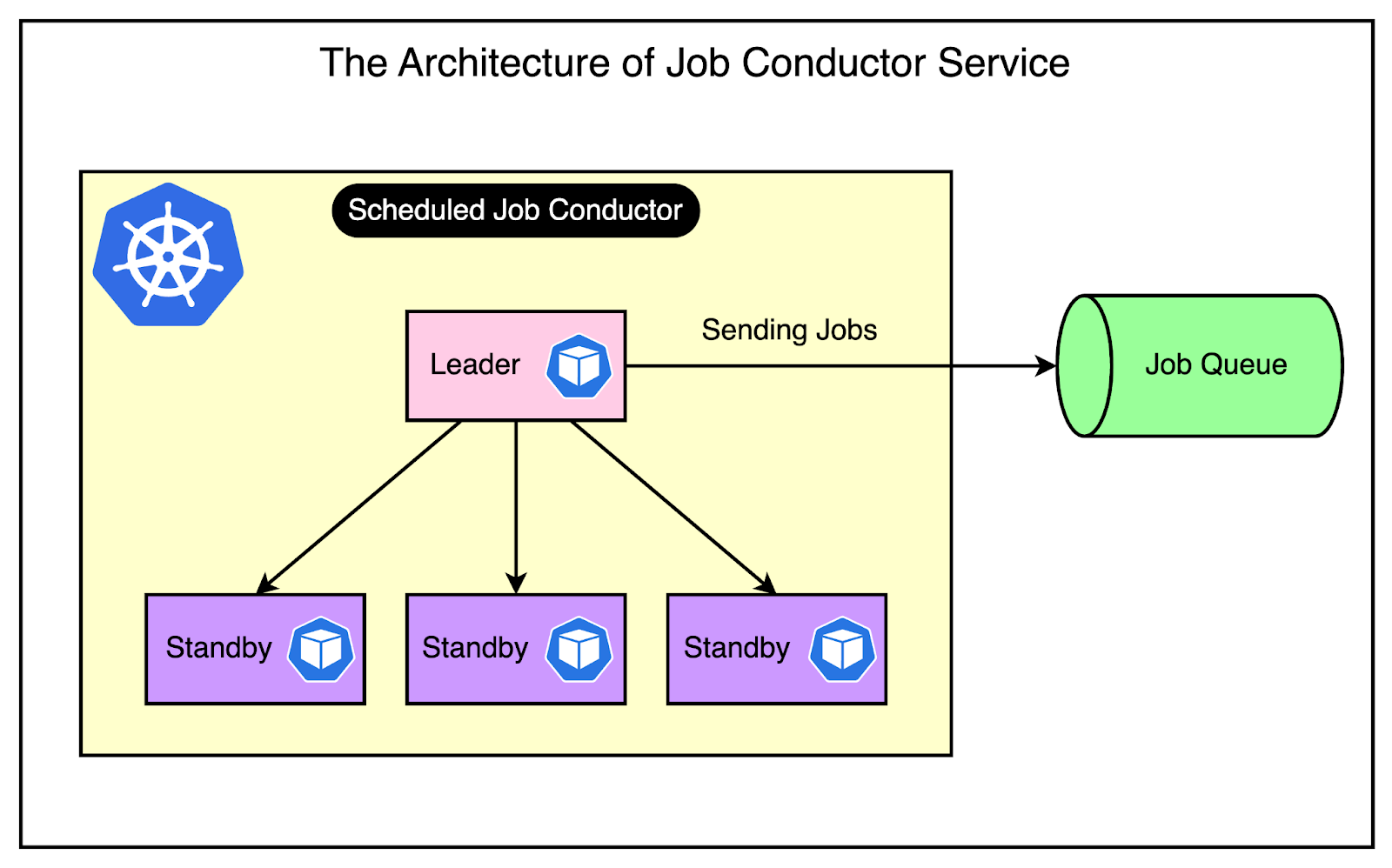
It had some key properties that we should consider.
1 - Scalability through Kubernetes Deployment
By deploying the cron execution service on Bedrock, Slack gains the ability to easily scale up multiple pods as needed.
As you might be aware, Kubernetes provides a flexible infrastructure for containerized applications. You can dynamically adjust the number of pods based on the workload.
2 - Leader Follower Architecture
Interestingly, Slack's cron execution service does not process requests on multiple pods simultaneously.
