
How PayPal Scaled Kafka to 1.3 Trillion Daily Messages

Database Performance at Scale: A Practical Guide [FREE BOOK] (Sponsored)

Discover new ways to optimize database performance – and avoid common pitfalls – in this free 270-page book.
This book shares best practices for achieving predictable low latency at high throughput. It’s based on learnings from thousands of real-world database use cases – including Discord, Disney, Strava, Expedia, Epic Games & more.
Explore often-overlooked factors that impact database performance at scale
Recognize the performance challenges teams face with different types of workloads
Select database infrastructure and topology that’s suited to your needs
Optimize how you benchmark and monitor performance
Avoid common mistakes that impact latency and throughput
Get practical advice for navigating performance tradeoffs
Disclaimer: The details in this post have been derived from the article originally published on the PayPal Tech Blog. All credit for the details about PayPal’s architecture goes to their engineering team. The link to the original article is present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
In the 2022 Retail Friday, PayPal’s Kafka setup witnessed a traffic volume of 21 million messages per second.
This was about 1.3 trillion messages in a single day.
Similarly, Cyber Monday resulted in 19 million messages per second coming to around 1.23 trillion messages in a single day.
How did PayPal scale Kafka to achieve these incredible numbers?
In this post, we will go through the complete details of PayPal’s high-performance Kafka setup that made it possible.
Kafka at PayPal
Apache Kafka is an open-source distributed event streaming platform.
PayPal adopted Kafka in 2015 and they use it for building data streaming pipelines, integration, and ingestion.
At present, PayPal’s Kafka fleet consists of over 1500 brokers hosting 20,000 topics. The 85+ clusters are expected to maintain a 99.99% availability.
Over the years, PayPal has seen tremendous growth in streaming data and they wanted to ensure high availability, fault tolerance, and optimal performance.
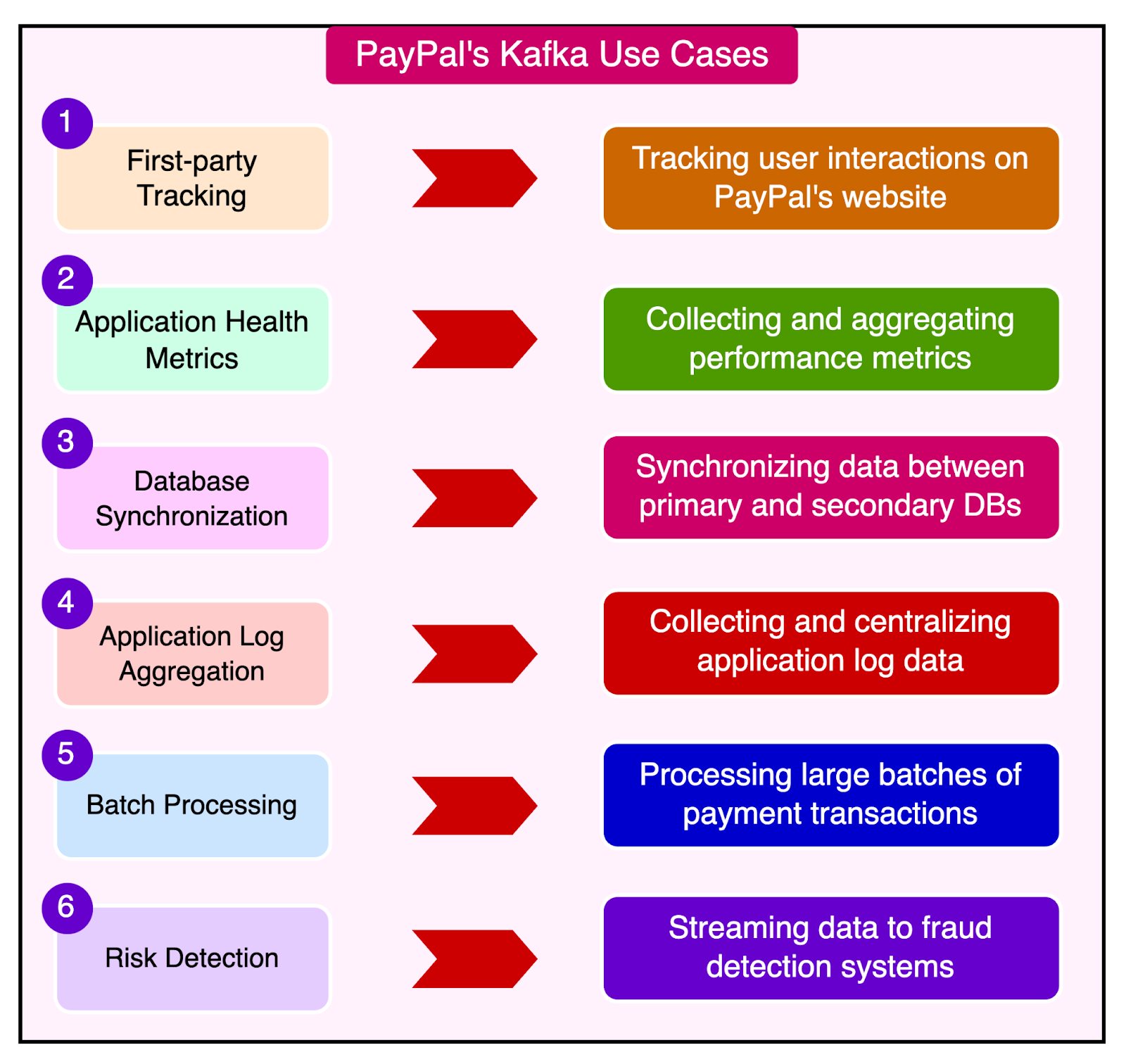
Some of the specific use cases where PayPal uses Kafka are as follows:
First-party Tracking: Tracking user interactions and clickstream data on PayPal’s website and mobile app for real-time analytics and personalization.
Application Health Metrics: Collecting and aggregating performance metrics from various PayPal services to monitor system health and detect anomalies.
Database Synchronization: Synchronizing data between PayPal’s primary database and secondary databases for disaster recovery and high availability.
Application Log Aggregation: Collecting and centralizing log data from different PayPal applications and services for troubleshooting, monitoring, and analysis.
Batch Processing: Processing large batches of payment transaction data using Kafka as a buffer for decoupling the data ingestion and processing stages.
Risk Detection and Management: Streaming real-time payment data through Kafka for feeding the fraud detection and risk assessment models.
Analytics and Compliance: Capturing and analyzing financial transaction data in real-time for regulatory reporting and audit purposes.