Instead, they adopt a leader-follower architecture, where only one pod (the leader) is responsible for scheduling jobs, while the other pods remain in standby mode.
This design decision may seem counterintuitive, as it appears to introduce a single point of failure. However, the Slack team determined that synchronizing the nodes would be a more significant challenge than the potential risk of having a single leader.
A couple of advantages of the leader-follower architecture are as follows:
Rapid Failover: If the leader pod goes down, Kubernetes can quickly promote one of the standby pods to take over the work. This minimizes downtime and makes the cron execution service highly available.
Simplified Synchronization: By having a single leader, Slacks avoids the complexity of dealing with conflicts.
3 - Offloading Resource-Intensive Tasks
The job conductor service is only responsible for job scheduling. The actual execution is handled by worker nodes.
This separation of concerns allows the cron execution service to focus on job scheduling while the job queue handles resource-intensive tasks.
Latest articles
If you’re not a paid subscriber, here’s what you missed.

To receive all the full articles and support ByteByteGo, consider subscribing:
The Job Queue
Slack's cron execution service relies on a powerful asynchronous compute platform called the Job Queue to handle the resource-intensive task of running scripts.
The Job Queue is a critical component of Slack's infrastructure, processing a whopping 9 billion jobs per day.
The Job Queue consists of a series of so-called theoretical “queues” through which various types of jobs flow. Each script triggered by a cron job is treated as a single job within the Job Queue.
See the below diagram for reference:
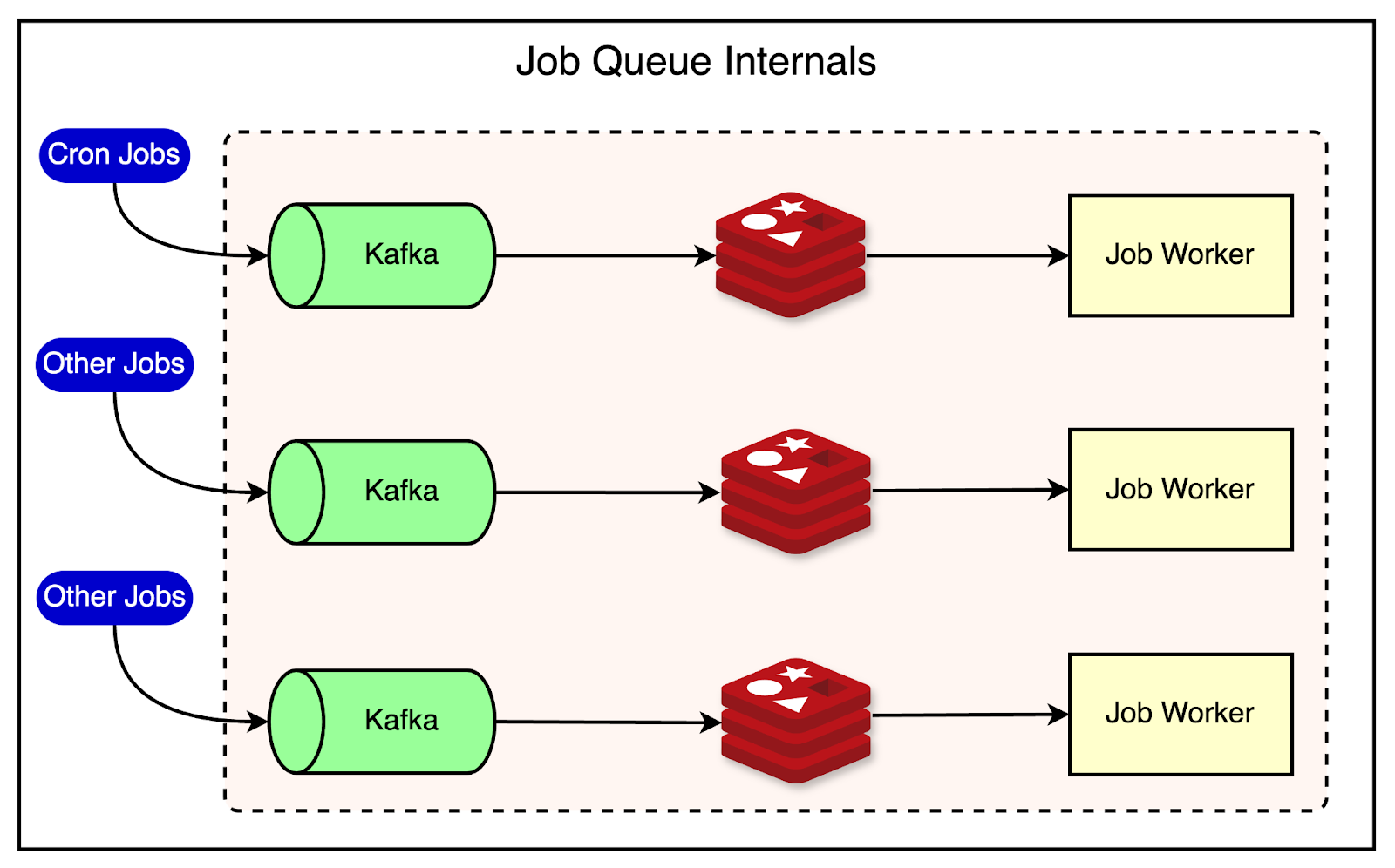
The key components of the job queue architecture are as follows:
Kafka: Jobs are initially stored in Kafka since it provides durable storage. Kafka ensures that jobs are persisted and can be recovered in case of system failures or backups.