How PayPal Operates Kafka?
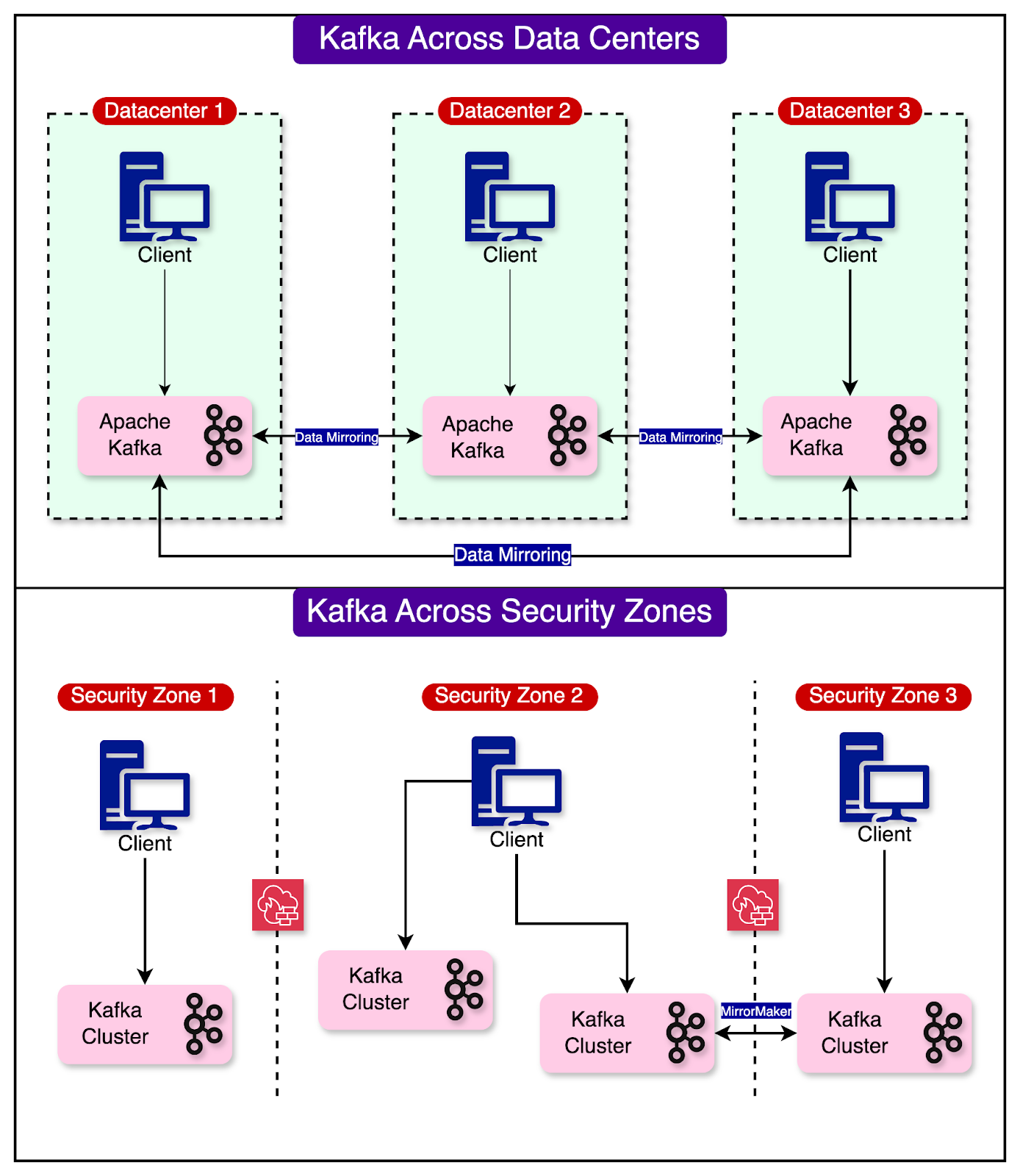
PayPal’s infrastructure is spread across multiple geographically distributed data centers and security zones. Kafka clusters are deployed across these zones.
There are some key differences between data centers and security zones:
A data center is a physical facility that houses computing infrastructure. A security zone is a logical partition with a data center or across data centers, created through network segmentation.
While data centers help with isolation and availability, security zones provide an additional level of security isolation beyond the physical boundaries.
Security zones are often defined based on data classification levels, such as highly sensitive, confidential, or public data.
In the context of PayPal, Kafka clusters handling sensitive payment data may be placed in a high-security zone with restricted access. Clusters processing less sensitive data may reside in a different security zone.
One thing, however, is common.
Whether it is data centers or security zones, MirrorMaker is used to mirror the data across the data centers, which helps with disaster recovery and communication across security zones.
For reference, Kafka MirrorMaker is a tool for mirroring data between Apache Kafka clusters. It leverages the Kafka Connect framework to replicate data, which improves resiliency.
See the diagram below to get an idea about PayPal’s Kafka setup across data centers and security zones:
Operating Kafka at the scale of PayPal is a challenging task. To manage the ever-growing fleet of Kafka clusters, PayPal has focused on some key areas such as:
Cluster Management
Monitoring and Alerting
Configuration Management
Enhancements and Automation
The diagram below shows a high-level view of PayPal’s Kafka Landscape:
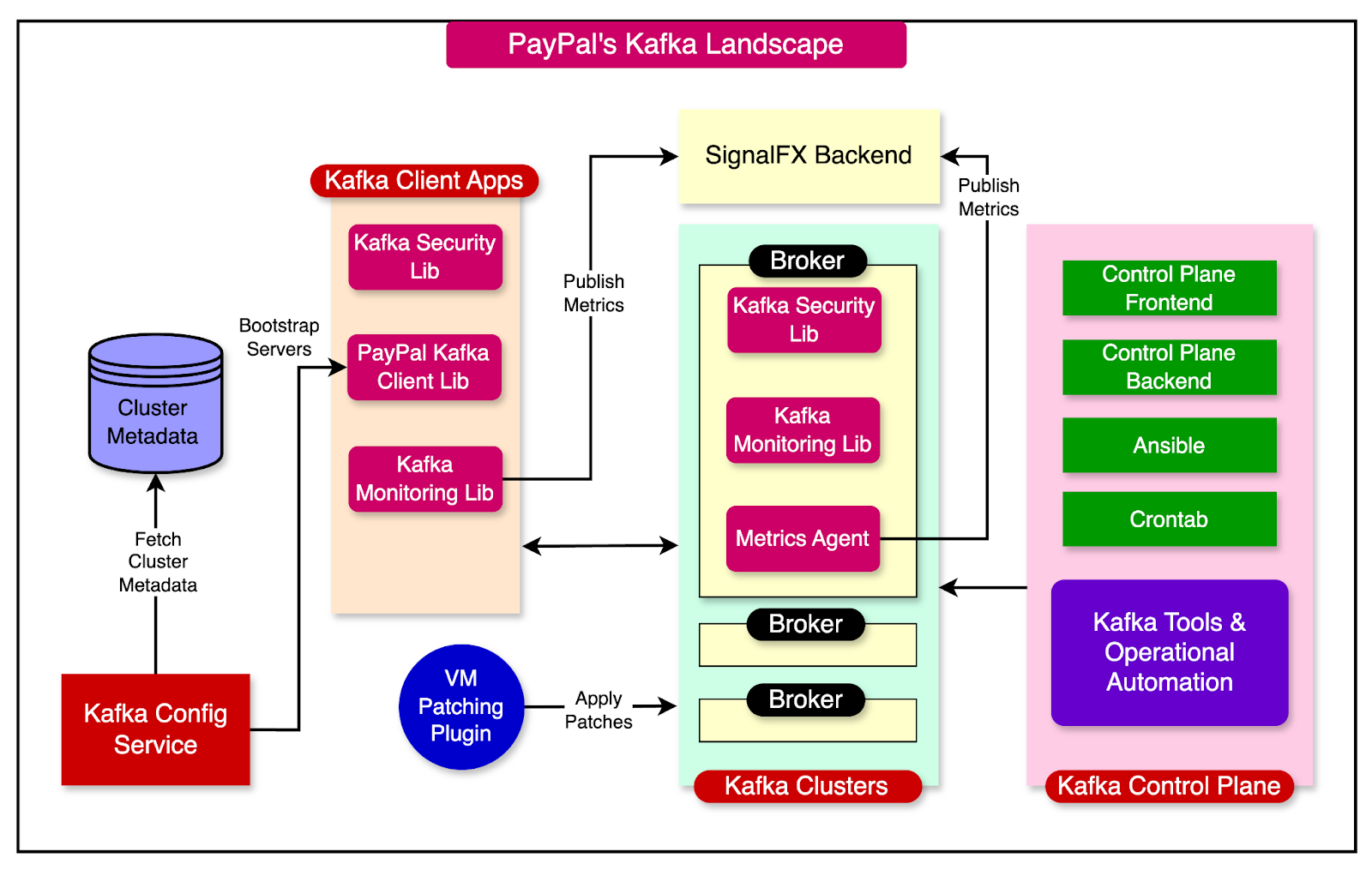
In the subsequent sections, we will look at each area in greater detail.
Cluster Management
Cluster management deals with controlling Kafka clusters and reducing operational overhead. Some of the key improvements were done in areas like:
Kafka Config Service
ACLs
Kafka Libraries for PayPal
QA environment
Let’s look at each improvement in more detail.
Latest articles
If you’re not a paid subscriber, here’s what you missed.

To receive all the full articles and support ByteByteGo, consider subscribing:
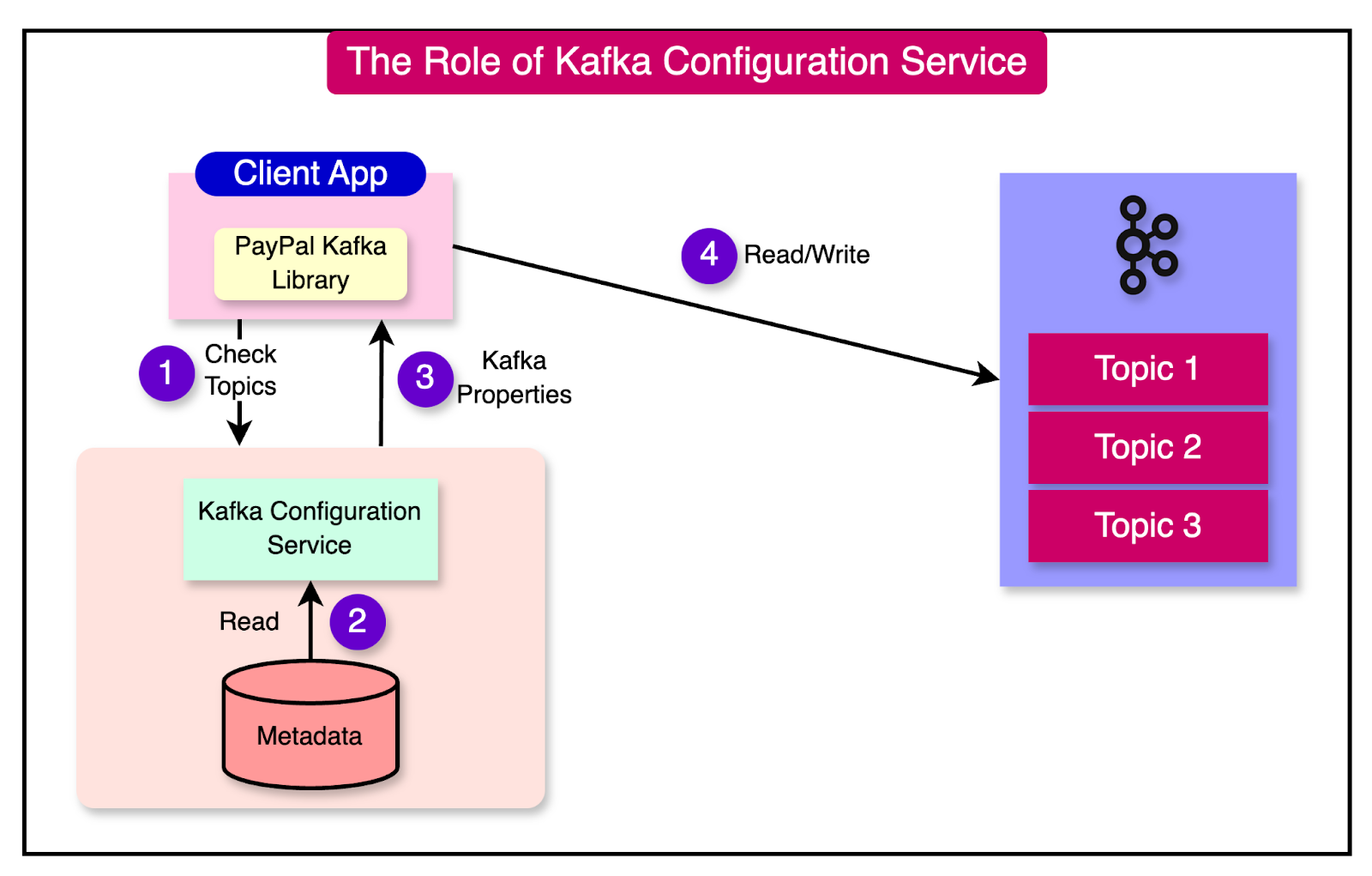
Kafka Config Service
PayPal built a special Kafka config service to make it easy for clients to connect to the Kafka clusters.
Before the config service, clients had to hardcode the broker IPs in the connection configuration.
This created a maintenance nightmare due to a couple of reasons:
Firstly, replacing a broker for upgrades, patching, or disk failures required updates to the client. Missing to update one broker IP somewhere would often lead to multiple incidents.
Second, Kafka is configuration-heavy, making it tough for developers to figure out a suitable set of configurations. Often, the Kafka clients would override certain properties without knowing the implications, resulting in support issues due to unexpected behavior.
The Kafka config service solved these issues. The service makes it easy for the Kafka clients to follow a standard configuration. Ultimately, it reduces operational and support overhead across teams.
The diagram below shows the Kafka client retrieving bootstrap servers and configuration from the config service using the topic information.
Kafka ACLs
Initially, any PayPal application could connect to any of the existing Kafka topics. This was an operational risk for the platform considering that it streams business-critical data.
To ensure controlled access to Kafka clusters, ACLs were introduced.
For reference, ACLs are used to define which users, groups, or processes have access to specific objects such as files, directories, applications, or network resources. It’s like a table or list specifying a particular object's permissions.
With the introduction of ACLs, applications had to authenticate and authorize access to Kafka clusters and topics.
Apart from making the platform secure, ACLs also provided a record of every application accessing a particular topic or cluster.
PayPal Kafka Libraries
It was important to ensure that Kafka clusters and the clients connecting to them operate securely. Also, there was a need to ensure easy integration to multiple frameworks and programming languages. They didn’t want each engineering team to reinvent the wheel.
To facilitate these needs, PayPal built a few important libraries:
Resilient Client Library: When a client tries to establish a connection to the cluster, this library gets the Kafka broker details and the required configuration for the producer or consumer application.