Redis: From Kafka, jobs are moved into Redis (an in-memory data store) for short-term storage. Redis allows additional metadata, such as the identity of the worker executing the job, to be stored alongside the job itself. This metadata is important for tracking and managing job execution.
Job Workers: Jobs are dispatched from Redis to job workers, which are nodes that execute the script. Each job worker is capable of running the scripts associated with the jobs it receives.
Slack achieves several important benefits by using the Job Queue:
Offloading compute and memory concerns: The Job Queue is designed to handle a massive amount of work, with a capacity far exceeding the requirements of the cron execution service. Offloading the compute and memory demands of the running scripts helps keep the cron execution service lightweight.
Isolation and performance: The Job Queue lets them keep the jobs isolated on their specific “queues” so that the jobs triggered by the cron execution service are processed smoothly. There is no impact on them due to other jobs in the system.
Reliability and fault tolerance: The Job Queue’s architecture ensures that jobs are stored durably and recoverable in case of failures.
Reduce development and maintenance efforts: This was probably the most important factor since leveraging an existing, battle-tested system like the Job Queue helped Slack reduce the development time required to build the cron execution service.
Vitess Database Table for Job Tracking
To boost the reliability of their cron execution service, Slack also employed a Vitess table for deduplication and job tracking.
Vitess is a database clustering system for horizontal scaling of MySQL. It provides a scalable and highly available solution for managing large-scale data.
A couple of important requirements handled by Vitess are as described as follows:
1 - Deduplication
Within Slack’s original cron system, they used flocks, a Linux utility for managing locking in scripts so that only one copy of a script runs at a time.
While this approach worked fine, there were cases where a script’s execution time exceeded its recurrence intervals, leading to the possibility of two copies running concurrently.
To handle this issue, Slack introduced a Vitess table to handle deduplication.
Here’s how it works:
When a new job is triggered, Slack records its execution as a new row in the Vitess table.
The job’s status is updated as it progresses through the system, with possible states including “enqueued”, “in progress”, and “done”.
Before kicking off a new run of a job, Slack queries the table to check if there are any active instances of the same job already running. This query is made efficient by using an index on the script names.
The below diagram shows some sample data stored in Vitess.

2 - Job Tracking and Monitoring
The Vitess table also helps with job tracking and monitoring since it contains information about the state of each job.
The job tracking functionality is exposed through a simple web page that displays the execution details. Developers can easily look up the state of their script runs and any errors encountered during execution.
Conclusion
One can debate whether using cron was the right decision for Slack when it came to job scheduling.
But it can also be said that organizations that choose the simplest solution for critical functionalities are more likely to grow into organizations of Slack’s size. On the other hand, companies that deploy solutions that try to solve all the problems when they have 0 customers never become that big. The difference is an unrelenting focus on solving the business problem rather than building fancy solutions from the beginning.
Slack’s journey from a single cron box to a sophisticated, distributed cron execution service shows how simple solutions can be used to build large-scale systems.
References:
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
why are both kafka and redis required here. wouldnt one be enough
I don't quite understand how the jobs are "dispatched" from Redis to the workers. Wouldn't workers need to poll the Redis cache in-order to figure out the available jobs? Can someone please explain? And also it is mentioned that it is debatable whether cron was the right choice for Slack. What other possible options Slack could have considered?