Monitoring Library: This library publishes critical metrics for client applications, allowing applications to set alerts and get notifications in case of any issues.
Kafka Security Library: The Kafka platform supports more than 800 applications. This library takes care of the required certificates and tokens to enable SSL authentication for applications connecting to the Kafka clusters. It avoids a lot of overhead around key management, certificate updates, and key rotations.
QA Platform
One of the great things PayPal did was to set up a production-like QA platform for Kafka for developers to test changes confidently.
This is a common problem in many organizations where the testing performed by developers is hardly indicative of the production environment, resulting in issues after launch.
A dedicated QA platform solves this by providing a direct mapping between production and QA clusters.
The same security standards are followed. The same topics are hosted on the clusters with the brokers spread across multiple zones within the Google Cloud Platform.
Monitoring and Alerting
Monitoring and alerting are extremely important aspects for systems operating at a high scale. Teams want to know about issues and incidents quickly so that cascading failures can be avoided.
At PayPal, the Kafka platform is integrated with the monitoring and alerting systems.
Apache Kafka provides multiple metrics. However, they have taken out a subset of metrics that help them identify issues faster.
The Kafka Metrics library filters out the metrics and sends them to the SignalFX backend via SignalFX agents running on all brokers, Zookeepers, MirrorMakers, and Kafka clients. Individual alerts associated with these metrics are triggered whenever abnormal thresholds are breached.
Configuration Management
Operating a critical system requires one to guard against data loss. This is not only applicable to the application data but also to the infrastructure information.
What if the infrastructure gets wiped out and we’ve to rebuild it from scratch?
At PayPal, configuration management helps them store the complete infrastructure details. This is the single source of truth that allows PayPal to rebuild the clusters in a couple of hours if needed.
They store the Kafka metadata such as topic details, clusters, and applications in an internal configuration management system. The metadata is also backed up to ensure that they have the most recent data in case it’s required to re-create clusters and topics in case of a recovery.
Enhancements and Automation
Large-scale systems require special tools to carry out operational tasks as quickly as possible.
PayPal built multiple such tools for operating their Kafka cluster. Let’s look at a few important ones:
Patching Security Vulnerabilities
PayPal uses BareMetal for deploying the Kafka brokers and virtual machines for Zookeeper and MirrorMakers.
As we can expect, all of these hosts need to be patched at frequent intervals to fix any security vulnerabilities.
Patching requires BM restart which can cause partitions to lag. This can also lead to data loss in the case of Kafka topics that are configured with a replica set of three.
They built a plugin to query whether a partition was lagging before patching the host, thereby ensuring only a single broker is patched at a time with no chances of data loss.
Topic Onboarding
Application teams require topics for their application functionality. To make this process standardized, PayPal built an Onboarding Dashboard to submit a new topic request.
The diagram below shows the onboarding workflow for a topic.

A special review team checks the capacity requirements for the new topic and onboards it to one of the available clusters. They use a capacity analysis tool integrated into the onboarding workflow to make the decision.
For each new application being onboarded to the Kafka system, a unique token is generated. This token is used to authenticate the client’s access to the Kafka topic. As discussed earlier, an ACL is created for the specific application and topic based on their role.
MirrorMaker Onboarding
As mentioned earlier, PayPal uses MirrorMaker for mirroring the data from one cluster to another.
For this setup, developers also use the Kafka Onboarding UI to register their requirements. After due checks by the Kafka team, the MirrorMaker instances are provisioned.
The diagram below shows the process flow for the same:

Conclusion
The Kafka platform at PayPal is a key ingredient for enabling seamless integration between multiple applications and supporting the scale of their operation.
Some important learnings to take away from this study are as follows:
Tooling is a must when operating Kafka on a large scale. This involves operations such as cluster installation, topic management, patching VMs, etc.
Availability is as good as the ability of alerting and monitoring systems to provide timely inputs to the infrastructure team.
ACLs are a great way to have a better understanding of how the various applications are connected with Kafka.
A dedicated QA environment is critical for developers to ship changes with confidence and speed.
References
SPONSOR US
Get your product in front of more than 500,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing hi@bytebytego.com
Why is data mirroring needed ? Is it for fault tolerance purpose ?
Thank you so much for putting your hard work into describing what actually happens behind the scenes at PayPal and how they leverage Kafka in simple words! ♥️😊